Spark复习重点
Spark
用于大规模数据集处理的统一分析引擎(分布式计算框架)
快速、分布式、可扩展、容错的集群计算框架
基于内存计算的大数据分布式计算框架
具有MapReduce具有的优点,但不同于MapReduce
Spark底层源码是scala
.scala 编译后生成为 .class文件 运行在JVM
object Hello{
def main(args:Array[String]):Unit = {
println("hello")
}
}
//Unit :没有返回值,相当于VOID
scala基础语法
- 末尾符号:分号 ; 是可选的,建议不添加分号
- 区分大小写:scala是大小写敏感的,意味着Hello和hello在scala中会有不同的含义
- 类名:方法名称的第一个字母小写
- 引用:在scala中的引用: import scala.util._ //_代表该包下的所有类
scala中的基本数据类型:Byte Int Float Char Double Long Short Boolean
scala与java的基本数据类型不同
scala中变量与常量
变量:定义之后,值可以改
常量:定义之后,值不可更改
scala中定义常\变量:
var 变量名称:[数据类型] = 值
val 常量名称:[数据类型] = 值
scala语法:yield/break
yield 在for后面指定一个表达式,遍历的每个元素都执行这个表达式,返回一个集合
object ForDemo {
def main(args:Array[String]):Unit ={
val a = 1 to 20
val list = for(i<-a if i%2==0 if i<=10) yield i*2
println(list) //(4,8,12,16,20)
中止循环需要声明Break对象
val loop = new Breaks() loop.break()
scala语法:可变长参数
数据类型后面紧跟一个*
object MethodDemo{
def main(args:Array[String]):Unit = {
addInt(1)
addInt(1,2,3)
addInt(1,2,3,4,5)
}
def addInt(a:Int*):Unit = {
var sum =0
for (i<-a){
sum+=a
}
println(sum)
}
scala语法:数组
- 定长数组Array
声明后长度不能再改变
val a1 = new Array[String](3) a1(0)= a1(1)= a1(2)=
//更简便的方式
val a2 = Array(1,2,3,4,5)
数组常用操作方法
- head 取数组中第一个元素(下标为0)
- last取数组中最后一个元素
- init取数组中除了最后一个元素以外其他的元素
- tail取数组中除了第一个元素以外的其他元素
- mkString()将数组转成字符串
- isEmpty判断是否为空
- length 获取数组长度
- sum 数组中所有元素和
- min 取数组中最小的元素
- max 取数组中最大的元素
val a1 = Array(1,2,3,4,5)
println(a1.tail.mkString("(",",",")"))
println(a1.init.mkString("-"))
println(a1.length)
println(a1.isEmpty)
println(a1.sum)
println(a1.min)
println(a1.max)
- 不定长数组 ArrayBuffer
声明之后,数组的长度是可变的
- concat:合并相同数据类型的数组
import scala.Array._
val a1 = Array(1,2,3)
val a2 = Array(4,5,6)
val ints:Array[Int] = concat(a1,a2)
println(ints.mkString(","))
- fill(n)(element):返回数组,长度由第一个参数指定,同时第二个参数指定数组中的值
val a1 = fill(3)(10) //res : (10,10,10)
- ofDim[T](n,n) 创建二维数组,参数的第一个值指定外层数组的长度,参数第二个值指定内层数组的长度
scala语法:List列表
- 声明不可变列表
val list1 = List[Int](1,2,3,4,5)
val list2 = List[String]("222","111")
val list3 = List(1,"dasd",true)
- Nil 空列表
val list1 = 2::3::4::Nil val list2 = 5::6::7::list1 println(list2)
scala语法:元组Tuple
包含不同类型的元素,元组的最大长度为22
- 声明元组
val t2 = new Tuple1("jack","jerry",23,true)
- 取值
val t3 = new Tuple2("jack","jerry")
println(t3._2) //在元组中取值,_n代表取第几个元素,n从1开始
println(t3._1)
scala语法:Iterator迭代器
- toIterator 转换为迭代器
- hasNext 判断是否有元素
- next() 取出元素
object IteratorDemo{
def main(args:Array[String]):Unit = {
val list = List(1,2,3,4).toIterator()
while(list.hasNext()) //hasNext()判断是否有元素
{
println(list.next()) //next取出元素
}
}
}
scala语法:面向对象
- 通过class来定义一个类
object Demo {
def main(args:Array[String]):Unit = {
val person = new Person
person.name = "jack"
println(person.age)
person.say()
}
}
class Person{
var name:String = _ //代表占位符,1.变量必须是var声明 2.声明变量时必须指定类型
val age:Int = 20
def say(): Unit = {
println(name+","+age)
}
}
- 伴生对象和伴生类
满足两个条件:
伴生对象和伴生类必须在同一源码文件下
伴生对象和伴生类必须同名
作用:伴生类和伴生对象可以互相访问对方的私有成员
object Demo {
def main(args:Array[String]):Unit = {
Person.run()
}
}
class Person {
private val name:String = "jack"
private def say():Unit = {
println(name+","+Person.age)
}
}
object Person{
private val age = 20
val person = new Person
def run():Unit = {
println(person.name)
person.say()
}
}
- 构造器
scala类的构造分为:主构造和辅助构造
一个类中只能有一个主构造,可以有多个辅助构造方法
主构造方法和类交织在一起
辅助构造通过this关键字定义,辅助构造的第一行代码必须调用主构造或其他辅助构造
//主构造案例
object Demo {
def main(args:Array[String]):Unit ={
val person = new Person("jack","age")
}
}
class Person(name:String,age:Int) //主构造和类交织在一起
{
println("创建了Person对象") //只要通过new来实例化对象肯定会调用构造
}
//辅助构造案例
object Demo {
def main(args:Array[String]):Unit ={
val person = new Person("jack","age","SDJN","bigdata")
}
}
class Person(name:String,age:Int) //主构造和类交织在一起
{
println("1.创建了Person对象") //只要通过new来实例化对象肯定会调用构造
def this(name:String,age:Int,addr:String){
this(name,age)
println("2.创建了Person对象")
}
def this(name:String,age:Int,addr:String,major:String)
{
this(name,age,addr)
println("3.创建了Person对象")
}
}
- 样例类
通过case定义类的叫做样例类,一般没有类的实体
case class Person(name:String,age:Int,sex:String,major:String) //封装数据
Spark集群环境
Spark是用于大规模数据集处理的统一分析引擎
特点:快速、易用、通用性、运行在任何地方、简洁
Spark架构
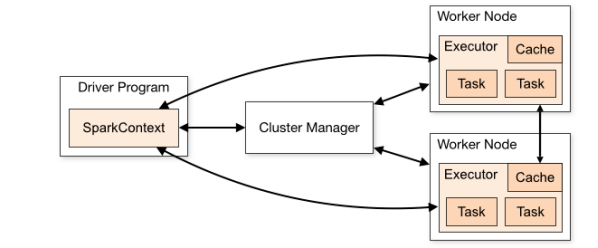
- Spark应用程序作为独立进程集合运行在集群上
- 驱动程序中包含一个SparkContextu对象协调进程
- SparkContext会连接集群管理器(Spark自带的Standalone、Yarn、Mesos)
- 当SparkContext连接到集群管理器时,Spark程序在集群的Nodes节点上启动Executor进程
- Executors是计算和存储应用程序数据的进程
Spark的运行模式
local模式:Spark运行在本地上,不需要搭建Spark和Yarn集群
Spark on Standalone : 集群管理器是Standalone,应用程序运行在Spark集群上
Spark on Yarn:集群管理器是Yarn,应用程序运行在Yarn集群上
Spark中的术语
Driver program 运行应用程序的main()函数并且创建SparkContext的过程
Cluster manager 用于在集群上获取资源的外部服务 *主节点
Deploy mode 区分驱动进程所在的位置,分为cluster模式和client模式
Executor 工作节点上的应用程序启动的进程,该进程运行任务并将数据跨任务存储在内存或磁盘上,每个应用程序都有自己的执行程序
Task 一种工作单元,将发送给一个执行者
SparkContext
通常而言,用户开发的Spark应用程序的提交、执行和输出都是通过SparkContext完成的,在正式提交application之前,需要先初始化SparkContext。
DAGScheduler负责创建Job,将DAG中的RDD划分到不同的Stage,给Stage创建对应的Task,将Task批量提交给TaskScheduler等功能。
TaskScheduler负责按照FIFO或者FAIR等调度算法对批量的Task进行调度,为Task分配资源,将Task发送到集群管理的当前应用程序的Executor,由其负责执行Task。
- SparkContext是Spark应用程序的入口点。
- SparkContext会连接Spark集群。
- SparkContext会创建RDD、累加器、广播变量
- 在JVM中激活状态的SparkContext只能有一个。
Spark编程
RDD
RDD叫做弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面元素可并行计算的集合。
五大属性:
- 分区列表,RDD中包含很多分区
- 每个算子作用在每个分区上
- 一个RDD有一系列的依赖,依赖其他的RDD
- 可选的,对key-value对的RDD可进行分区
- 可选的,移动数据不如移动计算
RDD的创建方式
- parallelizing 把集合转换为RDD
val conf = new SparkConf().setMaster("local").setAppName("wordcount")
val sc = new SparkContext(conf)
val list = List(1,2,3,4,5)
val listRDD:RDD[Int] = sc.parallelize(list,3) //3指定分区数量,不指定则使用默认分区数量
listRDD.foreach(println)
sc.stop()
- 从外部存储创建RDD
val fileRDD:RDD[String] = sc.textFile(path)
RDD的算子
算子分为转换算子与行动算子
转换算子:由一个RDD经过算子之后转换成了一个新的RDD
行动算子:由一个RDD生成了一个scala集合或者对象
- 常用转换算子
map算子
object TransformationDemo{
def main(args:Array[String]):Unit = {
val conf = SparkConf().setMaster().appName()
val sc = SparkContext(conf)
mapDemo(sc)
sc.stop()
}
def mapDemo(sc:SparkContext):Unit = {
val list = List(1,2,3,4,5)
val listRDD = sc.parallelize(list)
listRDD.map(_*2).foreach(println)
}
}
---*************************************************************---
val a = sc.parallelize(List("dog","salmon","salmon","rat","elephant"),3)
val b = a.map(_.length)
val c = a.zip(b)
c.collect
//res0: Array[(String, Int)] = Array((dog,3), (salmon,6), (salmon,6), (rat,3), (elephant,8))
filter算子
val a = sc.parallelize(1 to 10,3)
val b = a.filter(_%2==0)
b.collect
def reduceByKeyDemo(sc:SparkContext):Unit ={
//qq-win10-山东省-xxx-xxx
val fileRDD:RDD[String] = sc.textFile(path)
fileRDD.map(x=>((x.split("-")(2),1))).reduceByKey(_+_).filter(x=>(x._2>300)).foreach(println)
reduceByKey算子
val a =sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), 2)
val b = a.map(x=>(x.length,x))
b.reduceByKey(_+_).collect
//res87: Array[(Int, String)] = Array((4,lion), (3,dogcat), (7,panther), (5,tigereagle))
sortBy算子
//qq-win10-山东省-xxx-xxx
val fileRDD:RDD[String] = sc.textFile(path)
fileRDD.map(x=>(x.split("-")(2),1))).reduceByKey(_+_).filter(x=>(x._2>300)).sortBy(_._2,false).foreach(println)
//默认为升序,true为升序,false为降序
flatMap算子
val a = sc.parallelize(1 to 10, 5) a.flatMap(1 to _).collect //res47: Array[Int] = Array(1, 1, 2, 1, 2, 3, 1, 2, 3, 4, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5, 6, 7, 1, 2, 3, 4, 5, 6, 7, 8, 1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10) sc.parallelize(List(1, 2, 3), 2).flatMap(x => List(x, x, x)).collect //res85: Array[Int] = Array(1, 1, 1, 2, 2, 2, 3, 3, 3)
- 常用行动算子
reduce算子
def collectDemo(sc:SparkContext):Unit = {
val list = List(1,2,3,4,5)
val listRDD = sc.parallelize(list)
val ints:Int = listRDD.reduce(_+_)
println(ints)
}
//collect返回为数组
collect算子
def collectDemo(sc:SparkContext):Unit = {
val list = List(1,2,3,4,5)
val listRDD = sc.parallelize(list)
val ints:Array[Int] = listRDD.collect()
println(ints.mkString("-"))
}
//collect返回的是数组
count()算子
def collectDemo(sc:SparkContext):Unit = {
val list = List(1,2,3,4,5)
val listRDD = sc.parallelize(list)
val ints:Int = listRDD.count()
println(ints)
}
//返回数据集中元素的数量
take算子
def collectDemo(sc:SparkContext):Unit = {
val list = List(1,2,3,4,5)
val listRDD = sc.parallelize(list)
val ints:Array[Int] = listRDD.take(3) //返回数据集中前3个数据组成的数组
ints.foreach(println)
}
saveAsTextFile()算子
向Windows磁盘写数据时:saveAsTextFile("file:///xxxxxxxxxxx")
向HDFS中写数据时:saveAsTextFile("hdfs://ip:port/xxx")
实例:计算每个学生的平均成绩
张三,hadoop,78 张三,hbase,80 张三,spark,88 李四,hadoop,89 李四,hbase,82 李四,spark,99 王五,hadoop,96 王五,hbase,84 王五,spark,70 赵六,hadoop,67 赵六,hbase,86 赵六,spark,77
object Avgall{
def main(args:Array[String]):Unit = {
val conf = SparkConf().setMaster().appname()
val sc = SparkContext(conf)
val fileRDD = sc.textFile(path)
fileRDD.map(_.split(",")).map(x=>(x(0),x(2))).groupByKey().map(x=>(x._1,x._2.sum/x._2.size)).sortBy(_._2,false).take(2)\
sc.saveAsTextFile()
sc.stop()
}
}
RDD的依赖
RDD依赖分为两种:宽依赖,窄依赖
宽依赖:每个父RDD的Partition最多被子RDD的一个Partition使用
窄依赖:一个父RDD的Partition会被多个子RDD的Partition使用
Stage划分
阶段的划分就是看有没有宽依赖,如果有,就会分为一个Stage
SparkSQL
SparkSQL是一个用于处理结构化数据的Spark组件
具有的特性:
1.集成性
2.统一的数据访问
3.集成Hive
4.标准的连接
- SparkSession
SparkSQL中所有功能的入口点是SparkSession类
- DataFrame API的使用
在一个SparkSession中,应用程序可以从一个已经存在的RDD,hive表,外部数据库,Spark数据源中创建一个DataFrame
val spark:SparkSession = SparkSession.builder().setMaster().appname().getOrCreate() val pDF:DataFrame = spark.read.json(path) pDF.show() spark.stop()
- 通用的读取数据的方法
spark.read.format("").load(path)
//format参数为想要设置的读取文件类型
//path为读取路径
查询操作
pDF.select($"site",$"month",$"value").show()
pDF.select($"site",$"month",$"value").groupBy("month").count().show()
//统计月份出现的次数
pDF.select.($"site",$"month",$"value").groupBy("month").count().sort(desc("count")).show()
//倒叙排序输出
pDF.select.($"site",$"month",$"value").where($"value">650).show()
//条件输出
DF创建表操作
val pmDF = spark.read.option("header","true").csv(path)
pmDF.createOrReplaceTempView("pmTable")
spark.sql("select site,month,value from pmTable where value>650").show()
SparkSQL数据源
SparkSQL通过DataFrame接口支持对各种数据源(text,json,csv,jdbc,hive表,parquet,avro)进行操作,可使用行动算子操作DataFrame,也可以用于创建临时视图,将DataFrame注册为临时视图后可对其数据进行SQL查询。
获取数据源的方法
SparkSession.read.load(path) //默认读取的parquet文件
SparkSession.read.format().load() //指定读取模式
SparkSession.read.csv()/json()/text()/jdbc()
保存数据的方法
DataFrame.write.save() //默认存储为parquet文件
DataFrame.write.format().save() //指定写入模式
DataFrame.write.csv()/json()/text()/jdbc()
数据库操作
object JDBCDemo {
def main(args:Array[String]):Unit ={
val spark = SparkSession.builder().master().appname().getOrCreate()
val jdbcDF = spark.read.format("jdbc")
.option("url","jdbc:mysql://192.168.100.100:3306")
.option("dbtable","spark.t_user")
.option("user","root")
.option("password","root")
.load()
jdbcRDD.show()
//从数据库中读取数据
//从外部读取数据,写入数据库
val filterDF = jdbcDF.select().where()
//向数据库中写数据
filterDF.write.format("jdbc")
.option("url","jdbc:mysql://192.168.100.100:3306")
.option("dbtable","spark.t_user")
.option("user","root")
.option("password","root")
.save()
spark.stop()
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号