博客备份
知识点整理——STL与容器
收录时间:2022.03.08
点击此处展开查看内容
[TOC]1. \(\tt{STL}\) 概论
STL容器是指由官方提供的用于存放数据的类模板。为了加强其可用性,一般会集成众多成员函数,故它们都具有极强的实用性与拓展性,是平时竞赛中常会被使用到的工具。下文就一部分STL容器及其功能函数做出解释。
2. 通用方法之比较
任何两个容器对象,只要它们的类型相同,就可以用< <= > >= == != 进行比较运算。规则如下:
a == b:若 a 和 b 中的元素个数相同,且对应元素均相等,则a == b的值为 true,否则值为 false。a < b:规则类似于词典中两个单词比较大小,从头到尾依次比较每个元素,如果- \(a\) 中元素小于 \(b\) 中元素,则 \(a < b\) 的值为 \(true\)
- \(a\) 中元素个数比 \(b\) 少,\(a < b\) 的值也为 \(true\)
- 其他情况下值为 \(false\)
3. 通用方法之成员函数
通用的构造函数
容器类型<元素类型> 容器名称;:直接构造。构造空容器。容器类型<元素类型> 容器名称 ({元素内容, 元素内容, ……});:利用数组进行构造。容器类型<元素类型> 容器名称 (另一个已有容器的名称);:复制构造。利用另一个已有的同类型容器构造一个独立复制品。
通用的容量操作
- \(\tt{}size()\) :返回容器中元素的数量。
- \(\tt{}empty()\) :判断容器对象是否为空。
通用的遍历操作
对于顺序容器( \(\tt{}vector\) )、关联容器( \(\tt{}set、multiset、map、multimap\) ),均有以下功能函数:
- \(\tt{}begin()\) :返回第一个元素的迭代器。
- \(\tt{}end()\) :返回容器的尾部。注意:直接使用
*a.end()是越界访问。
通用的元素操作之读取
- \(\tt{top()}\) :对于栈,返回头部元素。
- \(\tt{}front()\) :对于队列、关联容器,返回第一个元素。
- \(\tt{}back()\) :对于队列、关联容器,返回最后一个元素。
通用的元素操作之插入
- \(\tt{}push()\) :对于栈、队列这种数据结构,用于在头部向容器内压入元素。
- \(\tt{}insert()\) :对于顺序容器, \(insert()\) 允许你在任何位置进行插入操作;而对于关联容器,这一函数会先寻找合适位置,再将数据插入(保证容器有序)。
- \(\tt{}push\_back()\) :对于顺序容器,用于尾部插入。
- \(\tt{}emplace()\) :【C++11】这一函数是 \(insert()\) 和 \(push()\) 的完全上位替代。用法一致,效率高一倍。
- \(\tt{}emplace\_back()\) :【C++11】这一函数是 \(push\_back()\) 的完全上位替代。
通用的元素操作之删除
- \(\tt{}pop()\) :对于栈、队列这种数据结构,用于弹出头部元素。
- \(\tt{}erase()\) :对于顺序容器, \(insert()\) 允许你进行单点及区间删除;而对于关联容器,只能对单点删除。
- \(\tt{}pop\_back()\) :对于顺序容器,用于尾部删除。
- \(\tt{}clear()\) :清空容器。
4. 迭代器 \(\tt{iterator}\)
迭代器可以指向容器中的某个元素,借助迭代器可以读写它指向的元素。与指针类似。
容器名::iterator 迭代器名;:为容器创建一个正向迭代器。对其进行++操作时,迭代器指向下一个元素。容器类名::reverse_iterator 迭代器名;:为容器创建一个反向迭代器。对其进行++操作时,迭代器指向上一个元素。
例如以下代码块,即是利用迭代器,完成了对vector容器内所有元素的遍历:
vector<int>::iterator it;
for(it = v.begin(); it != v.end(); it ++) {
cout << *it << endl;
}
5. 使用 \(\tt{auto}\) 关键字代替迭代器
注意:需要C++11及以上版本的编译器才支持这一函数
在C++11及以上版本中, \(auto\) 关键字的加入使得迭代器的使用被大大简化。使用 \(auto\) 翻译上方迭代器代码,格式如下:
for(auto it = v.begin(); it != v.end(); it ++) {
cout << *it << endl;
}
以上的代码块还能被进一步简化,如下:
for(auto it : v) {
cout << it << endl;
}
6. \(\tt{pair}\) 的用法
类似于一个结构体,让你能够快速的将两个单独的元素绑在一起成为一个合成元素。
常常用于 \(\tt{}map\) 容器的“下标-元素”对。详见下文 \(\tt{}map\) 容器详解。
构造函数
pair<元素类型, 元素类型> P;构造空 \(\tt{}pair\) 。pair<元素类型, 元素类型> P (元素内容, 元素内容);:数据构造。- 使用花括号可以替代
make_pair用法,如下例。
vector<pair<string, int> > v;
v.push_back({"WIDA", 23});
元素操作:读取
\(\tt{}pair\) 中只有两个元素,分别是 \(\tt{}first\) 和 \(\tt{}second\) ,只需要按照正常读取结构体的方式读取即可。
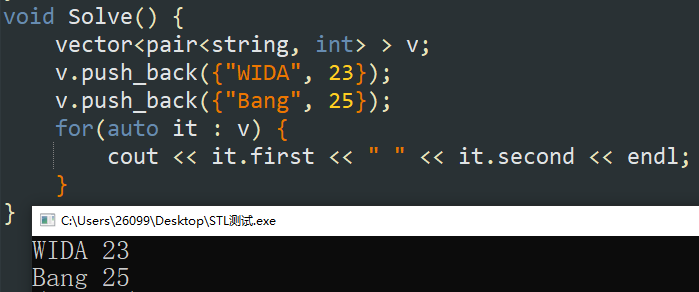
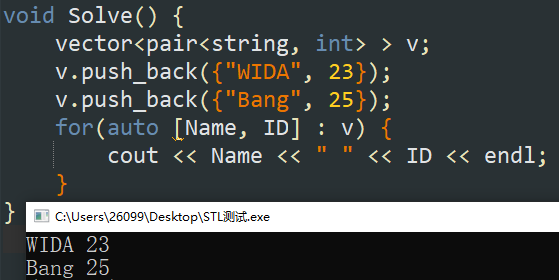
【C++17】也可以直接进行读取(同 \(\tt{}tuple\) )。
元组 \(\tt{tuple}\) 的用法
【C++11】在C++11版本引入的全新类型,可类比于 \(\tt{pair}\) ,差别在于 \(\tt{pair}\) 只支持两个元素,而元组在理论上支持 \(3\) 到无穷多个元素;亦可类比于结构体,较之更简洁、直观。
构造函数
tuple<int, int, int, int> T;:构造新元组。
元素操作:读取
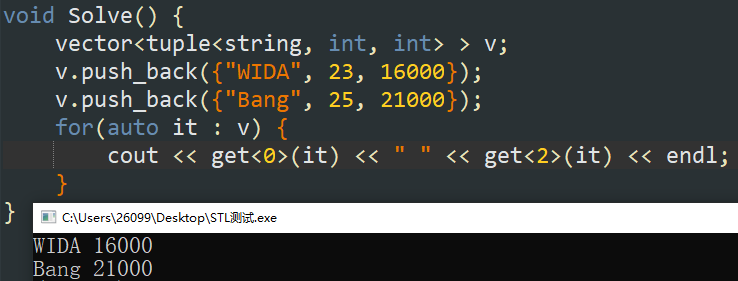
使用 get<index>(obj) 可以获取 \(\tt{obj}\) 对象中的第 \(obj\) 个元素,如下例。但是需要注意的是, \(\tt{index}\) 只能手动输入,而不支持动态输入(例如,用 \(\tt{for}\) 循环输入是不可以的)。
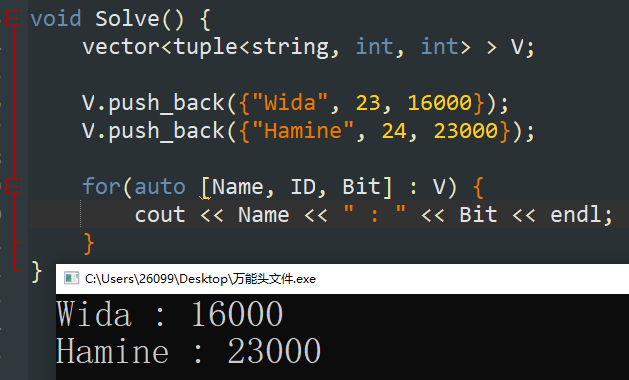
【C++17】使用 \(\tt{auto}\) 可以取出容器中的三元组,如下例。
7. 容器适配器——栈 \(\tt{}stack\)
遵循先进后出(FILO)的数据结构。只能在一端(称栈顶,top)对其内部元素进行操作。
不允许遍历行为。若需清空栈,需要逐个弹出。
构造函数
stack<元素类型> S;:构造空容器。stack<元素类型> S ({元素内容, 元素内容, ……});:数组构造。在后面的元素会先被弹出。stack<元素类型> S1 (S);:复制构造。生成容器 \(S\) 的独立复制品 \(S1\)。在此句之前,应当已定义过 \(S\)。
容量操作
int len=S.size();:返回容器大小。S.empty():判断是否为空。
元素操作
S.push(元素内容):向栈顶添加一个元素。S.emplace(元素内容):向栈顶添加一个元素。相较 \(\tt{}push()\) 效率更高。S.top();:返回栈顶元素。S.pop():弹出栈顶元素。
8. 容器适配器——循环队列 queue
遵循先进先出(FIFO)的数据结构。元素自队尾进入,队头删除。
不允许遍历行为。若需清空队列,需要逐个弹出。
构造函数
queue<元素类型> Q;:构造空容器queue<元素类型> Q ({元素内容, 元素内容, ……});:数组构造。queue<元素类型> Q1 (Q);:复制构造。生成容器 \(Q\) 的独立复制品 \(Q1\) 。在此句之前,应当已定义过 \(Q\) 。
容量操作
int len=Q.size();:返回容器大小Q.empty():判断是否为空
元素操作
Q.push(元素内容):向头添加一个元素.Q.emplace(元素内容):向头添加一个元素。相较 \(push()\) 效率更高。Q.front();:返回头部元素。Q.back();:返回尾部元素。Q.pop():弹出队头元素。
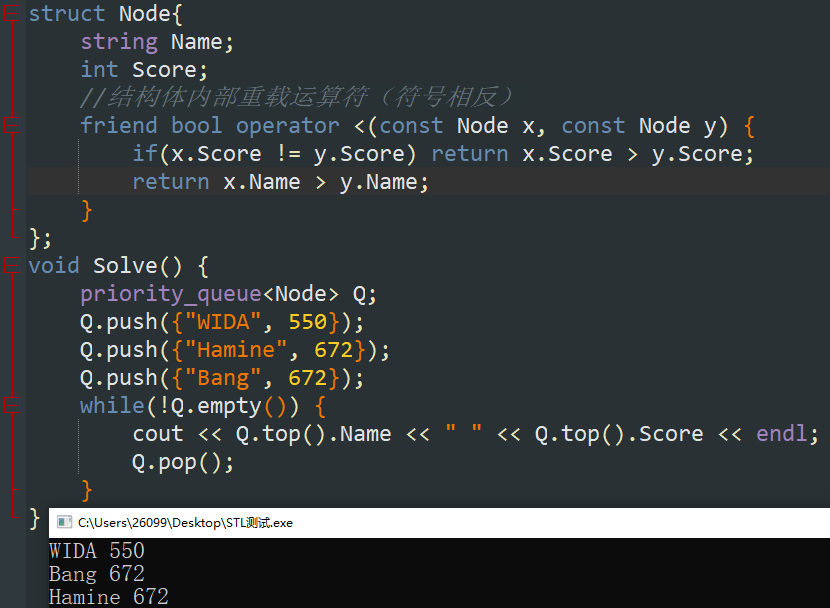
9. 容器适配器——优先队列 \(\tt{}priority\_queue\)
与普通队列 \(queue\) 不同的是, \(priority\_queue\) 是有序的,元素放入后会按照优先度(默认升序)进行排序。内置的 \(int\),\(string\) 类型本身就可以比较大小,若要使用自定义的结构体类型,则需要重载运算符 “<”。
构造函数
priority_queue<元素类型> P;:构造升序空容器priority_queue<int, vector<int>, less<int> > P;:内置升序排序。priority_queue<int, vector<int>, greater<int> > P;:内置降序排序。priority_queue<元素类型> P1 (P);:复制构造。
容量操作
int len=P.size();:返回容器大小P.empty():判断是否为空
元素操作
P.push(元素内容):向队首添加一个元素P.emplace(元素内容):向队首添加一个元素。相较 \(push()\) 效率更高。P.top();:返回队首元素。P.pop():弹出队首元素。
重载运算符
10. 序列式容器——双向队列 deque
可以看作是普通队列 \(queue\) 的加强版,双向队列可以对头尾元素快速地进行插入和删除操作。
像数组、 \(vector\) 容器一样,支持随机访问(即支持 [] 操作符和 at() 操作, \(O(1)\) ),但性能没有 \(vector\) 好,且相较于 \(vector\) 占用更多内存。
允许在内部进行插入和删除操作,但性能不及 \(list\) 。
构造函数
deque<元素类型> D;:构造空容器deque<元素类型> D (N, 元素内容);:数据构造。 \(D\) 容器初始含有 \(N\) 个相同元素。deque<元素类型> D ({元素内容, 元素内容, ……});:数组构造。在前面的元素会先被弹出。deque<元素类型> D1 (D);:复制构造。生成容器 \(D\) 的独立复制品 \(D1\) 。在此句之前,应当已定义过 \(D\) 。
容量操作
int len=D.size();:返回容器大小D.empty():判断是否为空
元素操作
D.pop_back(元素内容):弹出尾部元素。D.pop_front(元素内容):弹出头部元素。D.push_front(元素内容):向头添加一个元素。D.emplace_front(元素内容):向头添加一个元素。相较 \(push()\) 效率更高。D.push_back(元素内容):向尾添加一个元素。D.emplace_back(元素内容):向尾添加一个元素。相较 \(push()\) 效率更高。D.clear():清空。
11. 序列式容器——可变长度数组 \(\tt{}vector\)
相对普通数组, \(\tt{}vector\) 数组的长度不定,故对于随机数据,其内存占用会大大下降。
就CF日常赛来看,世界顶级大佬多数都是使用 \(\tt{}vector\) 数组来完全替代普通数组。大家也可以尝试逐步替代。
构造函数
vector<元素类型> V;:构造空容器。
vector<long long> Vvector<元素类型> V (N, 元素内容);:数据构造。初始含有 \(N\) 个相同元素,且初值给定。
vector<bool> V (10, true);vector<元素类型> V ({元素内容, 元素内容, ……});:数组构造。
-
vector<元素类型> V ({元素内容, 元素内容, ……});:数组构造。 -
vector<元素类型> V1 (V):复制构造。生成容器 \(V\) 的独立复制品 \(V1\)。在此句之前,应当已定义过 \(V\) 。 -
vector<元素类型> V2 (V.开始位置, V.结束位置);:范围复制构造。生成 \(V\) 容器 \([begin,end]\) 区间的独立复制品 \(V2\) 。 -
容量操作
-
int len = V.size();:返回容器大小。 -
V.empty();:判断容器是否为空。元素操作:插入
-
V.push_back(元素内容);:尾部插入。 -
V.emplace_back(元素内容);:尾部插入。相较 \(push\_back()\) 、 \(insert()\) 效率更高。 -
V.emplace(插入位置,元素内容);:在指定位置处插入。相较 \(push\_back()\) 、 \(insert()\) 效率更高。 -
V.insert(插入位置, 元素内容);:在指定位置处插入。 -
V.insert(插入位置, 重复数量, 元素内容);:在指定位置处插入 \(N\) 个相同元素。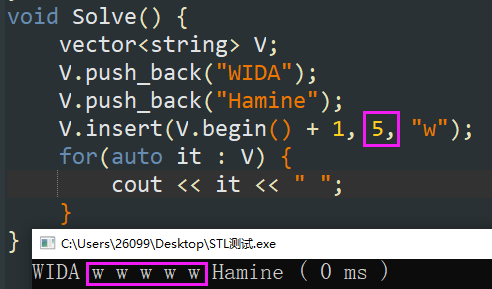
元素操作:读取
-
V.front():返回第一个元素,等价于*V.begin()和V[0]。 -
V.back():返回最后一个个元素,等价于*--V.end()和V[V.size()-1]。元素操作:删除
-
V.pop_back();:尾部删除。 -
V.erase(删除位置);:单点删除。删除指定位置处元素。 -
V.erase(删除位置1, 删除位置2);:区间删除。删除 \([begin,end]\) 区间的元素。 -
V.clear();:一键清空。
12. 字符串 string 容器
构造函数
string S;:构造空容器。string S (元素内容);:数据构造。string S1 (S);:复制构造。生成容器 \(S\) 的独立复制品 \(S1\)。在此句之前,应当已定义过 \(S\)。string S1 (S.开始位置, S.结束位置);:范围复制构造。生成 \(S\) 容器 \([begin,end]\) 区间的独立复制品 \(S2\) 。string S1 (S, 开始位置下标, 长度);:范围复制构造。生成字符串 \(S[pos,pos+len)\) 区间的独立复制品 \(S2\) 。S="xxx";:重赋值.
容量操作
-
int len=S.size();:返回容器大小。 -
int len=S.length();:返回容器大小。 -
S.empty();:判断容器是否为空。元素操作:插入
-
S.push_back(元素内容);:尾部插入单个字符。 -
S.insert(插入位置, 元素内容);:在指定位置处插入单个字符。 -
S.insert(插入位置下标, 元素内容);:在指定位置处插入字符串。 -
S.insert(插入位置, 重复数量, 元素内容);:在指定位置处插入 \(N\) 个字符。 -
S.append(元素内容);:将元素(字符串或字符)拼接到尾部。 -
S.append(重复数量, 元素内容);:将 \(N\) 个字符拼接到尾部。元素操作:删除
-
S.erase(删除位置);:单点删除。删除指定位置处字符。 -
S.erase(删除位置下标);:区间删除。删除指定位置及其之后的全部元素。 -
S.erase(删除位置1, 删除位置2);:区间删除。删除 \([begin,end]\) 区间的元素。元素操作:查找
-
int index=S.find(元素内容);:查找元素(字符串或字符),并返回第一次出现的下标。若不存在,返回字符串最大可开大小。 -
int index=S.find(元素内容, 开始位置下标);:从指定位置开始查找元素(字符串或字符),并返回第一次出现的下标。若不存在,返回字符串最大可开大小。 -
int index=S.rfind(元素内容);:逆序查找元素(字符串或字符),并返回第一次出现的正序下标。若不存在,返回字符串最大可开大小。 -
int index=S.rfind(元素内容, 开始位置下标);:从指定位置开始向前查找元素(字符串或字符),并返回第一次出现的正序下标。若不存在,返回字符串最大可开大小。元素操作:其他
-
sort(S.开始位置, S.结束位置);:对 \([pos1,pos2]\) 区间的元素快速排序。
13. 关联式容器——有序集合 set
\(set\) 容器基于红黑树,故其能时刻对数据自动排序(默认为升序),保证数据有序。搜索的时间复杂度仅为 \(Olog_2n\) ,十分的高效有用。
\(set\) 容器的第二个特点是其保证元素的唯一性,置入其中的元素会被自动去重。
除此之外,与 \(map\) 这种关联容器不同, \(set\) 容器只能对单点操作(不允许手写 S.begin()+3 这种涉及迭代器加减法的式子),故相较于前面的一些容器, \(set\) 容器少了非常多成员函数。请详细阅读下文介绍,并将其与其他容器相区分。
构造函数
set<元素类型> S;:构造空容器。set<元素类型,greater<> > S;:内置降序排序。set<元素类型> S ({元素内容, 元素内容, ……});:数组构造。set<元素类型> S1 (S):复制构造。生成容器 \(V\) 的独立复制品 \(V1\)。在此句之前,应当已定义过 \(V\)。
容量操作
int len=S.size();:返回容器大小。S.empty();:判断容器是否为空。
元素操作:插入
S.insert(元素内容);:尾部插入。时间复杂度为 \(O(log_2n)\)。S.emplace(元素内容);:尾部插入。相较 \(insert()\) 效率更高。
元素操作:删除
-
S.clear();:一键清空。 -
S.erase(迭代器);:单点删除。删除迭代器指向的元素。 -
S.erase(元素内容);:单点删除。 -
连续头部删除:使用滚动 \(\tt{}auto\ it\) 实现,如下例:
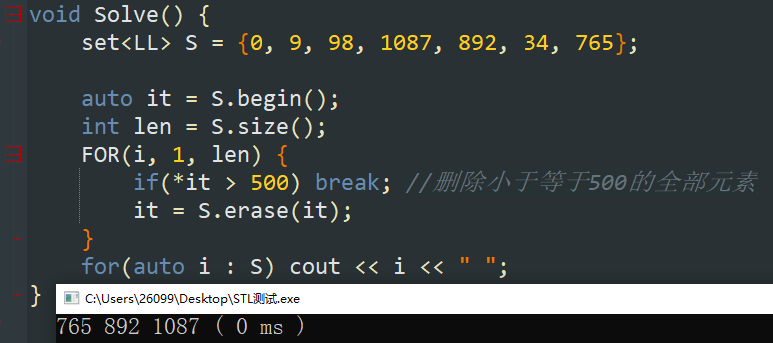
错误用法如下:
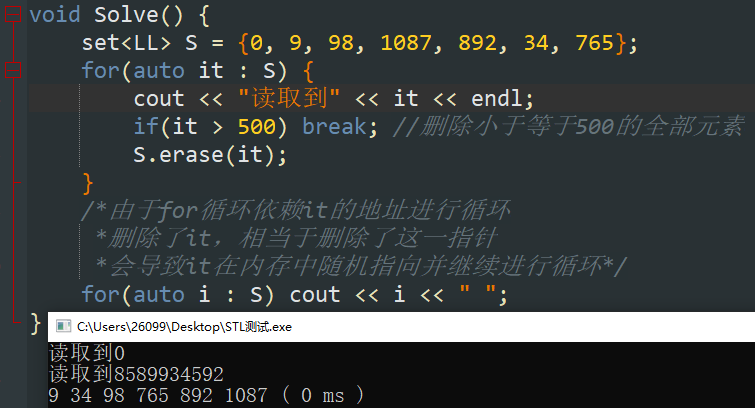
元素操作:查找
S.find(元素内容);:查找元素,并返回第一次出现时的迭代器。若不存在,返回 \(S.end()\)。S.rfind(元素内容);:逆序查找元素,并返回第一次出现时的迭代器。若不存在,返回 \(S.end()\)。S.lower_bound(元素内容);:返回第一个 \(\geqslant\) 目标元素的迭代器。S.upper_bound(元素内容);:返回第一个 \(>\) 目标元素的迭代器。
元素操作:读取
S.begin();:返回容器中最小元素的迭代器。S.end();:返回容器中最大元素的下一个位置的迭代器。
元素操作:其他
S.count(元素内容):查询容器中是否含有这一元素。S.swap(S1):容器元素互换。
迭代器
\(set\) 与 \(multiset\) 迭代器比较特殊,称之为“双向访问迭代器”,其不支持随机访问,仅支持 “++” 和 “--” 两个算术运算操作。如果将迭代器 it++ ,则 it 会指向经过排序之后的下一个元素,而非简单的遍历。这两个算术运算操作的时间复杂度均为 \(O(log_2n)\)。
自定义排序函数重载
struct cmp{
bool operator()(const int &a,const int &b){
return a>b;//按元素值降序排序
}
};
set <int,cmp> S;
14. 有序多重集合 multiset 容器
与普通集合 \(set\) 最大的不同是, \(multiset\) 不去重。
与 \(set\) 存在不同的函数
S.erase(元素内容):删除容器中所有目标元素。S.count(元素内容):返回容器中目标元素数量。
15. unordered_set 容器
注意:需要C++11及以上版本的编译器才支持这一函数
与普通集合 \(set\) 的不同是, \(unordered\_set\) 内部元素是无序的,且函数时间复杂度更低【平均可达 \(O(1)\) ,最坏为 \(O(n)\) 】,而相应的代价是会消耗较多内存。
在底层代码层面上,由于 \(unordered\_set\) 基于哈希表,不能直接和不带哈希函数的其他容器共用(如 \(vector\) ),对 \(vector\) 定义哈希函数代码如下:
namespace std {
template<>
struct hash<std::vector<int>> {
size_t operator()(const vector<int> &v) const {
std::hash<int> hasher;
size_t seed = 0;
for (int i : v) {
seed ^= hasher(i) + 0x9e3779b9 + (seed << 6) + (seed >> 2);
}
return seed;
}
};
}
int main(){
unordered_set<vector<int> > S;
return 0;
}
16. unordered_multiset 容器
注意:需要C++11及以上版本的编译器才支持这一函数
与普通集合 \(set\) 的不同是, \(unordered\_multiset\) 不排序、不去重。
17. bitset 容器
可以看作其为一个多位二进制数(对二进制进行状态压缩),这一容器将会把你的数据自动转换成二进制(每一位均为 \(0\) 或 \(1\) 的整数,而不是字符串)并进行进一步运算。一般来说,使用 \(bitset\) 容器可以是你的算法复杂度 \(/64\) (如果你的电脑是64位)。而对于评测机,这一理论值甚至可以减少到 \(/128\) 。
构造函数
\(bitset\) 容器可以接受仅带 \(0\) 和 \(1\) 的 \(string\) 类型和整数类型。
-
bitset<容器长度> B;:构造空容器。 -
bitset<容器长度> B (字符串);:基于您给出的字符串构造容器。 -
bitset<容器长度> B = 整型:基于您给出的整型构造容器。 -
bitset<容器长度> B (整型):基于您给出的整型构造容器。 -
应当注意的是,进入容器后会被倒序排列,并且会在高位补上 \(0\) 如
bitset<6> B = 8,数组 \(B[5]\) 至 \(B[0]\) 输出依次为0 0 0 1 0 0。容量操作
-
B.size();:返回容器大小(位数)。元素操作
-
~B:将容器内全部元素按位取反。 -
B.set():将所有位变 \(1\)。 -
B.set(下标内容):将指定位变 \(1\)。 -
B.set(下标内容, 元素内容):将指定位变指定内容。 -
B.reset():将所有位变 \(0\)。 -
B.reset(下标内容):将指定位置 \(0\)。 -
B.flip():将容器内全部元素取反。 -
B.filp(下标内容):对指定位置取反。 -
B.to_ulong():重新转换为 \(unsigned\ long\) 类型的结果,如果超出范围则报错。 -
B.to_ullong()重新转换为 \(unsigned\ long\ long\) 类型的结果,如果超出范围则报错 -
B.to_string()重新转换为 \(string\) 类型的结果,如果超出范围则报错。 -
[]:可以用于取值,也可以赋值。 -
B.count():返回有多少位为 \(1\)。位运算
除了上述提到的所有元素操作函数之外, \(bitset\) 还支持全部的位运算,但是需要位数相同。
举例如下:
int main(){
bitset<23>B1 (string("11101001"));
bitset<23>B2 (string("11101000"));
cout<<(B1 ^ B2)<<"\n";//按位异或
cout<<(B1 | B2)<<"\n";//按位或
cout<<(B1 & B2)<<"\n";//按位与
cout<<(B1 << 5)<<"\n";//左移5位
cout<<(B2 >> 5)<<"\n";//右移5位
cout<<(B1 == B2)<<"\n";//比较是否相等
return 0;
}
18. 关联式容器— \(\tt{}map\)
相较于普通数组, \(\tt{}map\) 容器允许你使用任何类型的数据作为下标。
与 \(\tt{}set\) 容器相同, \(\tt{}map\) 同样建立于红黑树之上,只能对单点操作,保证所有数据有序(默认按照下标升序排序),且保证不存在重复元素。查询时间复杂度为 \(\mathcal{O}log_2n\) 。
注意:一旦 \(map\) 中的一个元素被使用 [] 访问,无论此前是否被赋值,它都被视为已经存在。例如:使用 if(M["abc"]); 查询元素是否存在,则会被自动生成一个二元组 ("abc",zero),此时再使用 cout<<M.count("abc"); 答案是存在。时间一长,就会出现非常多“零值二元组”,白白占用了空间。强烈建议在使用 [] 访问前,先用 find() 方法检查key值的存在性
构造函数
map<下标类型, 元素类型> M;:构造空容器。map<下标类型, 元素类型> M3({{下标,元素},{下标,元素},{……}});:数组构造。map<下标类型, 元素类型> M1 (M);:复制构造。map<下标类型, 元素类型> M2 (M.开始位置, M.结束位置);:范围复制构造。
容量操作
int len=M.size();:返回容器大小M.empty():判断是否为空
元素操作:插入
注意:由于 \(\tt{}map\) 数组元素唯一性,在使用 \(\tt{}insert\) 进行插入操作时,若新的下标已经在容器内,则直接无视这次操作;而用数组的方式则可以。
-
M.insert({下标内容,元素内容});:使用花括号构建二元组插入(也支持 \(\tt{}pair\) ,此处略)。当下标重复时无法使用(如下图)。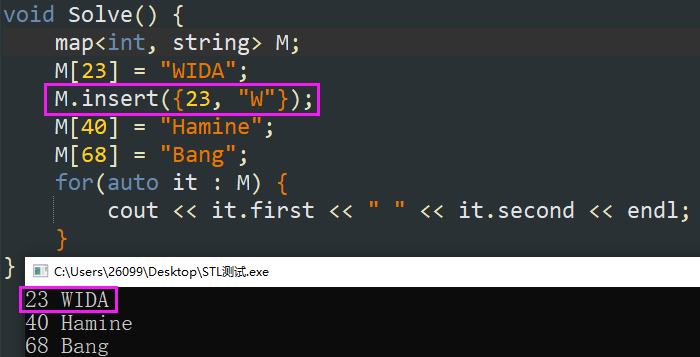
-
M.emplace(pair<下标类型, 元素类型>(下标内容,元素内容));:使用 \(\tt{}pair\) 插入,但不支持花括号构建二元组。相较 \(\tt{}insert()\) 效率更高。当下标重复时无法使用。
元素操作:直接修改
- 如同普通数组, \(\tt{}map\) 可以使用方括号 \([]\) ,该操作可以直接覆盖已有下标(与函数插入不同)。
元素操作:删除
-
M.earse(下标值);:通过下标删除元素。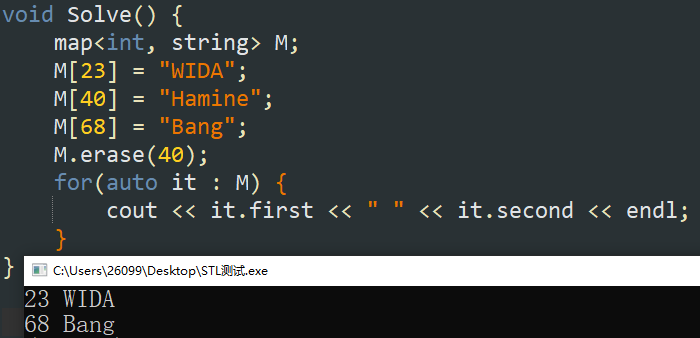
-
M.clear();:清空。
元素操作:查找
-
S.find(元素内容);:查找元素,并返回第一次出现时的迭代器。若不存在,返回结尾地址( \(\tt{}S.end()\) )。 -
S.rfind(元素内容);:逆序查找元素,并返回第一次出现时的迭代器。若不存在,返回结尾地址。 -
M.lower_bound(元素内容);:返回第一个 \(\geq\) 目标元素的迭代器。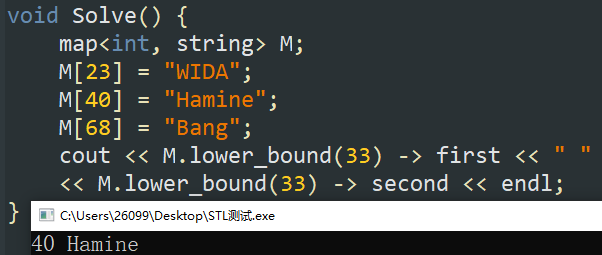
-
M.upper_bound(元素内容);:返回第一个 \(>\) 目标元素的迭代器。
元素操作:其他
M.count(元素内容):查询容器中是否含有这一元素。M.swap(M1);:容器元素互换。
迭代器
与 \(set\) 容器的迭代器一样,也是“双向访问迭代器”。
重载函数为按下标降序排序
struct cmp{
bool operator()(const int x,const int y){
return x>y;//按照下标值降序排列
}
};
map <int,char,cmp> M;
重载函数为按元素值大小排序
bool cmp_by_value(const PAIR &x, const PAIR &y) {
return x.second>y.second;//按元素值降序排列
//return x.second<y.second;//按元素值升序排列
}
sort(v.begin(), v.end(), cmp_by_value);
19. multimap 容器
与普通 \(map\) 的不同是, \(multimap\) 不去重。
20. unordered_map 容器
与普通 \(map\) 的不同是, \(unordered\_map\) 不排序,使用哈希实现。单次操作时间接近 \(\mathcal{O}(1)\) 。
21. unordered_multimap 容器
与普通 \(map\) 的不同是, \(unordered\_map\) 不排序、不去重。
22. STL算法——快速排序 sort
库自带的快速排序。可以使用 \(\tt{Lambda}\) 函数简化自定义函数,如下例,即达到了降序排序的效果。
vector<int> V(100);
for(auto &it : V) cin >> it;
sort(a.begin(), a.end(), [] (int x, int y) {
return x > y;
});
23. STL算法——查找有序序列的 lower_bound 和 upper_bound
其原理是在给定的范围内进行二分查找。与容器中的功能函数类似,区别在于增加了开始和结束参数,需要自己设定查找范围;且需要保证区间单调,默认为不下降序列。
若在数组中使用,为了得到数组下标而不是地址,在末尾需要减去起始位置。
因为查找区间是前开后闭的,当区间内全部内容全部相同时,使用 upper_bound() 会返回结束位置,有可能出现越界情况。
构造函数
lower_bound(开始位置, 结束位置, 元素内容):在[开始位置, 结束位置)区间内查找,返回第一个 \(\geq\) 目标元素的地址。upper_bound(开始位置, 结束位置, 元素内容):在[开始位置, 结束位置)区间内查找,返回第一个 \(>\) 目标元素的地址。
重载函数为小于、小于等于目标元素
lower_bound(begin, end, num, greater<type>())upper_bound(begin, end, num, greater<type>())
使用方法
cout<<lower_bound(a,a+n,x)-a<<endl;:在 \(a\) 数组中查找 \(x\) 第一次出现时的迭代器,如要得到下标,需要减去起始位置(即数组名字)。
常见玩法
upper_bound(a,a+n,k)-lower_bound(a,a+n,k):查找 \(k\) 在有序数组 \(a\) 中出现了几次
24. STL算法——全排列算法 next_permutation 和 prev_permutation
在提及这个函数时,我们先需要补充几点字典序相关的知识。
对于三个字符所组成的序列
{a,b,c},其按照字典序的6种排列分别为:
{abc},{acb},{bac},{bca},{cab},{cba}
其排序原理是:先固定a(序列内最小元素),再对之后的元素排列。而b<c,所以abc<acb。同理,先固定b(序列内次小元素),再对之后的元素排列。即可得出以上序列。
而 next_permutation 算法,即是按照字典序顺序输出的全排列;相对应的, prev_permutation 则是按照逆字典序顺序输出的全排列。可以是数字,亦可以是其他类型元素。其直接在序列上进行更新,故直接输出序列即可。
使用方法1:输出一组数据的全排列
#include<bits/stdc++.h>
using namespace std;
int a[4]={1,2,3,4};
int main(){
sort(a,a+4);//注意,此行的存在是为了保证输出完整的全排列,若只需要给定排序之后(或之前)的一部分,则删去此行。
do{
for(int i=0;i<4;i++) cout<<a[i]<<" ";
cout<<endl;
}while(next_permutation(a,a+4));
return 0;
}
使用方法2:输出一组数据的第 \(k\) 个排列
#include<bits/stdc++.h>
using namespace std;
int a[7]={1,2,3,4,5,6,7},k,num;
int main() {
sort(a,a+7);
cin>>k;
do{
if(num==k){
for(int i=0;i<7;i++) cout<<a[i]<<" ";
cout<<endl;
break;
}
num++;
}while(next_permutation(a,a+7));
return 0;
}
25. STL算法——数组反转函数 reverse、随机打乱函数 random_shuffle
将一个数组、顺序容器中的全部元素反转、打乱。
使用方法
reverse(a, a+n);:反转数组。reverse(V.begin(), V.end());:反转 \(vector\) 容器内的数据。
26. STL算法——数组去重函数 unique
此函数在使用前,需确保对象已经排序。
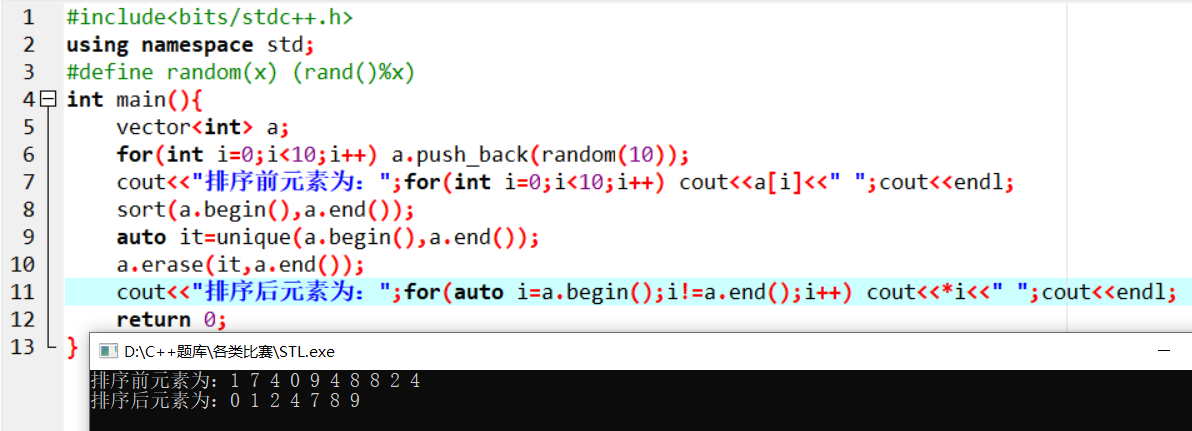
其作用是,对于区间 [开始位置, 结束位置) ,不停的把后面不重复的元素移到前面来,也可以说是用不重复的元素占领重复元素的位置。并且返回去重后容器中不重复序列的最后一个元素的下一个元素。所以在进行操作后,数组、容器的大小并没有发生改变。
参见下方图片:
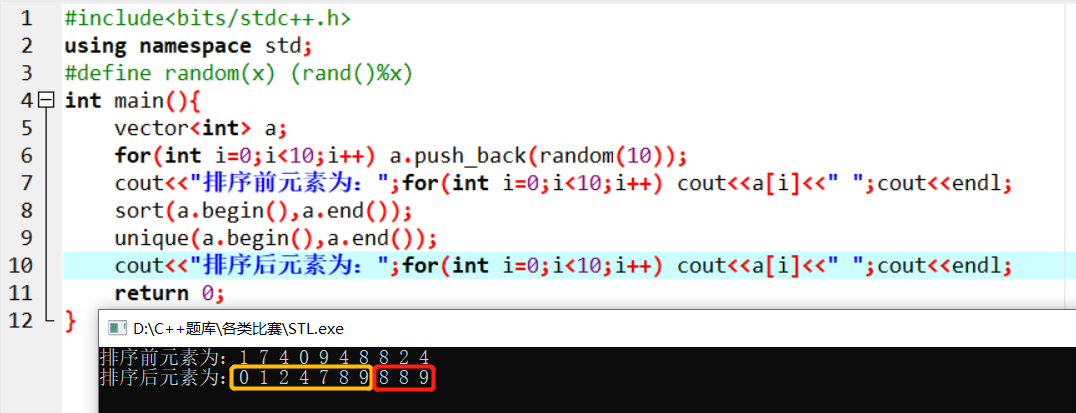
使用方法
unique(a, a+n);:对数组去重。unique(V.begin(), V.end());:对 \(vector\) 容器内的数据去重。
常见玩法
可以将 \(unique\) 函数和 \(earse\) 函数相结合,达到完全删去重复元素的目的,如下方代码
auto it=unique(V.begin(), V.end());
V.erase(it,V.end());
27. C++位运算函数——_builtin
GCC提供了一系列的builtin函数,可以实现一些简单快捷的功能来方便程序编写。
使用方法
__builtin_popcount(unsigned int x):返回二进制下 \(1\) 的个数。int n = 15; //二进制为1111 cout<<__builtin_popcount(n)<<endl;//输出4__builtin_ffs(unsigned int x):返回二进制下最后一个 \(1\) 的位置(从1开始计算)。int n = 1;//1 int m = 8;//1000 cout<<__builtin_ffs(n)<<endl;//输出1 cout<<__builtin_ffs(m)<<endl;//输出4__builtin_ctz(unsigned int x):返回二进制下后导 \(0\) 的个数(当x为0时,和x的类型有关)。int n = 1;//1 int m = 8;//1000 cout<<__builtin_ctzll(n)<<endl;//输出0 cout<<__builtin_ctz(m)<<endl;//输出3
注:以上函数的 \(long\ long\) 版本只需要在函数后面加上 ll 即可, \(unsigned\ long\ long\) 同理。
28. 字符串转换为数字函数——sto
【C++11】C++11提供了一些新的字符串转换函数,可以快捷的将一串字符串转换为指定进制的数字。
使用方法
stoi(字符串, 0, x进制):将一串 \(x\) 进制的字符串转换为 \(int\) 型数字。
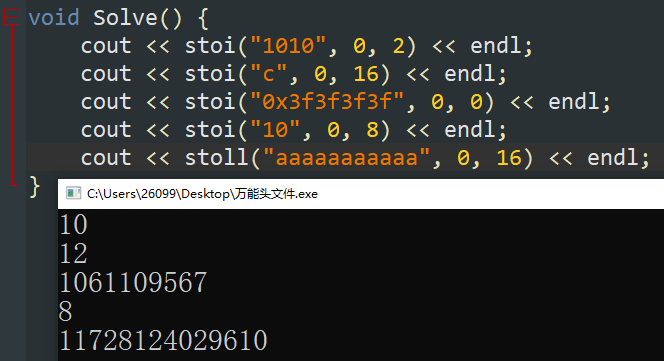
stoll(字符串, 0, x进制):将一串 \(x\) 进制的字符串转换为 \(long\ long\) 型数字。- stoull,stod,stold同理。
附录:参考
[1]. Bitset用法小结
[2]. pair常见用法详解
[3]. C++11中emplace的使用
[4]. C++11新特性emplace操作
[5]. 关于lower_bound( )和upper_bound( )的常见用法
[6]. 【用法总结】C++ STL中 next_permutation函数的用法
[7]. C++ reverse函数的用法
[8]. C++STL中的unique函数解析
[9]. c++高效位运算函数之 _builtin
[10]. [洛谷日报第79期]二进制与位运算
[11]. c++中的atoi()和stoi()函数的用法和区别
本文尚处于施工修改中,各位过路的大佬神犇,若有任何的批评建议,欢迎于站内私信或各大社交媒体平台向我反馈,感激不尽!
文 / WIDA
2022.02.??优化了全文框架,增加了一定的图片样例
2022.01.17优化了 \(\tt{stoi()}\) 的内容
2021.12.18修改了bitset容器的部分内容
2021.11.06新增位运算函数builtin
2021.11.04修改部分内容
2021.09.05修改部分内容
2021.08.18成文
首发于WIDA个人博客,仅供学习讨论

 浙公网安备 33010602011771号
浙公网安备 33010602011771号