Kafka简介
1.Kafaka主要设计目标
• 以时间复杂度O(1)的方式提供消息持久化的能力,即使对TB级数据也能保证常数时间的访问性能。
• 高吞吐率,即使在非常廉价的商用机器上也能做到单机每秒100K条消息的传输。
• 支持Kafka Server间消息分区记忆分布式消费
• 支持离线数据处理和事实数据处理
• Scale out:支持在线水平扩展
2.发布-订阅模式
kafka采用了发布-订阅的消息模式来传递模式。在发布-订阅消息中,消息被持久化到一个topic中,与点对点消息系统不同的是,消费者可以订阅一个或多个topic,消费者可以消费该topic中的所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。在发布-订阅消息系统中,消息的生产者被称为发布者,消费者称为订阅者。发布者发送数据到topic的消息,只有订阅了topic的订阅者才会收到消息。
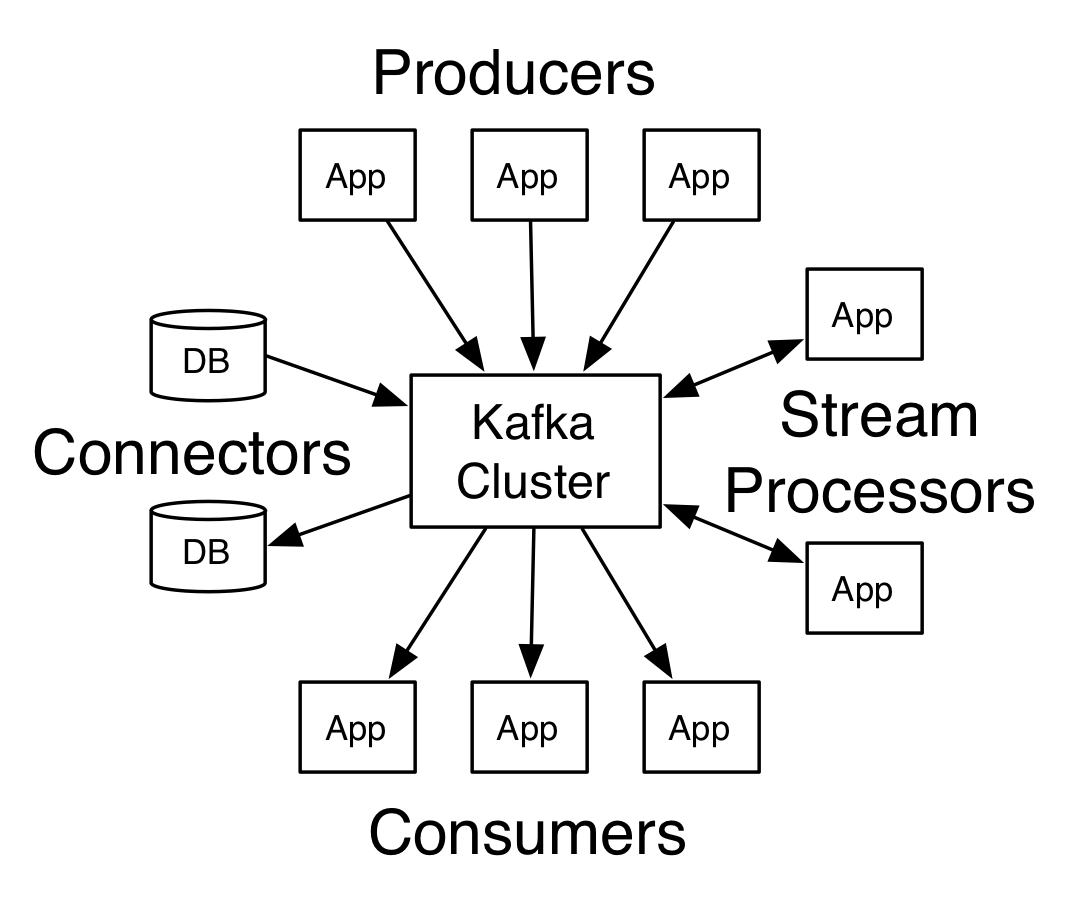
3.1 Broker
Kafka集群包含一个或者多个服务器,服务器节点称为Broker。
Broker存储Topic的数据,
► 如果某个Topic有N个Partition,集群有N个Broker,那么每个Broker存储该topic的一个Partition。
► 如果某个topic有N个Partition,集群有N+m个Broker,那么N个broker存储该topic的一个Partition,剩余的M个Broker不存储该Topic的Partition数据。
► 如果某个Topic有N个Partition,集群中Broker的数目少于N个,那么一个Broker存储该Topic的一个或者多个Partition,在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
3.2 Topic
每条发布到Kafka集群中的小时都有一个类别,这个类别被称为Topic。物理上不同的Topic的消息分开存储,逻辑上一个Topic的消息虽然保存在一个或者多个broker上,但是用户只需要制定消息的Topic即可,生产或者消费数据二不必关心数据存储与何处。(有点类似于数据库中的表名)
3.3Partition
Topic中的数据分割为一个或者多个partition。每个Topic至少有一个Partition。每个Partition中的数据使用多个segment文件存储。Partition中的数据是有序的,不同Partition间的数据丢失了数据的顺序。如果Topic有多个Partition消费数据时就不能保证数据的顺序,在需要严格保证消息的消费顺序的场景下,需要将Partition数目设为1.
3.4 Producer
生产者既数据的发布者,该角色将消息发布到Kafka的Topic中。Broker接受到生产者发送的消息后,Broker将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的Partition。
3.5 Consumer
消费者可以从broker中读取数据。消费者可以消费多个Topic中的数据。
3.6 Consumer Group
每一个Consumer属于一个特定的Consumer Group。可以为一个Consumer指定Group Name.若不指定Group Name则属于默认的Group。
3.7 Leader
每个Partition有多个副本,其中有且仅有一个Leader。Leader是当前负责数据读写的Partition。
3.8 Follower
Follower跟随Leader,所有写请求都是通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步,如果Leader失效,则从Follower中选举一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,Leader会吧这个Follower从“in sync relicas”(ISR)列表中删除,重新创建一个Follower。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号