深度学习环境配置
前言:
-
对于大部分用户来说,显卡驱动在机器出厂时已经预装。另外如果只是运行 PyTorch 项目而不需要编译 CUDA 程序的话,那么只用安装 PyTorch 就够了。
-
如果租用云 GPU 的话,只要选择 PyTorch 作为实例镜像即可获得预装 PyTorch 的机器。
CUDA
NVIDIA Driver
NVIDIA Driver 是运行 CUDA 程序的必要依赖。nvidia-smi 显示的 CUDA 版本表示驱动支持的最高 CUDA 版本。
APT 安装(推荐)
-
安装内核头文件开发包:
sudo apt install linux-headers-$(uname -r) -
添加软件源:
RELEASE=ubuntu2404 && \ wget https://developer.download.nvidia.com/compute/cuda/repos/$RELEASE/x86_64/cuda-keyring_1.1-1_all.deb && \ sudo dpkg -i cuda-keyring_1.1-1_all.deb && \ sudo apt update && \ rm cuda-keyring_1.1-1_all.deb -
检测最佳驱动类型:
sudo apt install nvidia-driver-assistant nvidia-driver-assistant -
根据检测结果安装显卡驱动:
sudo apt install nvidia-open # 桌面版 sudo apt install nvidia-headless-open # 无头版,适合纯服务器- NVIDIA 开源驱动为
nvidia-open,专有驱动为cuda-drivers。新硬件一般采用开源驱动。
- NVIDIA 开源驱动为
-
验证安装:
nvidia-smi
使用安装文件
-
在 NVIDIA.com 搜索指定 GPU 型号的驱动并下载。
wget https://download.nvidia.com/XFree86/Linux-x86_64/570.169/NVIDIA-Linux-x86_64-570.169.run -
运行安装文件:
sh ./NVIDIA-Linux-x86_64-*.run --print-recommended-kernel-module-type # 检测最佳驱动类型 sudo sh ./NVIDIA-Linux-x86_64-*.run -M open # 根据检测结果安装 open 或 proprietary 驱动
参考:
- Ubuntu | Driver Installation Guide
- NVIDIA Transitions Fully Towards Open-Source GPU Kernel Modules | NVIDIA Technical Blog
持久守护程序
sudo systemctl enable --now nvidia-persistenced
参考:Persistence Daemon | Driver Installation Guide
热更新
sudo fuser -k /dev/nvidia* # 停止正在使用显卡的程序
lsmod | grep nvidia # 查看依赖显卡驱动的模块
sudo rmmod nvidia_uvm nvidia_drm nvidia_modeset # 卸载依赖模块
sudo rmmod nvidia # 卸载显卡驱动
nvidia-smi # 重启显卡驱动
禁用自动更新
sudo apt-mark hold nvidia-open
卸载
# APT
sudo apt purge --autoremove nvidia-open
# .run 文件
sudo nvidia-uninstall
参考:
- Removing the Driver | Driver Installation Guide
- How can I uninstall a nvidia driver completely ? | Ask Ubuntu
Fabric Manager
对于装有 NVSwitch 的机器,需要使用 Fabric Manager 管理 NVSwitch 网络。
判断是否有 NVSwitch:
nvidia-smi nvlink -s
安装:
sudo apt-get install cuda-drivers-fabricmanager-<driver-branch>
<driver-branch>替换为 NVIDIA Driver 的主版本号
启动 Fabric Manager:
sudo systemctl enable --now nvidia-fabricmanager
Installing Fabric Manager | NVIDIA Fabric Manager
CUDA Toolkit
如果要编译 CUDA 代码,需安装 CUDA Toolkit。编译产物使用 CUDA Toolkit 对应的 CUDA 版本。
安装方法:在 CUDA Toolkit Downloads 页面填写表格,获得安装命令。
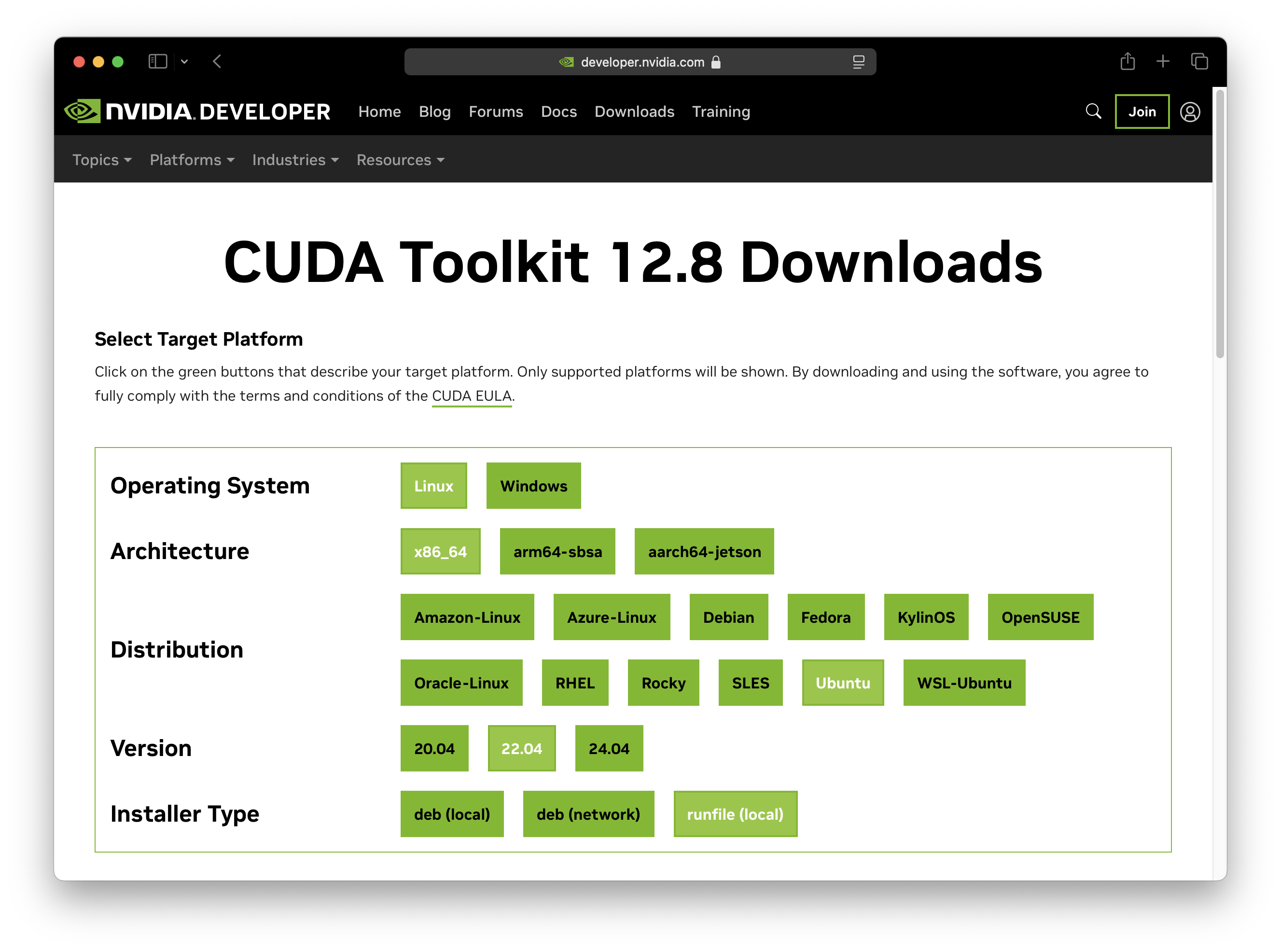
安装完成后,可以使用 nvcc -V 命令检查安装是否成功。
deb (network)
使用 deb (network) 安装方法,只会按需下载要安装的组件,更方便快捷。是推荐的安装方法。
sudo apt install cuda-toolkit # 安装最新版 CUDA Toolkit
sudo apt install cuda-toolkit-12-9 # 安装指定版本 CUDA Toolkit
sudo apt install cuda-minimal-build # 只安装编译工具链
将下面的命令加入 ~/.bashrc:
export CUDA_HOME="/usr/local/cuda-12.4"
export PATH="$CUDA_HOME/bin:$PATH"
切换默认 CUDA Toolkit 版本:
update-alternatives --display cuda # 显示默认 CUDA Toolkit 版本
sudo update-alternatives --config cuda # 修改默认 CUDA Toolkit 版本
卸载 CUDA Toolkit:
sudo apt purge --autoremove "*cuda*" "*cublas*" "*cufft*" "*cufile*" "*curand*" "*cusolver*" "*cusparse*" "*gds-tools*" "*npp*" "*nvjpeg*" "nsight*" "*nvvm*"
参考:
runfile
使用 runfile 可以将 CUDA Toolkit 安装到任意位置。
sh cuda_*_linux.run --silent --toolkit --toolkitpath="$HOME/.local/opt/cuda-12.4" # 将 12.4 改为实际的版本号
rm cuda_*_linux.run
如果需要安装配套的显卡驱动,添加
--driver选项
并将下面的命令添加到 ~/.bashrc:
export CUDA_HOME="$HOME/.local/opt/cuda-12.4" # 将 12.4 改为实际的版本号
export PATH="$CUDA_HOME/bin:$PATH"
export LD_LIBRARY_PATH="$CUDA_HOME/lib64:$CUDA_HOME/extras/CUPTI/lib64:$LD_LIBRARY_PATH"
卸载 CUDA Toolkit
sudo cuda-uninstaller # 选择需要卸载的 CUDA 版本
rm -rf $CUDA_HOME # 删除残留文件
参考:
- Runfile Installation | NVIDIA CUDA Installation Guide for Linux
- Post-installation Actions | NVIDIA CUDA Installation Guide for Linux
测试 CUDA 环境
wget https://gist.githubusercontent.com/f0k/0d6431e3faa60bffc788f8b4daa029b1/raw/8c38eadc9d81a957e5df5963bda8c4ab3271b664/cuda_check.c
nvcc -lcuda -o cuda_check cuda_check.c
./cuda_check
示例输出:
Found 1 device(s).
Device: 0
Name: NVIDIA H100 80GB HBM3
Compute Capability: 9.0
Multiprocessors: 132
Concurrent threads: 270336
GPU clock: 1980 MHz
Memory clock: 2619 MHz
Total Memory: 80994 MiB
Free Memory: 80469 MiB
参考:Simple program to test whether nvcc/CUDA work | GitHub
cuDNN
cuDNN 一般通过 pip 安装,不需要使用系统安装。
cuDNN 是 CUDA 的扩展库,针对深度神经网络中的基础操作提供高度优化的实现方式。
安装方法:在 cuDNN Downloads 页面填写表格,获得安装命令。
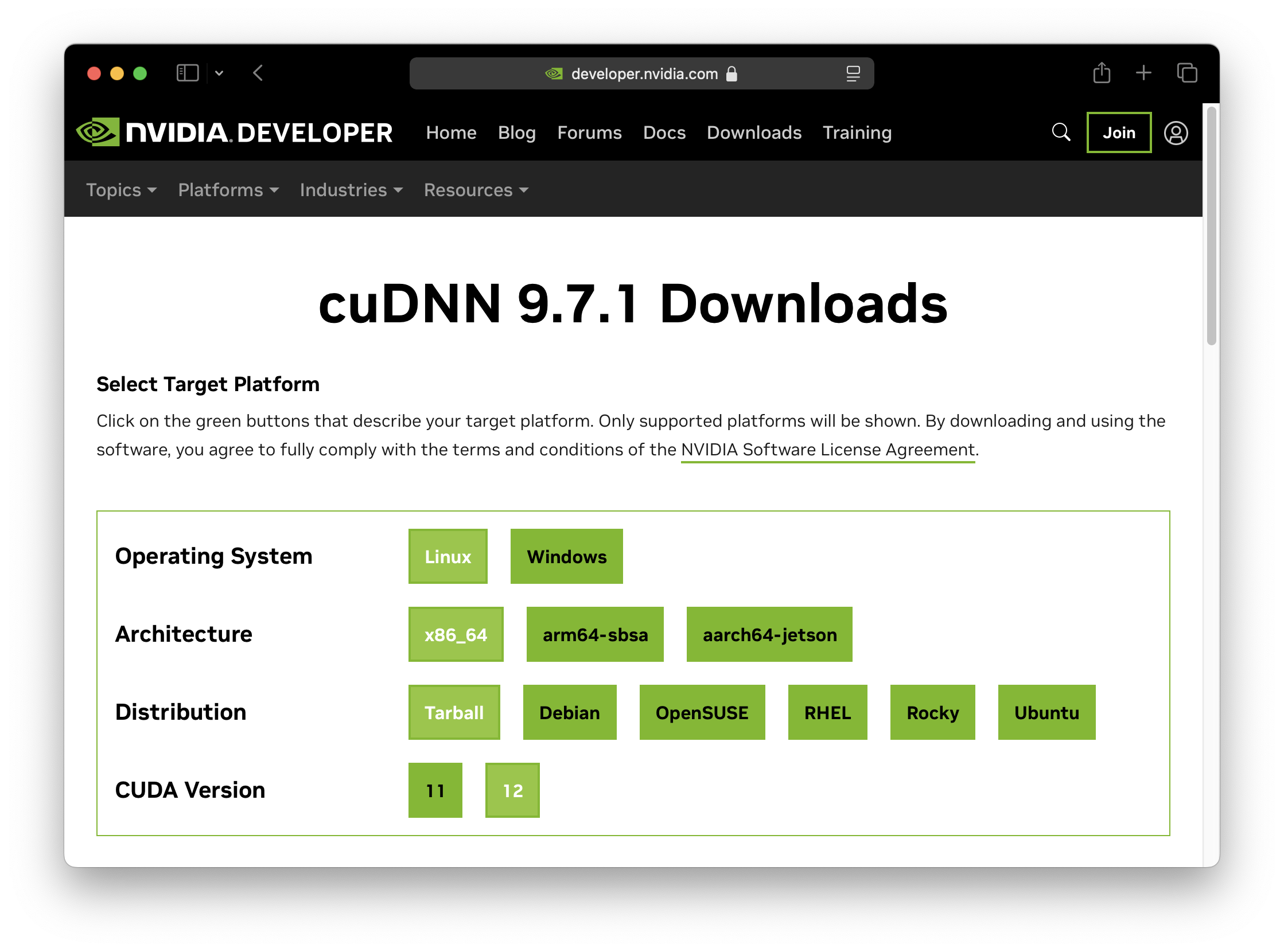
Ubuntu
sudo apt install cudnn # 安装最新版
sudo apt install cudnn9-cuda-12 # 安装指定版本
APT 只能安装一个版本的 cuDNN
参考:Package Manager Network Installation | NVIDIA cuDNN Installation Guide
Tarball
CUDA_HOME="$HOME/.local/opt/cuda-12.4" # 将 12.4 改为实际的版本号
tar -xJf cudnn-*-archive.tar.xz
cp -P cudnn-*-archive/include/cudnn*.h $CUDA_HOME/include
cp -P cudnn-*-archive/lib/libcudnn* $CUDA_HOME/lib64
rm -rf cudnn-*-archive*
参考:Tar File Installation | NVIDIA cuDNN Doc
cuSPARSELt
cuSPARSELt 一般通过 pip 安装,不需要使用系统安装。
安装方法:在 cuSPARSELt Downloads 页面填写表格,获得安装命令。
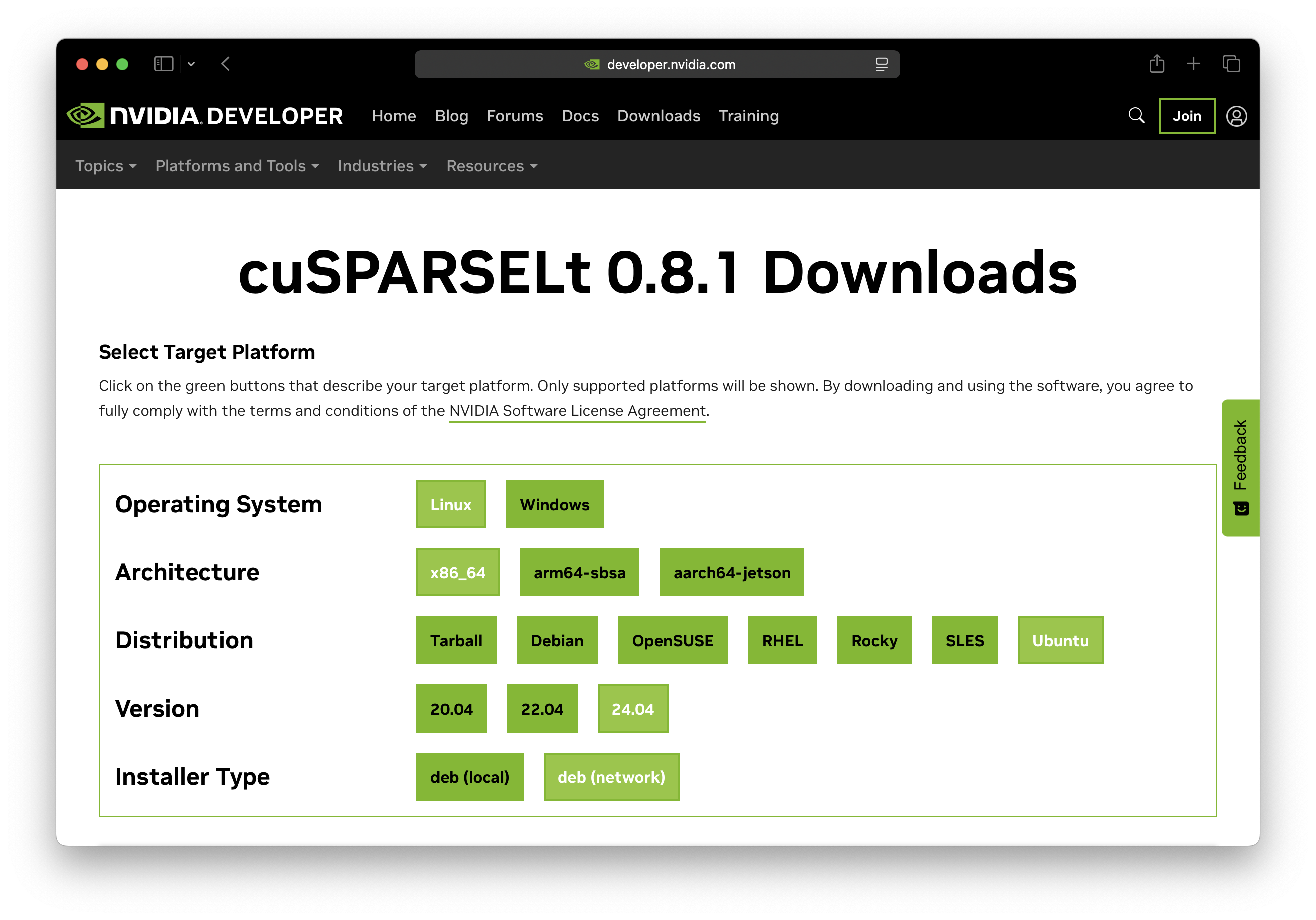
Ubuntu
sudo apt install cusparselt # 安装最新版
sudo apt install cusparselt-cuda-12 # 安装指定版本
NCCL
-
在 NVIDIA Collective Communications Library (NCCL) Download Page 找到要安装的 NCCL 版本。
-
安装:
RELEASE=ubuntu2404 wget https://developer.download.nvidia.com/compute/cuda/repos/$RELEASE/x86_64/cuda-keyring_1.1-1_all.deb sudo dpkg -i cuda-keyring_1.1-1_all.deb sudo apt update sudo apt install libnccl2=2.26.2-1+cuda12.8 libnccl-dev=2.26.2-1+cuda12.8
NVIDIA Container Toolkit
NVIDIA Container Toolkit 允许在 Docker 容器中调用宿主机的 NVIDIA GPU。
-
清理旧的 NVIDIA Container Toolkit:
sudo apt purge --autoremove nvidia-container-toolkit nvidia-container-runtime nvidia-docker2 -
安装 NVIDIA Container Toolkit:
# 安装公钥 curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey \ | sudo gpg --dearmor -o /etc/apt/keyrings/nvidia-container-toolkit-keyring.gpg # 添加 nvidia-container-toolkit 源 curl -sL https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list \ | sed 's#deb https://#deb [signed-by=/etc/apt/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' \ | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list # 安装 nvidia-container-toolkit sudo apt update sudo apt install nvidia-container-toolkit -
注册 NVIDIA Container Runtime 到 Docker:
sudo nvidia-ctk runtime configure --runtime=docker -
重启 Docker:
sudo systemctl restart docker -
测试安装:
sudo docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
Rootless Mode
-
注册 NVIDIA Container Runtime 到用户级 Docker:
nvidia-ctk runtime configure --runtime=docker --config=$HOME/.config/docker/daemon.json -
重启用户级 Docker:
systemctl --user restart docker -
关闭 NVIDIA Container CLI 对 cgroups 设备控制器的依赖(cgroups 的设备控制器需要 root 权限才能操作):
sudo nvidia-ctk config --set nvidia-container-cli.no-cgroups --in-place
参考:Installing the NVIDIA Container Toolkit | NVIDIA Container Toolkit
启用 CDI 支持
-
启用 CDI 刷新服务:
sudo systemctl enable --now nvidia-cdi-refresh.path sudo systemctl enable --now nvidia-cdi-refresh.service -
设置 NVIDIA Container Runtime 为 CDI 模式:
sudo nvidia-ctk config --set nvidia-container-runtime.mode=cdi --in-place
参考:Support for Container Device Interface | NVIDIA Container Toolkit
Vulkan
sudo apt install libvulkan1 mesa-vulkan-drivers vulkan-tools
参见:
MIG
未完待续
Python
PyTorch
PyTorch 是由 Facebook AI Research lab 开发的开源机器学习框架,可用于计算机视觉和自然语言处理。
安装预编译包
打开 PyTorch 官网,往下拉,填写表格后获得安装命令。
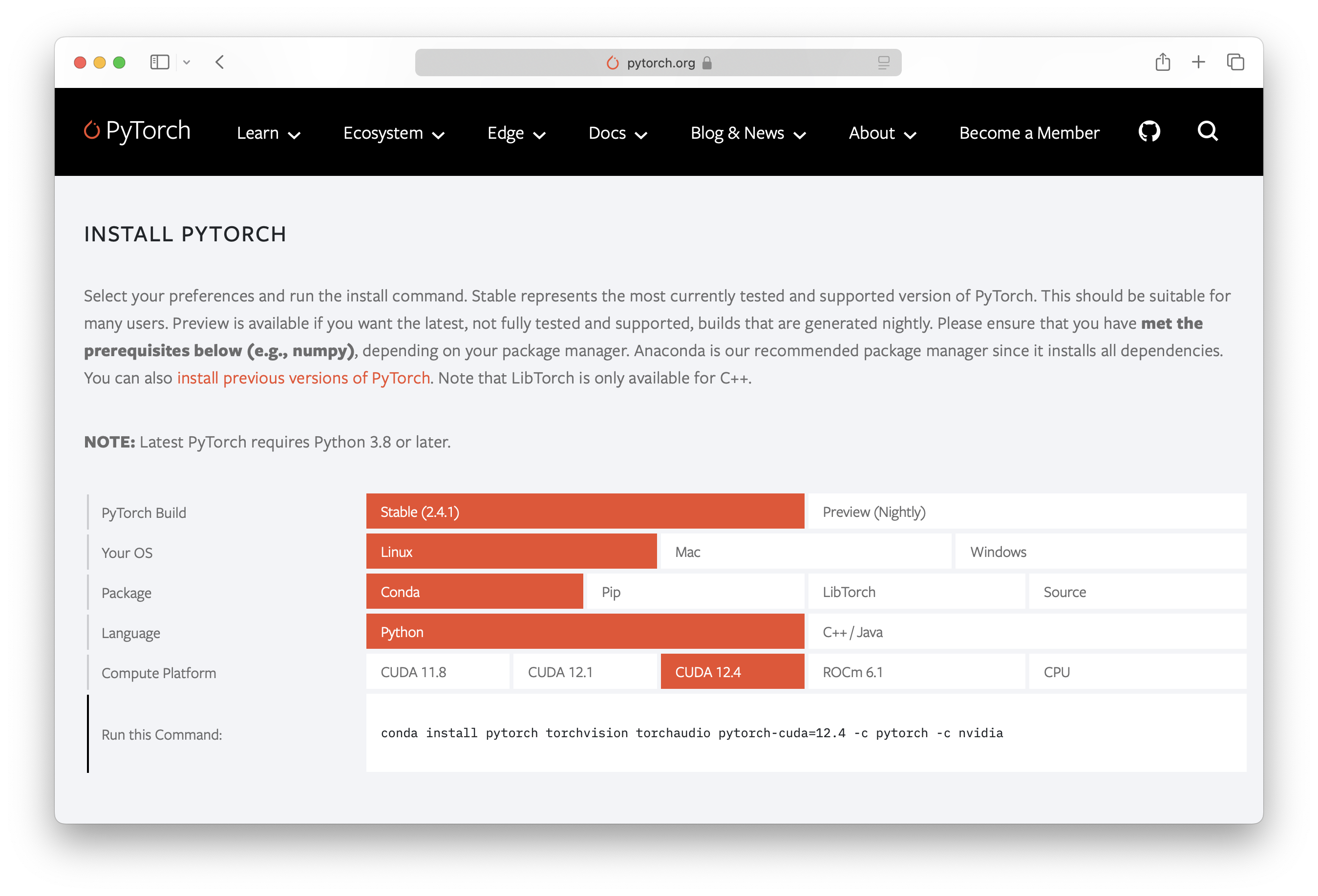
-
pip:
# 安装 PyTorch (CUDA 12.4) pip3 install torch torchvision torchaudio -i https://download.pytorch.org/whl/cu124 # 使用阿里镜像 pip3 install torch torchvision torchaudio -i https://mirrors.aliyun.com/pytorch-wheels/cu124不要使用
--extra-index选项安装,因为在遇到相同版本号时 pip 可能选择 PyPI 源的版本,这导致无法安装兼容指定 CUDA 版本的 PyTorch。 -
conda:
conda install pytorch torchvision torchaudio pytorch-cuda=12.4 -c pytorch -c nvidia
- Anaconda 的
pytorch包只能调用 CPU,pytorch-cuda包可以调用 GPU。- 自
2.5版本起,PyTorch 官方停止了 Anaconda 包的发布,请使用pip安装 PyTorch。参见:Deprecating PyTorch’s official Anaconda channel
手动编译
-
激活环境:
conda create -n torch-builder python=3.13 -y conda activate torch-builder -
获取源码:
git clone -b v2.8.0 --depth 1 https://github.com/pytorch/pytorch cd pytorch git submodule sync git submodule update --init --recursive --depth 1 --progress -
编译安装依赖:
pip install --group dev pip install mkl-static mkl-include .ci/docker/common/install_magma_conda.sh 12.9 # 修改 CUDA 版本 make triton -
编译安装 torch:
export CMAKE_PREFIX_PATH="${CONDA_PREFIX:-'$(dirname $(which conda))/../'}:${CMAKE_PREFIX_PATH}" pip install --no-build-isolation -e .
PyTorch 测试命令
python -c "import torch; print(torch.cuda.is_available())" # 检查 PyTorch 能否调用 GPU
python -c "import torch; print(torch.version.cuda)" # 检查当前 PyTorch 安装所支持的 CUDA 版本
python -c "import torch; print(torch.cuda.get_device_capability())" # 检查 GPU 计算能力
python -c "import torch; print(torch._C._GLIBCXX_USE_CXX11_ABI)" # 检查 ABI 兼容性
常用环境变量
export CUDA_DEVICE_ORDER=PCI_BUS_ID # 指定显卡排序方式
export OMP_NUM_THREADS=8 # 指定 OpenMP 程序并行线程数量
参见:
xFormers
xFormers 是一个专注于优化和扩展 Transformer 模型的开源库,旨在提高 Transformer 模型的效率和灵活性,使其在不同硬件和任务上表现更佳。
pip install xformers -i https://download.pytorch.org/whl/cu128
PyG
PyG: PyTorch Geometric
pip install torch_geometric
pip install pyg_lib torch_scatter torch_sparse torch_cluster torch_spline_conv -f https://data.pyg.org/whl/torch-2.7.0+cu128.html
参考:Installation | pytorch_geometric documentation
FlashAttention
FlashAttention 可以用来加速 Attention 计算。但是作者在 PyPI 只提供了源码分发,因此如果直接运行 pip install flash-attn 命令会从源码编译安装,编译过程非常耗时且容易失败。@mjun0812/flash-attention-prebuild-wheels 提供了各种环境的 flash-attn 预编译包,可以省去编译的麻烦:
pip install https://github.com/mjun0812/flash-attention-prebuild-wheels/releases/download/v0.7.16/flash_attn-2.8.3%2Bcu130torch2.10-cp313-cp313-linux_x86_64.whl
FlashAttention 官方也 Release 了一些预编译包,不过环境种类没有上面的项目齐全。下面是关于官方 Release 版本选择的一些说明:
-
cuXX:CUDA 版本,需要参考显卡驱动支持的版本 -
torchX.X:PyTorch 版本,需要参考环境中安装的 PyTorch 版本 -
cxx11abiXXXX:C++11 ABI 兼容性,可以通过如下命令检查:python -c "import torch; print(torch._C._GLIBCXX_USE_CXX11_ABI)"
如果想要自己编译 flash-attn,可以使用如下命令:
pip install -U pip wheel setuptools packaging ninja
MAX_JOBS=$(nproc) pip install --no-build-isolation flash-attn
FA 版本兼容性
| Architecture | Representative GPUs | Recommended FA |
|---|---|---|
| Turing (SM75) | T4, RTX 20 series | FA2 |
| Ampere (SM80/86) | A100, RTX 30 series, A40/A6000 | FA2 |
| Ada Lovelace (SM89) | RTX 40 series, L40 | FA2 |
| Hopper (SM90) | H100, H800, H200 | FA3 |
| Blackwell (SM100/110/120) | B100/B200/GB200, RTX 50 series, RTX PRO 6000 | FA4 |
参考:
causal-conv1d
causal-conv1d 是 Dao-AILab 开发的另一个加速包。和 FlashAttention 一样,二进制分发在 GitHub 而不是 PyPI,因此需要手动指定安装 URL:
pip install https://github.com/Dao-AILab/causal-conv1d/releases/download/v1.5.0.post8/causal_conv1d-1.5.0.post8+cu12torch2.6cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
Faiss
-
安装依赖:
sudo apt install libopenblas-dev swig intel-mkl libgflags-dev python3-dev conda create -n faiss-builder python=3.13 numpy && conda activate faiss-builder -
构建 faiss:
git clone https://github.com/facebookresearch/faiss.git && cd faiss cmake -B build . lscpu | grep avx512 # 检查是否支持 AVX512 扩展指令集 make -C build -j faiss_avx512 # 使用 AVX512 指令集优化 make -C build -j faiss # 不使用高级指令集 -
构建 Python 包并安装:
make -C build -j swigfaiss # 构建 Python 包 (cd build/faiss/python && python setup.py install) # 安装 Python 包
vLLM
Pre-built wheels
# pip
pip install vllm --extra-index-url https://download.pytorch.org/whl/cu130
# uv
uv pip install vllm --torch-backend=cu130 # {auto,cpu,rocm6.3}
安装指定版本:
export VLLM_VERSION=$(curl -s https://api.github.com/repos/vllm-project/vllm/releases/latest | jq -r .tag_name | sed 's/^v//')
export CUDA_VERSION=129
uv pip install https://github.com/vllm-project/vllm/releases/download/v${VLLM_VERSION}/vllm-${VLLM_VERSION}+cu${CUDA_VERSION}-cp38-abi3-manylinux1_x86_64.whl --extra-index-url https://download.pytorch.org/whl/cu${CUDA_VERSION}
这些 wheel 使用 Python 3.8 ABI 构建,因此与 Python 3.8 及更高版本兼容。
参考:Pre-built wheels | vLLM Docs
Build from source
-
安装构建依赖:
pip install meson-python cython sudo apt install ccache # (可选)ccache 可以利用缓存加速二次构建 -
克隆 vllm:
git clone -b v0.10.1 https://github.com/vllm-project/vllm.git cd vllm -
更新目标 PyTorch 版本:
python use_existing_torch.py -
构建并安装
pip install -r requirements/build.txt CCACHE_NOHASHDIR="true" pip install --no-build-isolation -e .
参见:Use an existing PyTorch installation | vLLM
Apex
git clone https://github.com/NVIDIA/apex && cd apex
# 使用 core 扩展构建(cpp 和 cuda)
APEX_CPP_EXT=1 APEX_CUDA_EXT=1 pip install -v --no-build-isolation .
# 并行构建
NVCC_APPEND_FLAGS="--threads 4" APEX_PARALLEL_BUILD=8 APEX_CPP_EXT=1 APEX_CUDA_EXT=1 pip install -v --no-build-isolation .
# 要使用其他扩展进行构建,请使用环境变量
APEX_CPP_EXT=1 APEX_CUDA_EXT=1 APEX_FAST_MULTIHEAD_ATTN=1 APEX_FUSED_CONV_BIAS_RELU=1 pip install -v --no-build-isolation .
# 一次性构建所有 contrib 扩展
APEX_CPP_EXT=1 APEX_CUDA_EXT=1 APEX_ALL_CONTRIB_EXT=1 pip install -v --no-build-isolation .
参考:NVIDIA/apex
MAGMA
MAGMA 是下一代线性代数(LA)GPU 加速库集合,由 LAPACK 和 ScaLAPACK 的开发团队设计和实现。
PyTorch 提供了 Magma 预编译包,可以通过以下命令安装:
curl -sSL https://raw.githubusercontent.com/pytorch/pytorch/refs/heads/main/.ci/docker/common/install_magma.sh | sudo bash -s -- 12.9 # 修改 CUDA 版本
参考:pytorch/pytorch/.ci/docker/common/install_magma.sh
TensorFlow
TensorFlow 是由 Google Brain 开发的机器学习框架,虽然目前的行业地位不如 PyTorch,但由于发展较早,你会在很多地方见到它的身影。
pip install 'tensorflow[and-cuda]'
验证安装:
python -c "import tensorflow as tf; print(tf.config.list_physical_devices('GPU'))"
不建议使用 conda 安装 TensorFlow。官方只在 PyPI 发布 TensorFlow。
参考:Install TensorFlow 2 | TensorFlow.org
Cog
Cog 是一个用于将机器学习模型打包到容器中的工具。
sudo curl -o /usr/local/bin/cog -L https://github.com/replicate/cog/releases/latest/download/cog_`uname -s`_`uname -m`
sudo chmod +x /usr/local/bin/cog
Troubleshooting
PyTorch 无法使用 GPU
>>> torch.cuda.is_available()
/home/user/.local/opt/miniforge3/envs/myenv/lib/python3.12/site-packages/torch/cuda/__init__.py:129: UserWarning: CUDA initialization: Unexpected error from cudaGetDeviceCount(). Did you run some cuda functions before calling NumCudaDevices() that might have already set an error? Error 802: system not yet initialized (Triggered internally at /opt/conda/conda-bld/pytorch_1729647378361/work/c10/cuda/CUDAFunctions.cpp:108.)
return torch._C._cuda_getDeviceCount() > 0
False
在正确安装了显卡驱动和 pytorch-cuda 包的情况下,尝试重启电脑。
参考:CUDA initialization: Unexpected error from cudaGetDeviceCount() | Stack Overflow
无法使用 nvidia-smi
$ nvidia-smi
Failed to initialize NVML: Driver/library version mismatch
NVML library version: 570.133
原因:安装的驱动程序版本和当前运行的驱动程序版本不一致:
dpkg -l | grep nvidia-utils # 查看安装的驱动程序版本
cat /proc/driver/nvidia/version # 查看运行的驱动程序版本
解决方法:重启,或参见热更新。
参考:Nvidia NVML Driver/library version mismatch | Stack Overflow
Unable to load any of libcudnn_engines_precompiled.so
Unable to load any of {libcudnn_engines_precompiled.so.9.9.0, libcudnn_engines_precompiled.so.9.9, libcudnn_engines_precompiled.so.9, libcudnn_engines_precompiled.so}
疑似由于在安装 cuDNN 之前部署了 PyTorch 环境导致。删除 cuDNN,或者重新配置 PyTorch 环境。
NVIDIA Container Toolkit 无法使用
$ sudo docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
Failed to initialize NVML: Unknown Error
解决方法:
-
编辑 NVIDIA Container Toolkit 配置文件:
sudoedit /etc/nvidia-container-runtime/config.toml-no-cgroups = true +no-cgroups = false -
重启 docker daemon:
sudo systemctl restart docker
似乎这个选项对 root docker 和 rootless docker 是互斥的:如果设置 no-cgroups = true,那么 rootless docker 能使用 GPU 设备而 root docker 不能使用 GPU 设备。如果设置 no-cgroups = false,则反之。
参考:
- [SOLVED] Docker with GPU: "Failed to initialize NVML: Unknown Error" | Arch Linux Forums
- Nvida Container Toolkit: Failed to initialize NVML: Unknown Error | NVIDIA Developer Forums
Rootless mode 容器无法调用 NVIDIA GPU
$ docker run --rm --gpus all --runtime nvidia ubuntu nvidia-smi
docker: Error response from daemon: failed to create task for container: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: error during container init: error running prestart hook #0: exit status 1, stdout: , stderr: Auto-detected mode as 'legacy'
nvidia-container-cli: mount error: failed to add device rules: unable to find any existing device filters attached to the cgroup: bpf_prog_query(BPF_CGROUP_DEVICE) failed: operation not permitted: unknown
Run 'docker run --help' for more information
问题原因:
NVIDIA Container Runtime 使用了 legacy 模式。
解决方法:使用 CDI 模式
sudo nvidia-ctk config --set nvidia-container-runtime.mode=cdi --in-place
参考:System Update in Arch Linux, broked NVIDIA container. Open Source drivers | GitHub
无法生成 NVIDIA CDI 配置文件
在更新 NVIDIA Container Toolkit v1.18.0 后,生成 CDI 文件时会出现如下错误:
$ sudo nvidia-ctk cdi generate --output=/etc/cdi/nvidia.yaml
ERRO[0000] invalid discovery mode: cdi
解决方法:
sudo nvidia-ctk cdi generate --mode=auto --output=/etc/cdi/nvidia.yaml
对于 nvidia-cdi-refresh 服务:
sudoedit /etc/systemd/system/nvidia-cdi-refresh.service
-ExecStart=/usr/bin/nvidia-ctk cdi generate
+ExecStart=/usr/bin/nvidia-ctk cdi generate --mode=auto
参见:invalid discovery mode: cdi | GitHub
Error 802: system not yet initialized
$ python -c "import torch; print(torch.cuda.is_available())"
/lib/python3.13/site-packages/torch/cuda/__init__.py:180: UserWarning: CUDA initialization: Unexpected error from cudaGetDeviceCount(). Did you run some cuda functions before calling NumCudaDevices() that might have already set an error? Error 802: system not yet initialized (Triggered internally at /pytorch/c10/cuda/CUDAFunctions.cpp:119.)
return torch._C._cuda_getDeviceCount() > 0
问题原因:对于使用 NVSwitch 的机器,必须启动 Fabric Manager 才能让 CUDA 正常工作。
解决方法:重启 Fabric Manager
sudo systemctl restart nvidia-fabricmanager

 浙公网安备 33010602011771号
浙公网安备 33010602011771号