hadoop3.0 +hive3.x 集群环境搭建
一、环境清单
| hostname | 说明 | 已安装软件 |
|---|---|---|
| hadoop235 | mysql5.7 | |
| hadoop236 | namenode | hadoop3.0,hive-3.1.2 |
| hadoop237 | SecondaryNameNode、JobHistoryServer | hadoop3.0 |
| hadoop238 | ResourceManager | hadoop3.0 |
二、hadoop 环境搭建
配置主机hosts文件
172.20.10.235 hadoop235
172.20.10.236 hadoop236
172.20.10.237 hadoop237
172.20.10.238 hadoop238
免密登录 (双向都需执行)
- hadoop236想登录hadoop237,需要将hadoop236的密钥信息拷贝到hadoop237机器
ssh-keygen -t rsa
ssh-copy-id hadoop237
2.1 配置jdk 8环境
2.1.1 卸载自带jdk
# 卸载自带jdk7
rpm -qa | grep jdk 或 rpm -qa | grep java | xargs rpm -e --nodeps
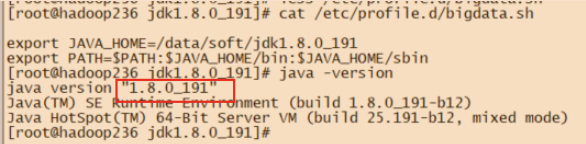
2.1.2 配置jdk8
- 编辑
/etc/profile.d/bigdata.sh,并执行source命令
export JAVA_HOME=/data/soft/jdk1.8.0_191
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/sbin
2.2 配置hadoop 3环境
2.2.1 hdfs配置
1. hadoop-env.sh
export JAVA_HOME=/data/soft/jdk1.8.0_191
2. core-site.xml
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop236:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/soft/modules/hadoop-3.0.0/dataDir</value>
</property>
</configuration>
3.hdfs-site.xml
<configuration>
<!--指定namenode web ui的地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop236:9870</value>
<description>
The address and the base port where the dfs namenode web ui will listen on.
</description>
</property>
<!--指定secondaryNamenode web ui的地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop237:9868</value>
<description>
The secondary namenode http server address and port.
</description>
</property>
</configuration>
3. yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop238</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop237:19888/hadoop/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为30天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>2592000</value>
</property>
</configuration>
4. mapred-site.xml
<configuration>
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop237:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop237:19888</value>
</property>
</configuration>
5. workers
hadoop236
hadoop237
hadoop238
6. 配置环境变量和启动用户权限 /etc/profile.d/bigdata.sh
export HADOOP_HOME=/data/soft/modules/hadoop-3.0.0
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
7. 拷贝代码
8. 格式化和启动、查看、环境测试
hdfs namenode -format # 在hadoop236上执行(查看core-site.xml配置)
start-dfs.sh
start-yarn.sh # 在hadoop238上执行(查看yarn-site.xml配置)
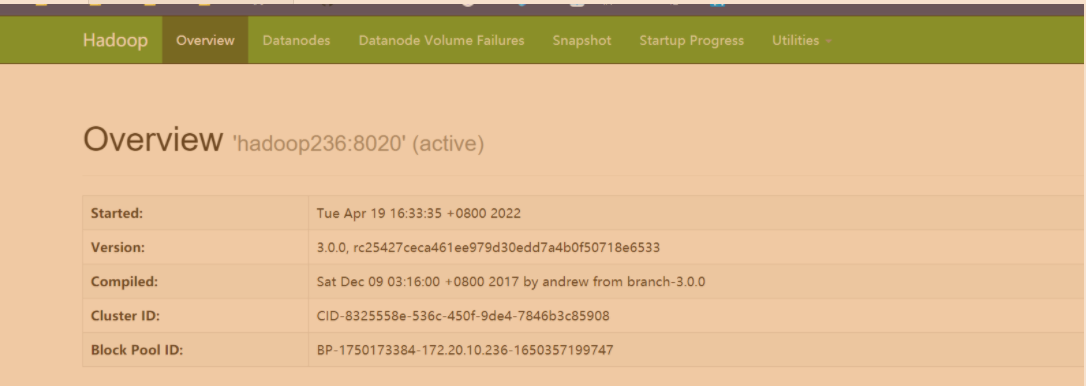
- 查看hdfs UI
http://hadoop236:9870/
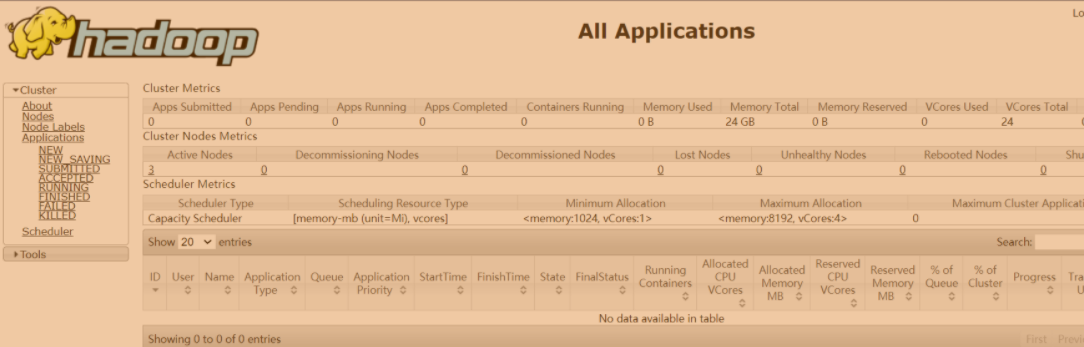
- 查看yarn UI
http://hadoop238:8088/cluster注意resourcemanager所在机器上机器和查看
hadoop jar /data/soft/modules/hadoop-3.0.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar wordcount /testdir/input/demo01/wordcount /testdir/output/demo01/wordcount
9. 配置历史服务器,方便查看job的运行状况 mapred-site.xml
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop237:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop237:19888</value>
</property>
10. 分发代码、启动历史服务器、UI查看
mapred --daemon start historyserver # 在hadoop237上执行
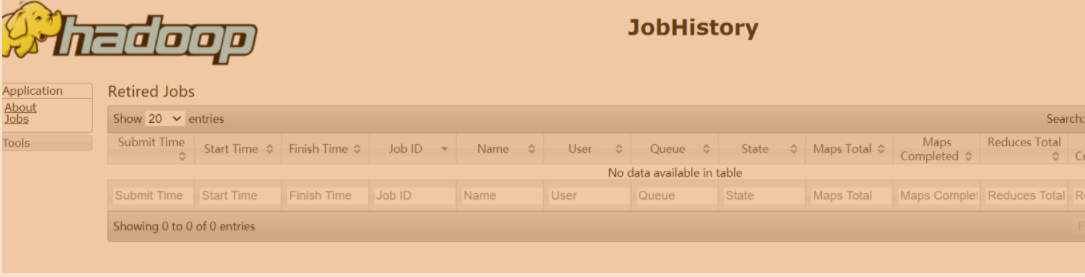
- 查询任务历史日志
http://hadoop237:19888/jobhistory注意在hadoop237上执行启动命令mapred --daemon start historyserver
![]()
11. 配置yarn日志收集到hdfs yarn-site.xml
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop237:19888/hadoop/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为30天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>2592000</value>
</property>
12. 重启yarn和历史日历服务
mapred --daemon stop historyserver # 在hadoop237上执行 mapred-site.xml
stop-yarn.sh # 在resourcemanager所在机器上执行(yarn-site.xml指定)
三、hive环境配置
3.1 配置系统环境
export HIVE_HOME=/opt/module/hive-2.3.7
export PATH=$PATH:$HIVE_HOME/bin:$HIVE_HOME/sbin
3.2 处理log4j冲突
# 防止日志冲突
mv lib/log4j-slf4j-impl-2.6.2.jar lib/log4j-slf4j-impl-2.6.2.jar.bak
3.3 安装hive元信息存储库:mysql5.7
mysql-5.7.22-linux-glibc2.12-x86_64.tar.gz
create database hiveDB_metastore charset=utf8;
3.4 添加mysql连接驱动
# 将mysql-jdbc驱动放到 hive/lib下
3.5 修改hive-site.xml配置
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc 连接的 URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/hiveDB_metastore?useSSL=false</value>
</property>
<!-- jdbc 连接的 Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc 连接的 username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc 连接的 password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive 默认在 HDFS 的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
</property>
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!-- 使用 JDBC 方式访问 Hive; 指定 hiveserver2 连接的 host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hdp232</value>
</property>
<!-- 指定 hiveserver2 连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
3.6 初始化元数据配置表
schematool -initSchema -dbType mysql -verbose
3.7 启动hive服务(可用jdbc连接)
bin/hive --service hiveserver2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号