第七章学习小结
1.基础概念和术语
仅列出我在了解之前完全不知道的
(1)关键字:关键字是数据元素(或记录) 中某个数据项的值,用它可以标识一个数据元素(或记录)。
(2)动态查找表和静态查找表:若在查找的同时对表做修改操作(如插入和删除),则相应的表称之为动态查找表,否则称之 为静态查找表。
(3)平均查找长度(ASL)的计算方式:对于含有n个记录的表,查找成功时的平均查找长度为ASL= Pi+Ci(i:1~n)的和,Pi为查找表中第i个记录的概率,Pi(i:1~n)求和为1,C为找到表中其关键字与给定值
相等的第!个记录时,和给定值已进行过比较的关键字个数。
2.线性表查找
在书上找到一张图,比较全面的对比了顺序查找、折半查找和分块查找的区别。
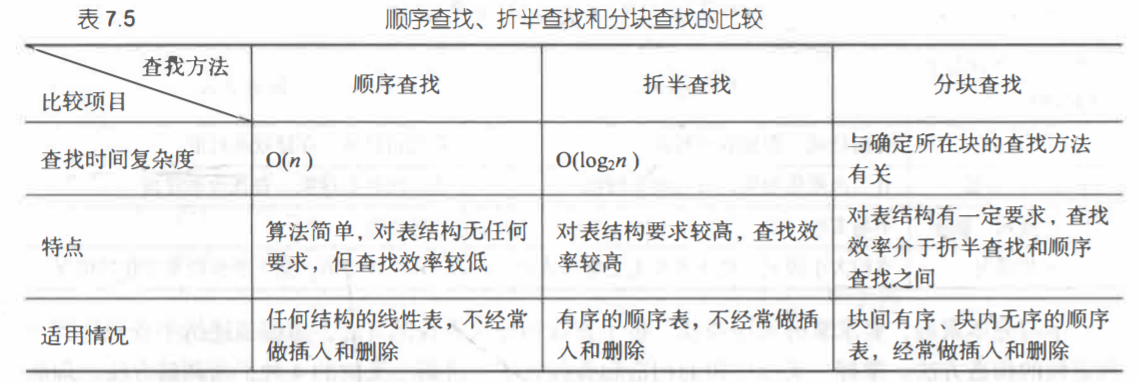
特别值得写的有几点,(1)顺序查找的存储数组中,一般第零号元素是闲置的,有“哨兵”的作用,防止在运行的时候进入死循环。查找时会倒序查找,即从最后一个元素开始往前查找。(2)折半查找中的
for循环中low<=high中的等于是不可去掉的,最简单的例子是查找表只有一个元素并且查找这个元素的时候。(3)判定树:把当前查找区间的中间位置作为根, 左子表和右子表分别作 为根的左子树和右子
树,由此得到的二叉树称为折半查找的判定树。经历比较的关键字个数恰为该结点在树中的层次。(4)折半查找法在查找成功时和给定值进行比较的关键 字个数至多为 log(2)n+ 1。(5)分块查找的平均
查找长度为ASL=(1/2)*((n/s)+s)+1。n为表长,s是每一块的记录数。
3.树表的查找
依旧是书上的一张较为全面的图。
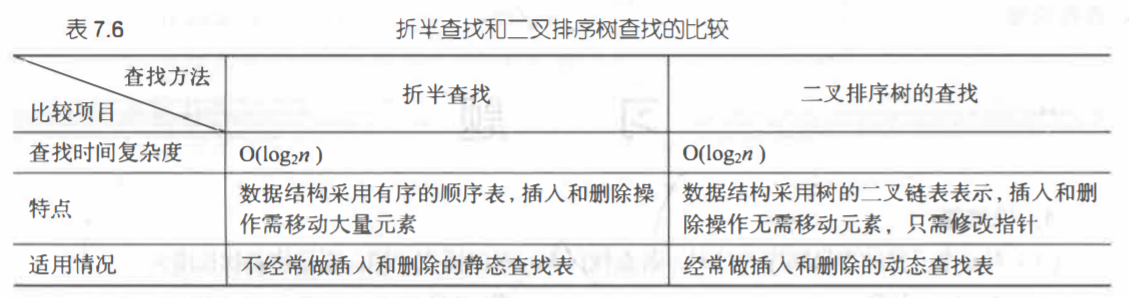
(1)二叉排序树:若它的左子树不空,则左子树上所有结点的值均小千它的根结点的值,若它的右子树不空,则右子树上所有结点的值均大千它的根结点的值,它的左、 右子树也分别为二叉排序树。
(2)二叉排序树中,平衡二叉树性能最好。平衡方法:LL型、RR型、LR型 和RL型。(3)B树:B-树是一种平衡的多叉查找树,是一种在外存文件系统中常用的动态索引技术。(4)B+树:B+树是一种
B-树的变型树,更适合做文件系统的索引。
3.散列表的查找
基础概念:(1)散列函数和散列地址:在记录的存储位置p和其关键字key 之间建立一个确定的对应关 系H, 使 p=H(key), 称这个对应关系H为散列函数,p为散列地址。(2)散列表:一个有限连续的地址
空间,用以存储按散列函数计算得到相应散列地址的数据 记录。通常散列表的存储空间是一个一维数组,散列地址是数组的下标。(3)同义词:具有相同函数值的关键字对该散列函数来说称作同义词。
(4)装填因子:a=表中填入记录数/散列表长度
处理冲突的两类方法:
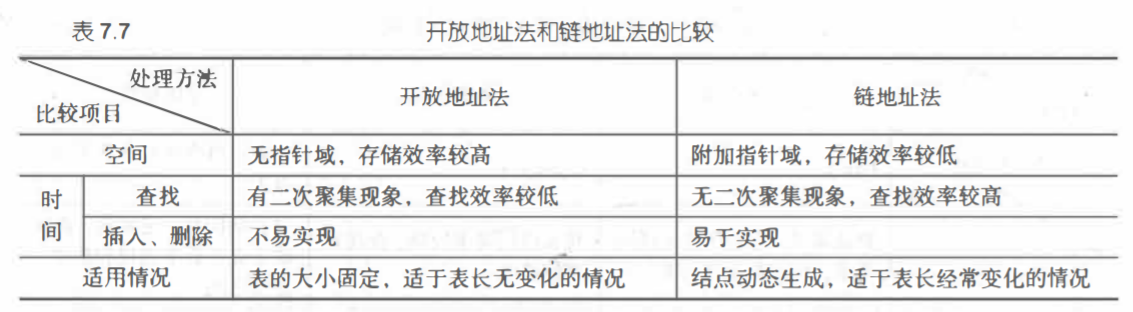
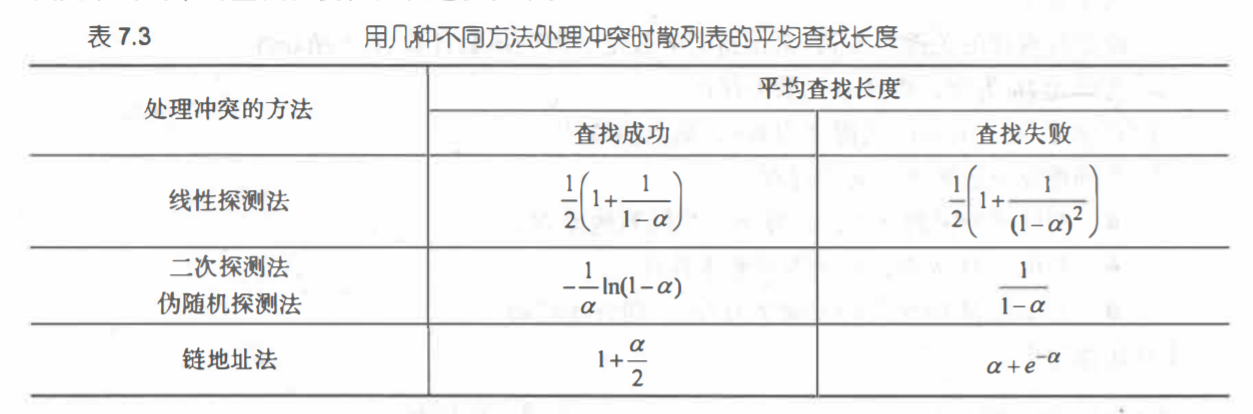
(1)开放地址法:主要方法:线性探测法:这种探测方法可以将散列表假想成一个循环表,发生冲突时,从冲突地址的下一单元顺 序寻找空单元,如果到最后 一个位置也没找到空单元,则回到表头开始继
续查找,直到找到 一个空位,就把此元素放入此空位中。如果找不到空位,则说明散列表已满,需要进行溢出 处理。通用公式:Hi=(H(key)+di)%m , i:1~k(k<=m-1) 。
二次探测法:di=1^2,-1^2,2^2,-2^2... +k^2,-k^2(k<=m/2)
(2)开放地址法:链地址法的基本思想是:把具有相同散列地址的记录放在同一个单链表中,称为同义词链 表。有 m 个散列地址就有 m 个单链表,同时用数组 HT[O…m-1]存放各个链表的头指针,凡是
散列地址为 l 的记录都以结点方式插入到以 HT[i]为头结点的单链表中。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号