
线上内存泄露bug分析记录
一、问题出现
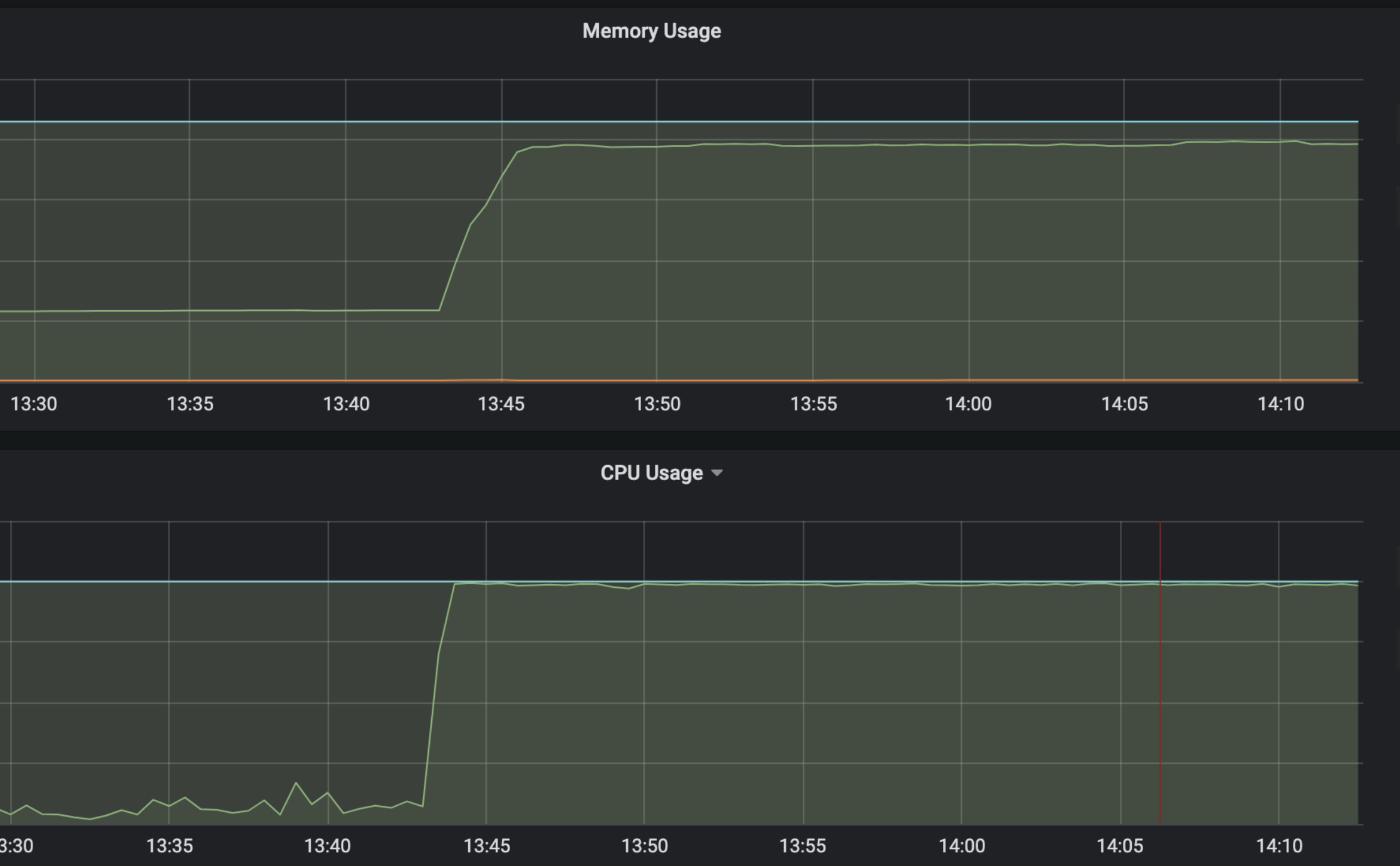
pod内存与cpu几乎同时开始飙升,同时到限制的峰值:
二、假想
可能是主键加密与雪花ID的新增特性导致CPU和内存不够?
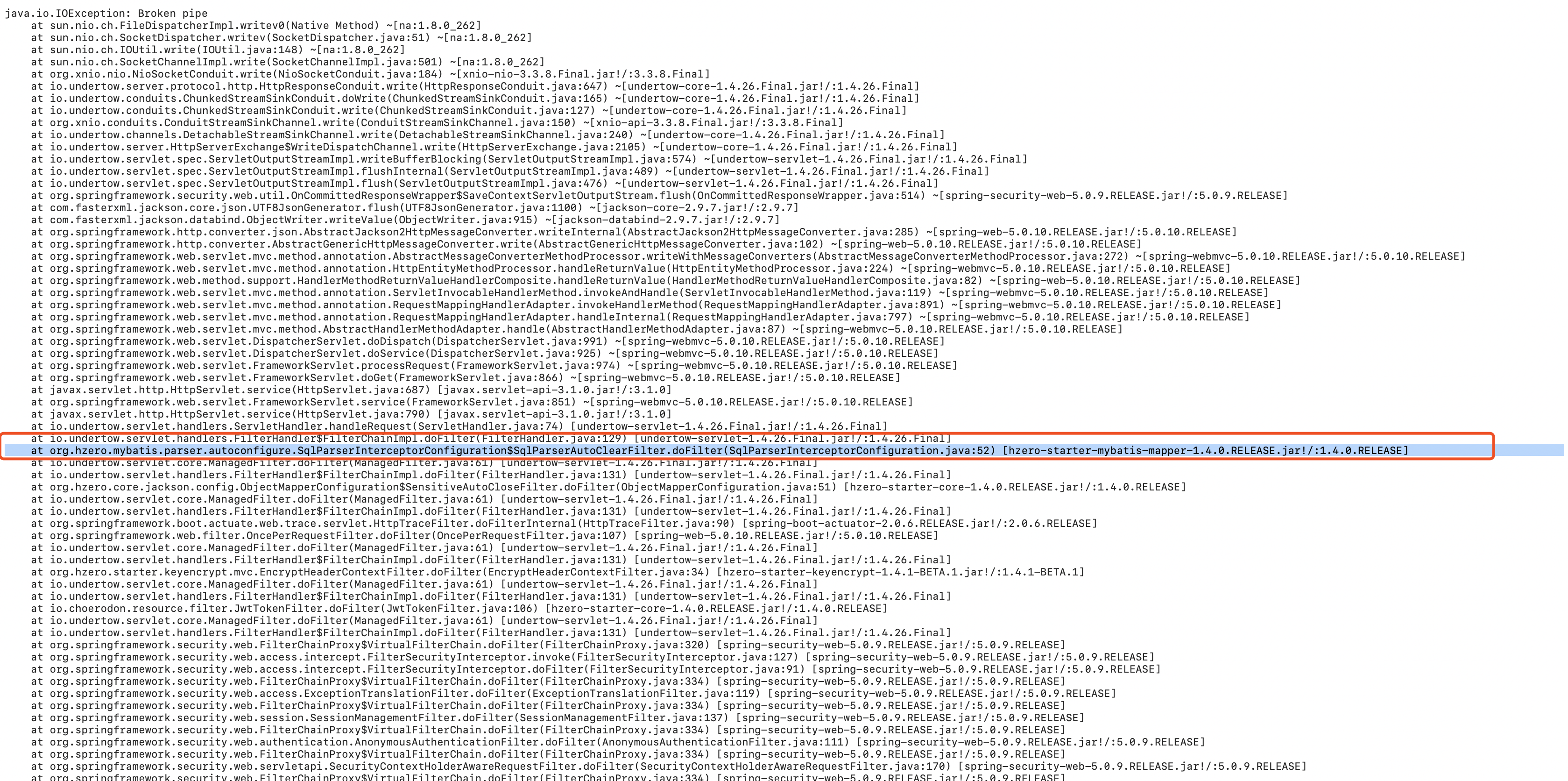
由于上图报错可追溯到的自己的代码最近一行就是hzero抛出,一度怀疑是主键加密导致的性能问题,于是把服务器配置从2c8G加到8c16G,CPU无峰值限制,结果不到1小时还是出现内存和CPU使用同时达到峰值。
对主键加密压测后得到:100的线程组循环100次,CPU耗费在30%左右。所以基本上排除了主键加密。
刚开始走的弯路很多,一直以为CPU是由于用户操作产生,所以一直在分析接口占用CPU的损耗。但是这里很特殊,内存和CPU几乎同时达到峰值,而接口(比如导出Excel,优化了jvm内存占用后)虽然消耗CPU,但是并不吃内存,很明显不会同时飙升。
三、正确的思路
使用jmap分析jvm具体信息
jmap -histo[:live] [pid] // 打印每个class的实例数目,内存占用,类全名信息. VM的内部类名字开头会加上前缀”*”. 如果live子参数加上后,只统计活的对象数量.
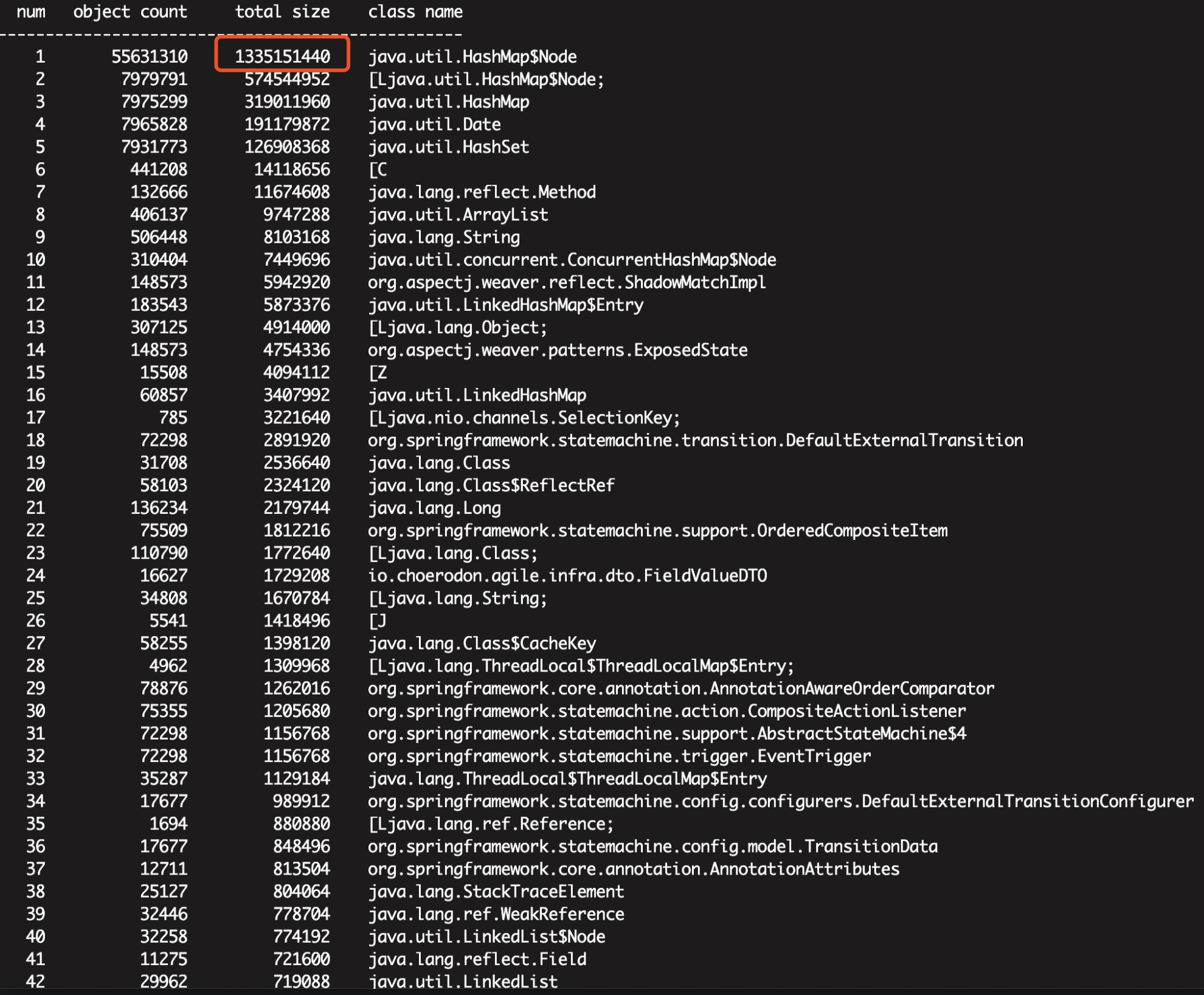
拉取heap信息,由于.phd文件太大,可借助工具IBM HeapAnalyzer打开

使用IBM HeapAnalyzer分析heap情况

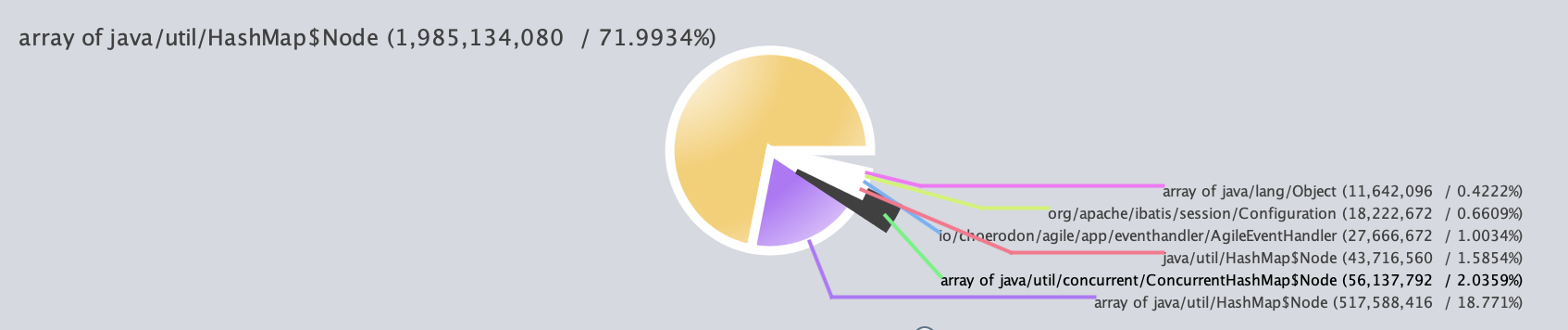
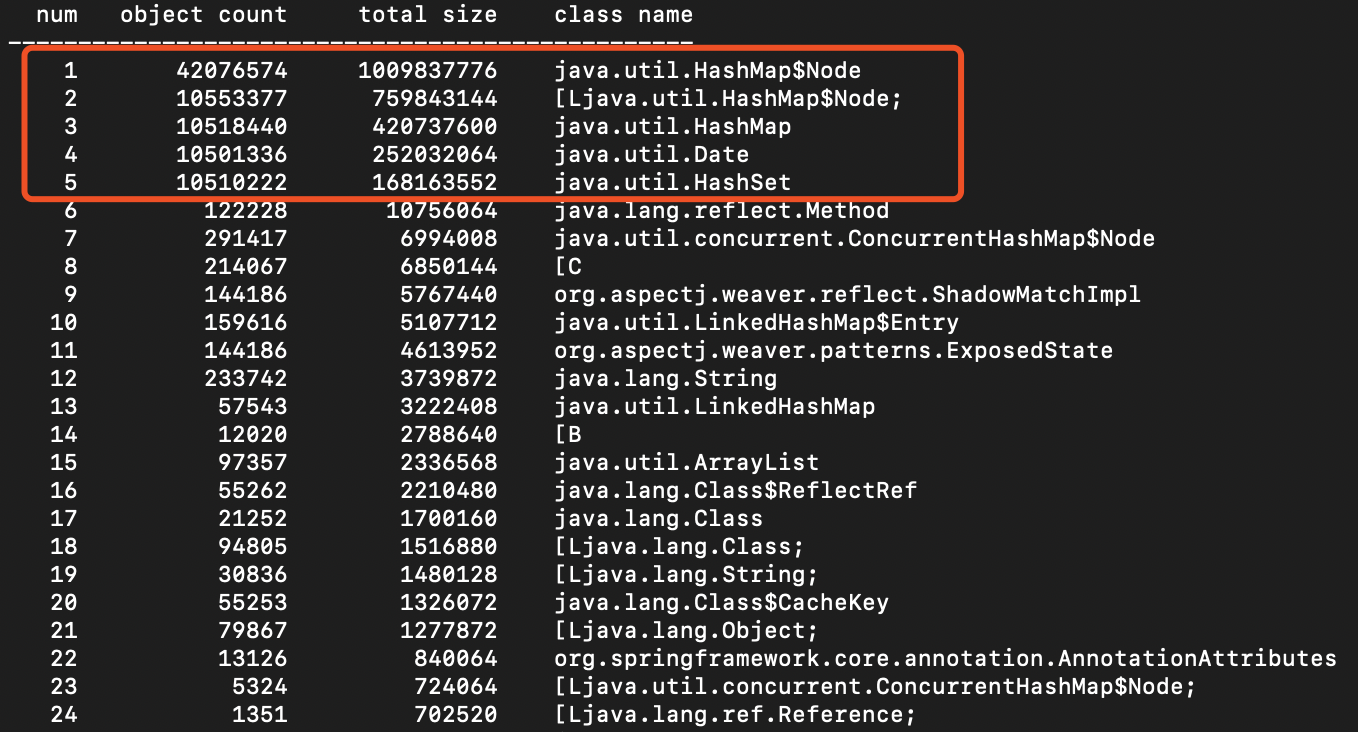
最强大之处在于,Reference Tree->Leak Suspect,找到泄露嫌疑最大的那个对象,即上图的HashMap对象。层层展开后,找到最底层的对象,就可以找到你们熟悉的类了。
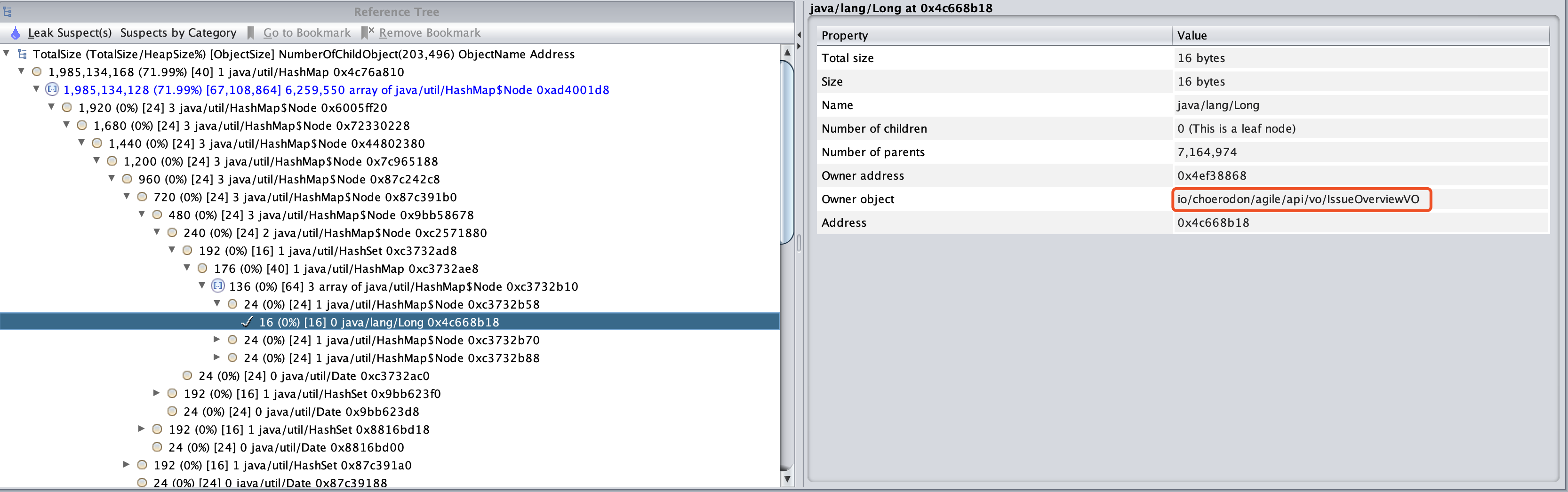
定位到这个类后,代码排除到这个类的所有接口,就得到了以下优美的图形
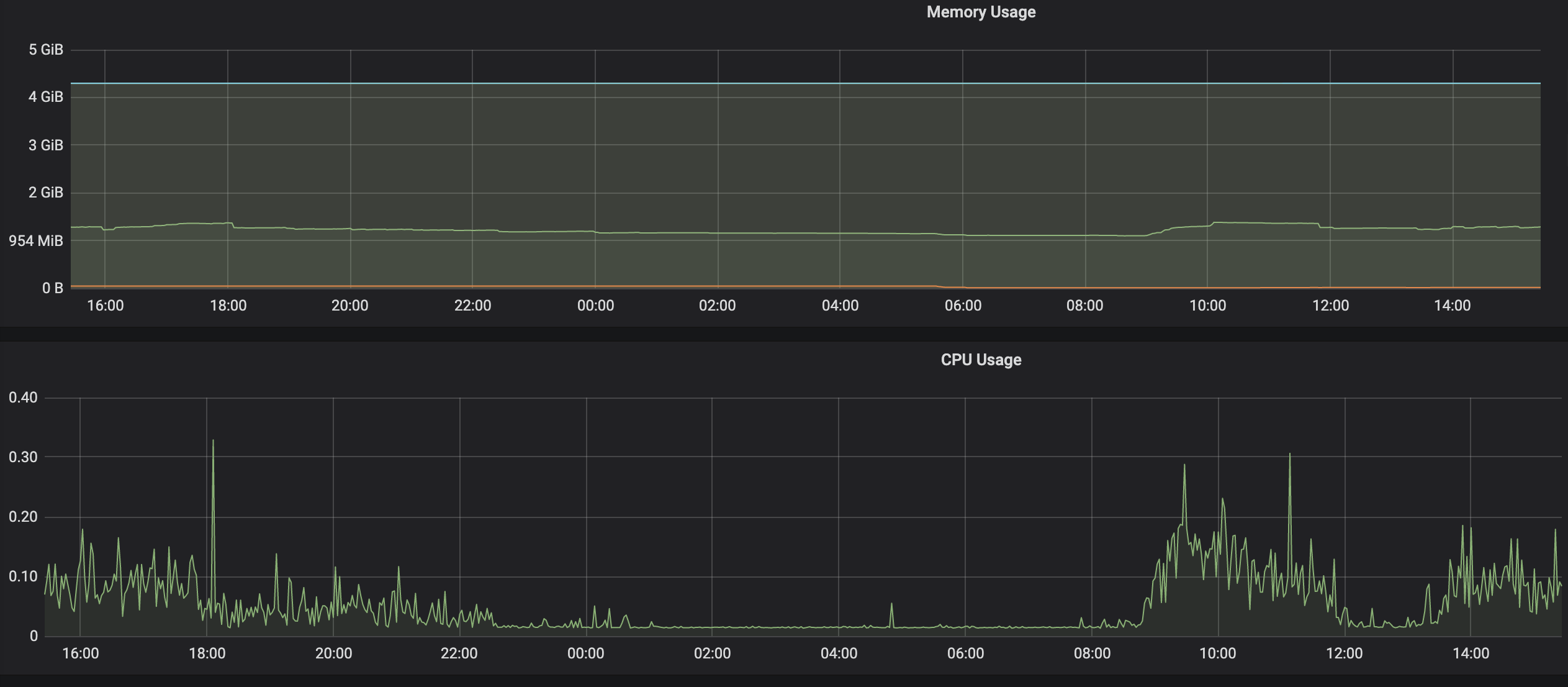
最终得出的结论:hashMap内存泄露2个G,导致jvm疯狂gc,cpu消耗也要跟着涨。
四、查找代码原因
查看代码,分析HashMap泄露的真正原因:
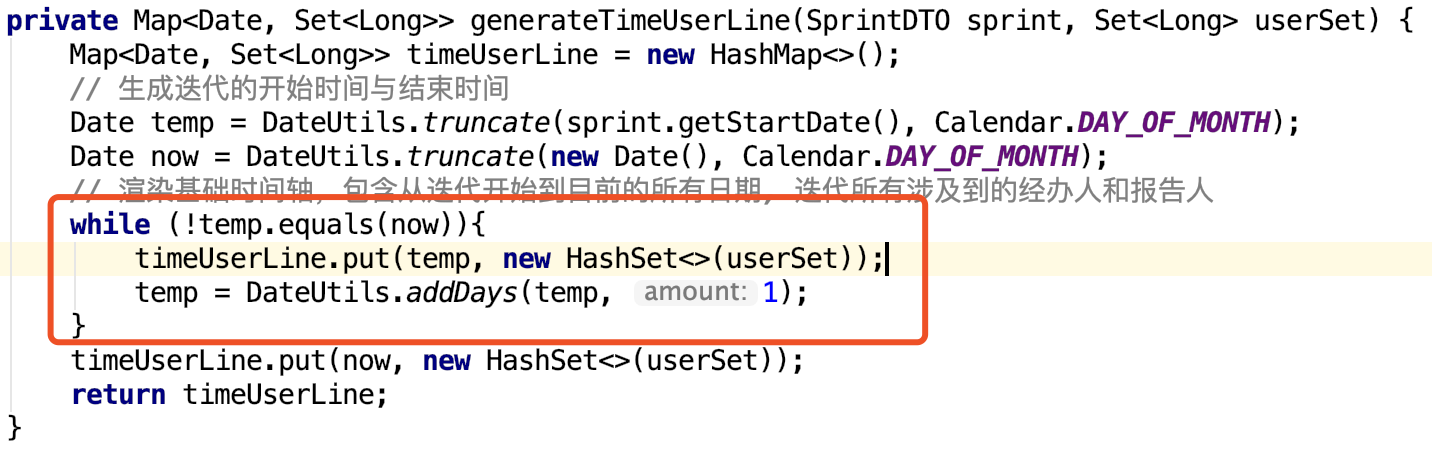
当temp>now时,相当于写了while(true),HashMap实例化越来越多,最终导致崩盘。
找到代码原因后,在测试环境重现,访问有问题的项目,得到如下信息:
pod各线程CPU、内存消耗:
top -Hp [Pid]
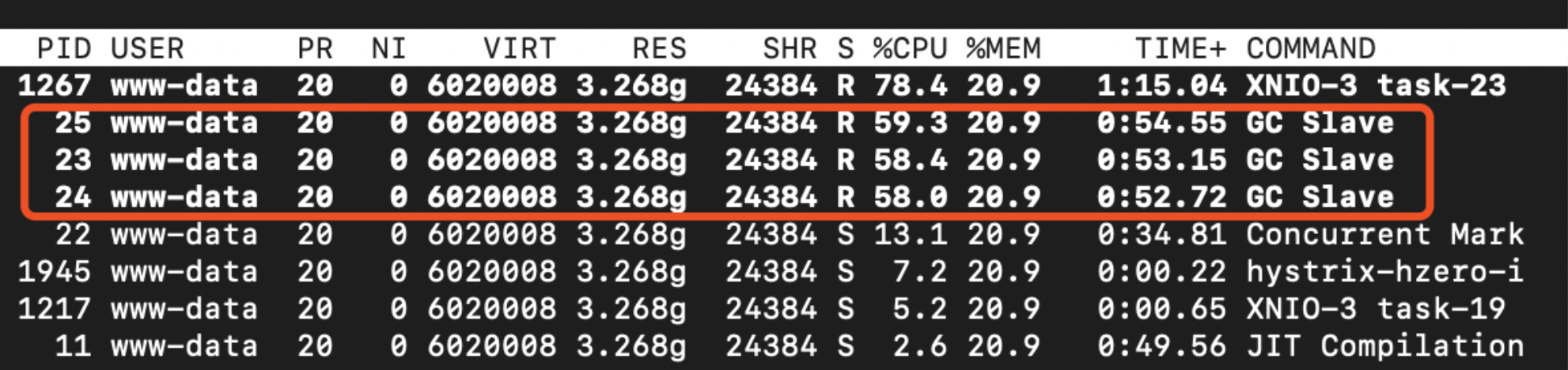
可以看到jvm gc尤为醒目。
再次通过jmap查看java对象占用内存信息,可清晰查看到HashMap内存占用异常情况。
查看pod内存与cpu,几乎要到峰值,而且还在不断上升,验证了上面的猜想。
$ kubectl top po -n namespaces
podName cpu mem
agile-service-ede46-59d95cdc86-lvmrz 2901m 3365Mi
五、jvm具体监控
监控方法:
使用jstat命令对Java应用程序的资源和性能进行实时的命令行的监控,包括了对Heap size和垃圾回收状况的监控; Jstat –class <pid>:显示加载class的数量,及所占空间等信息; Jstat –gc <pid>:显示gc相关的堆信息,查看gc的次数,及时间; Jstat -gcutil <pid>:统计gc信息; Jstat –gccause <pid>:统计gc信息(同gcutil),同时显示最后一次或当前正在发生的垃圾回收的诱因; Jstat –gc –h2 <pid> 3000 10:每2次打印一次表头,每3秒输出一次结果,一共输出10次;
如:

参数解释:
S0C:年轻代中第一个survivor(幸存区)的容量 (字节)
S1C:年轻代中第二个survivor(幸存区)的容量 (字节)
S0U:年轻代中第一个survivor(幸存区)目前已使用空间 (字节)
S1U:年轻代中第二个survivor(幸存区)目前已使用空间 (字节)
EC:年轻代中Eden(伊甸园)的容量 (字节)
EU:年轻代中Eden(伊甸园)目前已使用空间 (字节)
OC:Old代的容量 (字节)
OU:Old代目前已使用空间 (字节)
PC:Perm(持久代)的容量 (字节)
PU:Perm(持久代)目前已使用空间 (字节)
YGC:从应用程序启动到采样时年轻代中gc次数
YGCT:从应用程序启动到采样时年轻代中gc所用时间(s)
FGC:从应用程序启动到采样时old代(全gc)gc次数
FGCT:从应用程序启动到采样时old代(全gc)gc所用时间(s)
GCT:从应用程序启动到采样时gc用的总时间(s)
NGCMN:年轻代(young)中初始化(最小)的大小 (字节)
NGCMX:年轻代(young)的最大容量 (字节)
NGC:年轻代(young)中当前的容量 (字节)
OGCMN:old代中初始化(最小)的大小 (字节)
OGCMX:old代的最大容量 (字节)
OGC:old代当前新生成的容量 (字节)
PGCMN:perm代中初始化(最小)的大小 (字节)
PGCMX:perm代的最大容量 (字节)
PGC:perm代当前新生成的容量 (字节)
S0:年轻代中第一个survivor(幸存区)已使用的占当前容量百分比
S1:年轻代中第二个survivor(幸存区)已使用的占当前容量百分比
E:年轻代中Eden(伊甸园)已使用的占当前容量百分比
O:old代已使用的占当前容量百分比
P:perm代已使用的占当前容量百分比
S0CMX:年轻代中第一个survivor(幸存区)的最大容量 (字节)
S1CMX :年轻代中第二个survivor(幸存区)的最大容量 (字节)
ECMX:年轻代中Eden(伊甸园)的最大容量 (字节)
DSS:当前需要survivor(幸存区)的容量 (字节)(Eden区已满)
TT: 持有次数限制
MTT : 最大持有次数限制
六、HashMap典型内存泄漏案例
1 /** 2 * HashMap的内存泄露 3 */ 4 public class HashMapLeakTest { 5 6 public static void main(String[] args) { 7 Map<HashKey, Integer> map = new HashMap<HashKey, Integer>(); 8 HashKey p = new HashKey("zhangsan","12333-suu-1232"); 9 10 map.put(p, 1); 11 p.setName("lisi"); // 因为p.name参与了hash值的计算,修改了之后hash值发生了变化,所以删除不掉 12 map.remove(p); 13 14 System.out.println(map.size()); 15 } 16 } 17 18 /** 19 * key 类 20 */ 21 class HashKey { 22 private final String id; 23 private String name; 24 25 public HashKey(String name, String id) { 26 this.name = name; 27 this.id = id; 28 } 29 30 public void setName(String name) { 31 this.name = name; 32 } 33 34 @Override 35 public int hashCode() { 36 return name.hashCode()+id.hashCode(); 37 } 38 }
@Override public int hashCode() { return id.hashCode(); }
所以自定义Object作为HashMap的KEY一定注意重写hashCode()或equals()方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号