五、神经网络的基本框架-nn.module的使用、卷积
前置知识
super().init() 是用于调用父类的构造函数(初始化方法)
搭建简单的神经网络框架
import torch
from torch import nn
class MM(nn.module):
def __init__(self):
super(MM,self).__init__() # 调用父类的初始化函数
def forward(self,input):
output=input+1
return output
mm=MM()
x=torch.tensor(1.0)
output=mm(x) # 这里可以直接调用类,是因为所有nn.module类及继承自它的子类都含有特殊的call函数,而call函数中又会自动调用它内部的一些函数(例如这里的forward函数)
print(output)
卷积操作
以Conv2d为例,2D 卷积操作(Convolutional Operation),主要目的是 通过卷积核提取输入图像的局部特征。这种操作广泛应用于 图像处理、特征提取和深度学习中的 CNN(卷积神经网络)。
以下是Conv2d所需要的参数,这里是torch.nn.functional中的conv2d(区别一下torch.nn和torch.nn.functional:前者是对后者功能的一个封装)这里先介绍torch.nn.functional中的conv2d

事实上,卷积操作 是在输入图像上滑动卷积核,并计算 加权和 以生成特征图。
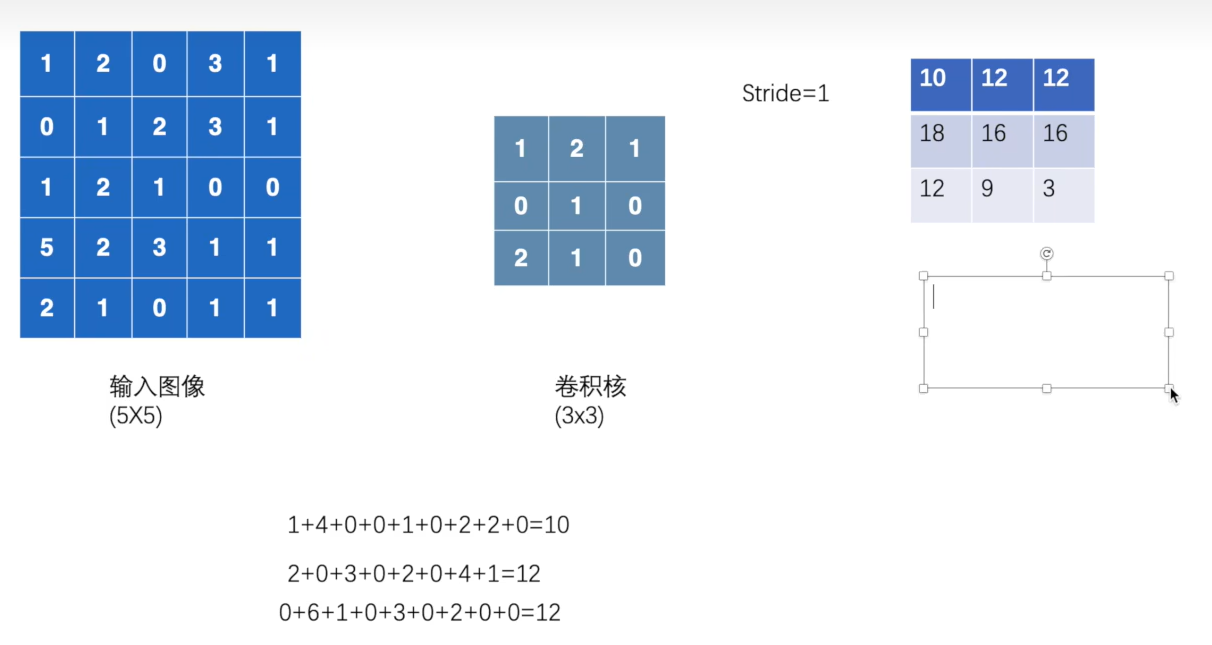
以下将做一个简单的示范:
import torch
import torch.nn.functional as F
# 输入的图像为以下数据
input=torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
# 以下为卷积核
kernel=torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
input=torch.reshape(input,(1,1,5,5))
kernel=torch.reshape(kernel,(1,1,3,3))
print(input.shape)
print(kernel.shape)
output=F.conv2d(input,kernel,stride=1)
print(output)
output2=F.conv2d(input,kernel,stride=2)
print(output2)
output3=F.conv2d(input,kernel,stride=1,padding=1)
print(output3)
得到的输出结果如下:

卷积层
这里便是直接对torch.nn中的conv2d进行使用。
以下展示了官方文档中的卷积操作动图:
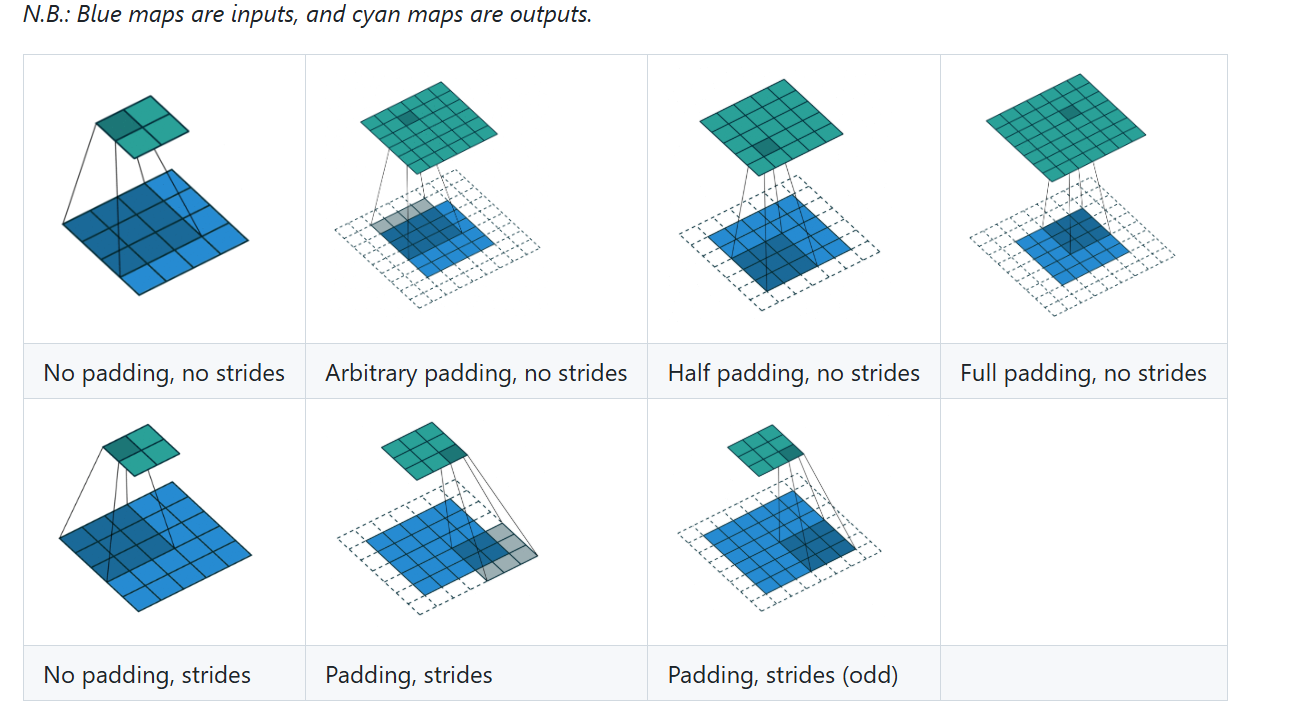
特殊:空洞卷积

简单示例:
dataset=torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader=DataLoader(dataset,batch_size=64,shuffle=True)
class MM(nn.Module):
def __init__(self):
super(MM,self).__init__()
self.conv1=Conv2d(3,6,3,1,0)
def forward(self,x):
x=self.conv1(x)
return x
mm=MM()
writer=SummaryWriter("logs")
step=0
for data in dataloader:
imgs,targets=data
output=mm(imgs)
print(imgs.shape)
print(output.shape)
# torch.Size([64, 3, 32, 32])
writer.add_images("input",imgs,step)
# torch.Size([64, 6, 30, 30])
output=torch.reshape(output,(-1,3,30,30)) # 由于tensorboard无法展示6 channels的图像,
# 所以在不太严谨的情况下需要将6切成3,
# 但因此会导致batch_size增多,在不知道它的大小之前,可以设置为-1
writer.add_images("output",output,step)
step+=1
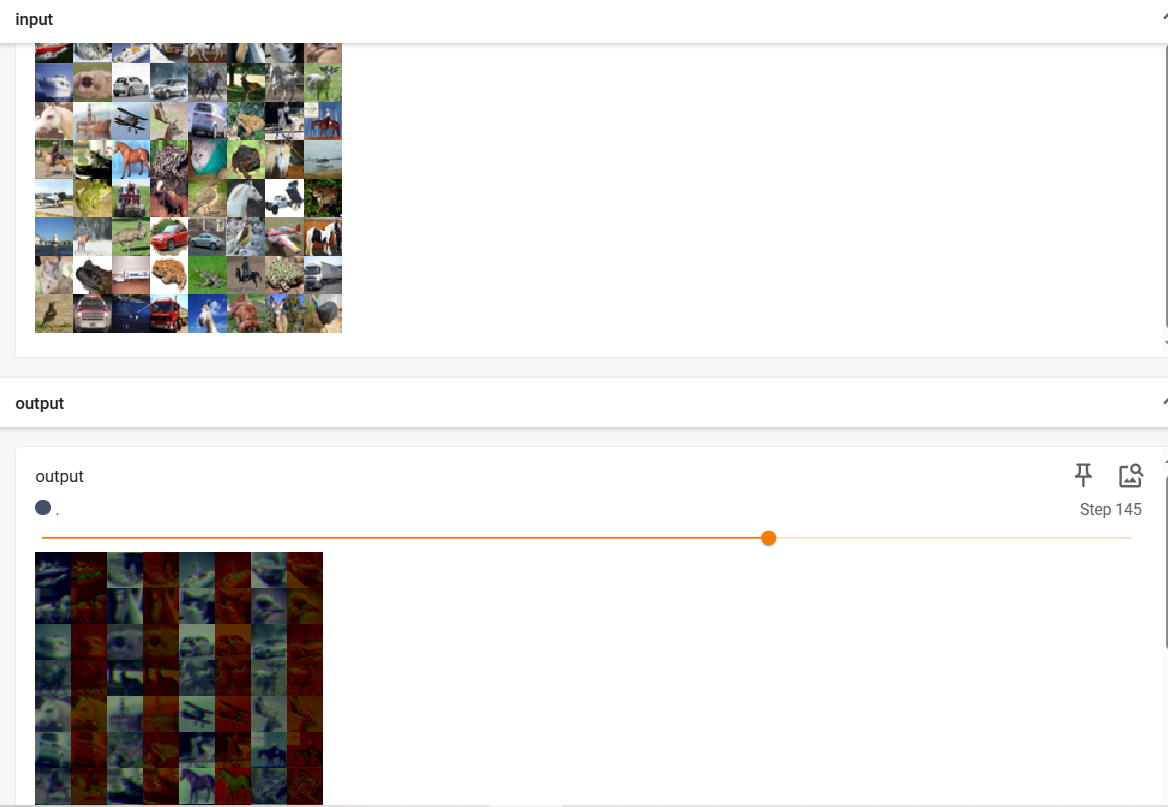
在tensorboard中的输出结果如下图所示:
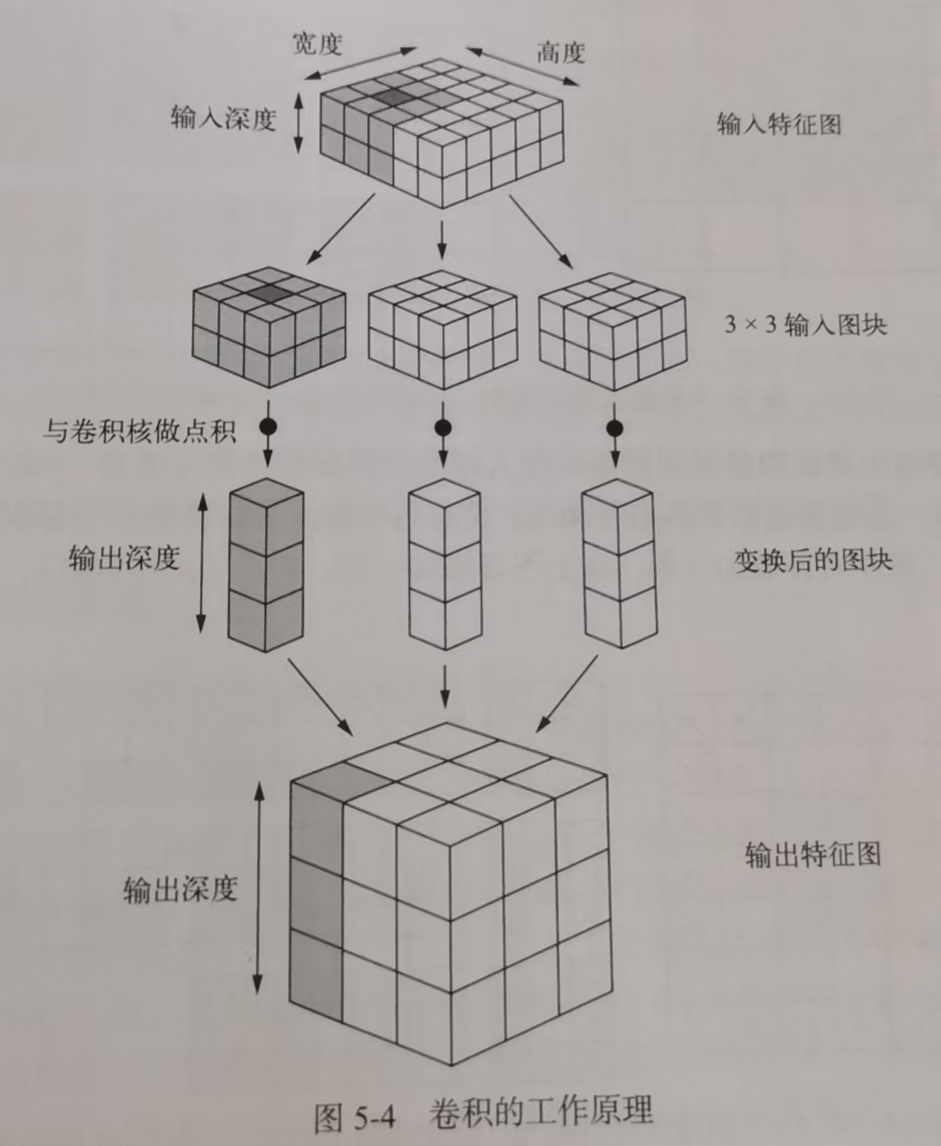
补充:3维卷积示意图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号