简单的排序
以a[5]为例
a[5] = {9,6,15,4,2};
1.简单选择法排序
遍历数组把数组的最小值(或是最大值)找到,然后放在数组0号位置上。然后划掉0号位置,遍历剩下的数字找到最值,然后放到数组1号位置上,以此类推
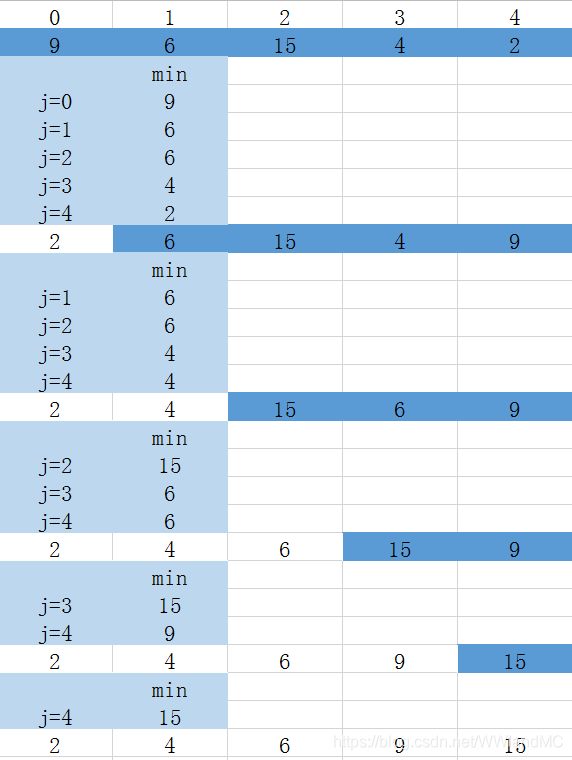
从i个记录中挑选最小记录需要比较i-1次
第i(i=0~n-2)趟从n-i记录中挑选最小记录需要比较n-i-1次
对n个记录进行简单选择排序,比较次数为:n*(n-1)/2
移动次数,正序为最小值0,反序为最大值3(n-1)
简单选择排序最好,最坏和平均时间复杂度均为O(n^2)
简单选择排序的时间复杂度和初始序列的顺序无关
代码片段如下
// c
for(i=0;i<5;i++){
min = a[i];
k_min = i;
for(j=i+1;j<5;j++){
if(min>a[j]){
min = a[j];
k_min = j;
}
}
if(k_min != i){
a[k_min] = a[i];
a[i] = min;
}
}
# python
for i in range(len(a)):
min = a[i]
k_min = i
for j in range(i+1,len(a)):
if min > a[j]:
min = a[j]
k_min = j
if k_min != i:
a[k_min] = a[i]
a[i] = min
2.冒泡法排序
这个算法的名字由来是因为越大的元素(或者最小)会经由交换慢慢“浮”到数列的顶端(升序或降序排列),就如同碳酸饮料中二氧化碳的气泡最终会上浮到顶端一样,故名“冒泡排序”。
选定一个方向进行扫描,逐个比较数组中相邻的两个数组元素的值,将较小的数(从小到大排序)排在较大的数前面
图解如下
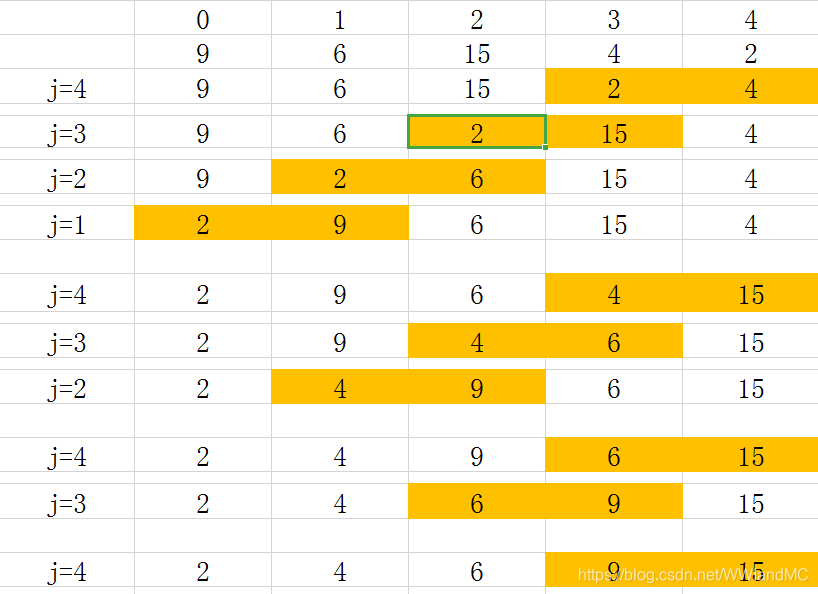
最好的情况——关键字在记录序列中正序:
只需要进行1趟冒泡
比较次数 = n-1
移动次数 = 0;
最坏的情况——关键字在记录序列中反序:
需要进行n-1趟冒泡
比较次数 = n(n-1)/2
移动次数 = 3n*(n-1)/2
所以冒泡排序最好的时间复杂度为O(n),最坏时间复杂度为O(n^2);
改进后的冒泡排序代码片段如下
for (int i = 1; i < size; i++) //外层循环1~size-1
{
bool exchange = false;
for (int j = size - 1; j >= i; j--)
{
//内层循环i~size-1
if (a[j] < a[j - 1])
{
exchange = true; //如果一趟冒泡后没有交换任何关键字则说明该序列已经排好
swaq(a[j], a[j - 1]); //交换两个数
}
}
if (exchange == false)
{
break;
}
}
# python
def swap(a,b):
return b,a
for i in range(1,len(a)):
exchange = False
for j in range(len(a)-1,i-1,-1):
if a[j] < a[j-1]:
exchange = True
a[j], a[j-1] = swap(a[j], a[j-1])
if exchange == False:
break
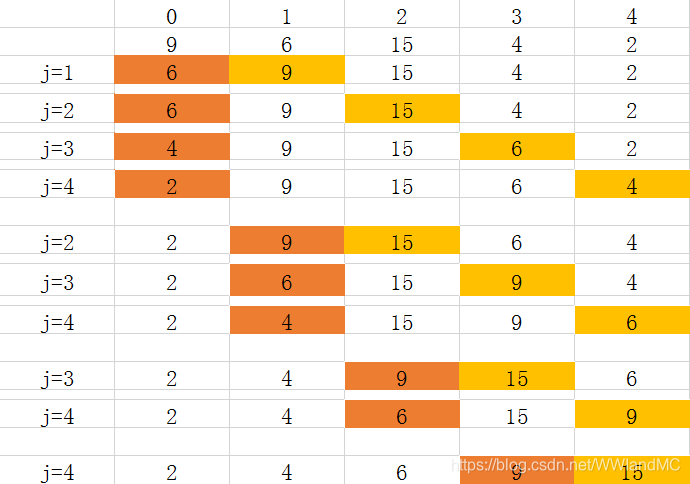
3.交换排序
和冒泡排序的区别在于
冒泡排序是边比较边移动,逐个比较相邻的元素;而交换排序是选定一个位置不变,逐个比较相对大小并与固定位置交换
图解如下
代码片段如下:
for(i=0;i<size;i++){
for(j=i+1;j<size;j++){
if(a[j]>a[j-1]){
swap(a[j],a[j-1]);
}
}
}
def swap(a,b):
return b,a
for i in range(len(a)):
for j in range(i+1,len(a)):
if a[j] > a[j-1]:
swap(a[j],a[j-1])
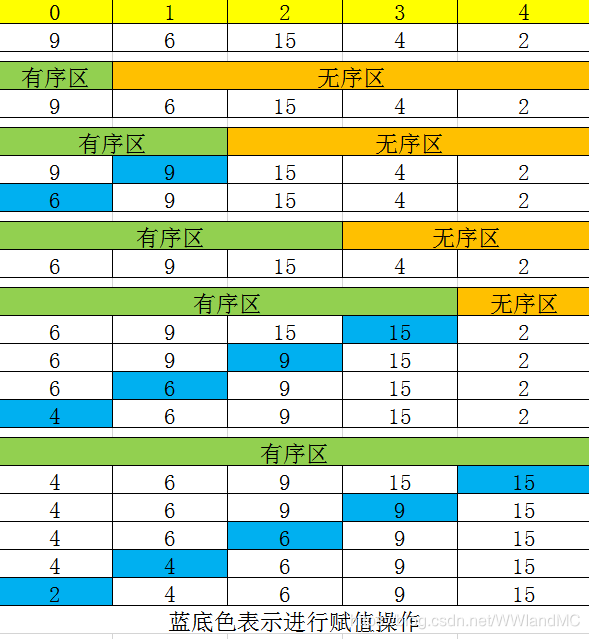
4.直接插入排序法
基本思路:把初始序列分成有序区和无序区,把无序区的元素按照有序区的顺序一一插入有序区,直到有序区包含了所有数据。注意有序区不一定是已经排好序的。
初始时,有序区只有一个元素(只有一个元素可认为有序),把无序区里面n-1个元素插入有序区。
for(i=1;i<size;i++){
if(a[i]<a[i-1]){ //只有当反序的时候才进入排序流程
tmp = a[i];
j = i-1;
do{ //找a[i]的插入位置
a[j+1] = a[j]; //将关键字大于a[i]的记录向后移
j--;
}while((j>=0) && (a[j]>tmp));
a[j+1] = tmp; //在j+1出插入
}
}
在最好的情况下——关键字在记录序列中正序
比较次数 = n-1;元素移动次数 = 0;
最好的情况下时间复杂度为O(n)
最坏的情况下——关键字在记录序列中反序
比较次数 = n(n-1)/2;元素移动次数 = (n-1)(n+4)/2;
最坏的情况时间复杂度为O(n^2)
平均时间复杂度为O(n^2)
排序和查找<stdlib.h>
qsort
void
qsort( void *base, size_t n_elements, size_t el_size, int ( *compare )( void const *, void const * ) ) ;
最后一个参数是一个函数指针
bsearch
void
bsearch( void const *key, void const *base, size_t n_elements, size_t el_size, int ( *compare )( void const *, void const * ) );
bsearch的原理是二分查找,数组需要预先排序
#include <stdio.h>
#include <stdlib.h>
int
compare( void const *a, void const *b )
{
return ( *( int* )a ) > ( *( int* )b ) ? 1 : 0;
}
int
main( int argc, char *argv[] )
{
int i;
int key = 110;
int *ans;
int a[] = { 0, 110, 222, 55 };
qsort( a, sizeof(a) / sizeof( int ), sizeof( int ), compare );
for( i = 0; i < sizeof( a ) / sizeof( int ); i++ ){
printf("%d ", a[i]);
}
ans = ( int* )bsearch( &key, a, sizeof( a ) / sizeof( int ), sizeof( int ), compare );
if( ans != NULL ){
printf("\n%d", *ans);
}else{
printf("\nNot Found");
}
return 0;
}
