

C++开发时字符编码的选择
最近看了很多有关字符编码的讨论帖子, 自己也做了很多尝试, 针对linux和windows上字符编码的选择做了个简单整理, 在此做个记录
首先是基础编码知识, 下面我列出的4个编码方式或字符集是我们应该了解的
1. ANSI
2. UNICODE
3. UTF8
4. GB2312
这里因为个人专业水平有限, 为了避免错误的解释, 不对这些概念做详细解释, 而是贴出一些我查找到的有用的资料
Unicode 和 UTF-8 有什么区别 ---- https://www.zhihu.com/question/23374078
简体汉字编码方案(GB2312、GBK等)以及全角、半角、CJK ---- https://zhuanlan.zhihu.com/p/27099035
ANSI编码与代码页 ---- https://zhuanlan.zhihu.com/p/27136737
接下来是我自己的验证和尝试的过程以及自己的知识总结
先贴出来我在windows和linux环境下的测试代码, 编译器我分别用linux GCC, MSVC v100 和 MSVC v141做了测试
1 #ifdef _WIN32 2 #if _MSC_VER >= 1600 3 #pragma execution_character_set("utf-8") 4 #endif 5 #endif 6 7 #include <stdio.h> 8 #include <string> 9 10 int main() 11 { 12 std::string testANSI = "中国"; 13 std::wstring testUNICODE = L"中国"; 14 15 printf("sizeof wchar_t : %lu \n", sizeof(wchar_t)); 16 printf("length of std::string : %lu \n", testANSI.length()); 17 printf("length of std::wstring : %lu \n", testUNICODE.length()); 18 19 printf("ANSI :"); 20 for (size_t idx = 0; idx < testANSI.length(); ++idx) 21 { 22 printf(" %hhx", testANSI[idx]); 23 } 24 printf("\n"); 25 26 printf("UNICODE :"); 27 for (size_t idx = 0; idx < testUNICODE.length(); ++idx) 28 { 29 printf(" %hx", testUNICODE[idx]); 30 } 31 printf("\n"); 32 33 return 0; 34 }
下面贴出不同平台不同编码方式下程序的输出结果
1.windows环境下, 源代码编码为ANSI(本地gb2312)
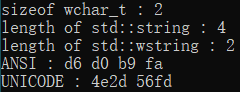
2.windows环境下, 源代码编码为UTF8, 不使用execution_character_set宏
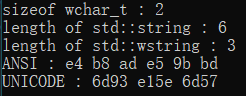
3.windows环境下, 源代码编码为带BOM的UTF8, 不使用execution_character_set宏
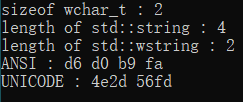
4.windows环境下, 源代码编码为UTF8, 使用execution_character_set宏
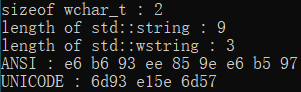
5.windows环境下, 源代码编码为带BOM的UTF8, 使用execution_character_set宏
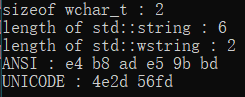
6. Ubuntu linux环境下, 源代码编码为带BOM的UTF8, 使用默认编码方式编译(这里我指定的编码方式即默认编码)

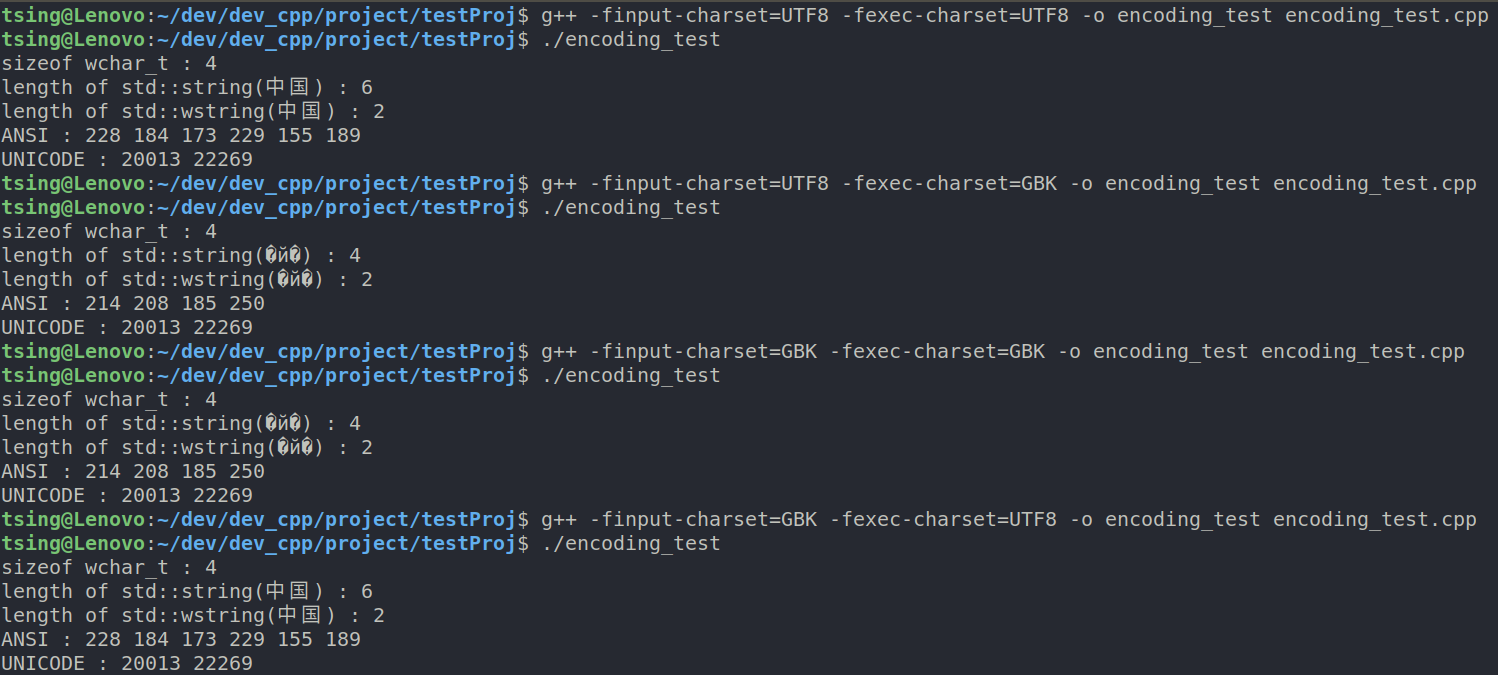
7. Ubuntu linux环境下, 源代码编码在UTF8和GBK之间变换, 指定不同编码输出
MSVC v100和MSVC v141(对应vs2010和vs2017)的结果相同, 上方windows平台运行截图均为vs2017编译运行结果
对上述结果进行总结
windows环境下, 源文件编码为不带BOM的UTF8时, 由于编译器没能正常识别文件编码, string的内容被保存为文件的原本内容(utf8), wstring保存的结果均是宽字符字符串, 而非UNICODE字符集
windows环境下, 源文件编码为带BOM的UTF8或ANSI时, 编译器能够正常识别文件编码(或者直接用本地编码解析), string内容被保存为gb2312字符串, wstring内容均为UNICODE字符集
上面两种情况, 仅当源文件编码为带BOM的UTF8且程序使用execution_character_set宏指明UTF8时, string内容才会被存为UTF8格式, UNICODE不受影响内容正常
linux环境下在文件输入编码格式正确的情况下, 不管怎么搞内容都一致, 且GCC编译器可以兼容带BOM的UTF8源文件
综上, 总结我个人的看法建议 :
纯Windows平台开发, 源代码使用ANSI, 字符类型选择wchar_t, 杜绝char和string, 并且避免使用POSIX, 使用MSVC编译器一定要在visual studio中选择使用UNICODE字符集(影响_UNICODE和UNICODE两个宏声明, 使用多字节则会声明宏_MBCS)
跨平台, 类Unix占大头则源代码使用UTF8, Windows占大头则源代码使用UTF8 with BOM并且选择不受影响的编译器, 字符类型选择char, 在调用API和IO时根据需要进行转换
重要的一点, 尽可能避免在源代码中使用ASCII码以外的任何字符(学好english是关键呐)
最后是我查阅和借鉴的资料,帖子,博文:
截止到 2017 年,C++ 对于 Unicode 支持情况如何 ---- https://www.zhihu.com/question/55601459
目前(2020 年)开发WINDOWS程序,用UNICODE还是多字节更实际 ---- https://www.zhihu.com/question/364285465
[C/C++] 各种C/C++编译器对UTF-8源码文件的兼容性测试(VC、GCC、BCB)---- https://www.cnblogs.com/zyl910/archive/2012/07/26/cfile_utf8.html
以上, 如有错误疏漏, 请务必指出, 任何问题欢迎讨论, 转载请注明, 感谢

 浙公网安备 33010602011771号
浙公网安备 33010602011771号