端侧模型部署(pytorch->paddle-lite)
端侧模型部署-Paddle Lite
1. 当前的环境:
- python:3.9
- pip管理:paddlelite==2.13rc0, x2paddle==1.6.0, paddlepaddle==2.6.2
- 使用的框架:YOLOv5 (当前还有YOLOv5u版本,链接)
(这些版本仅作为参考,是一个能够成功的案例。)
踩过的坑:
- 有些 Paddle-Lite 版本并未编译支持当前环境 Python 版本的 wheel,因此无法直接通过 pip 安装。例如 paddlelite2.12就没有 python3.9 编译的 whl(除非自己编译,但比较麻烦)
- paddlepaddle 版本影响从第三方模型(例如PyTorch)转为 Paddle model 的结果
最开始下载的 paddlepaddle 版本过高,导致生成的模型是如下的结构:
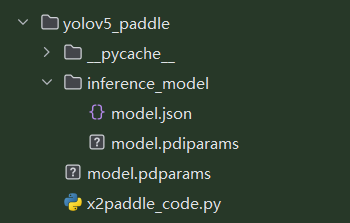
而传统的PaddlePaddle推理模型(及上述的 inference_model 目录下)应该包含.pdmodel(模型结构)和.pdiparams(模型参数)两个主要文件。
正常情况:
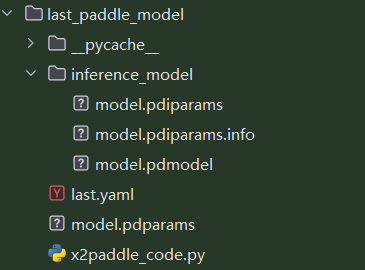
然而,在PaddlePaddle 3.0 beta 2及更高版本中,模型导出格式发生了变化。新版本会默认导出JSON格式的模型文件,而不是传统的protobuf格式。这种变化可能导致一些依赖传统格式的工具(如Paddle-Lite)无法正常工作。参考博客
2. 部署:第三方模型→ Paddle → Paddle-Lite
背景:将当前基于 YOLOv5 训练得到的模型部署至可运行的端侧设备,采用 PyTorch → Paddle → Paddle-Lite 的模型转换与部署路径。

-
将 YOLOv5 训练得到的模型权重.pt 转为 Paddle model
方法一 YOLOv5 expert.py 导出:
https://docs.ultralytics.com/zh/yolov5/tutorials/model_export/#exported-model-usage-examplespython export.py \ --weights runs/exp/weights/best.pt \ --img 640 \ --device cpu \ --include paddle踩过的坑:
尝试检测生成的 paddle 模型,官方的指令如下:
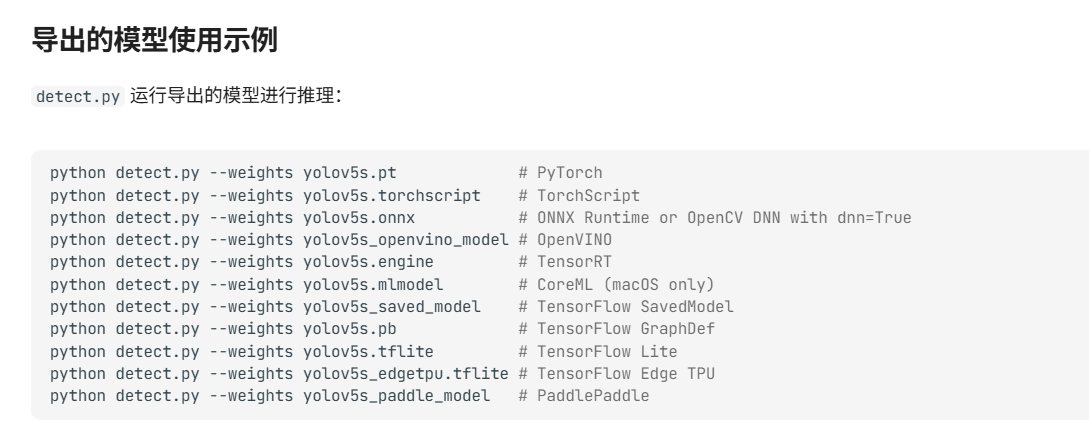
python detect.py --weights last_paddle_model将 export.py 导出的 paddle 模型直接用 YOLOv5 的 detect.py 去检测,但出现报错(因为 Paddle 的输出是 [1, 21, 64, 64], 而 detect.py 期望的输入是 [1, 3, 7, 80, 80] )。查 GPT 得到的原因如下(如有其他原因还请指正):

实际上,到此处为止已经不需要用 detect.py 去做验证了,直接用 Paddle-lite 去做后处理就好。方法二 X2Paddle convert 导出:
https://github.com/PaddlePaddle/X2Paddle/blob/develop/docs/inference_model_convertor/convert2lite_api.md
还没试过此方法,官方示例如下:x2paddle.convert.pytorch2paddle(module, save_dir, jit_type="trace", input_examples=None, convert_to_lite=False, lite_valid_places="arm", lite_model_type="naive_buffer")
-
将 Paddle model 转为 Paddle Lite
一、python api 方法(opt API文档):https://www.paddlepaddle.org.cn/lite/develop/api_reference/python_api/opt.html
import paddlelite.lite as lite import os """ https://www.paddlepaddle.org.cn/lite/develop/user_guides/model_optimize_tool.html lite_valid_places参数目前可支持 arm、 opencl、 x86、 metal、 xpu、 bm、 mlu、 intel_fpga、 huawei_ascend_npu、imagination_nna、 rockchip_npu、 mediatek_apu、 huawei_kirin_npu、 amlogic_npu,可以同时指定多个硬件平台(以逗号分隔,优先级高的在前),opt 将会自动选择最佳方式。如果需要支持华为麒麟 NPU,应当设置为 “huawei_kirin_npu,arm”。 """ a=lite.Opt() # 非 combined 形式 # a.set_model_dir("mobilenet_v1") # a.set_optimize_out("mobilenet_v1_opt") # a.set_valid_places("x86") # conmbined 形式,具体模型和参数名称,请根据实际修改 ori_model = 'last_paddle_model' place = 'arm' #'opencl,x86. failed: x86_opencl' a.set_model_file(f"../runs/{ori_model}/inference_model/model.pdmodel") a.set_param_file(f"../runs/{ori_model}/inference_model/model.pdiparams") # print("-all options for opt:") # a.print_supported_ops() dir = f"{ori_model}-lite-opt-" + place if not os.path.exists(dir): os.mkdir(dir) a.set_optimize_out(dir + "/opt") a.set_valid_places(place) a.run()二、命令行工具方法(opt 使用指南):
https://www.paddlepaddle.org.cn/lite/develop/user_guides/opt/opt_python.htmlpaddle_lite_opt \ --model_dir=<model_param_dir> \ --model_file=<model_path> \ --param_file=<param_path> \ --optimize_out_type=(protobuf|naive_buffer) \ --optimize_out=<output_optimize_model_dir> \ --valid_targets=(arm|opencl|x86|npu|xpu|huawei_ascend_npu|imagination_nna)\ --enable_fp16=(true|false) \ --quant_model=(true|false) \ --quant_type=(QUANT_INT16|QUANT_INT8)具体参数的含义可参考上述链接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号