六、神经网络-最大池化
前置知识
- 最大池化也可以称为下采样
- MaxPool2d中的参数:

stride:这里就和conv2d有了区别,在conv2d中stride的默认值是1,而maxpool2d中stride的默认值是kernel_size
ceil_mode:是否要向上取整,如下图,如果为true则该情况也会保留。默认为False。

最大池化的使用
目的:保留局部最大的特征,同时将数据量减小,常用于特征提取
import torch
from torch import nn
input=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]],dtype=torch.float32)
input=torch.reshape(input,(1,5,5))
print(input.shape)
class MM(nn.Module):
def __init__(self):
super(MM,self).__init__()
self.maxpool=nn.MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,x):
output=self.maxpool(x)
return output
mm=MM()
output=mm(input)
print(output)
- 当我们将ceil_mode设置为true的时候,保留不满的情况,得到的输出结果如下:
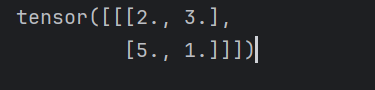
- 当我们将ceil_mode设置为false的时候,会舍去不满的情况,得到的输出结果如下:

用tensorboard展示最大池化的结果
将上面的input删除,导入数据集进行批量处理
dataset=torchvision.datasets.CIFAR10(root='./dataset', train=False, download=True,transform=torchvision.transforms.ToTensor())
dataloader=torch.utils.data.DataLoader(dataset,batch_size=64,shuffle=True)
class MM(nn.Module):
def __init__(self):
super(MM,self).__init__()
self.maxpool=nn.MaxPool2d(kernel_size=3,ceil_mode=False)
def forward(self,x):
output=self.maxpool(x)
return output
mm=MM()
writer=SummaryWriter("logs_maxpool")
step=0
for data in dataloader:
imgs,targets=data
writer.add_images("input",imgs,step)
outputs=mm(imgs)
writer.add_images("output",outputs,step)
step+=1
writer.close()
得到的结果如下所示,可见池化将图片变模糊了


 浙公网安备 33010602011771号
浙公网安备 33010602011771号