Task01:论文数据统计
- 学习主题:论文数量统计,统计2019年全年,计算机各个方向的论文数量。
- 涉及到的知识点:jupyter notebook中安装库;json文件的读取;列表推导式;爬虫;正则表达式
01 安装conda
conda分为anaconda和miniconda。
下载地址
miniconda官网:https://conda.io/miniconda.html
- 添加频道
1、官方频道
conda config --add channels bioconda
conda config --add channels conda-forge
2、清华频道
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
- 在jupyter notebook 中直接安装第三方库
进行pip install 对应第三方库名
02 任务说明
- 任务主题:论文数量统计,即统计2019年全年计算机各个方向论文数量;
- 任务内容:赛题的理解、使用 Pandas 读取数据并进行统计;
- 任务成果:学习 Pandas 的基础操作;
- 可参考的学习资料:开源组织Datawhale joyful-pandas项目
03 代码说明
导入package并读取原始数据
# 导入所需的package
import seaborn as sns #用于画图
from bs4 import BeautifulSoup #用于爬取arxiv的数据
import re #用于正则表达式,匹配字符串的模式
import requests #用于网络连接,发送网络请求,使用域名获取对应信息
import json #读取数据,我们的数据为json格式的
import pandas as pd #数据处理,数据分析
import matplotlib.pyplot as plt #画图工具
import json
import time
导入数据
# 读取json文件内容,返回字典格式
json_filename='D:/BaiduNetdiskDownload/archive/arxiv-metadata-oai-snapshot.json'
data=[]
with open(json_filename,'r',encoding='utf8') as f:
for idx,line in enumerate(f):
#print(idx)
#print(line)
#if(idx>=2000):
#break
data.append(json.loads(line))

data=pd.DataFrame(data)
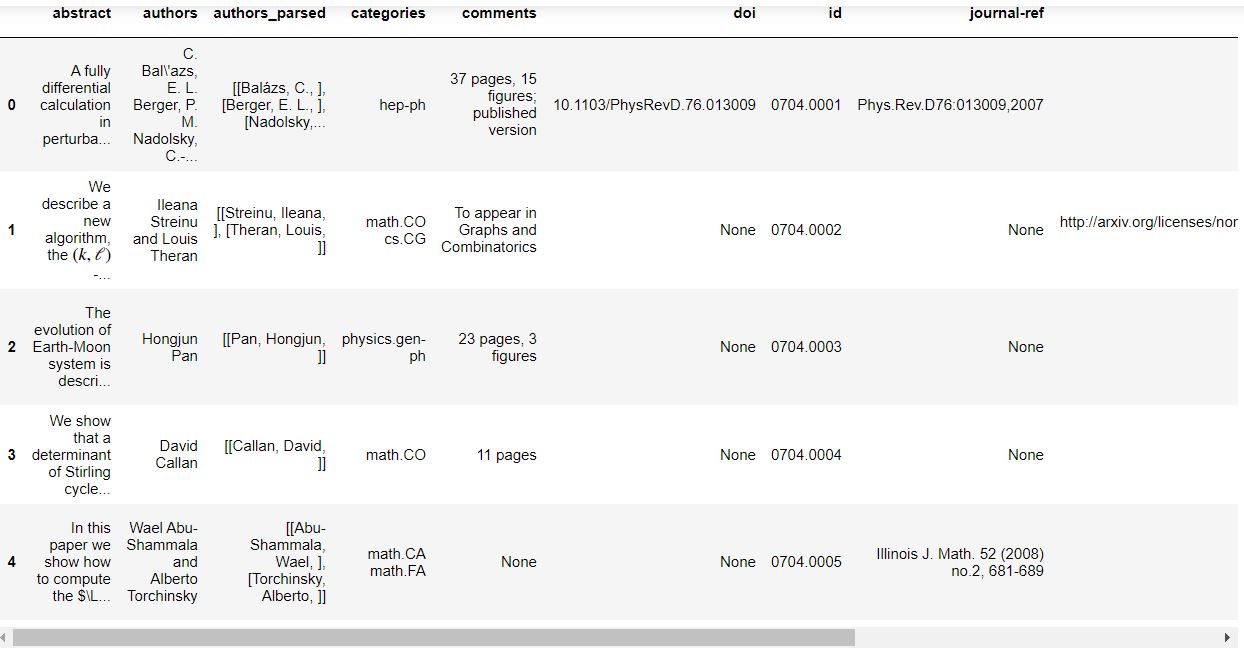
print(data)

data.head()
'''
count:一列数据的元素个数;
unique:一列数据中元素的种类;
top:一列数据中出现频率最高的元素;
freq:一列数据中出现频率最高的元素的个数;
'''
data["categories"].describe()

由于部分论文的类别不止一种,所以下面我们判断在本数据集中共出现了多少种独立的数据集。
# 所有的种类(独立的)
start=time.time();
unique_categories = set([i for l in [x.split(' ') for x in data["categories"]] for i in l])
end=time.time()
len(unique_categories)
unique_categories


data['year'] = pd.to_datetime(data['update_date']).dt.year #将update_date从例如2019-02-20的str变为datetime格式,并提取处year
del data['update_date'] #删除 update_date特征,其使命已完成
data = data[data['year'] >= 2019] #找出 year 中2019年以后的数据,并将其他数据删除
# data.groupby(['categories','year']) #以 categories 进行排序,如果同一个categories 相同则使用 year 特征进行排序
data.reset_index(drop=True, inplace=True) #重新编号
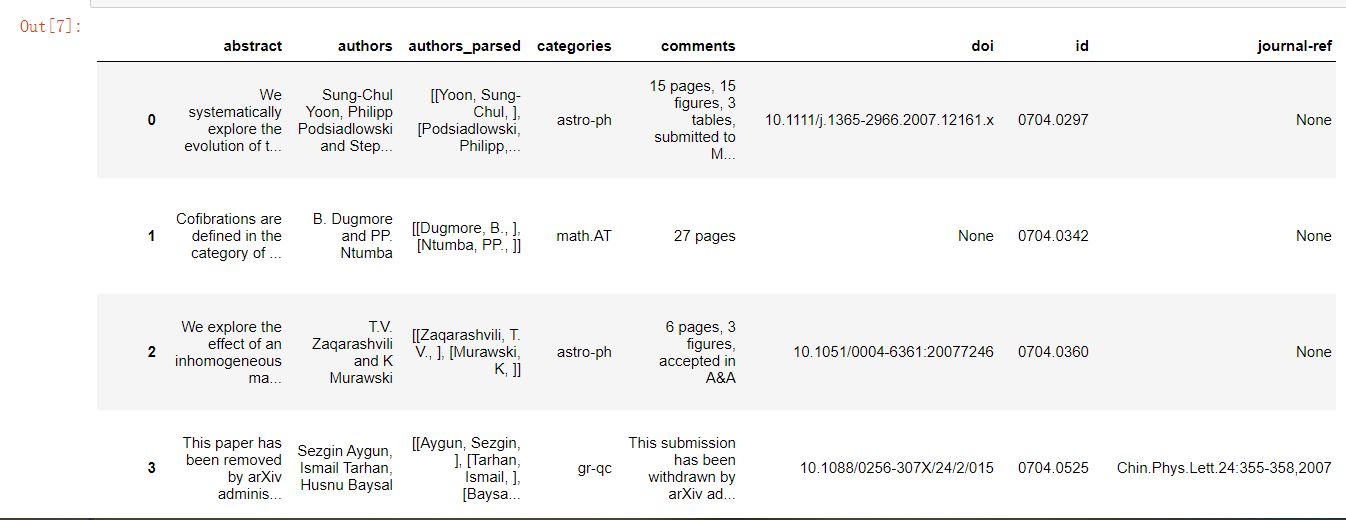
data #查看结果
#爬取所有的类别
website_url = requests.get('https://arxiv.org/category_taxonomy').text #获取网页的文本数据
soup = BeautifulSoup(website_url,'lxml') #爬取数据,这里使用lxml的解析器,加速
root = soup.find('div',{'id':'category_taxonomy_list'}) #找出 BeautifulSoup 对应的标签入口
tags = root.find_all(['h2','h3','h4','p'], recursive=True) #读取 tags
#初始化 str 和 list 变量
level_1_name = ''
level_2_name = ''
level_2_code = ''
level_1_names = []
level_2_codes = []
level_2_names = []
level_3_codes = []
level_3_names = []
level_3_notes = []
#进行
for t in tags:
if t.name == 'h2':
level_1_name = t.text
level_2_code = t.text
level_2_name = t.text
elif t.name == 'h3':
raw = t.text
level_2_code = re.sub(r'(.*)\((.*)\)',r'\2',raw) #正则表达式:模式字符串:(.*)\((.*)\);被替换字符串"\2";被处理字符串:raw
level_2_name = re.sub(r'(.*)\((.*)\)',r'\1',raw)
elif t.name == 'h4':
raw = t.text
level_3_code = re.sub(r'(.*) \((.*)\)',r'\1',raw)
level_3_name = re.sub(r'(.*) \((.*)\)',r'\2',raw)
elif t.name == 'p':
notes = t.text
level_1_names.append(level_1_name)
level_2_names.append(level_2_name)
level_2_codes.append(level_2_code)
level_3_names.append(level_3_name)
level_3_codes.append(level_3_code)
level_3_notes.append(notes)
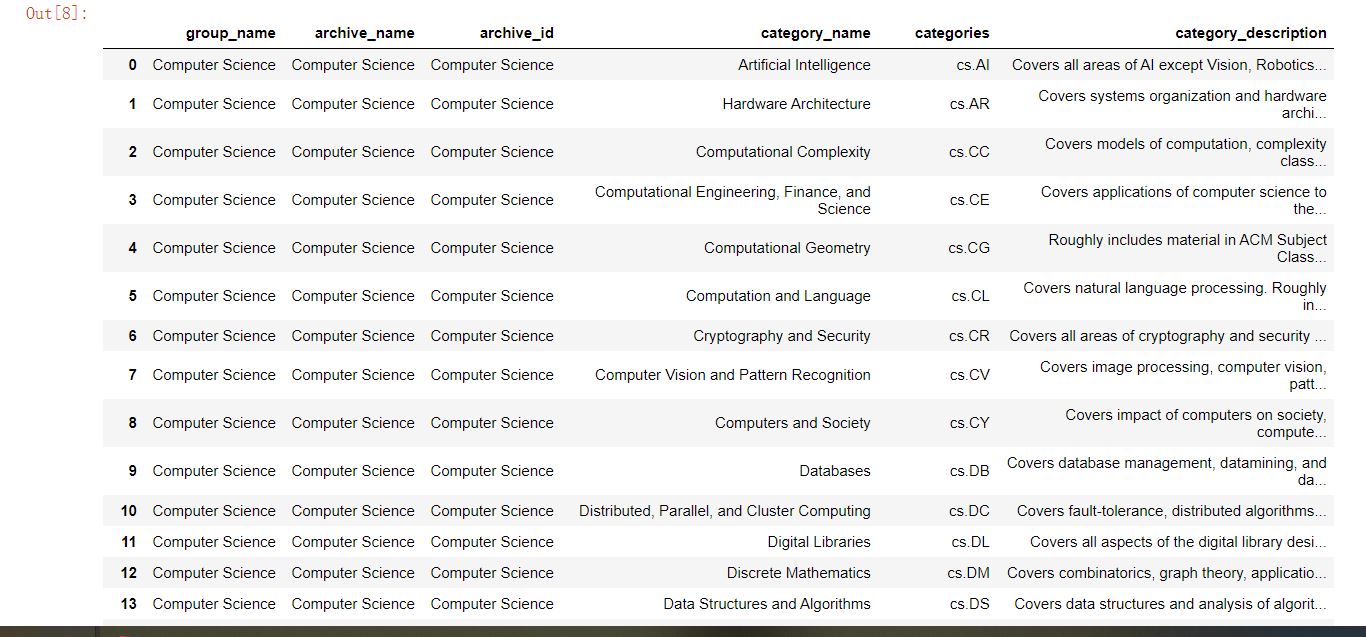
#根据以上信息生成dataframe格式的数据
df_taxonomy = pd.DataFrame({
'group_name' : level_1_names,
'archive_name' : level_2_names,
'archive_id' : level_2_codes,
'category_name' : level_3_names,
'categories' : level_3_codes,
'category_description': level_3_notes
})
#按照 "group_name" 进行分组,在组内使用 "archive_name" 进行排序
df_taxonomy.groupby(['group_name','archive_name'])
df_taxonomy
'''
pattern : 正则中的模式字符串。
repl : 替换的字符串,也可为一个函数。
string : 要被查找替换的原始字符串。
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
flags : 编译时用的匹配模式,数字形式。
其中pattern、repl、string为必选参数
'''
#re.sub(pattern, repl, string, count=0, flags=0)
re.sub(r'(.*)\((.*)\)',r'\2',raw)

_df = data.merge(df_taxonomy, on='categories', how='left').drop_duplicates(['id','group_name']).groupby('group_name').agg({'id':'count'}).sort_values(by='id',ascending=False).reset_index()
_df
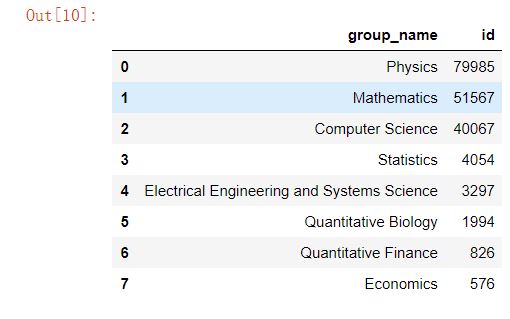
fig = plt.figure(figsize=(15,12))
explode = (0, 0, 0, 0.2, 0.3, 0.3, 0.2, 0.1)
plt.pie(_df['id'], labels=_df['group_name'], autopct='%1.2f%%', startangle=160,explode=explode)
plt.tight_layout()
plt.show()
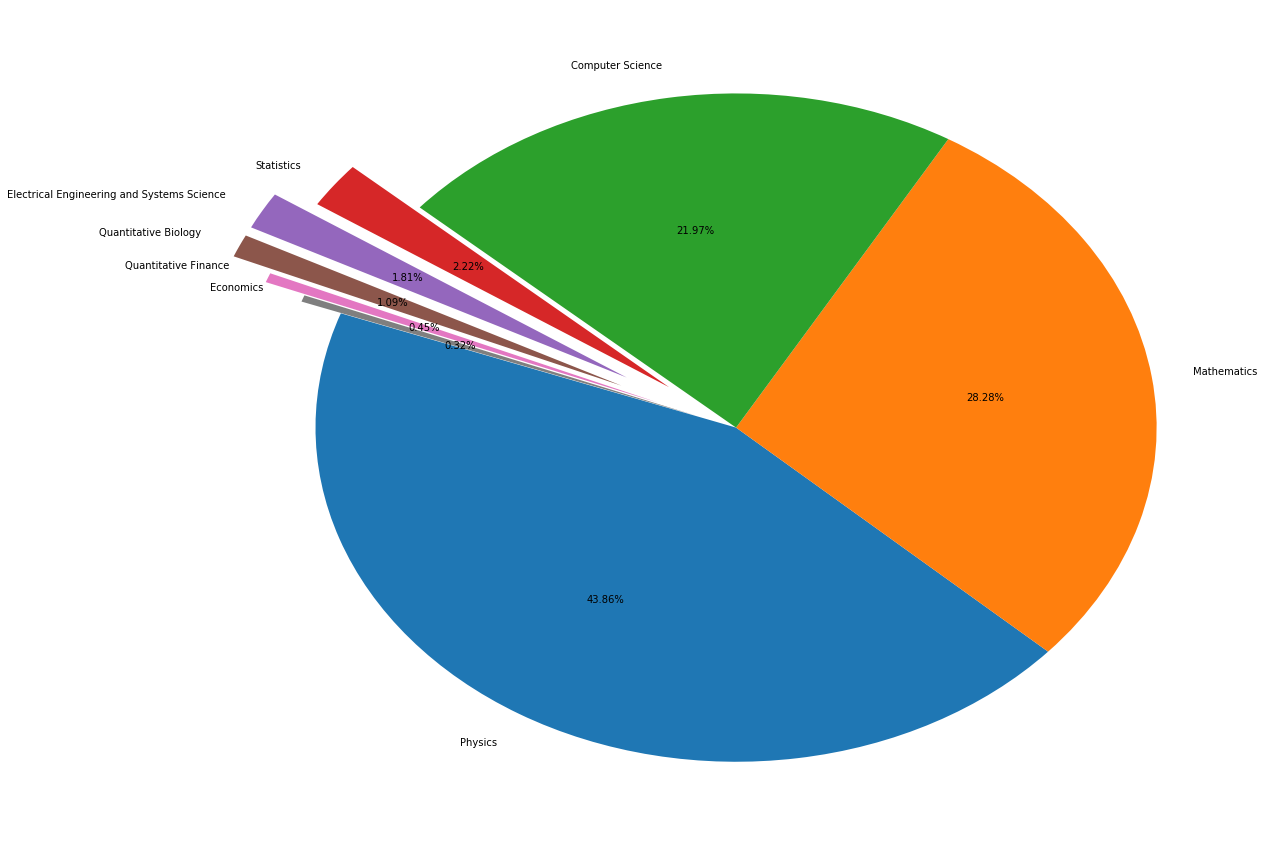
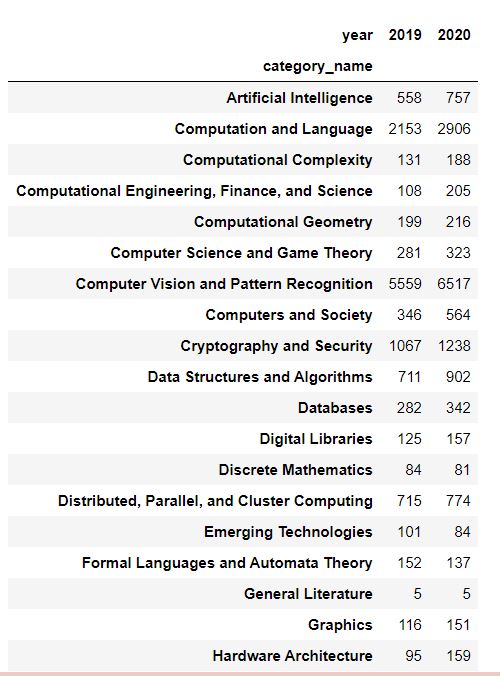
group_name='Computer Science'
cats = data.merge(df_taxonomy, on='categories').query('group_name == @group_name')
cats.groupby(['year','category_name']).count().reset_index().pivot(index='category_name', columns='year',values='id')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号