


DeiT-LT:印度科学院提出针对长尾数据的`DeiT`升级模型 | CVPR 2024
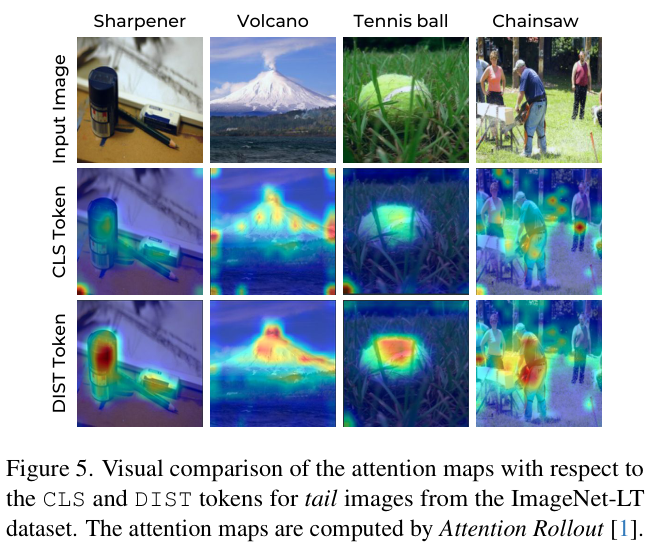
DeiT-LT为ViT在长尾数据集上的应用,通过蒸馏DIST标记引入CNN知识,以及使用分布外图像并重新加权蒸馏损失来增强对尾类的关注。此外,为了减轻过拟合,论文建议用经过SAM训练的CNN教师进行蒸馏,促使所有ViT块中DIST标记学习低秩泛化特征。经过DeiT-LT的训练方案,DIST标记成为尾类的专家,分类器CLS标记成为头类的专家,有效地学习与多数类和少数类相对应的特征
来源:晓飞的算法工程笔记 公众号
论文: DEYO: DETR with YOLO for Step-by-Step Object Detection

Introduction
ViT是需要对大型数据集进行预训练,数据高效ViT(DeiT)旨在通过从预训练的CNN中提取信息来减少预训练的要求,提高ViT的数据和计算效率。然而,所有这些改进仅限于平衡的ImageNet数据集。
关于DeiT可以看这篇文章:【DeiT:训练ImageNet仅用4卡不到3天的平民ViT | ICML 2021】
在这项工作中,论文的目标是从头开始研究和改进ViT的训练,而不需要对图像大小和分辨率各异的各种额外长尾数据集进行大规模预训练。最近的研究表明ViT在长尾识别任务上的性能有所提高,但这些通常需要在大规模数据集上进行昂贵的预训练。此外,大规模预训练数据集通常会无意中引入的偏差。为了减轻这些缺点,论文为长尾引入了数据高效的ViT(Deit-LT),一个可以在小型和大规模长尾数据集上从头训练ViT的方案。
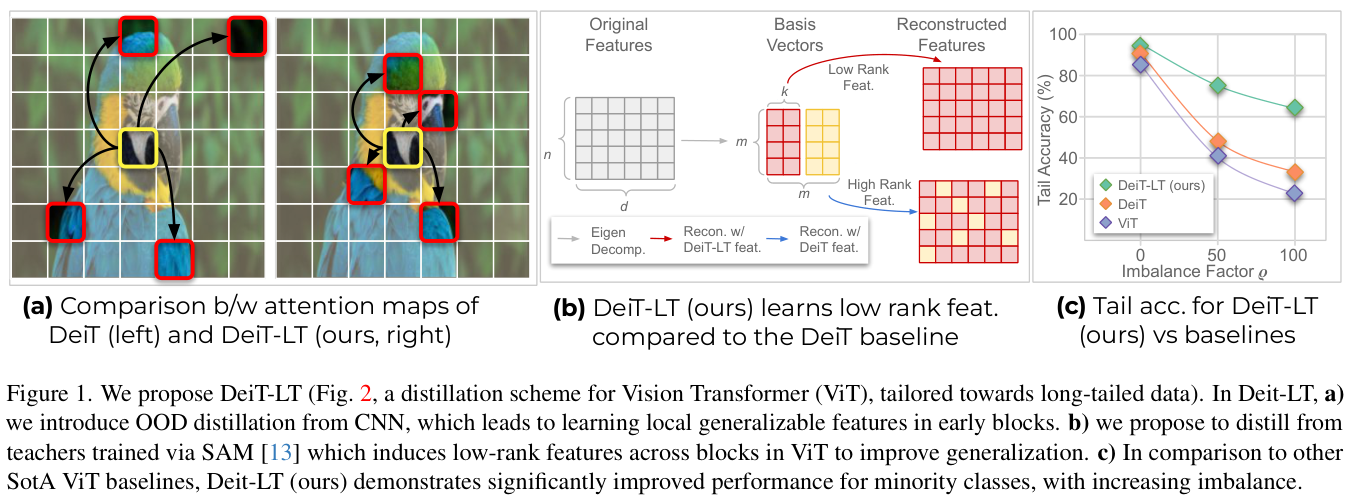
DeiT-LT基于以下重要设计原则:
- 通过强增强生成的分布外(
OOD)图像从低分辨率教师网络中提取知识。值得注意的是,即使CNN教师模型最初没有接受过此类增强的训练,这种方法也被证明是有效的。这种策略可以在ViT学生模型中成功引入类似CNN的特征局部性,最终提高了泛化性能,特别是对于少数(尾)类。 - 为了提高特征的通用性,使用经过锐度感知最小化(
SAM)训练的CNN教师模型来提取知识,促使所有ViT块中学习到长尾数据集所需的低秩泛化特征。 - 在
DeiT中,CLS和DIST标记产生类似的预测,而DeiT-LT则是分化的。CLS标记成为多数类别的专家,而DIST标记则学习局部低秩特征,成为少数类的专家。因此,DeiT-LT对多数类和少数类都有效,这在DeiT中是不可能实现的。
DeiT-LT (DeiT for Long-Tailed Data)
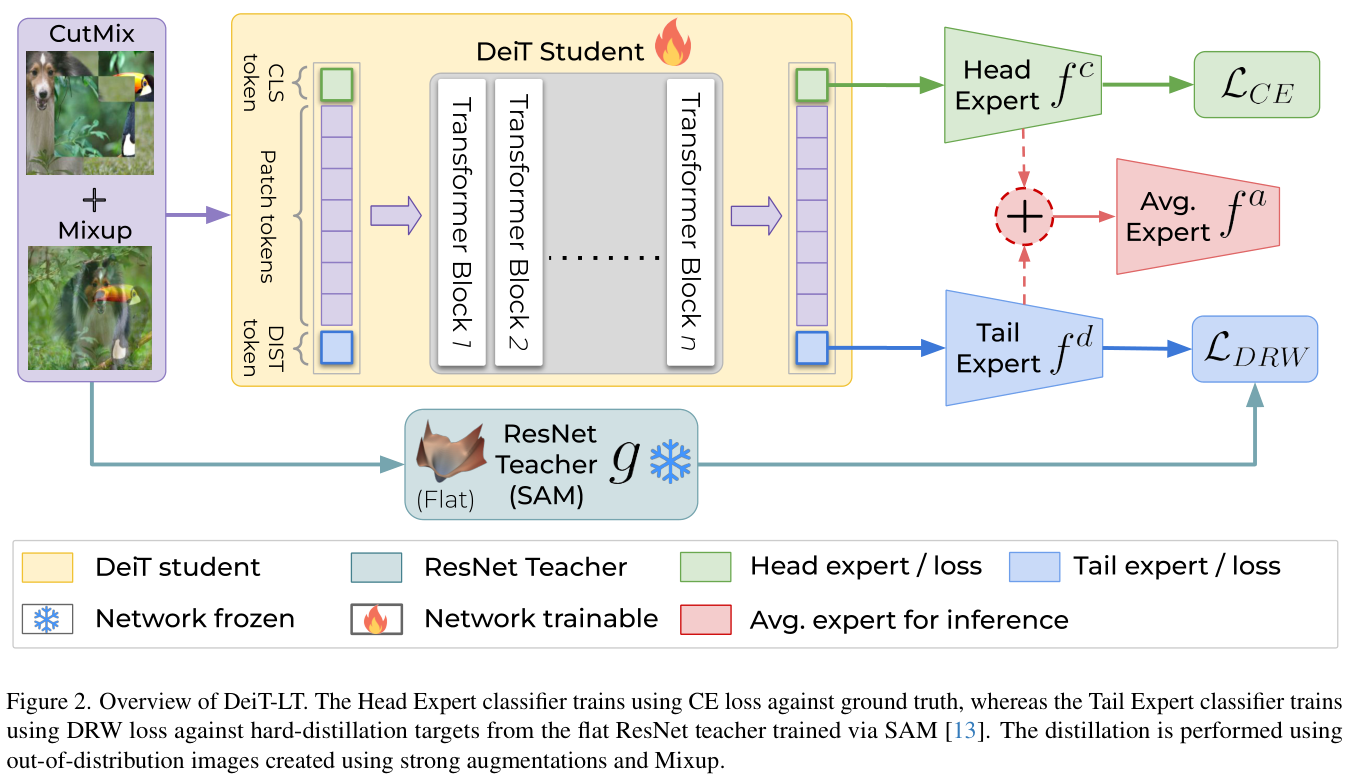
DeiT-LT是专门针对长尾数据的数据高效ViT模型,跟DeiT一样,除了CLS标记之外,还包含通过蒸馏从CNN学习的DIST标记。
此外,DeiT-LT引入了三个特殊的设计组件:
- 通过分布外(
OOD)图像进行有效蒸馏,这会引入局部特征并创建专家。 - 使用
DRW损失训练Tail Expert分类器。 - 通过蒸馏从
CNN教师学习低阶泛化特征。
Distillation via Out of Distribution Images
在DeiT中,需要使用跟ViT一样的强增强图像来训练一个大型CNN(RegNetY)用于蒸馏,这会产生额外的开销。相比之下,DeiT-LT使用常规的弱增强来训练小型CNN(ResNet-32)网络,然后在蒸馏过程中使用强增强图像获得预测进行蒸馏。
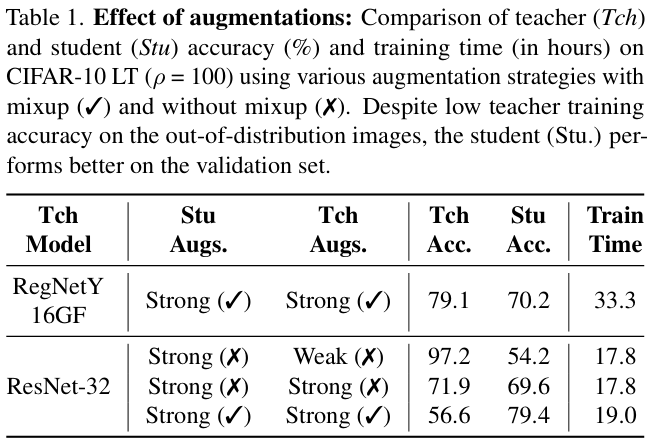
这些强增强图像是CNN的分布外 (OOD) 图像,因为模型在这些训练图像上的准确度较低,如表 1 所示(这里的Acc应该是对应增强图片的准确率,非简单测试集。RegNetY16GF教师应该是强增强训练的,不然Tec Acc不应该这么高。而ResNet-32教师则应该全是弱增强训练的,所以增加数据增强后Tec Acc逐步下降)。与弱增强蒸馏相比,尽管对强增强图像的准确度较低,但你强增强蒸馏依然可以产生有效的效果。因为ViT学生学会模仿CNN教师对分布外图像的错误预测,这使得学生能够学习教师的归纳偏差。
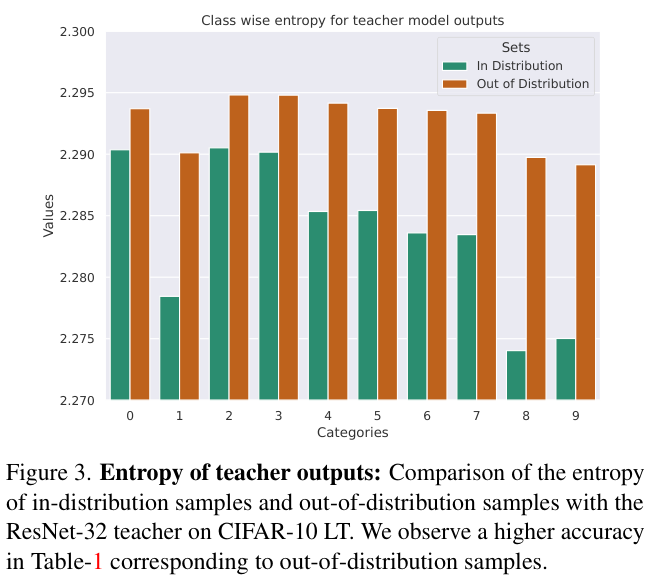
此外,论文发现通过混合两个类别的图像来创建额外的分布外样本也可以提高蒸馏性能。从教师预测的熵中可以看出,对于OOD样本的预测熵很高(即信息量更大)。总的来说,论文发现在蒸馏时增加不同数量的分布外数据有助于提高性能并导致CNN的有效蒸馏。
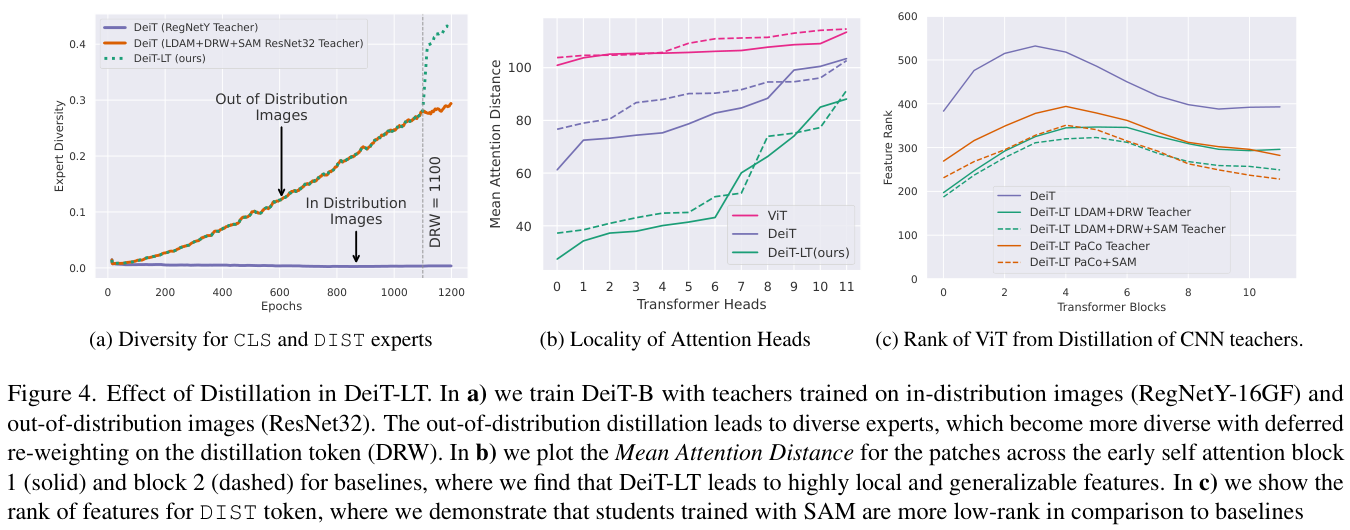
通过使用分布外图像进行蒸馏,教师预测 \(y\_t\) 通常与真实值 \(y\) 不同。因此,CLS标记和DIST标记的特征表达在训练时会有所不同。如图 4a 所示,CLS标记和DIST标记特征之间的余弦距离随着训练的进行而增加,导致CLS标记成为头类预测的专家,而DIST标记则专注于尾类预测。这个发现打破了DeiT中,CLS标记输出与DIST标记输出相似的现象。
Tail Expert with DRW loss.
论文引入了延迟重加权(DRW)来计算蒸馏损失,使用因子 \(w_y = 1/{1 + (e\_y − 1)\mathbb{1}_{\mathrm{epoch}}\ge K}\) 来衡量每个类别的损失,其中 \(e\_{y}=\mathrm{\frac{1-\beta^{{N}\_y}}{1{-\beta}}}\) 是 \(y\) 类中在 \(K\) 个周期后的有效样本数。因此,总损失如下:
DRW阶段进一步增强了DIST蒸馏头对尾部类别的关注,从而提高了性能。如图 4a 所示,两个标记间的多样性在引入DRW阶段后得到了改善。DRW能够引导不同的CLS和DIST标记的创建,分化为多数类和少数类的专家。
Induction of Local Features
为了深入了解OOD蒸馏的通用性和有效性,论文仔细研究了DeiT-LT生成的尾部特征。在图 4b 中,绘制了ViT头部每个标记的平均注意力距离。
- Insight 1
在DeiT-LT第一个和第二个块中,出现了像CNNN一样关注邻域标记的头。由于这种对局部泛化的类不可知的特征,少数类的泛化能力有所提高(图 1c)。
如果没有OOD蒸馏,DeiT和ViT基线在全局特征上过度拟合(图 4b),没有很好地泛化到尾部类别。因此,DeiT-LT中的OOD蒸馏是一种非常适合长尾场景的方法。
Low-Rank Features via SAM teachers
为了进一步提高特征的泛化性,特别是对于数据较少的类,论文通过锐度感知最小化(SAM)训练的CNN教师模型,使其能够收敛到最小平面并得到低秩特征。
为了分析LT情况下ViT学生模型的特征秩,论文专门计算尾类特征的秩。具体来说,对通过LDAM和PaCo训练的不同教师模型进行SAM对比实验,观察DIST特征秩情况。
- Insight 2
如图 4c 所示,根据SAM教师模型的预测蒸馏出的ViT模型会出现跨ViT块的低秩泛化DIST标记特征。
通过蒸馏最终的Logits向量就能将CNN教师的特征(低秩)迁移给学生,这对于ViT蒸馏是一个重大的新发现。
- Training Time
DeiT以高分辨率(\(224\times224\))训练大型CNN RegNetY-16GF来蒸馏ViT,而论文则以较低的分辨率训练较小的ResNet-32 CNN(\(32\times32\))来实现有竞争力的性能。如表 1 所示,这显著减少了计算要求和总体训练时间 13 小时,因为ResNet-32模型可以快速训练。此外,使用SAM教师模型时,学生模型的收敛速度比使用普通教师模型时快得多,这证明了SAM教师对于低秩蒸馏的功效。
Experiments
Experimental Setup
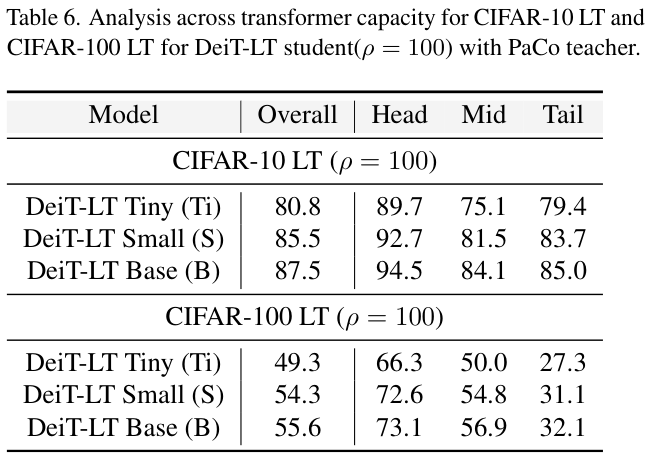
遵循DeiT中提到的设置来为论文的实验创建学生模型,对所有数据集使用DeiT-B学生模型架构。
教师模型的训练,可以选择使用基于重新加权的LDAM-DRW-SAM方法或PaCo+SAM(使用SAM优化器训练PaCo)来训练。
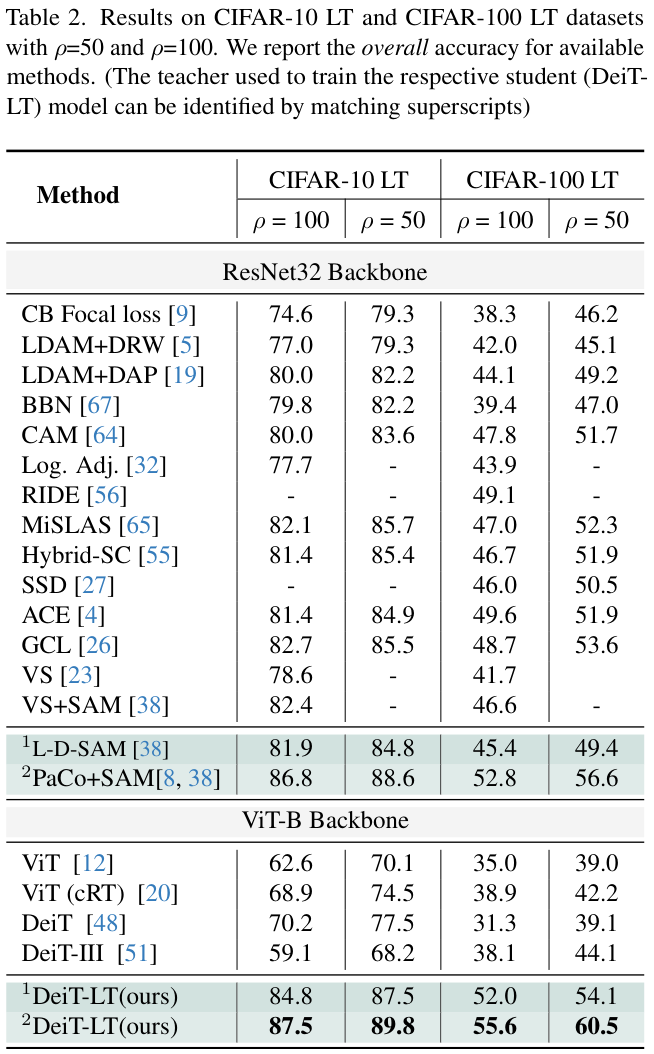
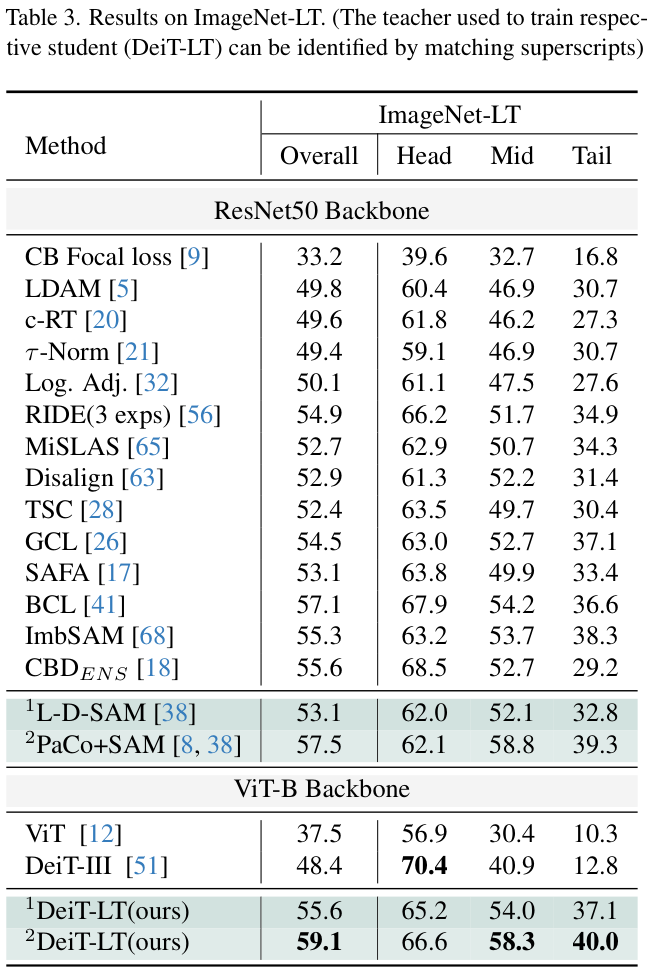
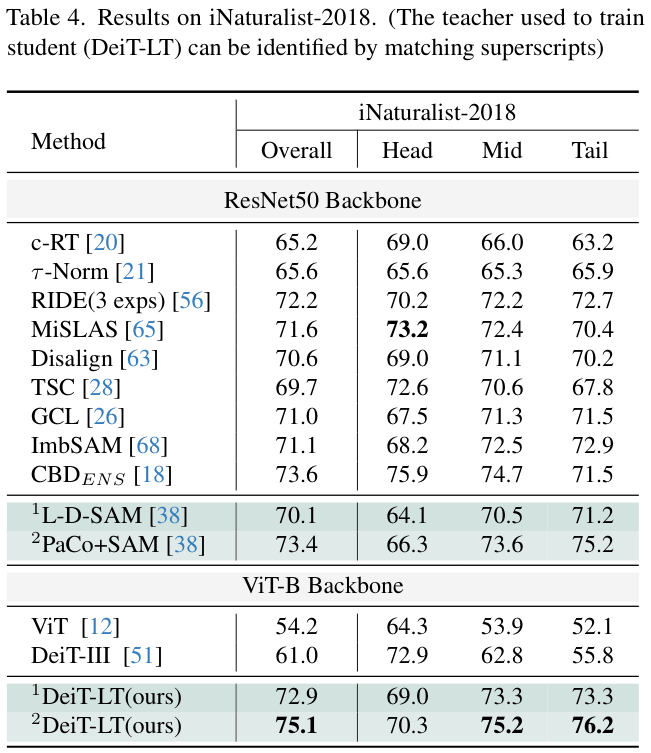
教师模型的选择,小规模数据集(CIFAR-10 LT和CIFAR-100 LT)采用ResNet-32,大规模ImageNet-LT的iNaturalist2018采用ResNet-50。
头部专家分类器使用CE损失训练,而尾部专家分类器则使用CE+DRW损失来训练来自教师网络的硬蒸馏目标。
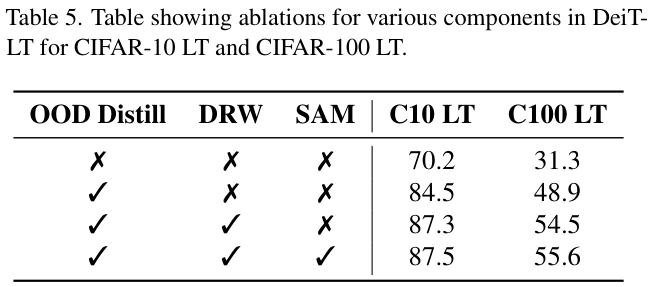
- Small scale CIFAR-10 LT and CIFAR-100 LT.
模型训练 1200 个周期,其中尾部专家分类器的DRW训练从第 1100 个周期开始。除了DRW训练(最后 100 个时期)外,对输入图像使用Mixup和Cutmix增强。使用AdamW优化器通过余弦学习率进行训练,基础LR为 \(5\times10^{-4}\)。
- Large scale ImageNet-LT and iNaturalist-2018.
模型分别训练了 1400 和 1000 个周期,尾部专家分类器的DRW训练分别从 1200 和 900 个周期开始。在整个训练过程中使用Mixup和Cutmix增强,都遵循余弦学习率,基本LR为 \(5\times10^{-4}\)。
Result
如果本文对你有帮助,麻烦点个赞或在看呗~undefined更多内容请关注 微信公众号【晓飞的算法工程笔记】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号