架构设计(一)
架构
系统: 一群有关联的个体 , 规则, 能力(产生了新能力)
子系统
模块:逻辑角度 -> 组件复用
组件: 物理角度 -> 单元分离
框架: 组件规范:mvc,等
架构:结构
1. 软件架构:指软件系统的顶层结构。
首先,系统是一群关联的个体组成,这些个体可以是子系统, 模块, 组件等;
其次, 系统中的个体需要根据某种规则运作, 架构需要明确个体运作和协作的规则;
第三,顶层结构的说法可以更好的区分系统和子系统。
2. 历史背景
三难
机器语言 -> 汇编语言 -> 高级语言
3.目的
解决软件系统复杂度的问题。
找复杂点
性能, 高可用, 扩展性, 存储高可靠, 安全性,成本。
4. 复杂度来源:高性能
单机:操作系统
多机:任务分配, 任务分解
5. 复杂度来源:高可用 -> 冗余
无中断
计算高可用:
- 任务分配器
- 连接(与业务处理器)
- 算法(分配)
存储高可用:
传输线路(故障)
状态决策:
- 独裁式
- 协商式
- 民主式: -> 脑裂 -> 解决:选举超一半
6. 复杂度来源:可扩展性
- 正确预测变化
- 完美封装变化
变化层, 接口稳定层
抽象层, 实现层
7. 复杂度来源:低成本, 安全, 规模
低成本 -> 附加约束
- 引入新事物
- 创造新事物
安全
- 功能安全:SQL注入, 代码漏洞
- 架构安全: 防火墙
规模: -> 量变引起质变 而带来的复杂度:
- 功能越来越多,系统复杂度指数增长
- 数据越来越多,系统复杂度发生质变
8. 架构设计原则
选择(不确定性)
- 合适原则: 合适由于业界领先
- 简单原则:简单优于复杂(结构复杂, 逻辑复杂,算法复杂)
- 演化原则:演化由于一步到位
9. 案例
10. 架构设计流程:识别复杂度
列出复杂度问题,排序依次解决;
理解需求,找复杂度 -> 可用排查法,从不同角度逐一分析
每秒TPS , 平均值, 峰值(2-4倍平均值)
设计目标用峰值计算。
复杂度
- 高性能
- 高可用
- 扩展性
TPS:写入
QPS:查询
eg. 目前TPS 是115, QPS是1150,
则峰值 x 3, TPS是345, QPS是3450 -> 这个量级不要求高性能;
预留后续发展, 按 峰值 x 4, TPS是 1380, QPS是13800 -> 高性能
不同的公司会有不同的复杂度分析: 安全,或成本
eg. 消息队列
前浪微博:复杂度体现在
- 高性能消息读取
- 高性能消息写入
- 高可用消息存储
- 高可用消息读取
11. 架构流程设计:设计备选方案
常见错误:
1.设计最优秀的方案
2. 只做一个方案
应设计3-5个备选方案。
备选方案差异要比较明显
备选方案的技术不要只限于已熟悉的技术
备选方案不用过于详细 -> 应关注技术选型,而不是细节
eg. 设计备选方案 - > 高性能读取,写入,高可用存储,读取。
1. 用kafka
2. 集群 + mysql 存储
高性能读取,写入 -> Java, 基于netty开发消息队列
高可用存储,读取 -> 服务器的主备方案, mysql的主备复制。
3. 集群 + 自研存储方案
可参考kafka,自己实现一套存储和复制方案。
12. 架构设计流程:评估和选择备选方案
- 最简派
- 最牛派
- 最熟派
- 领导派
分场景使用
1. 360度环评表: 列出我们需要关注的质量属性点,分别从这些点的维度评估每个方案,再综合选合适当时情况的最优方案。
常见的方案质量属性点:性能,可用性, 硬件成本, 项目投入,复杂度,安全性,可扩展性,可维护性等。
2. 按优先级选择
13. 架构设计流程: 详细方案设计
确定方案 的关键细节
详细设计方案阶段,可能遇到一种极端情况,发现备选方案不可行。
一般情况下,主要原因是涉及备选方案时遗漏了关键技术点或关键质量属性。
这种情况下,可通过以下方式避免:
- 架构师不但要备选方案的设计和选型,还要对备选方案的关键细节有深入理解
- 通过分步骤,分阶段,分系统,降低复杂度
- 如果方案本身复杂,可采取设计团队,博采众长,汇集大家的智慧。
14. 高性能数据库:读写分离
本质:将访问压力分散到集群中的多个节点,但没分散存储压力。
基本原理:将数据库读写操作分散到不同的节点上。
主 + 从 集群: 主负责读/写,从负责读。
不同于 主 + 备
基本实现:
- 数据库服务器,搭建主从集群,一主一从或一主多从 都可以。
- 主机负责读写,从机负责读
- 数据库主机通过复制将数据同步到从机,每个数据库都存了所有数据
- 业务服务器将写发给主数据库,读发给从数据库。
有两个复杂点:1. 主从复制延迟; 2. 分配机制
1. 复制延迟
先假设延迟1秒,数据写入主库后立刻访问从库,读取不到最新数,例如注册,会有业务问题。
它的常规解决方法:
- 写操作后的读操作指定发主数据库 -> 和业务强绑定,对业务侵入和影响较大
- 读从机失败后,再读一次主机 -> 即二次读取,无业务绑定,只需对底层数据库的访问封装,代价小,但若有很多二次读取,将增加主机的读取压力
- 关键业务读写都指向主机,非关键业务读写分离
2. 分配机制
将读写区分,访问不同的数据库,一般有两种方式:程序代码封装和中间件封装
2.1 程序代码封装:在代码中抽象一个数据访问层,实现读写分离和数据库连接管理。
特点:实现简单,可根据业务做定制化功能;
每个语言实现一次;
故障情况下,如果主从发生切换,则需要所有系统都修改配置并重启;
eg. 淘宝的 TDDL(Taobao Distributed Data Layer)
基本原理:基于集中式的配置Jdbc datasource实现: 有主备,读写分离
基本架构

2.2 中间件封装
指独立出一套系统,实现读写分离和数据库服务器连接的管理。
一般建议,程序语言封装或用成熟中间件
Mysql Router,
Atlas : 基于Mysql Proxy
思考:
读写分离一般用于实现什么场景?支撑多的业务规模?
读多写少,实时性要求不高
15. 高性能数据库集群:分库分表
分散存储
数据量 从千万到亿 , 就会有单台瓶颈。
业务分库
按业务分到不同的数据库 -> 分库能支撑百万甚至千万规模业务。
存在问题:join 问题(不同库), 事务, 成本等。
分表
垂直拆分, 水平拆分
垂直:
水平:
复杂性
1. 路由 - 范围路由(分布不均匀), hash路由(分布均匀), 配置路由(用单独的表记录路由信息)
2. join
3. count (count相加,记录数表)
4. order by
实现方式:代码封装,中间件封装
16. 高性能NoSQL
not only SQL, 弥补数据库缺陷
关系数据库缺点:
- 存储的行记录,无法存数据结构 - 无法直接存列表
- schema 扩展不方便: 操作不存在的列会报错,扩充列要DDL,麻烦
- 大数据场景下, I/O较高; 单列统计 ,会读取整行
- 全文搜索功能较弱; like 整表扫描, 性能低
NoSQL分4类
- k-v存储:解决无法存数据结构的问题, 以Redis为代表
- 文档数据库:解决强schema约束问题,以MongoDB为代表
- 列式数据库:解决大数据场景下I/O问题,以HBase为代表
- 全文搜索索引:解决全文搜索性能问题,以Elasticsearch为代表
Redis
eg, lpop 移除list第一个元素。
缺点:不支持完整的ACID, 只保证隔离性和一致性,无法保证原子性和持久性。
文档数据库
特点:no-schema,可存储和读取任意数据,大部分是Json格式存储
优点:
- 新增字段简单
- 历史数据不会出错
- 更易存储复杂数据
适合场景:电商和游戏
缺点:不支持事务,无法join操作。
列式数据库
对比,关系数据库,行式存储:读多列,效率高,能一次完成对一行对个列写操作。
列式数据库:对某个列统计,节省I/O;有更高的压缩比(行:3:1 - 5:1; 列: 8:1, 30:1)
一般将列式存储用在大数据分析和统计场景;主要针对部分单列操作,且写入后无需再更新,删除;
全文搜索引擎
基本原理:倒排索引,是一个索引方法,是建立单词到文档的索引。
使用方式:将关系数据转换为文档数据Json。
Elasticsearch是分布式文档存储方式,每个字段的所有数据默认被索引。
17.高性能缓存架构
某些复杂场景,单靠存储系统,性能提升是不够的。
a. 要经过复杂运算后得到的数据
b. 读多写少的数据
缓存-基本原理:将可能重复使用的数据放到内存,一次生成,多次使用,避免每次使用都访问存储系统。
mechache 单台支持50000 TPS以上。
缓存-架构设计要点:
1. 缓存穿透:指缓存中没数据,都查了存储系统。
有两种情况:
a. 存储数据不存在 - 解决:可设置一个默认值
b. 缓存数据生成耗费大量的时间或资源
2. 缓存雪崩:指缓存失效后,引起系统性能急剧下降的情况
解决:
a. 更新锁机制:对缓存更新操作加锁保护,集群时需要设置分布式锁。
b. 后台更新:由后台线程更新缓存,而不是业务线程;缓存本身设置有效期永久,后台定时更新;
当内存不足时,会踢掉数据,可有两种办法:
1>. 后台除定时更新缓存,还要频繁读缓存
2>. 业务线程发现缓存失效,通过消息队列发一条消息通知后台线程更新缓存。
还可以用后台更新进行缓存预热。
3. 缓存热点
对于一些特别热点的数据,大部分业务请求都命中同一份缓存数据,则这份数据所在的缓存服务器压力也很大。
缓存热点的解决方案是:复制多份缓存副本,将请求分散到多个缓存服务器,减轻缓存热点导致后台服务器压力。
一个细节要注意:不同的缓存副本不要设置统一的过期时间,应设置一个过期时间范围,不同副本过期时间是指定范围的随机值。
实现方式:
- 程序代码的中间层方式实现
- 独立中间件实现
18. 单服务器高性能模式:PPC与TPC
磁盘,操作系统,cpu,内存,网络,编程语言,架构, 都可能影响达到高性能。
架构师要考虑:高性能架构的设计
集中两个点
- 尽量提升单服务性能,将单服务器性能发挥到极致
- 如果单台服务器无法支持性能,设置服务器集群方案
还和编码有关
架构设计决定系统性能的上限,实现细节决定下限。
单服务器性能关键之一:服务器采用并发模型。
关键设计点:
- 服务器如何管理连接
- 服务器如何处理请求
这两个设计点都和操作系统的I/O模型及进程模型相关。
I/O模型: 阻塞, 非阻塞, 同步,异步
进程模型: 单进程, 多进程, 多线程
单服务器高性能模式:PPC, TPC
PPC
: process per connection ,指每次有新的连接就新建一个进程,去专门处理这个连接的请求。
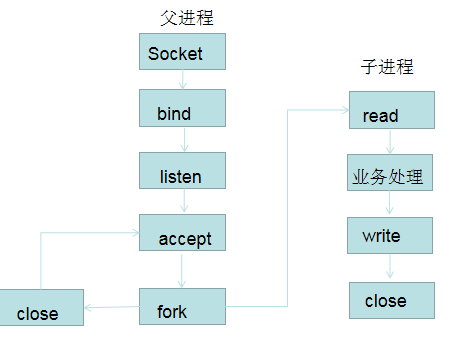
适合连接没那么多的情况。
缺点:
- fork代价高
- 父子进程通信复杂
- 支持的并发连接数量有限
一般情况下,PPC最多能处理的并发连接数就几百。
prefork -> 提前创建进程
TPC
Thread per connection. 每次有新的连接就新建一个线程,专门处理这个连接的请求。
TPC基本流程:
略
TCP虽然解决了fork代价高和进程通信复杂的问题,但有其他问题:
- 高并发性能问题
- 没有进程仅通信,但线程间的互斥和共享,易导致死锁
- 多线程相互影响,一个线程异常,整个进程退出
因此,几百连接的场景,更多用PPC
prethread -> 提前创建线程
19.单服务器高性能模式:Reactor与Proactor
PPC和TPC无法支持高并发
Reactor
资源复用,进程池
read阻塞 -> 改为了非阻塞,进程轮询多个连接(当连接太多,轮询效率低)
再改进 -> 只有连接上有数据,进程才去处理 -> 这就是I/O多路复用技术的来源。
I/O多路复用,关键实现点:
- 当多个连接共用一个阻塞对象后,进程只需要在一个阻塞对象上等待,无需轮询连接
- 当某个连接有新数据处理时,操作系统会通知进程,进程从阻塞状态返回,开始处理
I/O多路复用 + 线程池 ; 支持高并发,叫做 Reactor, 反应堆, 事件反应
Reactor 模式也叫 Dispatcher模式, 即I/O多路复用统一监听事件,收到事件后,分配(Dispatcher)给某个进程。
核心组成:Reactor 和 处理资源池
- Reactor 负责监听和分配事件
- 处理资源池 负责处理事件
Reactor 数量可变, 资源池数量可变。
Reactor 三种典型实现:
- 单Reactor 单进程/线程
- 单Reactor 多线程
- 多Reactor 多线程/进程

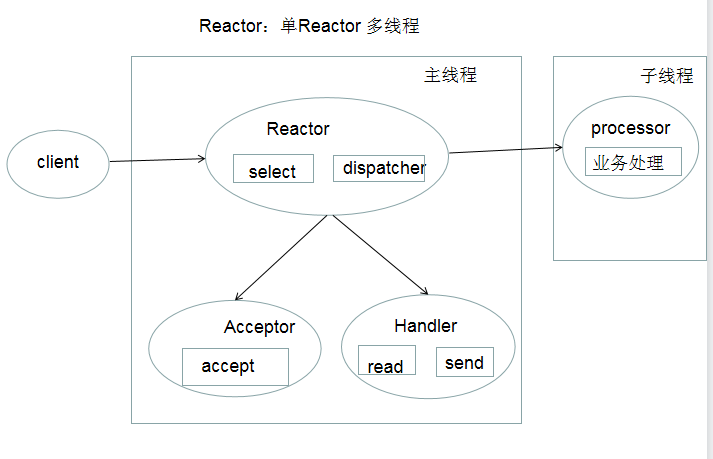
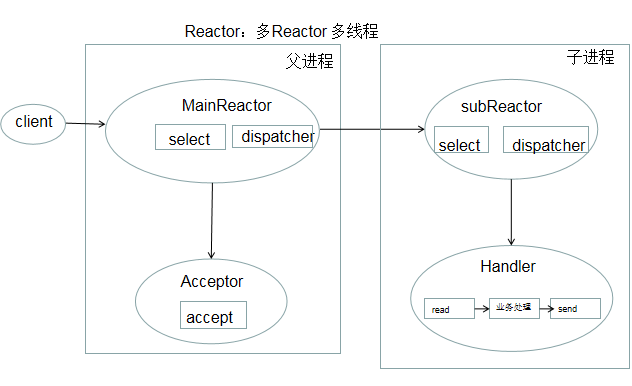
Proactor
同步是指进程在执行read, send这类I/O操作时,是同步的,如果把I/O改为异步,进一步提升性能,这就是异步网络模型 Proactor.
Proactor 异步网络模型 , 主动器
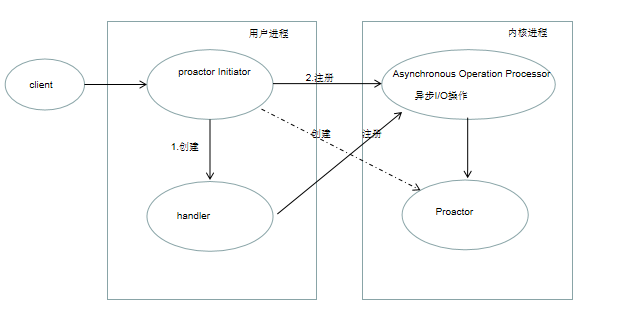
Proactor Initiator 创建handler , Proactor 并将它们通过Asynchronous Operation Processor 进行注册,
Asynchronous Operation Processor 负责处理注册请求,并完成I/O操作,完成后通知Proactor。
Proactor 根据不同的事件类型回调不同的Handler进行业务处理。
Handler完成业务处理,也可以注册新Handler到内核进程。
20. 高性能负载均衡:分类及架构
高性能集群的本质:增加更多的服务器提升系统整体的计算能力。
复杂度:任务分配
体现在要增加一个任务分配器(又叫负载均衡器),以及为任务选一个合适的任务分配算法。
实际任务分配不只考虑任务的负载均衡,不同任务的分配算法不同,有的基于负载考虑,
有的基于性能(吞吐量, 响应时间), 有的基于业务。
负载均衡不只是为了计算单元的负载达到均衡状态。
常见的负载均衡系统有3种:
- DNS负载均衡
- 硬件负载均衡
- 软件负载均衡

 浙公网安备 33010602011771号
浙公网安备 33010602011771号