深度学习入门之手写数字识别
介绍
手写数字识别是经典的深度学习的入门项目,属于图像分类任务。在这篇文章中,我们使用 CNN 搭建一个模型,并使用 MNIST 数据集训练模型。
MNIST 数据集
介绍 MNIST 数据集:
- 包含 0-9 共十个数字的手写体图片
- 训练集:60,000 张图片
- 测试集:10,000 张图片
- 图片大小:28×28 像素(单通道灰度图)
- 每个像素值:0-255(0 表示白色,255 表示黑色)
数据集结构:
MNIST
├── t10k-images-idx3-ubyte.gz # 训练集图片
├── t10k-labels-idx1-ubyte.gz # 训练集标签
├── train-images-idx3-ubyte.gz # 测试集图片
└── train-labels-idx1-ubyte.gz # 测试集标签
配置环境
使用 conda 创建一个名为 pytorch 的环境:
conda create -n pytorch python=3.12
conda activate pytorch
conda install pytorch torchvision pytorch-cuda=12.4 -c pytorch -c nvidia
预训练
模型定义
model.py
import torch
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.fc1 = nn.Linear(28*28, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 28*28) # 将图像展平成一维向量
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
训练和测试函数
train.py
import torch
def train(model, train_loader, criterion, optimizer, device):
model.train() # 设置模型为训练模式
total_loss = 0
correct = 0
total = 0
# 分批次训练
for batch_idx, (data, label) in enumerate(train_loader):
data, label = data.to(device), label.to(device)
output = model(data) # 前向传播
loss = criterion(output, label) # 计算损失
_, pred = output.max(1) # 计算预测结果
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 统计
total_loss += loss.item()
total += label.size(0)
correct += pred.eq(label).sum().item()
# 打印进度
if (batch_idx + 1) % 100 == 0: # 每 100 个 batch 打印一次
print(f'Batch: {batch_idx + 1}/{len(train_loader)}, '
f'Loss: {loss.item():.4f}, '
f'Accuracy: {100. * correct / total:.2f}%')
# 计算平均损失和准确率
avg_loss = total_loss / len(train_loader)
accuracy = 100. * correct / total
return avg_loss, accuracy
def test(model, test_loader, criterion, device):
model.eval() # 设置模型为评估模式
total_loss = 0
correct = 0
total = 0
with torch.no_grad(): # 关闭自动求导引擎
for data, label in test_loader:
data, label = data.to(device), label.to(device)
output = model(data) # 前向传播
_, pred = output.max(1) # 计算预测结果
loss = criterion(output, label) # 计算损失
# 统计
total_loss += loss.item()
total += label.size(0)
correct += pred.eq(label).sum().item()
# 计算平均损失和准确率
avg_loss = total_loss / len(test_loader)
accuracy = 100. * correct / total
return avg_loss, accuracy
数据加载器
data_loader.py
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
def get_data_loaders(train_batch_size=64, test_batch_size=1000):
# 数据集转换器
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 下载并加载训练集和测试集
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
# 数据加载器
train_loader = DataLoader(train_dataset, batch_size=train_batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=test_batch_size, shuffle=False)
return train_loader, test_loader
主程序
main.py
import torch
import torch.nn as nn
import torch.optim as optim
from model import MyModel
from train import train, test
from data_loader import get_data_loaders
# 定义超参数
BATCH_SIZE = 64
EPOCHS = 10
LEARNING_RATE = 0.001
def main():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = MyModel().to(device)
# 数据加载器
train_loader, test_loader = get_data_loaders()
# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
# 训练阶段
best_accuracy = 0
for epoch in range(EPOCHS):
print(f'\nEpoch: {epoch + 1}/{EPOCHS}')
# 训练
train_loss, train_acc = train(model, train_loader, criterion, optimizer, device)
print(f'Training - Average Loss: {train_loss:.4f}, Accuracy: {train_acc:.2f}%')
# 测试
test_loss, test_acc = test(model, test_loader, criterion, device)
print(f'Testing - Average Loss: {test_loss:.4f}, Accuracy: {test_acc:.2f}%')
# 保存最佳模型
if test_acc > best_accuracy:
best_accuracy = test_acc
best_model = model.state_dict()
print(f'\nBest Test Accuracy: {best_accuracy:.2f}%')
torch.save(best_model, './models/checkpoint.pth')
if __name__ == '__main__':
main()
推理
evaluate.py
import torch
import matplotlib.pyplot as plt
from model import MyModel
from data_loader import get_data_loaders
def evaluate():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 加载模型
model = MyModel().to(device)
model.load_state_dict(torch.load('./models/checkpoint.pth', map_location=device))
model.eval()
# 加载测试集
_, test_loader = get_data_loaders(test_batch_size=8)
data, label = next(iter(test_loader))
data = data.to(device)
# 推理
with torch.no_grad():
output = model(data)
_, pred = output.max(1)
# 将数据移到 CPU,以便后续画图
data = data.cpu()
pred = pred.cpu()
# 创建 8 个子图
_, axes = plt.subplots(2, 4, figsize=(16, 8))
axes = axes.ravel()
for idx in range(8):
axes[idx].imshow(data[idx].squeeze(), cmap='gray')
axes[idx].set_title(f'Pred: {pred[idx].item()}, Label: {label[idx].item()}')
axes[idx].axis('off')
plt.tight_layout()
plt.savefig('results/evaluation.png')
if __name__ == "__main__":
evaluate()
结果:
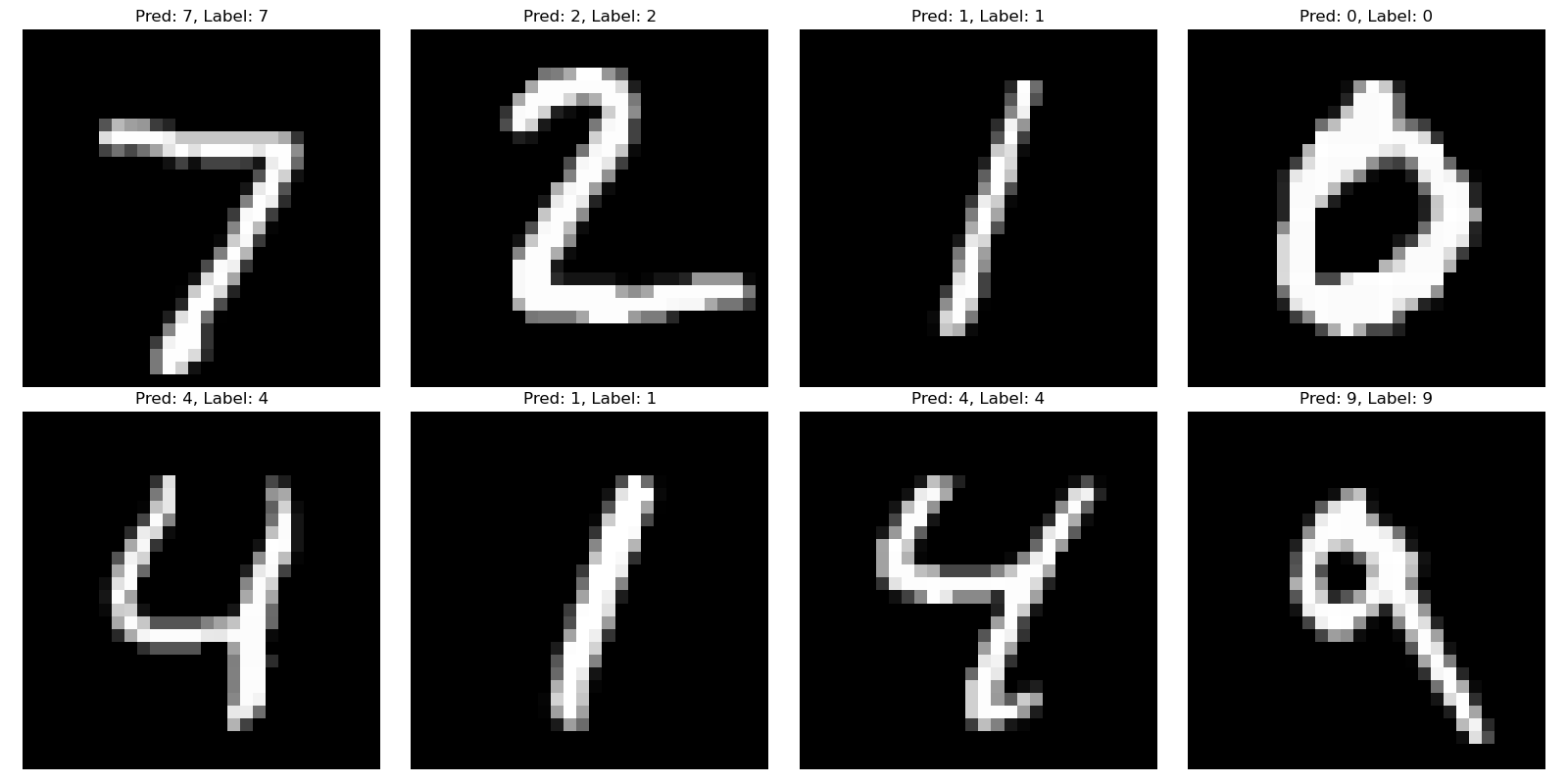
Hugging Face
Hugging Face 收集了大量的开源模型,相当于 AI 界的 GitHub。我们也可以将自己的模型上传到 Hugging Face 上。
-
首先,模型需要继承
PyTorchModelHubMixin类:import torch.nn as nn from huggingface_hub import PyTorchModelHubMixin class MyModel(nn.Module, PyTorchModelHubMixin, repo_url="hf_username/repo", pipeline_tag="image-classification", library_name="pytorch", license="mit"): def __init__(self, input_size, hidden_sizes, output_size): super(MyModel, self).__init__() self.fc1 = nn.Linear(input_size, hidden_sizes[0]) self.fc2 = nn.Linear(hidden_sizes[0], hidden_sizes[1]) self.fc3 = nn.Linear(hidden_sizes[1], output_size) -
实例化模型时传入
__init__的参数将自动序列化为config.json文件:config = { "input_size": 28*28, "hidden_sizes": [128, 64], "output_size": 10 } model = MyModel(**config) -
保存、上传和下载:
# 保存模型 model.save_pretrained(f"./models") # 上传模型 model.push_to_hub('hf_username/repo') # 下载模型 model = MyModel.from_pretrained('hf_username/repo')
参考:Uploading models | Hugging Face
参见:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号