Python Selenium、PIL、pytesser 识别验证码
思路:
- 使用Selenium库把带有验证码的页面截取下来
- 利用验证码的xpath截取该页面的验证码
- 对验证码图片进行降噪、二值化、灰度化处理后再使用pytesser识别
- 使用固定的账户密码对比验证码正确或错误的关键字判断识别率
1. 截取验证码
def cutcode(url,brower,vcodeimgxpath): #裁剪验证码 picName = url.replace(url,"capture.png") #改为.png后缀保存图片 brower.get(url) brower.maximize_window() #放大 brower.save_screenshot(picName) #截取网页 imgelement = brower.find_element_by_xpath(vcodeimgxpath) # 通过xpath定位验证码 location = imgelement.location # 获取验证码的x,y轴 size = imgelement.size # 获取验证码的长宽 rangle = (int(location['x']), \ int(location['y']), \ int(location['x'] + size['width']), \ int(location['y'] + size['height'])) # 写成我们需要截取的位置坐标 i = Image.open(os.getcwd()+r'\capture.png') # 打开截图 verifycodeimage = i.crop(rangle) # 使用Image的crop函数,从截图中再次截取我们需要的区域 verifycodeimage.save(os.getcwd()+r'\verifycodeimage.png') return brower
2. 对验证码图片进行降噪、二值化、灰度化处理并识别
def initTable(threshold=140): #降噪,图片二值化 table = [] for i in range(256): if i < threshold: table.append(0) else: table.append(1) return table def recode(): image=Image.open(os.getcwd()+r'\verifycodeimage.png') image = image.convert('L') #彩色图转换为灰度图 binaryImage = image.point(initTable(), '1') #将灰度图二值化 time.sleep(1) vcode=image_to_string(binaryImage) #使用image_to_string识别验证码 vcode = vcode.strip() return vcode
3. 通过点击登录按钮返回的信息判断验证码是否识别正确
def login(vcode,brower,usernamexpath,passwordxpath,vcodexpath,submitxpath,username,password): brower.find_element_by_xpath(usernamexpath).send_keys(username) brower.find_element_by_xpath(passwordxpath).send_keys(password) # 对文本框输入验证码值 brower.find_element_by_xpath(vcodexpath).send_keys(vcode) time.sleep(1) # 点击登录,sleep防止没输入就点击了登录 brower.find_element_by_xpath(submitxpath).click() # 等待页面加载出来 time.sleep(1) result = brower.page_source #获取页面的html return result
4. 接收识别验证码需要的参数,循环识别验证码
def main(): file_path = raw_input("param.txt path:") username = raw_input("username(default 'admin'):") password = raw_input("password(default '123456'):") codeerror = raw_input("vcode error key word in html(default '验证码错误'):") passerror = raw_input("vcode pass key word in html(default '密码错误'):") frequency = raw_input("How many time(default '100'):") vcodelen = raw_input("How many characters(default '4'):") remod = raw_input("choose remod(default:en+num,1:num,2:en):") starttime = datetime.datetime.now() txt = open(file_path) #txt中需要的参数:url usernamexpath passwordxpath vcode_input_xpath vcode_image_xpath submit_xpath lines = txt.readlines() url = lines[0].split("=",1)[1] usernamexpath = lines[1].split("=",1)[1] passwordxpath = lines[2].split("=",1)[1] vcodexpath = lines[3].split("=",1)[1] vcodeimgxpath = lines[4].split("=",1)[1] submitxpath = lines[5].split("=",1)[1] brower = webdriver.PhantomJS(executable_path=r'D:\Python27\PY\phantomjs-2.1.1-windows\bin\phantomjs.exe') #打开phantomjs.exe if username == '': username = "admin" if password == '': password = '123456' if codeerror == '': codeerror = u"验证码错误" #验证码错误时的关键字 else: codeerror = codeerror.decode(sys.stdin.encoding) #识别为Unicode自动转换 if passerror == '': passerror = u"密码错误" #验证码正确时的关键字 else: passerror = passerror.decode(sys.stdin.encoding) #识别为Unicode自动转换 if vcodelen == '': vcodelen = 4 else: vcodelen = int(vcodelen) if remod == '1': remod = '^[0-9]+$' elif remod == '2': remod = '^[A-Za-z]+$' else: remod = '^[A-Za-z0-9]+$' counterror = 0 countture = 0 if frequency == '': frequency = 100 else: frequency = int(frequency) a = 0 while a < frequency: brower = cutcode(url,brower,vcodeimgxpath) vcode = recode() if len(vcode) != vcodelen: #识别到的验证码长度不为4直接重新循环 continue if re.match(remod,vcode): #判断识别到的验证码是否只有字母加数字 result = login(vcode,brower,usernamexpath,passwordxpath,vcodexpath,submitxpath,username,password) if codeerror in result: print "[-]验证码错误"+vcode counterror += 1 elif passerror in result: print "[+]验证码正确"+vcode countture += 1 else: continue else: continue a += 1 os.remove(os.getcwd()+r'\verifycodeimage.png') os.remove(os.getcwd()+r'\capture.png') brower.close() #关闭浏览器 #把数字转换为str再print rat = str('%.3f%%' % (countture/frequency*100)) countture = bytes(countture) counterror = bytes(counterror) endtime = datetime.datetime.now() runtime = str((endtime-starttime).seconds/3600*60) print "[+]验证码正确次数:"+countture print "[-]验证码错误次数:"+counterror print "[+]识别率:"+rat print "运行时间:"+runtime+"min" if __name__ == '__main__': main()
这种方法识别验证码的效率比较低,但是因为写这个代码要识别的网站的验证码url打开时空白、空白的!然后想到这种方法虽然是效率比较低,但是适用性还是较广的,毕竟可以模拟人为操作浏览器。
然后有个缺点就是识别全数字的验证码正确率奇低==因为处理完验证码图片后数字就会变得有缺失==
如果说运行的过程中xpath的value出现问题了,有可能是网页还没加载出来就已经被截图了(xpath直接在网页上右键检查元素,然后再那个html代码里右键复制xpath就好了)
param.txt的demo(=与路径中间不要有空格!!):
url = username_xpath =//*[@id="txtUserName"] password_xpath =//*[@id="txtPassword"] vcode_input_xpath =//*[@id="txtValCode"] vcode_image_xpath =//*[@id="imgVerify"] submit_xpath =//*[@id="Button1"]
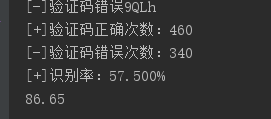
一开始写这个打算识别的目标站,只有57识别率==然后效率很低==毕竟不用自己写算法识别什么的。代码的排布什么的也挺烂的,不要介意啦==:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号