
按照《权威指南》的例子求最低温度并且修改默认调度器为FairScheduler
首先我只是下载了2003年的数据,因为网络较慢……然后把数据整合到test.txt中,upload到hdfs文件系统中。如图。已有一个test.txt。

数据准备好之后,开始搞代码。代码如图。
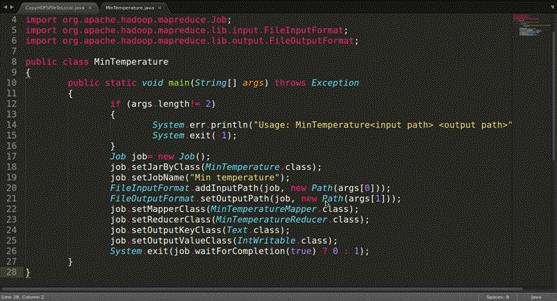
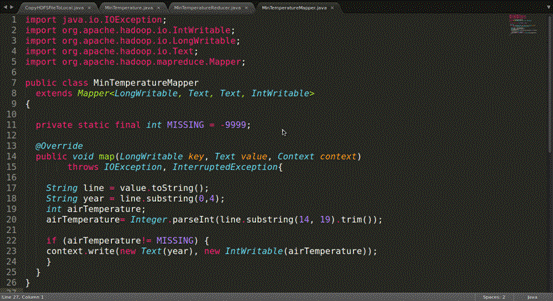
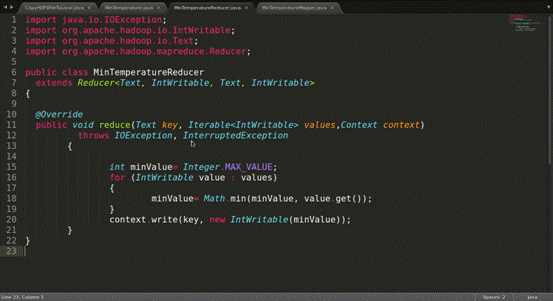
然后把它们打包成一个jar包,运行。
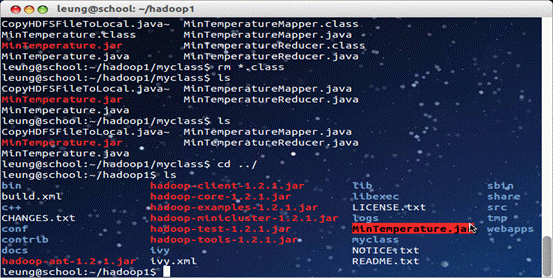
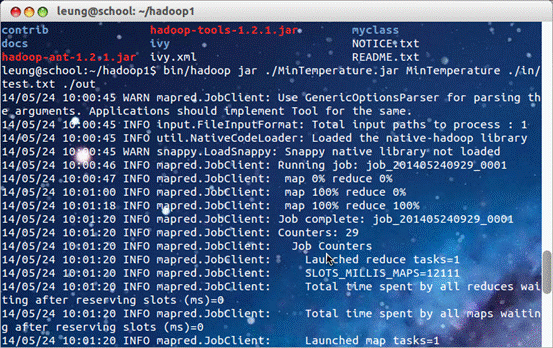
结果求得2003年的最低温度是-807。如图。

搞掂!!
接下来是实现hadoop的公平调度器。
首先不做任何修改,直接启动hadoop集群,然后启动两个作业,查看FIFO调度器队列。
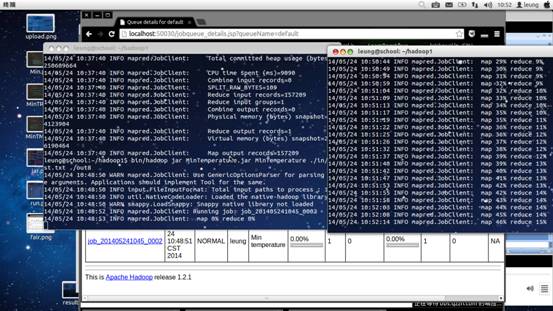
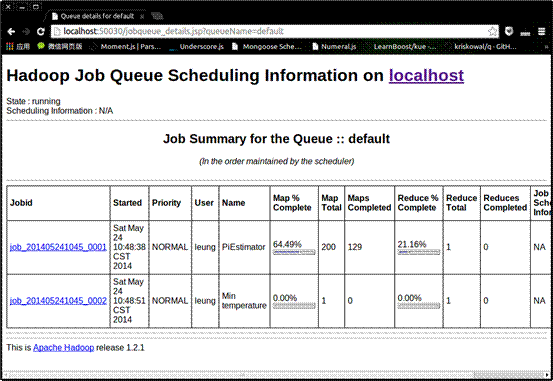
可以看到,同时启动两个作业,只会有一个作业运行,另一个作业处在等待状态。
而接下来是用公平调度器,在mapred-site.xml中加入如下属性:
<property> <name>mapred.jobtracker.taskScheduler</name> <value>org.apache.hadoop.mapred.FairScheduler</value> </property> <property> <name>mapred.fairscheduler.poolnameproperty</name> <value>pool.name</value> </property> <property> <name>pool.name</name> <value>${user.name}</value> </property>
然后在fair-scheduler.xml中设置了两个pool的名字以及容量等。就是在其中加入如下属性。
<?xml version="1.0"?> <allocations> <pool name="sample_pool"> <minMaps>1</minMaps> <minReduces>1</minReduces> <maxMaps>2</maxMaps> <maxReduces>2</maxReduces> <minSharePreemptionTimeout>300</minSharePreemptionTimeout> </pool> <user name="sample_user"> <maxRunningJobs>6</maxRunningJobs> </user> <userMaxJobsDefault>3</userMaxJobsDefault> <fairSharePreemptionTimeout>600</fairSharePreemptionTimeout> </allocations>
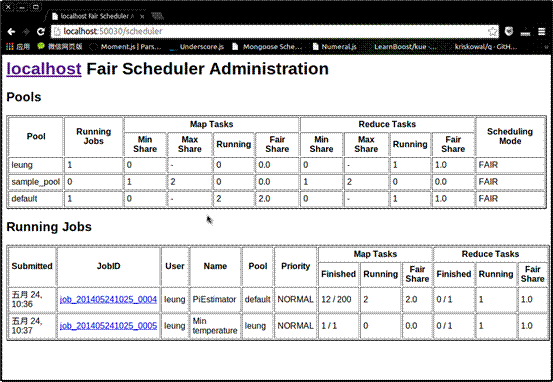
然后保存退出,重启集群,同时启动两个作业,查看调度器窗口,如图。可以看出两个作业同时运行,并且系统进行资源分配。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号