面向对象第三单元总结
概述
本单元主要是依靠JML规格,编写能够完成规定功能的代码,并且在完成功能的基础上,对复杂度有一定的要求,要尽可能地降低和分散复杂度,使得程序运行速度尽可能快。本单元共有三次作业:
一、JML
JML(Java Modeling Language)是用于对Java程序进行规格化设计的一种工具,是行为接口规格语言,可用于指定Java模块的行为。对于调用者,只需要根据规格就可以知道方法调用后所产生的结果及其影响,而不需要去考虑其具体代码如何实现;对于开发者,只需要根据规格实现满足规格的代码即可,不需要对输入输出进行过多的考虑。JML常常被用于两个方面,一方面是设计规格,实现代码;另一方面是对已有的代码,书写规格,提高代码的可维护性。
1、理论基础
注释结构
JML以javadoc注释的方式来表示规格,每行以@起头。其中行注释为“//@annotation”,块注释为“/*@ annotation... @*/”
除此之外,JML一般都有requires子句、副作用范围限定和ensures子句。requires子句是定义该方法的前置条件,这是对调用者的一些要求,如果想要调用这个方法来得到预计的结果的话,那么需要满足requires子句中的条件才可以;副作用范围限定,这个是列出这个方法执行后,会对哪些类成员进行修改,\nothing代表不会对任何成员进行修改,也表示是个pure方法;ensures子句定义后置条件,这是对方法实现的要求,这个方法要是的ensures后面的子句条件为真。
需要注意的是,规格中的每个子句必须以分号结尾。
JML表达式
JML表达式是对Java表达式的扩展,其中比较常用的包括\result、\old、\forall、\exists等。
- \result:表示一个非void类型的方法返回值。
- \old(expr):表示expr在方法执行前的值。值得注意的是,当expr是一个对象引用的时候,那么只要expr没有发生改变,那么\old(expr)指向的还是引用后的对象,\old(expr).size()和expr.size()永真,如果想要获得对象在方法调用前的一些属性,应该使用\old(expr.size())类似的语句。
- \forall:全称量词修饰的表达式,表示对于给定范围的元素,都应该满足约束。
- \exists:存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足约束。
- 等价关系操作符:expr1<==>expr2或者expr1<=!=>expr2,表示expr1==expr2或者expr1!=expr2,优先级比==和!=低。
- 推理操作符:expr1==>expr2,当expr1==false或者expr1==true且expr2==ture时,整个表达式为true。
- \max、\min:返回给定范围内的表达式的最大值、最小值。
- \sum:返回给定范围内的表达式的和。
- \num_of:返回指定变量中满足条件的个数。
方法规格
方法规格除了上面所提到的前置条件、后置条件、副作用范围限定,还有更高一级的区分,就是正常行为规格(normal_behavior)和异常行为规格(expcetional_behavior)。正常行为规格对应着正常的输入输出,而异常行为规格则用于应对用户的所有可能输入。当一个方法规格中涉及多个功能规格描述,或者父类已经定义了规格,子类重写的该方法,需要补充规格,需要在规格前面或者之间加入also来分隔。通常在异常行为规格中,后置条件用来抛出异常,需要使用signals子句来表示。
类型规格
- invariant:不变式,是要求所有可见状态下都必须满足的特性。
- constraints:状态变化约束,对象的状态在变化时需要满足的一些特性。
2、应用工具链
- OpenJML:可以对规格进行规范检查, 也可以对代码进行静态和运行时检查。
- JMLUnitNG:是用于JML注释的Java代码的自动化单元测试生成工具。
二、部署JMLUnitNG
部署JMLUnitNG耗费了很多时间,可能是因为头铁,总是想要在Windows10下面配置的缘故,总是有些bug等着我。
首先由于工具的一些问题,就只好把MyPath删减了一些,写出了一个简化版的MyPath类,去掉了所有的\exists和\forall,具体代码如下:
1 import java.util.ArrayList; 2 import java.util.HashSet; 3 4 public class MyPath { 5 private /*@ spec_public @*/ ArrayList<Integer> nodes; 6 private /*@ spec_public @*/ HashSet<Integer> set; 7 8 public MyPath(int... nodeList) { 9 nodes = new ArrayList<Integer>(); 10 set = new HashSet<Integer>(); 11 for (int i = 0; i < nodeList.length; i++) { 12 Integer a = nodeList[i]; 13 nodes.add(a); 14 set.add(a); 15 } 16 } 17 18 //@ ensures \result == nodes.size(); 19 public /*@pure@*/ int size() { 20 return nodes.size(); 21 } 22 23 /*@ requires index >= 0 && index < size(); 24 @ assignable \nothing; 25 @ ensures \result == nodes.get(index).intValue(); 26 @*/ 27 public /*@pure@*/ int getNode(int index) { 28 return nodes.get(index); 29 } 30 31 //@ ensures \result == set.contains(i); 32 public boolean containsNode(int i) { 33 return set.contains(i); 34 } 35 36 //@ ensures \result == (nodes.size() >= 2); 37 public boolean isValid() { 38 return nodes.size() >= 2; 39 } 40 41 public static void main(String[] args) { 42 ; 43 } 44 }
其中存储节点的数据结构还是使用ArrayList,所以在原来规格中的nodes.length都要给成nodes.size(),同时nodes[i]也要改成nodes.get(i).intValue()才能够避免报错。
然后当前目录结构为
然后执行以下指令:
1 java -jar .\jmlunitng.jar .\src\MyPath.java 2 javac -cp .\jmlunitng.jar .\src\*.java 3 java -jar .\openjml.jar -rac .\src\MyPath.java
到这一步,运行还是没有太大问题,文件目录结构如下所示:
│ jmlunitng.jar
│ openjml.jar
│
├─out
└─src
MyPath.class
MyPath.java
MyPath_ClassStrategy_int.class
MyPath_ClassStrategy_int.java
MyPath_ClassStrategy_int1DArray.class
MyPath_ClassStrategy_int1DArray.java
MyPath_ClassStrategy_java_lang_String.class
MyPath_ClassStrategy_java_lang_String.java
MyPath_ClassStrategy_java_lang_String1DArray.class
MyPath_ClassStrategy_java_lang_String1DArray.java
MyPath_containsNode__int_i__0__i.class
MyPath_containsNode__int_i__0__i.java
MyPath_getNode__int_index__0__index.class
MyPath_getNode__int_index__0__index.java
MyPath_InstanceStrategy.class
MyPath_InstanceStrategy.java
MyPath_JML_Test.class
MyPath_JML_Test.java
MyPath_main__String1DArray_args__10__args.class
MyPath_main__String1DArray_args__10__args.java
MyPath_MyPath__int1DArray_nodeList__0__nodeList.class
MyPath_MyPath__int1DArray_nodeList__0__nodeList.java
PackageStrategy_int.class
PackageStrategy_int.java
PackageStrategy_int1DArray.class
PackageStrategy_int1DArray.java
PackageStrategy_java_lang_String.class
PackageStrategy_java_lang_String.java
PackageStrategy_java_lang_String1DArray.class
PackageStrategy_java_lang_String1DArray.java
出现很多java文件和class文件,但是当我们运行时会出现无法找到主类的错误,这时候我们可以将这些java文件复制到idea中,在idea中运行MyPath_JML_Test即可,需要注意的是,要将jmlunitng.jar文件添加到项目中。
运行结果如下所示:
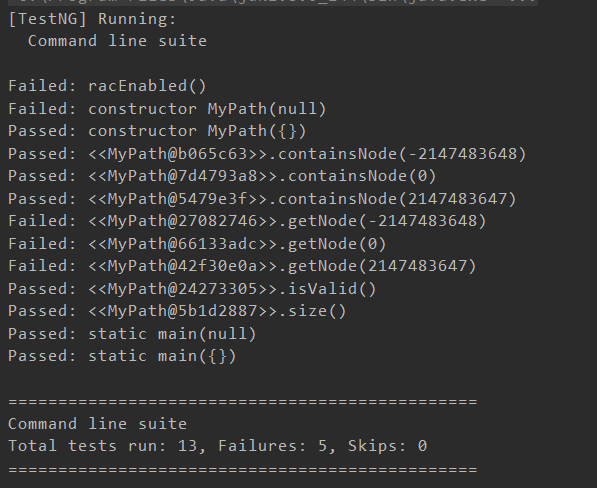
其中我们发现getNode方法出现的问题,虽然我们有requires,但是工具似乎并没有理我们,依旧出现了负数之类的测试。然后我们对这些方法进行了一些修改,得到了如下的结果:
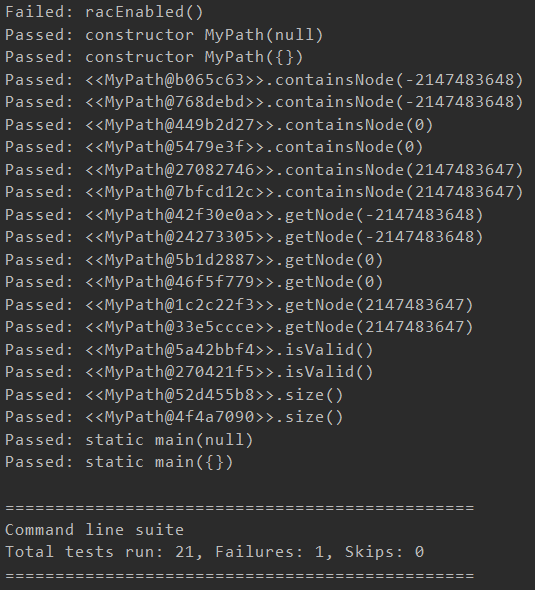
感觉整个测试样例似乎就是在测试整数溢出,对象是否为空等一些语法上的东西,似乎并没有测试一些方法逻辑上的东西,也有可能是代码太简单了,测试不出什么东西。
三、作业架构设计
第一次作业
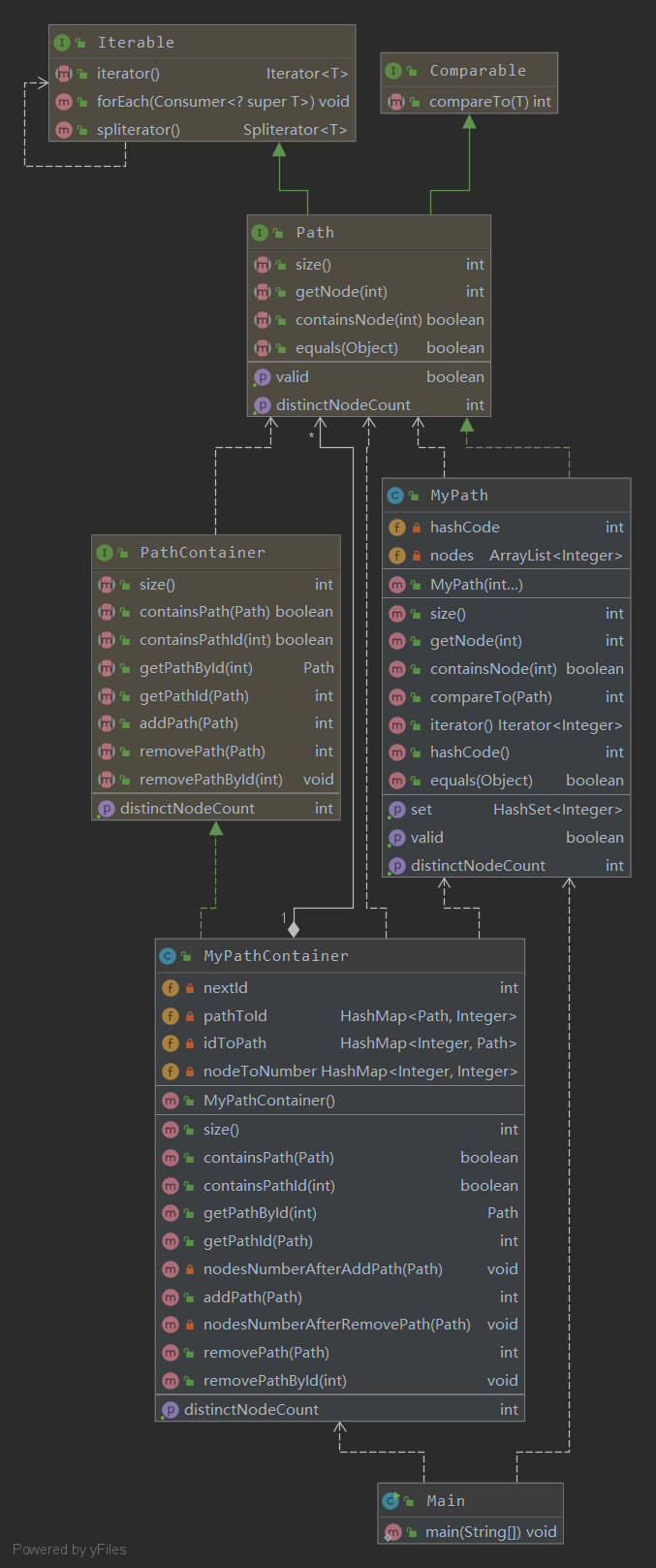
第一次作业比较简单,并没有什么需要架构设计的东西,完成两个需要的类就好了,其中MyPathContainer为了查找性能的提升,我加入了两个HashMap,PathId和Path的相互映射,使得getPathById和getPathId速度能够快一点,而且还加入了nodeToNumber的HashMap,来保存容器内有多少个不同的点。
第二次作业
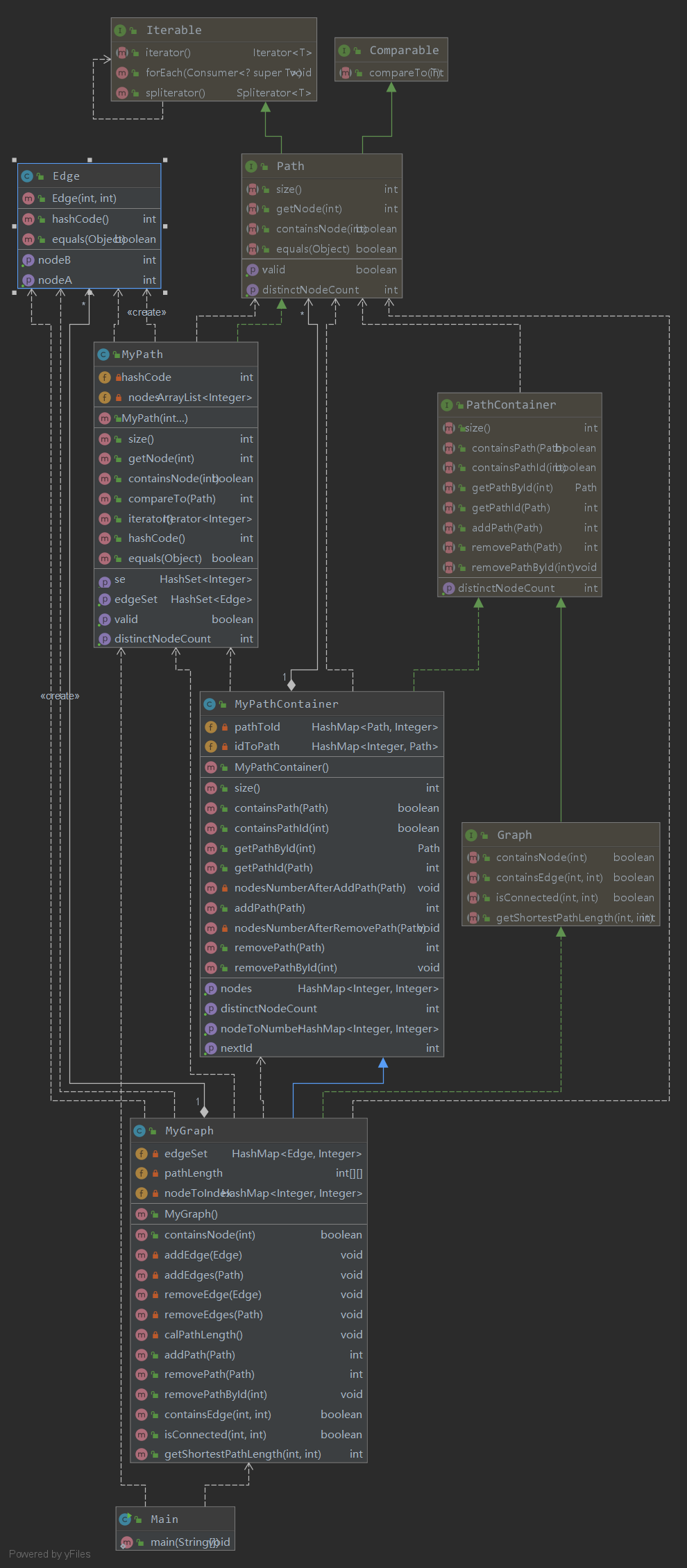
因为这一次作业的要求是对第一次作业的继承,所以这次作业我对第一次作业进行了继承,同时重写图变更函数,在不改变MyPathContainer的基础上,加入了对边的统计,在每次图变更之后,就计算各点之间的距离矩阵,同时使用Floyd算法来实现最短路径的计算,这个方法实现较为简单,而且复杂度也是可以承受的。
同时因为nodeId是在int范围内,而图内的最多节点个数不超过120个,所以距离矩阵最大不超过120*120,需要一个nodeId到距离矩阵index的映射,这同样也是在图变更的时候实现。而判断连通性则根据两点之间的最短路径长度来判断。这次作业的代码量并不大,主要是在实现Floyd算法上面,而且这个算法也不算难。
第三次作业
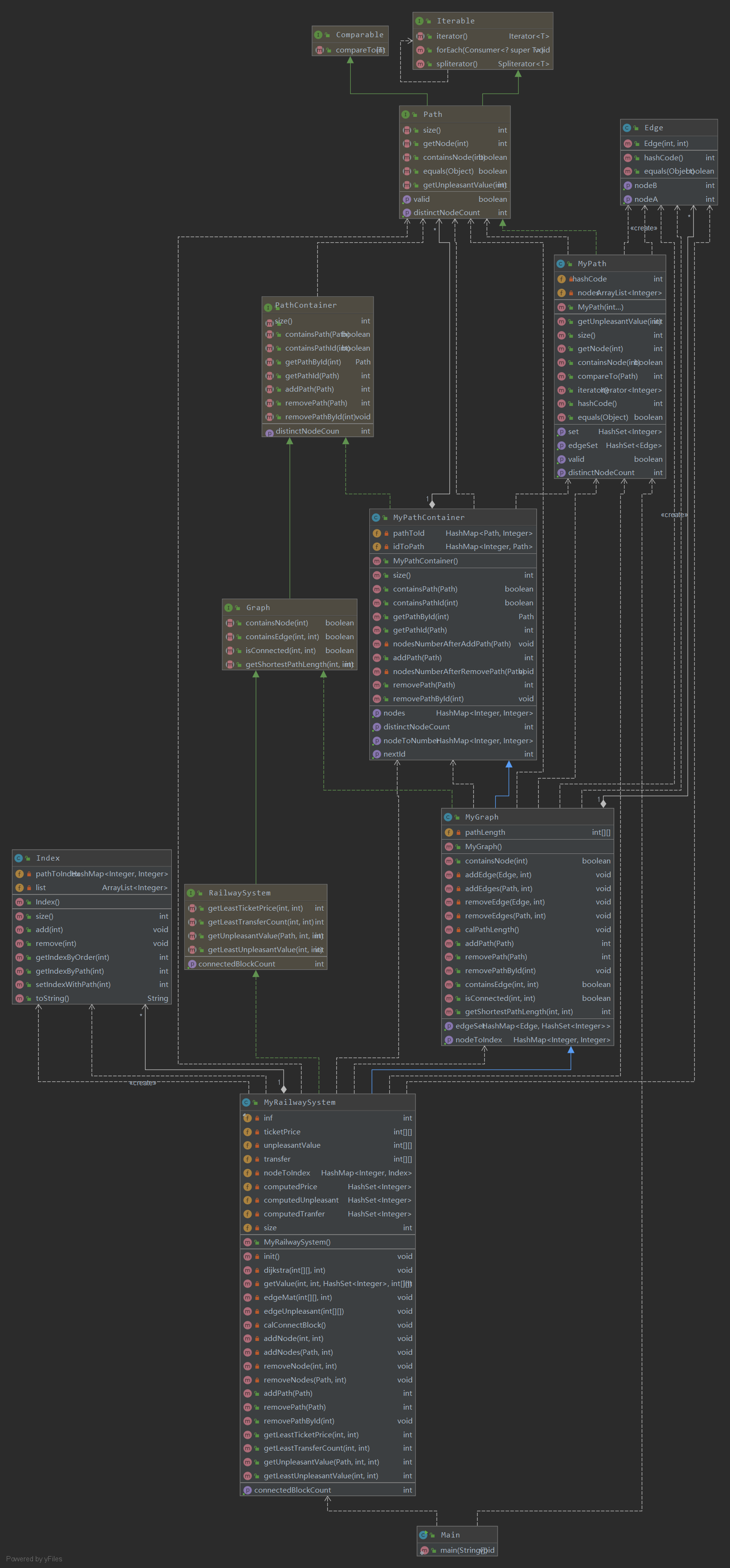
这次作业处理方式和第二次作业一样,都是继承上一次作业来继续写。这次的getLeastTickerPrice、getLeastUnpleasantValue和getLeastTransfer和第二次作业最短路径类似,只是需要考虑转乘的问题,可以通过拆点的方式,例如最小换乘可以在换乘站点之间的权值为1而其他边的权值为0的方式,来使用Floyd来求解。但是拆点可能使得距离矩阵变得非常巨大,如果针对这个来构造指令的话,那么距离矩阵会有4000+个点,Floyd的运算速度很慢,造成计算效率很低,所以我才用Dijkstra算法来解决这一问题。
首先我们对每个节点拆分成x+2个点,x为出现的路径总和,附加两个点为起点和终点,和这x个点有着一条有向边。然后我们最多只需要计算着120个起点到其他点的最短距离,复杂度降到了120*n^2,相比于n^3的复杂度,程序速度会快很多。而且Dijkstra是单源最短路径的算法,所以我们不需要一次性计算出所有的最短路径,只计算出需要的即可,如此我们可以增加一个HashMap,用来标记是否计算了该Node的最短路径,如此复杂度可以进一步降低。
在计算连通块个数的时候,我们可以通过循环来对所有点进行标记。因为MyGraph已经提供了点与点之间是否相连,所以我们可以一次取出一个未标记的点,然后遍历所有点来进行标记,一次可以标记一个连通块,所以循环n次就代表有n个联通块。
这次作业中,Dijkstra算法是一个重复的部分,大概需要计算三次,所以可以把这部分逻辑提取出来,做一个方法出来,但是我并没有提取出一个图计算类出来。如果提取一个图计算类出来,那么整个代码的耦合度能够降低许多,而且第二次作业的图计算也可以使用图计算类来实现。
四、代码实现的bug和修复
三次作业中均没有出现bug,不过有了解一些其他人的bug。比如在comparaTo函数中,字典序比较两条路径,有人使用对nodeId相减的方式进行判断,这会导致整数溢出。
五、规格撰写和理解的心得体会
规格撰写:规格的撰写用到了一些抽象,让我们去描述这些数据,在撰写规格的时候,只需要把方法当作一个黑箱,不需要考虑如何实现,只需要考虑前置条件、后置条件和副作用范围限定。对于我来说,简单的函数规格是比较容易写出的,而且有了规格,写代码也比较有方向。
理解:规格表述出来的意思非常严谨,但是相对于自然语言,还是有些难懂,尤其是一层嵌套一层的时候,那么理解起来就非常麻烦,而且规格是为了表示前置条件和后置条件,但实际实现的时候,和规格可能就差很远,有时候为了提高效率还有可能使用其他的算法来实现。对于我来说,一般是先看指导书了解这个方法是在干什么,然后再看规格来摸清细节。在实际实现的时候,一般要先设计数据的组织方式,然后再根据数据结构来写代码,而且由于规格已经限定了输入输出,逻辑简单的就按部就班地实现就好了,较为复杂的就需要分为多个方法来实现。规格对于代码的实现还是有很大帮助的,但是让程序员去理解的话,还需要一些自然语言的描述来辅助。
总的来说,JML对于实现上面肯定是有帮助的,但是目前来看并没有想象中的那么大,一方面是这个复杂逻辑的表示上面也是非常的复杂,对于程序员来说并不是那么友好,需要一些自然语言来辅助理解;另一方面,工具也不太利于使用,常常出现一些诡秘的bug,而且测试样例对于也局限于语法方面,对于代码逻辑还需要自行设计。但是JML非常严谨,对于程序员来说可以节省很多的精力用于处理输入输出,而是专心于代码的实现、复杂度的降低和bug的查找。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号