

jdk1.8中HashMap在扩容的时候做了哪些优化
首先讲一下hashMap扩容为2的幂次.为什么呢?
假设HashMap的容量为15转化成二进制为1111,length-1得出的二进制为1110 哈希值为1111和1110

那么两个索引的位置都是14,就会造成分布不均匀了,增加了碰撞的几率,减慢了查询的效率,造成空间的浪费。
总结:因为2的幂-1都是11111结尾的,所以碰撞几率小。使Hash算法的结果均匀分布。
扩容优化
下面我们讲解下JDK1.8做了哪些优化。
我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。
看下图可以明白这句话的意思,n为table的长度,图(a)表示扩容前的key1和key2两种key确定索引位置的示例,图(b)表示扩容后key1和key2两种key确定索引位置的示例,其中hash1是key1对应的哈希与高位运算结果。
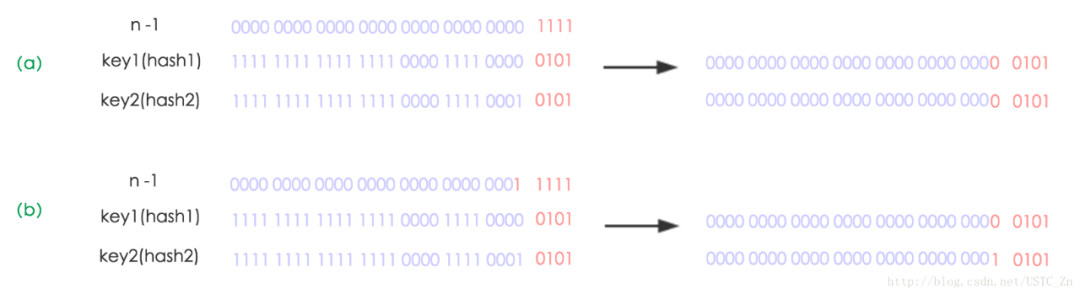
元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
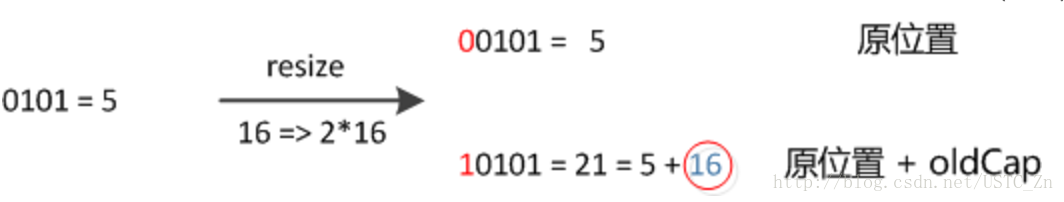
因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”,
可以看看下图为16扩充为32的resize示意图.
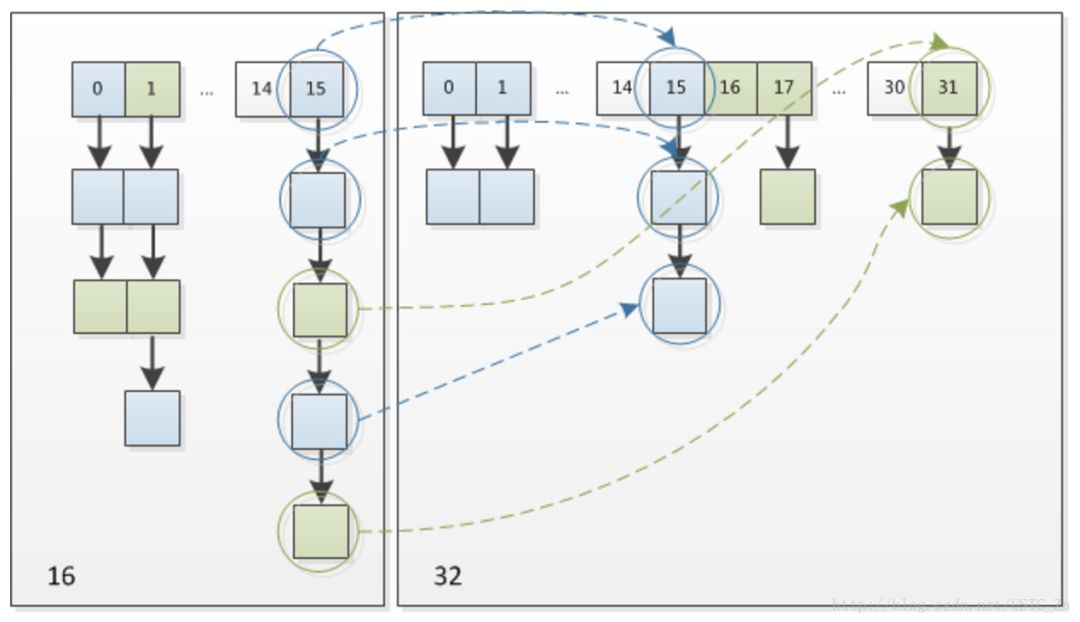
这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。
这一块就是JDK1.8新增的优化点。
有一点注意区别,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但是从上图可以看出,JDK1.8不会倒置。
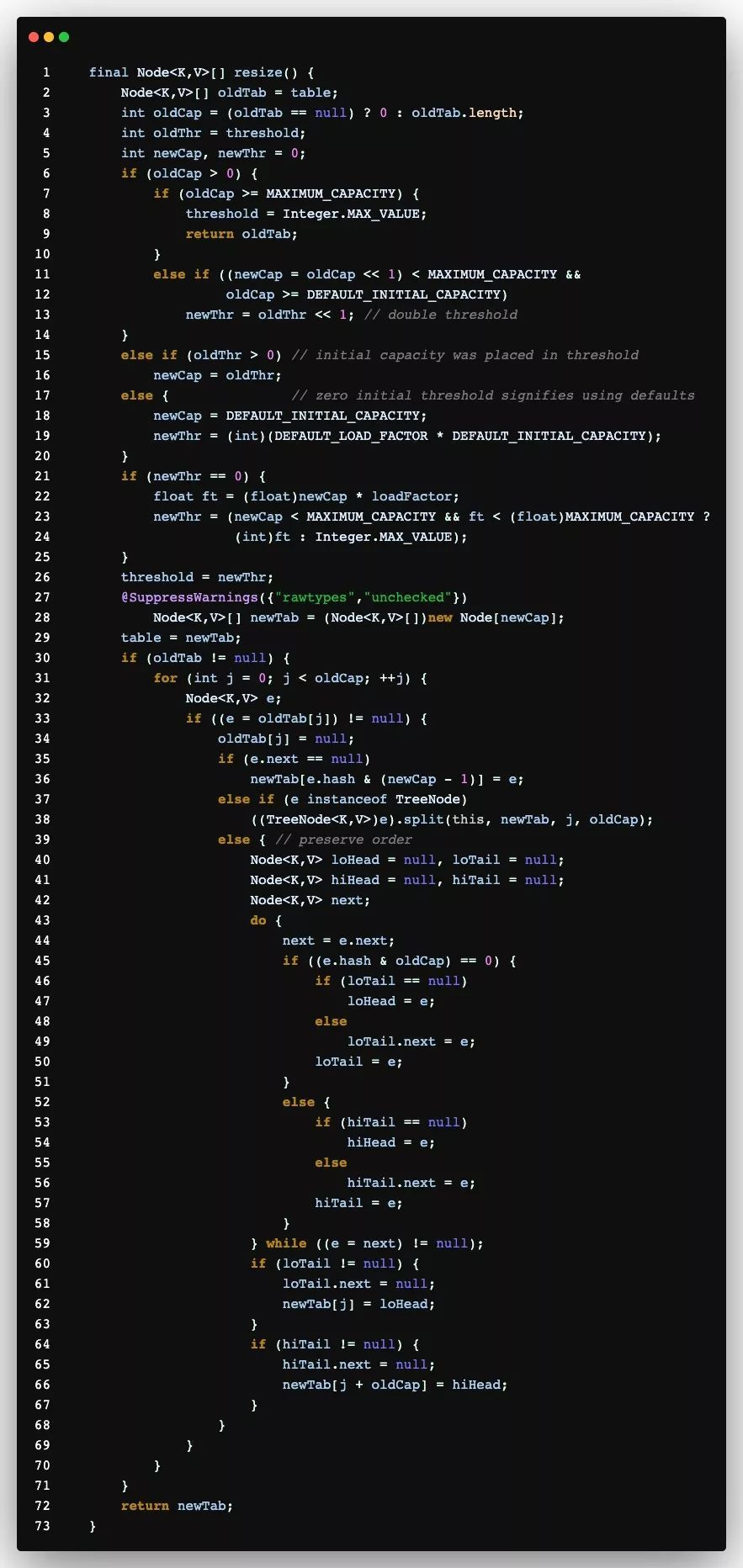
有兴趣的同学可以研究下JDK1.8的resize源码,写的很赞,如下:
参考:https://cloud.tencent.com/developer/article/1571903

 浙公网安备 33010602011771号
浙公网安备 33010602011771号