
【项目实训5】自建前端配置与测试
—— written by Unalome (2025.04.29-30)
由于最终的输出界面需要对用户友好,当前阶段的目标为将终端流式输出的转为自建前端的输出,以便后续接入Cherry Studio。
一、FastAPI+SSE流式输出到前端
1. FastAPI基础配置
CORS跨域处理
- 解决前后端端口不一致时的跨域问题(其中allow-origins字段在正式上线时改成具体的前端域名以消除安全隐患)
# 初始化
app = FastAPI()
# 添加CORS中间件(允许所有来源测试)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 允许所有来源
allow_credentials=True, # 允许携带凭证
allow_methods=["*"], # 允许所有HTTP方法
allow_headers=["*"], # 允许所有请求头
)
异步服务启动
- uvicorn是基于asyncio的ASGI服务器,支持异步请求处理。相比同步框架flask可提升高并发场景下的吞吐量
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8003)
2. SSE流式传输实现
Server-Sent Events(SSE)是一种基于 HTTP 协议的轻量级实时通信技术,允许服务器主动向客户端单向推送数据流。其核心优势在于低延迟、低开销和协议简洁性:基于纯文本的 text/event-stream 格式,无需复杂的握手或帧协议;支持自动重连与消息分界,天然适配高延迟网络环境。在 Web 应用中,SSE 结合异步后端框架(如 FastAPI)可高效实现高并发的实时数据传输,成为现代流式交互的重要技术支撑。
核心组件 StreamingResponse
- 响应头启用
text/event-stream代表使用SSE Cache-Control: no-cache防止浏览器或中间代理缓存响应,减少延迟X-Accel-Buffering: no解决反向代理的缓冲问题
@app.post("/rag-stream")
async def rag_stream(request: Request):
data = await request.json()
query = data.get("query", "")
return StreamingResponse(
generate_stream(query),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"X-Accel-Buffering": "no"
}
)
流式生成器 generate_stream
- 使用
AsyncGenerator类型,通过yield逐块返回数据。每次yield发送一个 SSE 事件,格式为 (data: 内容\n\n)。 - 流式调用大模型API:
async for chunk in stream异步迭代每个返回的 chunk,实时转发给前端。
async def generate_stream(query: str) -> AsyncGenerator[str, None]:
# ....检索逻辑....
try:
stream = await client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role": "user", "content": prompt}],
stream=True,
temperature=0.1
)
async for chunk in stream:
if content := chunk.choices[0].delta.content:
yield f"data: {content}\n\n"
except Exception as e:
yield f"data: 错误:{str(e)}\n\n"
finally:
yield "data: [DONE]\n\n"
性能优化
- 全链路异步及资源释放:全程使用
async/await避免同步阻塞操作拖慢整体性能,try/finally确保连接及时释放 - 直接调用大模型API绕过 Haystack 的 Pipeline 封装,减少中间环节的延迟,直接控制流式响应的生成逻辑,灵活处理每个 chunk
client = AsyncOpenAI(...)
stream = await client.chat.completions.create(...)
二、输出格式规范化
简易前端使用html+css搭建
SSE 数据解析与清洗
- 数据分块处理:后端通过
text/event-stream格式返回数据,每个事件以双换行符(\n\n)分隔。前端通过split('\n\n')切分数据块,确保完整解析每个事件。
chunk.split('\n\n').forEach(event => { ... });
- 过滤有效数据:仅处理以
data:开头的事件内容,过滤协议无关信息(注释、空行)
if (!event.startsWith('data: ')) return;
let content = event.slice(5).trim(); // 提取有效内容
自定义标签的 HTML 转换
- 后端返回
<think>深度思考</think>的标记内容,前端通过正则表达式将其转换为常见的的深度思考展示格式
content = content
.replace(/<think>/g, '<div class="think-marker">【思考中】</div><div class="think-content">')
.replace(/<\/think>/g, '</div><div class="think-marker">【思考结束】</div>');
动态内容渲染与实时滚动
- 渐进式内容追加:使用
innerHTML += content动态追加新内容,避免页面闪烁,同时保留历史记录。
currentResponseDiv.innerHTML += content;
- 自动滚动定位 每次追加内容后调用
scrollIntoView({ behavior: 'smooth' }),实现平滑滚动到底部,提升用户体验
currentResponseDiv.scrollIntoView({ behavior: 'smooth' });
三、测试与评估
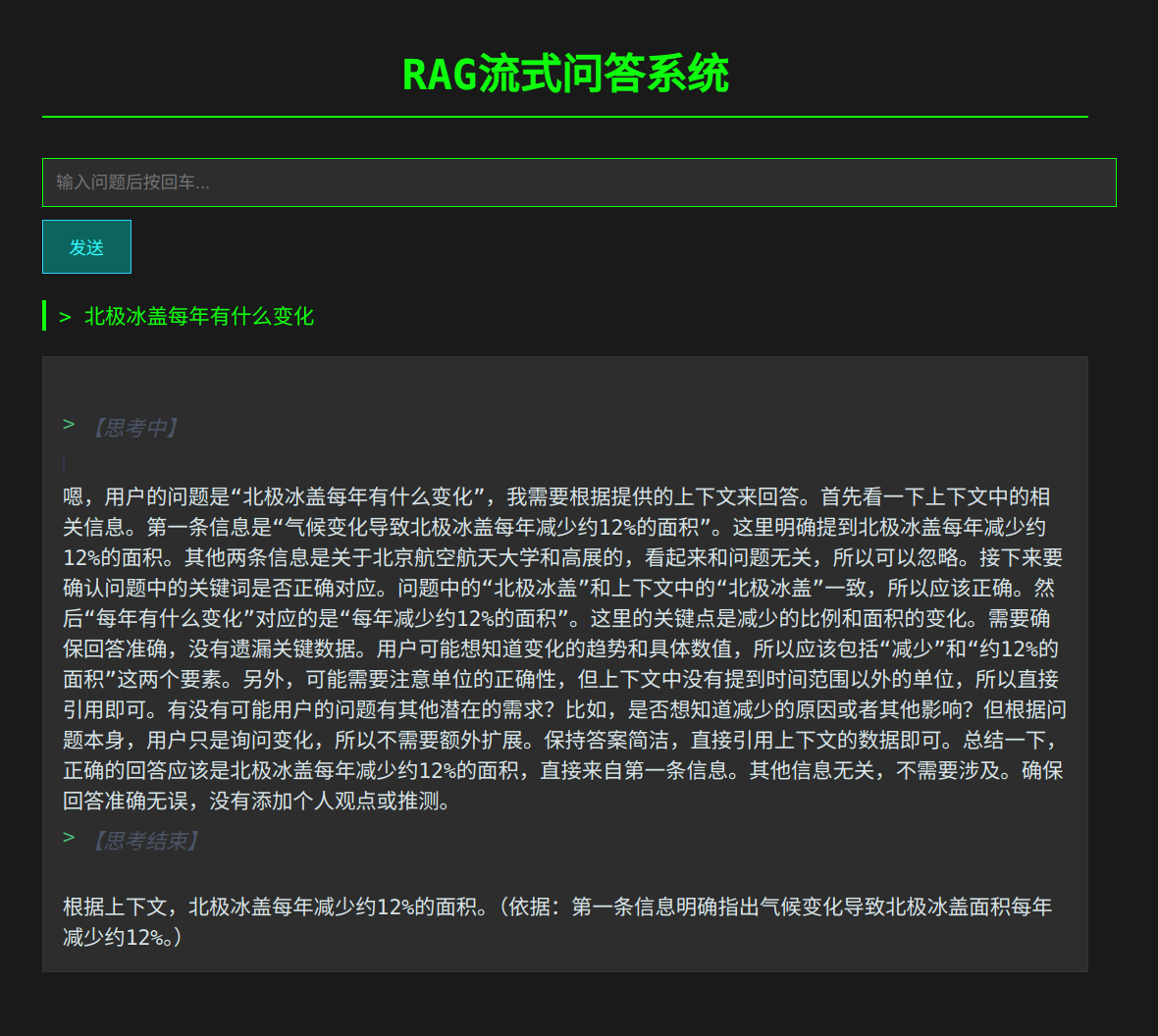
经测试在输出表现良好,延迟较低,界面简介美观,可读性强。
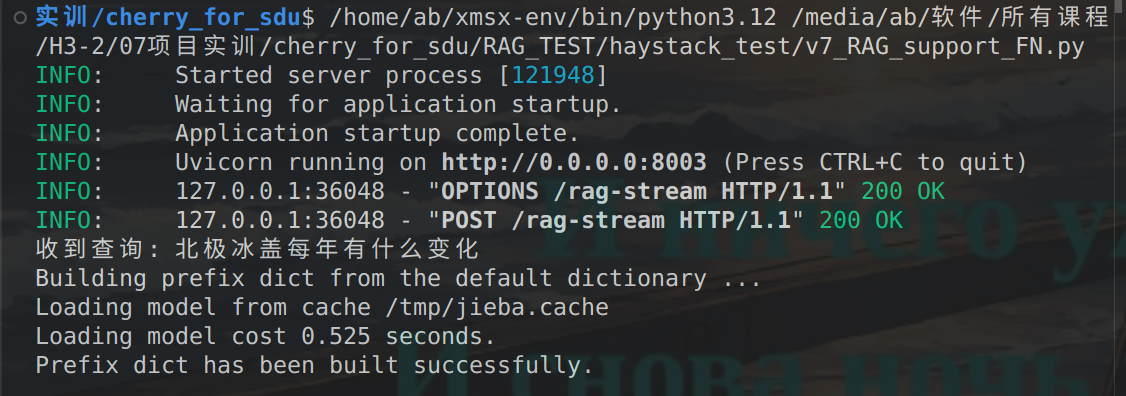
最终效果图如下:
【后端】
【前端】
四、下一步开发目标
(1)后端检索优化:针对大量数据提升检索准确率
(2)前端工程:从自建前端转移到Cherry Studio并美化界面

 浙公网安备 33010602011771号
浙公网安备 33010602011771号