

CvT:微软提出结合CNN的ViT架构 | 2021 arxiv
CvT将Transformer与CNN在图像识别任务中的优势相结合,从CNN中借鉴了多阶段的层级结构设计,同时引入了Convolutional Token Embedding和Convolutional Projection操作增强局部建模能力,在保持计算效率的同时实现了卓越的性能。此外,由于卷积的引入增强了局部上下文建模能力,CvT不再需要position Embedding,这使其在适应各种需要可变输入分辨率的视觉任务方面更具有优势
来源:晓飞的算法工程笔记 公众号
论文: CvT: Introducing Convolutions to Vision Transformers

Introduction
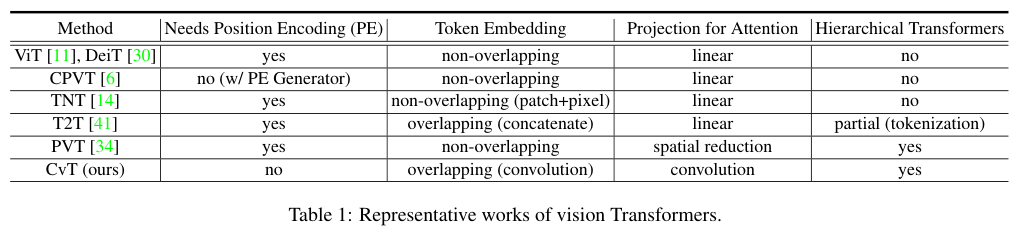
作者提出了一种名为Convolutional vision Transformer(CvT) 的新架构,通过将引入卷积网络的设计来提高ViT的性能和效率。CvT从CNN中借鉴了多阶段的层级结构设计,同时引入了Convolutional Token Embedding和Convolutional Projection两个新模块,分别用于增加block输入和中间特征的局部建模能力,提高效率。
CvT能够将CNN的理想特性(位移、缩放和失真的不变性)引入了ViT,同时保持Transformer的优点(动态注意力、全局上下文和更好的泛化能力)。由于卷积的引入,CvT可以移除Position Embedding,这使其在适应各种需要可变输入分辨率的视觉任务方面更具有优势。
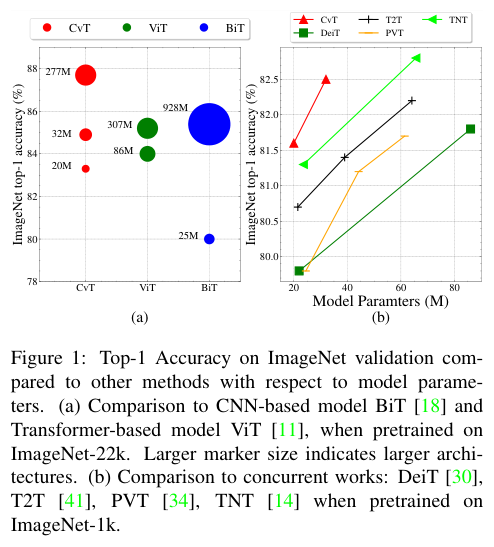
在ImageNet-1k上,CvT到达优于其他Vision Transformer和ResNet的性能,并且参数更少且FLOP更低。当在ImageNet-22k上预训练后,CvT-W24在ImageNet-1k验证集上获得了 87.7%的top-1准确率。
Convolutional vision Transformer
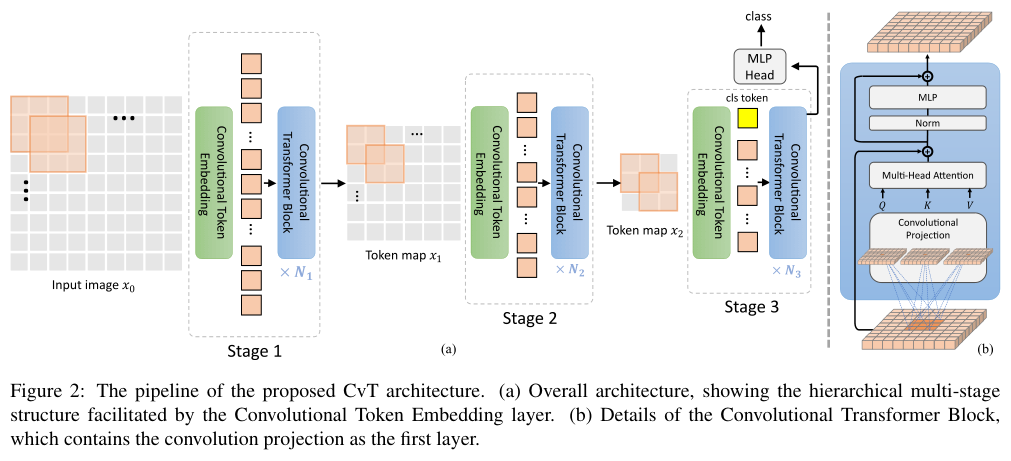
CvT的整体结构如图2所示,在ViT架构中引入了两种基于卷积的操作:Convolutional Token Embedding和Convolutional Projection,同时也从CNN中借鉴了多阶段的层级结构设计。
如图2a所示,CvT包含三个阶段,每个阶段有两个部分:
- 使用Convolutional Token Embedding层将输入图像(或2D重构的token图)进行处理,该层由卷积实现,外加层归一化。这使得每个阶段能够逐渐减少token的数量同时增加token的维度,从而实现空间下采样和增加特征的丰富性,类似于CNN的设计。与其他基于Transformer的架构不同,CvT不会将position embedding与token相加,这得益于卷积操作本身就建模了位置信息。
- 堆叠的Convolutional Transformer Block组成了每个阶段的其余部分。 Convolutional Transformer Block的结构如图2b所示,其中的Convolutional Projection为深度可分离卷积,用于
Q、K和Vembedding的转换,代替常见的矩阵线性投影。此外,class token仅在最后阶段添加,使用MLP对最后阶段输出的分类token进行类别预测。
Convolutional Token Embedding
CvT中的卷积操作主要是为了参考CNN的多阶段层级方法来对局部空间的上下文进行建模,从低级边缘特征到高阶语义特征。
给定一个2D图像或来自前一个阶段的2D重构输出\(x_{i−1}\in \mathbb{R}^{H_{i−1}\times W_{i−1}\times C_{i−1}}\)作为阶段i的输入,训练卷积函数\(f(\cdot)\)将\(x_{i−1}\)转换成维度为\(C_i\)的新token$ f(x_{i−1})\(。其中\)f(\cdot)\(的内核大小为\)s\times s\(、步幅为\)s - o\(和填充大小为\)p\(。新的token图\)f(x_{i−1})\in \mathbb{R}^{H_{i}\times W_{i}\times C_{i}}$的高度和宽度为:
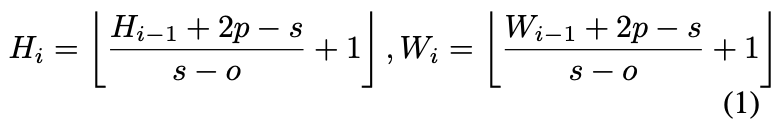
\(f(x_{i−1})\)随后展开为\(H_i W_i\times C_i\)的序列,并且在输入到后续层前通过通过层进行归一化。
Convolutional Token Embedding层可以通过改变卷积的参数来调整每个阶段的token特征维度和token数量,每个阶段逐渐减少token序列长度,同时增加token特征维度。这使得token能够在更大的空间上表达越来越复杂的视觉模式,类似于CNN的特征层。
Convolutional Projection for Attention
Convolutional Projection层的目标是实现局部空间上下文的建模,并通过对Q、K和V矩阵进行欠采样来提供效率优势。
虽然之前的研究也有尝试在Transformer Block中添加额外的卷积模块来进行语音识别和自然语言处理,但这些研究都带来更复杂的设计和额外的计算成本。相反,作者建议用深度可分离卷积替换多头自注意力的原始位置线性投影,得到Convolutional Projection层。
-
Implementation Details
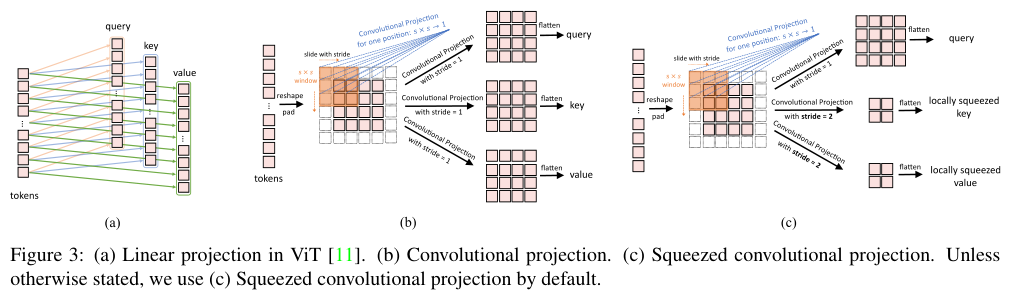
图3a展示了ViT中使用的原始位置线性投影,图3b展示了作者提出的\(s\times s\) Convolutional Projection操作。如图3b所示,token序列先重塑为2D token图,接着使用内核大小为s的深度可分离卷积层实现转换。最后,将得到的token图展开为一维以进行后续处理。这可以表述为:
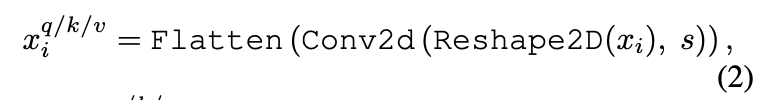
其中\(x^{q/k/v}\)是第i层Q/K/V输入矩阵,\(x_i\)是转换之前的token序列,Conv2d是深度方向可分离卷积,由以下方式实现:Depth-wise Conv2d → BatchNorm2d → Point-wise Conv2d,s指卷积核大小。
带有Convolutional Projection层的新Transformer block实际可认为是原始Transformer block的统一范式,将内核大小设置为\(1×1\)即是原始的位置线性投影层。
-
Efficiency Considerations
Convolutional Projection层的设计有两个主要的效率优势:
- 首先,使用更高效的卷积。使用标准\(s\times s\)卷积需要\(s^2 C^2\)的参数和\(\mathcal{O}(s^2 C^2T)\)的FLOP。将标准卷积拆分为深度可分离卷积则只会引入额外的\(s^2 C\)的参数和$\mathcal{O}(s^2CT ) $的FLOP,这对于模型的总参数和FLOP而言可以忽略不计。
- 其次,使用Convolutional Projection来降低MHSA操作的计算成本。如图3c所示,
K和V通过步幅大于1的卷积进行子采样,Q转换则使用步幅为1不变。这样K和V的token数量减少了4倍,后期MHSA操作的计算量减少了4倍。这仅带来了些许的性能损失,因为图像中的相邻像素往往在外观或语义上有冗余。此外,Convolutional Projection的局部上下文建模补偿了分辨率降低带来的信息损失。
4. Experiments
-
Model Variants

作者通过改变每个阶段的Transformer Block数量和中间特征维度,设计了三个具有不同参数和FLOP的模型,如表2所示。
Comparison to state of the art
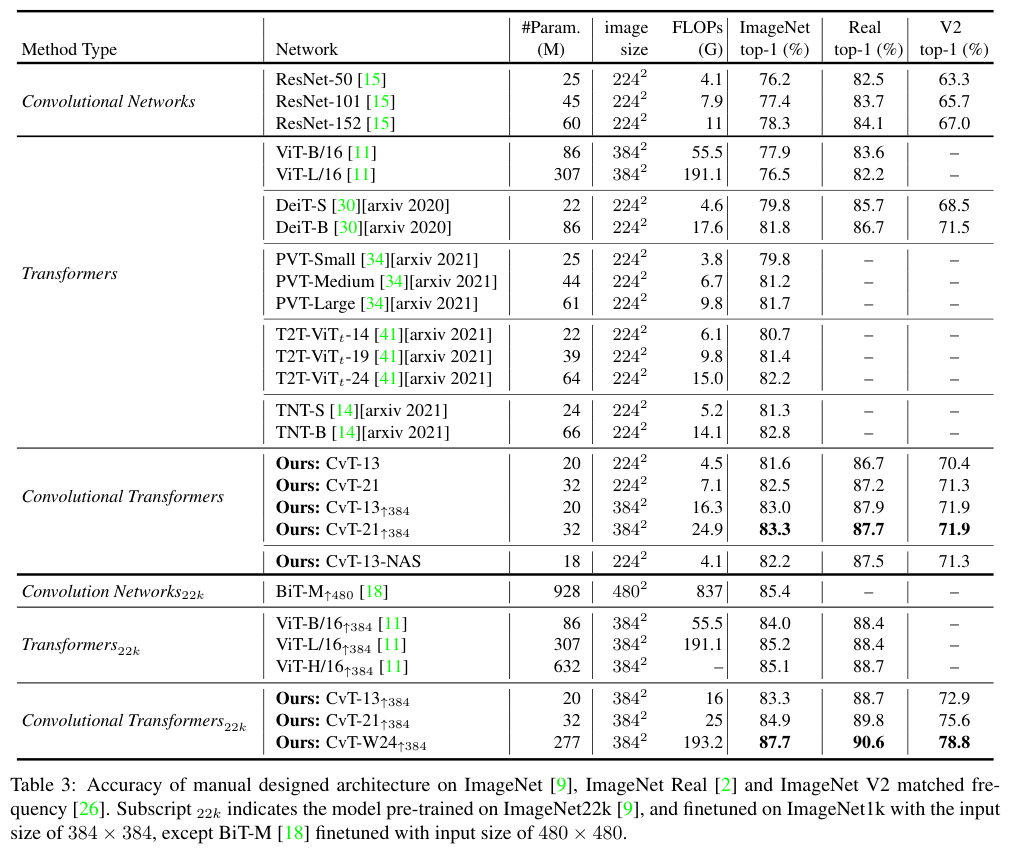
与SOTA方法对比。
Downstream task transfer
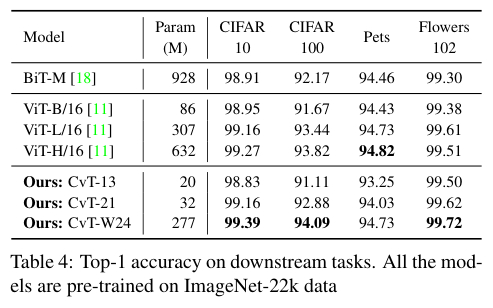
下游任务的迁移能力对比。
Ablation Study
-
Removing Position Embedding
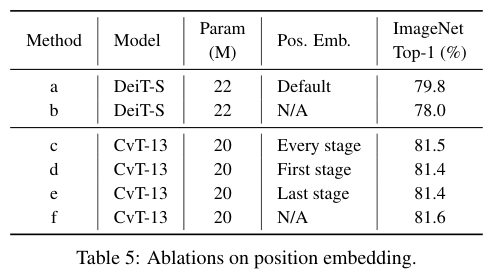
对比position embedding对CvT的影响。
-
Convolutional Token Embedding
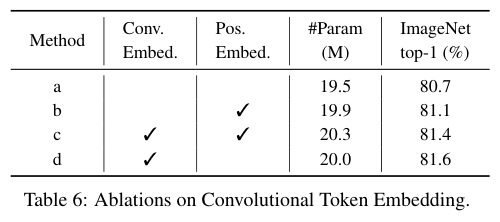
对比Convolutional Token Embedding模块的有效性。
-
Convolutional Projection
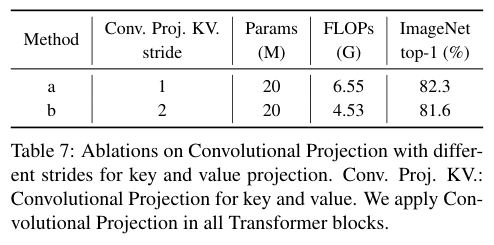
对比Convolutional Projection中的下采样做法的影响。
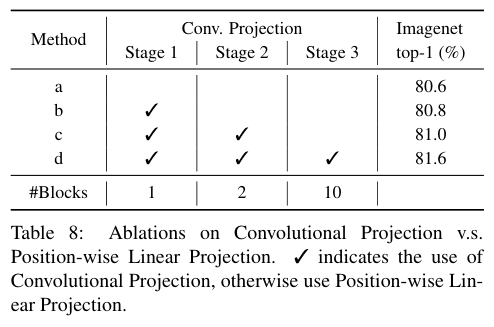
对比Convolutional Projection的有效性。
Conclusion
CvT将Transformer与CNN在图像识别任务中的优势相结合,从CNN中借鉴了多阶段的层级结构设计,同时引入了Convolutional Token Embedding和Convolutional Projection操作增强局部建模能力,在保持计算效率的同时实现了卓越的性能。此外,由于卷积的引入增强了局部上下文建模能力,CvT不再需要position Embedding,这使其在适应各种需要可变输入分辨率的视觉任务方面更具有优势。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号