

软工作业2:个人项目
作业要求
| 作业要求 | 完成论文查重算法 |
|---|---|
| 作业目标 | 实现论文查重系统,输出原文和抄袭文章的相似度 |
| GitHub链接 | https://github.com/VahidLee/VahidLee |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| Estimate | 估计这个任务所需时间 | 600 | 1005 |
| Development | 开发 | 400 | 480 |
| Analysis | 需求分析 | 10 | 10 |
| Design Spec | 生成设计文档 | 10 | 10 |
| Design Review | 设计复审 | 10 | 10 |
| Coding Standard | 代码规范 | 25 | 25 |
| Design | 具体设计 | 120 | 150 |
| Coding | 具体编码 | 180 | 240 |
| Code Review | 代码复审 | 30 | 20 |
| Test | 测试(自我测试、修改代码、提交修改) | 40 | 20 |
| Reporting | 报告 | 20 | 20 |
| Test Report | 测试报告 | 10 | 5 |
| Size Measuerment | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 15 | 60 |
项目需求
题目:论文查重
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:
从命令行参数给出:论文原文的文件的绝对路径。
从命令行参数给出:抄袭版论文的文件的绝对路径。
从命令行参数给出:输出的答案文件的绝对路径。
注意:输出格式为小数点后两位
实现原理
读出文件、写入文件
TxtIO.java实现文件的读出和写入,利用正则表达式去除某些文本中的HTML标记。
相似度计算
CalSimilarity.java通过HashSet来比对两个文件的相同字符个数所占原文件的个数,来计算相似度。
性能分析
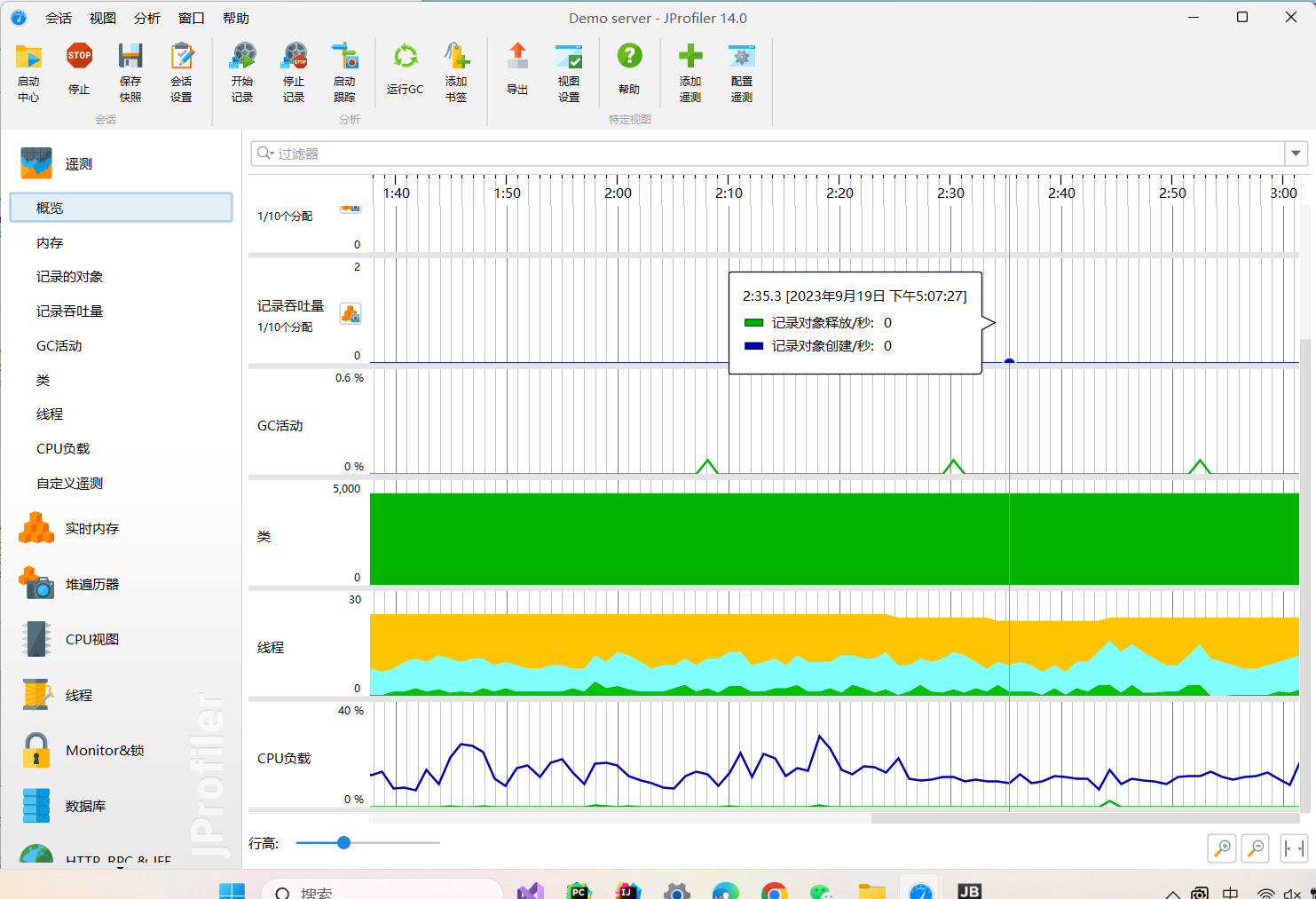
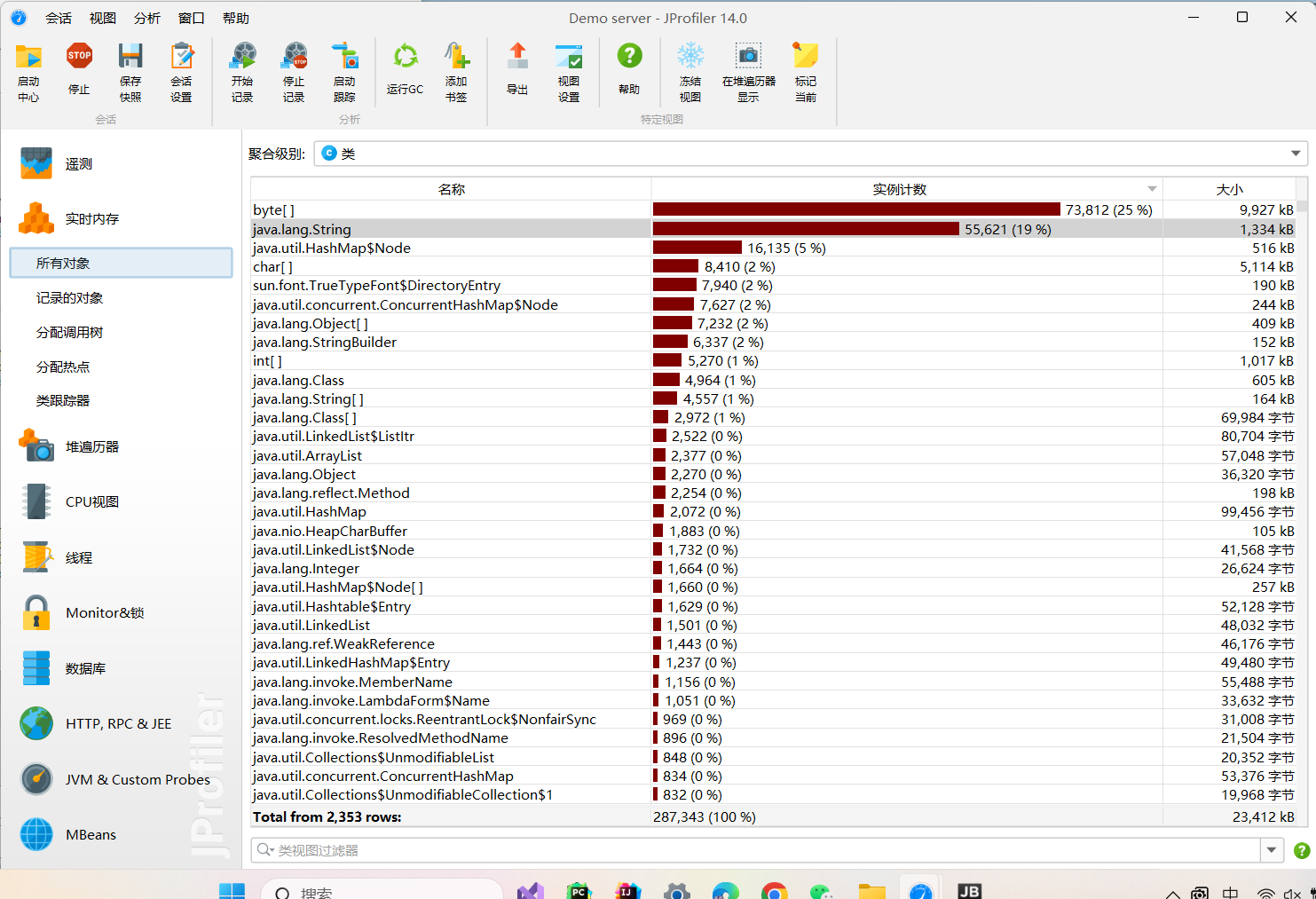
该查重算法实现均依赖于原生java库,编码简单,运行时间短。
代码覆盖率
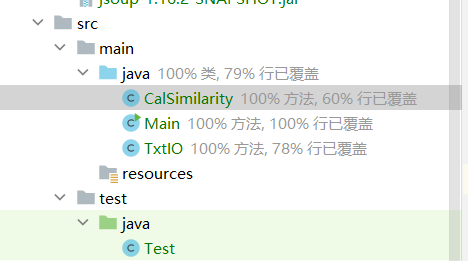
Main类的代码实现100%覆盖,TxtIO类因为有异常捕获机制所以有些代码未被覆盖,CalSimilarity类的代码覆盖率还有改进空间。
改进后的代码覆盖率
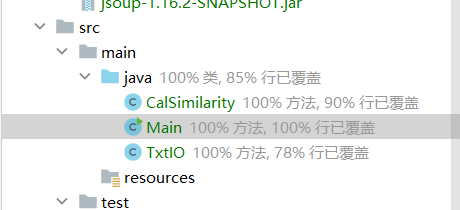
将重复的部分提取成一个方法,再优化部分代码后,CalSimilarity的覆盖率得到提高。
控制台输入样例

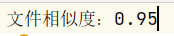
输出结果

结果文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号