
CAP:多重注意力机制,有趣的细粒度分类方案 | AAAI 2021
论文提出细粒度分类解决方案CAP,通过上下文感知的注意力机制来帮助模型发现细微的特征变化。除了像素级别的注意力机制,还有区域级别的注意力机制以及局部特征编码方法,与以往的视觉方案很不同,值得一看
来源:晓飞的算法工程笔记 公众号
论文: Context-aware Attentional Pooling (CAP) for Fine-grained Visual Classification

Introduction
论文认为大多数优秀的细粒度图像识别方法通过发掘目标的局部特征来辅助识别,却没有对局部信息进行标注,而是采取弱监督或无监督的方式来定位局部特征位置。而且大部分的方法采用预训练的检测器,无法很好地捕捉目标与局部特征的关系。为了能够更好地描述图片内容,需要更细致地考虑从像素到目标到场景的信息,不仅要定位局部特征/目标的位置,还要从多个维度描述其丰富且互补的特征,从而得出完整图片/目标的内容。
论文从卷积网络的角度考虑如何描述目标,提出了context-aware attentional pooling(CAP)模块,能够高效地编码局部特征的位置信息和外观信息。该模块将卷积网络输出的特征作为输入,学习调整特征中不同区域的重要性,从而得出局部区域的丰富的外观特征及其空间特征,进而进行准确的分类。
论文的主要贡献如下:
- 提出在细粒度图像识别领域的扩展模块CAP,能够简单地应用到各种卷积网络中,带来可观的细粒度分类性能提升。
- 为了捕捉目标/场景间的细微差别,提出由区域特征引导的上下文相关的attention特征。
- 提出可学习的池化操作,用于自动选择循环网络的隐藏状态构成空间和外观特征。
- 将提出的算法在8个细粒度数据集上进行测试,获得SOTA结果。
- 分析不同的基础网络,扩大CAP模块的应用范围。
Proposed Approach
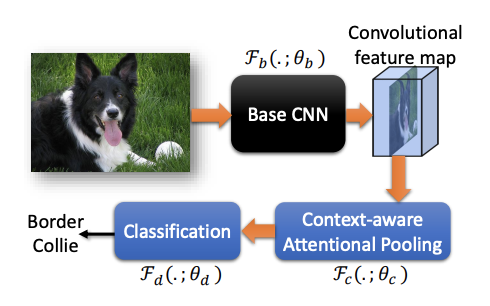
论文算法的整体流程如上图所示,输入图片,输出具体从属类别,包含3个组件(3组参数):
- 基础CNN网络\(\mathcal{F}(.;\theta_b)\)
- CAP模块\(\mathcal{F}(.;\theta_c)\)
- 分类模块\(\mathcal{F}(.;\theta_d)\)
Context-aware attentional pooling (CAP)
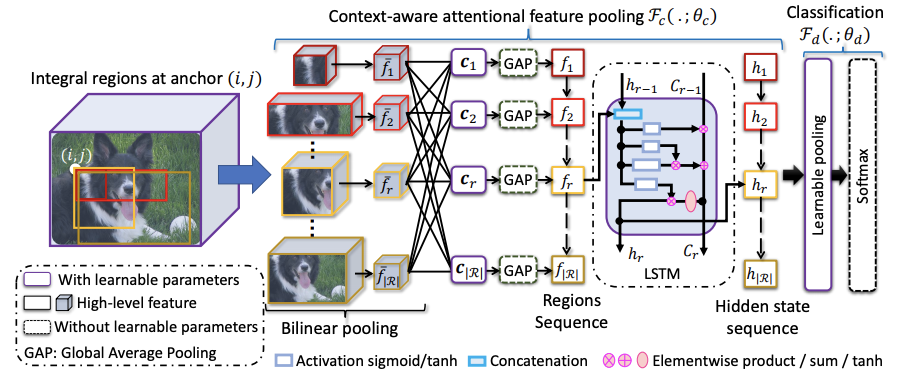
定义卷积网络输出的特征为\(x=\mathcal{F}_b(I_n;\theta_b)\),CAP的模块综合考虑像素级特征、小区域特征、大区域特征以及图片级特征的上下文信息进行分类。
-
pixel-level contextual information
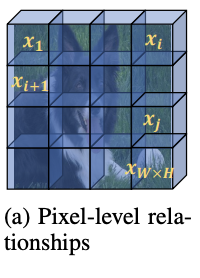
像素级特征的上下文信息主要学习像素间的关联度\(p(x_i|x_j;\theta_p)\),在计算\(j\)位置的输出时根据关联度综合所有其他像素特征,直接使用self-attention实现,特征转化使用\(1\times 1\)卷积。这一步直接对主干网络输出的特征进行操作,但没在整体流程图中体现。
-
Proposing integral regions
为了更高效地学习上下文信息,论文在特征图\(o\)上定义不同粒度级别的基本区域,粒度级别由区域的大小决定。假设\((i,j)\)位置上的最小的区域为\(r(i,j\Delta_x,\Delta_y)\)为例,可通过放大宽高衍生出一系列区域\(R=\{r(i,j,m\Delta_x,n\Delta_y)\}\),\(i < i + m \Delta_x \le W\),\(j < j + n \Delta_y \le H\)。在不同的位置产生相似的区域合集\(R\),得到最终的区域合集\(\mathcal{R}=\{R\}\)。\(\mathcal{R}\)覆盖了所有的位置的不同宽高比区域,可以提供全面的上下文信息,帮助在图片的不同层级提供细微特征。
-
Bilinear pooling
按照上一步,在特征图上得到\(|\mathcal{R}|\)个区域,大小从最小的\(\Delta_x\times\Delta_y\times C\)到最大的\(W\times H\times C\),论文的目标是将不同大小的区域表示为固定大小的特征,主要采用了双线性插值。定义\(T_{\psi}(y)\)为坐标转换函数,\(y=(i,j)\in \mathbb{R}^c\)为区域坐标,对应的特征值为\(R(y)\in \mathbb{R}^C\),则转换后的图片\(\tilde{R}\)的\(\tilde{y}\)坐标上的值为:
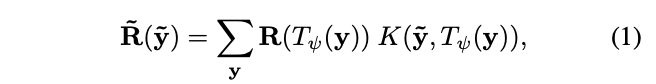
\(R(T_{\psi(y)})\)为采样函数,\(K(\cdots)\)为核函数,这里采用的是最原始的方法,将目标坐标映射回原图,取最近的四个点,按距离进行输出,最终得到池化后的固定特征\(\bar{f}(w\times h\times C)\)。
-
Context-aware attention
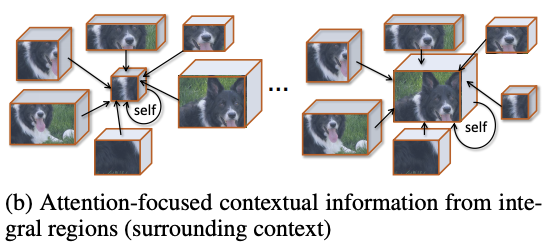
这里,论文使用全新的注意力机制来获取上下文信息,根据\(\bar{f}_r\)与其他特征\(\bar{f}_{r^{'}}(r, r^{'}\in \mathcal{R})\)的相似性进行加权输出,使得模型能够选择性地关注更相关的区域,从而产生更全面的上下文信息。以查询项\(q(\bar{f}_r)\)和一组关键词项\(k(\bar{f}_{r^{'}})\),输出上下文向量\(c_r\):
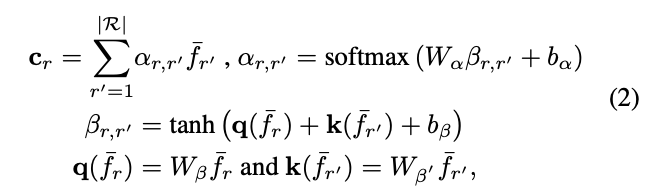
参数矩阵\(W_{\beta}\)和\(W_{\beta^{'}}\)用来将输入特征转换为查询项核关键项,\(W_{\alpha}\)为非线性组合,\(b_{\alpha}\)和\(b_{\beta}\)为偏置项,整体的可学习参数为\(\{W_{\beta},W_{\beta^{'}},W_{\alpha},b_{\alpha},b_{\beta}\}\in\theta_c\),而注意力项\(\alpha_{r,r^{'}}\)则代表两个特征之间的相似性。这样,上下文向量\(c_r\)能够代表区域\(\bar{f}_r\)蕴含的上下文信息,这些信息是根据其与其他区域的相关程度获得的,整体的计算思想跟self-attention基本相似。
-
Spatial structure encoding
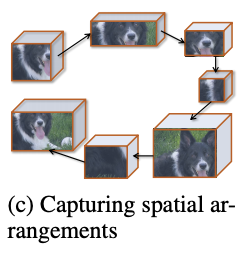
上下文向量\(c=\{c_r|r=1,\cdots|\mathcal{R}|\}\)描述了区域的关键程度和特点,为了进一步加入空间排列相关的结构信息,论文将区域的上下文向量\(c\)转为区域序列(论文按上到下、左到右的顺序),输入到循环神经网络中,使用循环神经网络的隐藏单元\(h_r\in\mathbb{R}^n\)来表达结构特征。
区域\(r\)的中间特征可表示为\(h_r=\mathcal{F}_h(h_{r-1},f_r;\theta_h)\),\(\mathcal{F}_h\)采用LSTM,\(\theta_h\in\theta_c\)包含LSTM的相关参数。为了增加泛化能力和减少计算量,上下文特征\(f_r\in\mathbb{R}^{1\times C}\)由\(c_r\in\mathbb{R}^{w\times h\times C}\)进行全局平均池化得到,最终输出上下文特征序列\(f=(f_1,f_2,\cdots,f_r,\cdots,f_{|\mathcal{R}|})\)对应的隐藏状态序列\(h=(h_1,h_2,\cdots,h_r,\cdots,h_{|\mathcal{R}|})\),后续用于分类模块中。
Classification
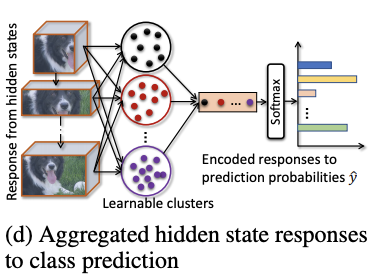
为了进一步引导模型分辨细微的变化,论文提出可学习的池化操作,能够通过组合响应相似的隐藏层\(h_r\)来整合特征信息。论文借鉴NetVLAD的思想,用可导的聚类方法来对隐藏层的响应值进行转换,首先计算隐藏层响应对类簇\(k\)的相关性,再加权到类簇\(k\)的VLAD encoding中:
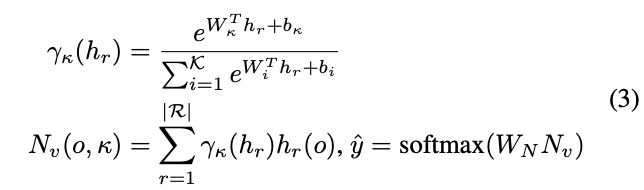
每个类簇都有其可学习的参数\(W_i\)和\(b_i\),整体思想基于softmax,将隐藏层的响应值按softmax的权重分配到不同的类簇中。在得到所有类簇的encoding向量后,使用可学习的权值\(W_N\)和softmax进行归一化。因此,分类模块\(\mathcal{F}_d\)的可学习参数为\(\theta_d=\{W_i, b_i, W_N\}\)。
Experiments and Discussion
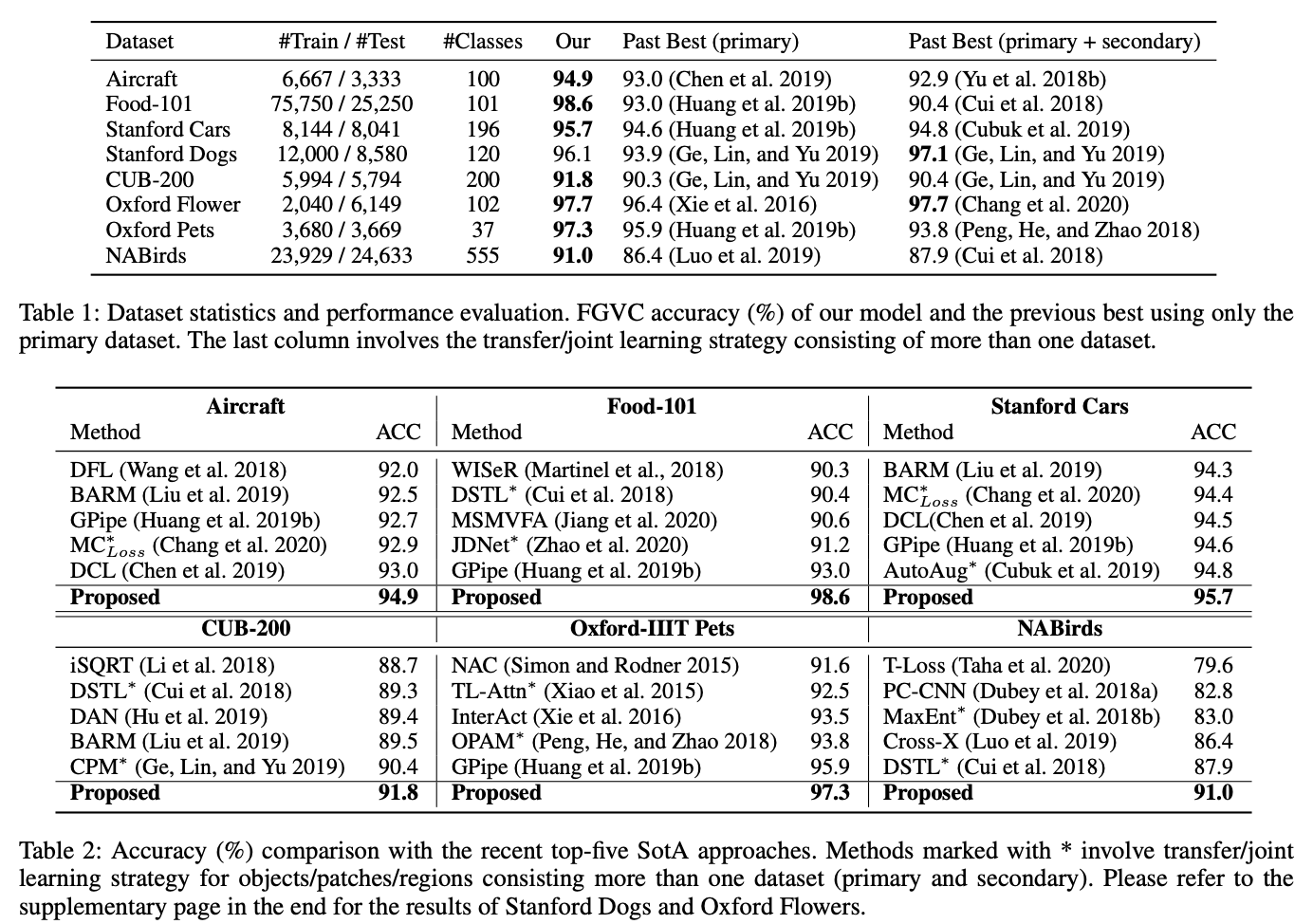
在不同的数据集上,对不同方法进行对比。
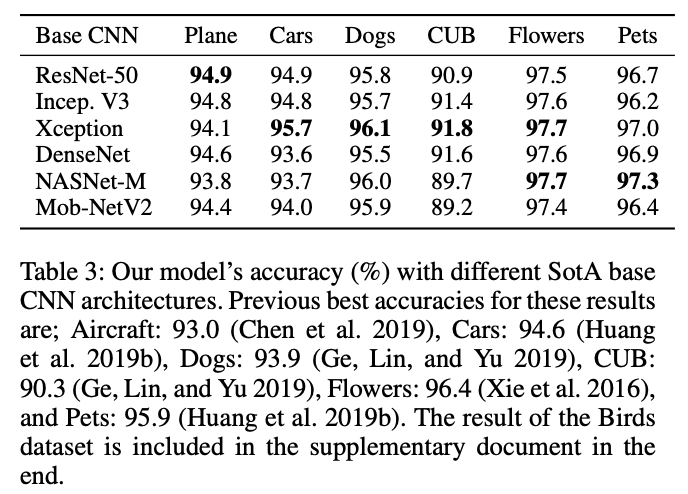
不同主干网络下的准确率对比。

不同模块输出特征的可视化,图b是加入CAP后,主干网络输出的特征。
Conclusion
论文提出细粒度分类解决方案CAP,通过上下文感知的注意力机制来帮助模型发现目标的细微特征变化。除了像素级别的注意力机制,还有区域级别的注意力机制以及局部特征编码方法,与以往的视觉方案很不同,值得一看。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号