

BAT机器学习面试1000题系列(第1~305题)
记录一些已经看过的题目。https://blog.csdn.net/v_JULY_v/article/details/78121924
1 请简要介绍下SVM,机器学习 ML模型 易
SVM,全称是support vector machine,中文名叫支持向量机。SVM是一个面向数据的分类算法,它的目标是为确定一个分类超平面,从而将不同的数据分隔开。
扩展:这里有篇文章详尽介绍了SVM的原理、推导,《支持向量机通俗导论(理解SVM的三层境界)》。此外,这里有个视频也是关于SVM的推导:《纯白板手推SVM》
8 说说你知道的核函数。机器学习 ML基础 易
通常人们会从一些常用的核函数中选择(根据问题和数据的不同,选择不同的参数,实际上就是得到了不同的核函数),例如:
- 多项式核 ,显然刚才我们举的例子是这里多项式核的一个特例(R = 1,d = 2)。虽然比较麻烦,而且没有必要,不过这个核所对应的映射实际上是可以写出来的,该空间的维度是
![]() ,其中 是原始空间的维度。
,其中 是原始空间的维度。
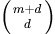 ,其中 是原始空间的维度。
,其中 是原始空间的维度。
- 高斯核
![]() ,这个核就是最开始提到过的会将原始空间映射为无穷维空间的那个家伙。不过,如果
,这个核就是最开始提到过的会将原始空间映射为无穷维空间的那个家伙。不过,如果![]() 选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上(数值上近似一下)相当于一个低维的子空间;反过来,如果
选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上(数值上近似一下)相当于一个低维的子空间;反过来,如果![]() 选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。不过,总的来说,通过调控参数
选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。不过,总的来说,通过调控参数![]() ,高斯核实际上具有相当高的灵活性,也是使用最广泛的核函数之一。下图所示的例子便是把低维线性不可分的数据通过高斯核函数映射到了高维空间:
,高斯核实际上具有相当高的灵活性,也是使用最广泛的核函数之一。下图所示的例子便是把低维线性不可分的数据通过高斯核函数映射到了高维空间:
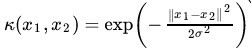 ,这个核就是最开始提到过的会将原始空间映射为无穷维空间的那个家伙。不过,如果
,这个核就是最开始提到过的会将原始空间映射为无穷维空间的那个家伙。不过,如果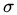 选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上(数值上近似一下)相当于一个低维的子空间;反过来,如果
选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上(数值上近似一下)相当于一个低维的子空间;反过来,如果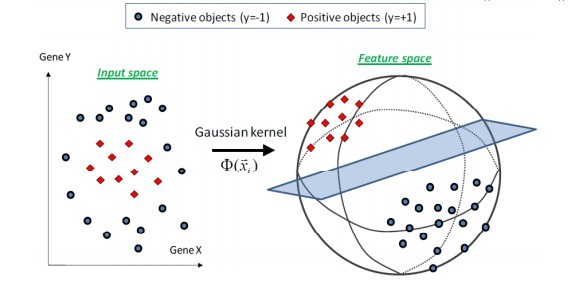
- 线性核
![]() ,这实际上就是原始空间中的内积。这个核存在的主要目的是使得“映射后空间中的问题”和“映射前空间中的问题”两者在形式上统一起来了(意思是说,咱们有的时候,写代码,或写公式的时候,只要写个模板或通用表达式,然后再代入不同的核,便可以了,于此,便在形式上统一了起来,不用再分别写一个线性的,和一个非线性的)。
,这实际上就是原始空间中的内积。这个核存在的主要目的是使得“映射后空间中的问题”和“映射前空间中的问题”两者在形式上统一起来了(意思是说,咱们有的时候,写代码,或写公式的时候,只要写个模板或通用表达式,然后再代入不同的核,便可以了,于此,便在形式上统一了起来,不用再分别写一个线性的,和一个非线性的)。
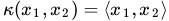 ,这实际上就是原始空间中的内积。这个核存在的主要目的是使得“映射后空间中的问题”和“映射前空间中的问题”两者在形式上统一起来了(意思是说,咱们有的时候,写代码,或写公式的时候,只要写个模板或通用表达式,然后再代入不同的核,便可以了,于此,便在形式上统一了起来,不用再分别写一个线性的,和一个非线性的)。
,这实际上就是原始空间中的内积。这个核存在的主要目的是使得“映射后空间中的问题”和“映射前空间中的问题”两者在形式上统一起来了(意思是说,咱们有的时候,写代码,或写公式的时候,只要写个模板或通用表达式,然后再代入不同的核,便可以了,于此,便在形式上统一了起来,不用再分别写一个线性的,和一个非线性的)。13 谈谈判别式模型和生成式模型?机器学习 ML基础 易
判别方法:由数据直接学习决策函数 Y = f(X),或者由条件分布概率 P(Y|X)作为预测模型,即判别模型。
生成方法:由数据学习联合概率密度分布函数 P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型。
由生成模型可以得到判别模型,但由判别模型得不到生成模型。
常见的判别模型有:K近邻、SVM、决策树、感知机、线性判别分析(LDA)、线性回归、传统的神经网络、逻辑斯蒂回归、boosting、条件随机场常见的生成模型有:朴素贝叶斯、隐马尔可夫模型、高斯混合模型、文档主题生成模型(LDA)、限制玻尔兹曼机
14 L1和L2的区别。机器学习 ML基础 易
L1范数(L1 norm)是指向量中各个元素绝对值之和,也有个美称叫“稀疏规则算子”(Lasso regularization)。
比如 向量A=[1,-1,3], 那么A的L1范数为 |1|+|-1|+|3|.
简单总结一下就是:
L1范数: 为x向量各个元素绝对值之和。
L2范数: 为x向量各个元素平方和的1/2次方,L2范数又称Euclidean范数或者Frobenius范数
Lp范数: 为x向量各个元素绝对值p次方和的1/p次方.
在支持向量机学习过程中,L1范数实际是一种对于成本函数求解最优的过程,因此,L1范数正则化通过向成本函数中添加L1范数,使得学习得到的结果满足稀疏化,从而方便人类提取特征。
L1范数可以使权值稀疏,方便特征提取。
L2范数可以防止过拟合,提升模型的泛化能力。
@AntZ: L1和L2的差别,为什么一个让绝对值最小,一个让平方最小,会有那么大的差别呢?看导数一个是1一个是w便知, 在靠进零附近, L1以匀速下降到零, 而L2则完全停下来了. 这说明L1是将不重要的特征(或者说, 重要性不在一个数量级上)尽快剔除, L2则是把特征贡献尽量压缩最小但不至于为零. 两者一起作用, 就是把重要性在一个数量级(重要性最高的)的那些特征一起平等共事(简言之, 不养闲人也不要超人)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号