
第八章学习小结
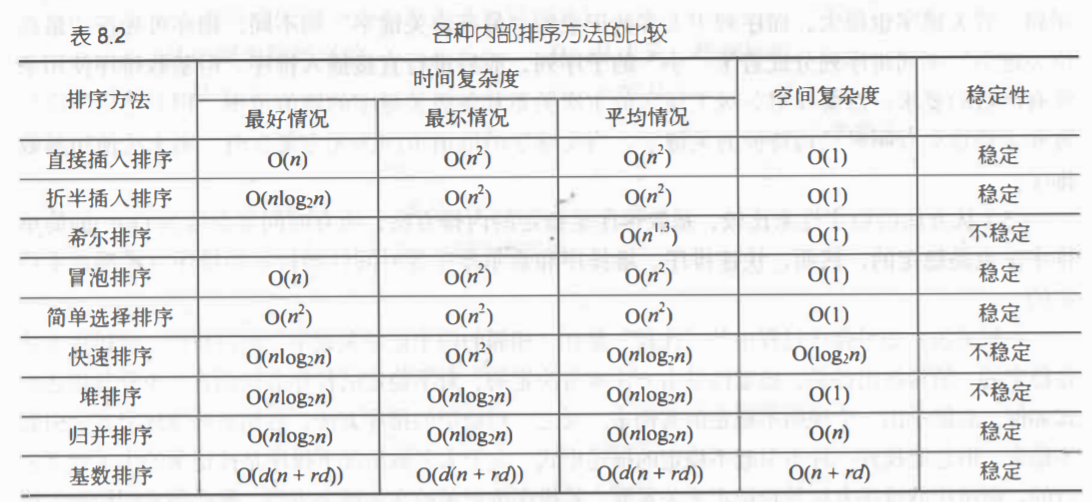
首先是各种排序的各方面比较,这张表还是比较全的。
1.折半插入排序
参考折半查找,折半插入操作类似。折半插入排序所需要的关键字比较次数与待排序序列的初始排列无关,仅依赖千记录的个数。
基本代码实现
void Binsert Sort(SqList &L) { for (i=2; i < =L. length; ++i) { L.r[O)=L.r[i); low=l;high=i-1; while(low<=high) { m=(low+high)/2; if(L.r[O) .key<L.r[m) .key) high=m-1; else low=m+l; } for (j=i一l;j>=high+l; --j) L.r[j+l]=L.r(j]; L.r[high+l]=L.r[O]; } }
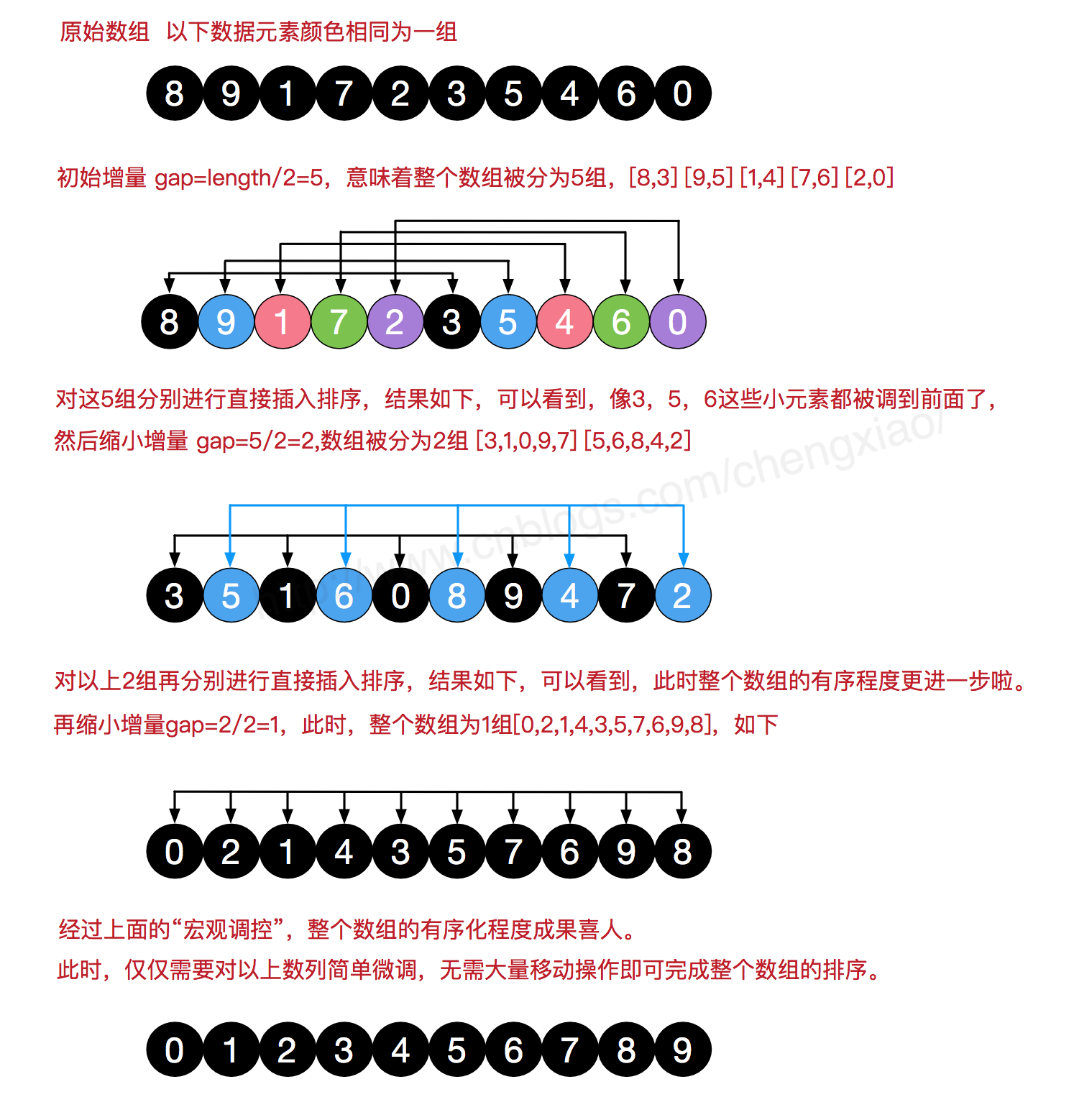
2.希尔排序
希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
引入图解:
3.冒泡排序
从第一个数开始,依次往后比较,如果前面的数比后面的数大就交换,否则不作处理。这就类似烧开水时,壶底的水泡往上冒的过程,较为简单。
基本代码实现
void BubbleSort(SqList &L) { m=L.length-1;flag=1; while ((m>O) && (flag==1)) { flag=O; for (j =1; j<=m; j ++) if(L.r[j] .key>L.r[j+1] .key) { flag=1; t=L.r[j); L.r[j)=L.r[j+1); L.r[j+1)=t; } --m; } }
4.快速排序
快速排序是冒泡排序的改进版。通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
图解:

5.堆排序
将待排序序列构造成一个大顶堆,此时,整个序列的最大值就是堆顶的根节点。将其与末尾元素进行交换,此时末尾就为最大值。然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了
建议参考:https://www.cnblogs.com/chengxiao/p/6129630.html
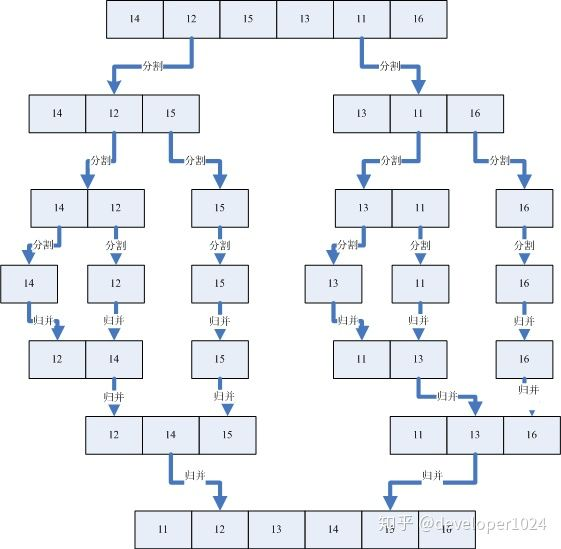
6.归并排序
归并排序是用分治思想,分治模式在每一层递归上有三个步骤:①将n个元素分成个含n/2个元素的子序列。②:用合并排序法对两个子序列递归的排序。③:合并两个已排序的子序列已得到排序结果。
图解示例:
基本代码实现:
void MSort(RedType R[],RedType &T[],int low,int high) {//R [low .. high]归并排序后放人 T[low.. high]中 if(low==high) T[low]=R[low]; else { mid=(low+high)/2; MSort(R,S,low,mid); MSort(R,S,mid+l,high); Merge(S,T,low,mid,high); } } void MergeSort(SqList &L) {//对顺序表 L 做归并排序 MSort(L.r,L.r,1,L.length); }
7.基数排序
基数排序可以看成是桶排序的扩展,以整数排序为例,主要思想是将整数按位数划分,准备 10 个桶,代表 0 - 9,根据整数个位数字的数值将元素放入对应的桶中,之后按照输入赋值到原序列中,依次对十位、百位等进行同样的操作,最终就完成了排序的操作。
建议参考演示视频:https://www.bilibili.com/video/av79834066/?p=2


 浙公网安备 33010602011771号
浙公网安备 33010602011771号