day3
初窥文件操作基本流程
计算机系统分为:计算机硬件,操作系统,应用程序三部分。
我们用python或其他语言编写的应用程序若想要把数据永久保存下来,必须要保存于硬盘中,这就涉及到应用程序要操作硬件,众所周知,应用程序是无法直接操作硬件的,这就用到了操作系统。操作系统把复杂的硬件操作封装成简单的接口给用户/应用程序使用,其中文件就是操作系统提供给应用程序来操作硬盘虚拟概念,用户或应用程序通过操作文件,可以将自己的数据永久保存下来。
有了文件的概念,我们无需再去考虑操作硬盘的细节,只需要关注操作文件的流程:
#1. 打开文件,得到文件句柄并赋值给一个变量 #2. 通过句柄对文件进行操作 #3. 关闭文件


#1. 打开文件,得到文件句柄并赋值给一个变量 f=open('a.txt','r',encoding='utf-8') #默认打开模式就为r #2. 通过句柄对文件进行操作 data=f.read() #3. 关闭文件 f.close() coding:文件操作
#1、由应用程序向操作系统发起系统调用open(...) #2、操作系统打开该文件,并返回一个文件句柄给应用程序 #3、应用程序将文件句柄赋值给变量f
关闭文件的注意事项
打开一个文件包含两部分资源:操作系统级打开的文件+应用程序的变量。在操作完毕一个文件时,必须把与该文件的这两部分资源一个不落地回收,回收方法为: 1、f.close() #回收操作系统级打开的文件 2、del f #回收应用程序级的变量 其中del f一定要发生在f.close()之后,否则就会导致操作系统打开的文件还没有关闭,白白占用资源, 而python自动的垃圾回收机制决定了我们无需考虑del f,这就要求我们,在操作完毕文件后,一定要记住f.close() 但是很多同学还是会忘记f.close(),对于这些同学,我们推荐傻瓜式操作方式:使用with关键字来帮我们管理上下文 with open('a.txt','w') as f: pass with open('a.txt','r') as read_f,open('b.txt','w') as write_f: data=read_f.read() write_f.write(data) 注意
文件编码
f=open(...)是由操作系统打开文件,那么如果我们没有为open指定编码,那么打开文件的默认编码很明显是操作系统说了算了,操作系统会用自己的默认编码去打开文件,在windows下是gbk,在linux下是utf-8。
#这就用到了上节课讲的字符编码的知识:若要保证不乱码,文件以什么方式存的,就要以什么方式打开。
f=open('a.txt','r',encoding='utf-8')
文件的打开模式
文件句柄 = open('文件路径', '模式')
模式可以是以下方式以及他们之间的组合:
| Character | Meaning |
| ‘r' | open for reading (default) |
| ‘w' | open for writing, truncating the file first |
| ‘a' | open for writing, appending to the end of the file if it exists |
| ‘b' | binary mode |
| ‘t' | text mode (default) |
| ‘+' | open a disk file for updating (reading and writing) |
| ‘U' | universal newline mode (for backwards compatibility; should not be used in new code) |
#1. 打开文件的模式有(默认为文本模式): r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】 w,只写模式【不可读;不存在则创建;存在则清空内容】 a, 之追加写模式【不可读;不存在则创建;存在则只追加内容】 #2. 对于非文本文件,我们只能使用b模式,"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式) rb wb ab 注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
#"+" 表示可以同时读写某个文件 r+, 读写【可读,可写】 w+,写读【可读,可写】 a+, 写读【可读,可写】 x, 只写模式【不可读;不存在则创建,存在则报错】 x+ ,写读【可读,可写】 xb 了解
文件内的光标移动
一: read(3):
1. 文件打开方式为文本模式时,代表读取3个字符
2. 文件打开方式为b模式时,代表读取3个字节
二: 其余的文件内光标移动都是以字节为单位如seek,tell,truncate
注意:
1. seek有三种移动方式0,1,2,其中1和2必须在b模式下进行,但无论哪种模式,都是以bytes为单位移动的
2. truncate是截断文件,所以文件的打开方式必须可写,但是不能用w或w+等方式打开,因为那样直接清空文件了,所以truncate要在r+或a或a+等模式下测试效果
with上下文管理
打开一个文件包含两部分资源:操作系统级打开的文件+应用程序的变量。在操作完毕一个文件时,必须把与该文件的这两部分资源一个不落地回收,回收方法为:
1、f.close() #回收操作系统级打开的文件
2、del f #回收应用程序级的变量
其中del f一定要发生在f.close()之后,否则就会导致操作系统打开的文件还没有关闭,白白占用资源,
而python自动的垃圾回收机制决定了我们无需考虑del f,这就要求我们,在操作完毕文件后,一定要记住f.close()
虽然我这么说,但是很多同学还是会忘记f.close(),对于这些同学,我们推荐傻瓜式操作方式:使用with关键字来帮我们管理上下文
with open('a.txt','w') as f:
pass
with open('a.txt','r') as read_f,open('b.txt','w') as write_f:
data=read_f.read()
write_f.write(data)
文件的修改
文件的数据是存放于硬盘上的,因而只存在覆盖、不存在修改这么一说,我们平时看到的修改文件,都是模拟出来的效果,具体的说有两种实现方式:
方式一:将硬盘存放的该文件的内容全部加载到内存,在内存中是可以修改的,修改完毕后,再由内存覆盖到硬盘(word,vim,nodpad++等编辑器)
import os with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f: data=read_f.read() #全部读入内存,如果文件很大,会很卡 data=data.replace('张三','SB') #在内存中完成修改 write_f.write(data) #一次性写入新文件 os.remove('a.txt') os.rename('.a.txt.swap','a.txt') 方法一
方式二:将硬盘存放的该文件的内容一行一行地读入内存,修改完毕就写入新文件,最后用新文件覆盖源文件
import os with open('a.txt') as read_f,open('.a.txt.swap','w') as write_f: for line in read_f: line=line.replace('alex','SB') write_f.write(line) os.remove('a.txt') os.rename('.a.txt.swap','a.txt') 方法二
练习
1. 文件a.txt内容:每一行内容分别为商品名字,价钱,个数,求出本次购物花费的总钱数
apple 10 3
tesla 100000 1
mac 3000 2
lenovo 30000 3
chicken 10 3
2. 修改文件内容,把文件中的张三都替换成SB
函数
为什么要用函数
现在python届发生了一个大事件,len方法突然不能直接用了。。。
然后现在有一个需求,让你计算'hello world'的长度,你怎么计算?
这个需求对于现在的你其实不难,我们一起来写一下。
s1 = "hello world" length = 0 for i in s1: length = length+1 print(length) for循环实现len功能
好了,功能实现了,非常完美。然后现在又有了一个需求,要计算另外一个字符串的长度,"hello wind".
于是,这个时候你的代码就变成了这样:
s1 = "hello world" length = 0 for i in s1: length = length+1 print(length) s2 = "hello wind" length = 0 for i in s2: length = length+1 print(length) for循环实现len功能2
这样确实可以实现len方法的效果,但是总感觉不是那么完美?为什么呢?
首先,之前只要我们执行len方法就可以直接拿到一个字符串的长度了,现在为了实现相同的功能我们把相同的代码写了好多遍 —— 代码冗余
其次,之前我们只写两句话读起来也很简单,一看就知道这两句代码是在计算长度,但是刚刚的代码却不那么容易读懂 —— 可读性差
print(len(s1)) print(len(s2))
我们就想啊,要是我们能像使用len一样使用我们这一大段“计算长度”的代码就好了。这种感觉有点像给这段代码起了一个名字,等我们用到的时候直接喊名字就能执行这段代码似的。要是能这样,是不是很完美啊?
初识函数定义与调用
现在就教大家一个既能,让你们把代码装起来。
def mylen(): s1 = "hello world" length = 0 for i in s1: length = length+1 print(length)
我们一起来分析一下这段代码做了什么。
其实除了def这一行和后面的缩进,其他的好像就是正常的执行代码。我们来执行一下,哦,好像啥也没发生。
刚刚我们已经说过,这是把代码装起来的过程。你现在只会往里装,还不会往出拿。那么应该怎么往出拿呢?我来告诉大家:
mylen()
是不是很简单?是不是似曾相识?这就是代码取出来的过程。刚刚我们就写了一个函数,并且成功调用了它。
#函数定义 def mylen(): """计算s1的长度""" s1 = "hello world" length = 0 for i in s1: length = length+1 print(length) #函数调用 mylen() 函数的定义和调用
总结一:
定义:def 关键词开头,空格之后接函数名称和圆括号(),最后还有一个":"。
def 是固定的,不能变,必须是连续的def三个字母,不能分开。
空格 为了将def关键字和函数名分开,必须空(四声),当然你可以空2格、3格或者你想空多少都行,但正常人还是空1格。
函数名:函数名只能包含字符串、下划线和数字且不能以数字开头。虽然函数名可以随便起,但我们给函数起名字还是要尽量简短,并能表达函数功能
括号:是必须加的,先别问为啥要有括号,总之加上括号就对了!
注释:每一个函数都应该对功能和参数进行相应的说明,应该写在函数下面第一行。以增强代码的可读性。
调用:就是 函数名() 要记得加上括号!
函数的返回值
刚刚我们就写了一个函数,这个函数可以帮助我们计算字符串的长度,并且把结果打印出来。但是,这和我们的len方法还不是太一样。哪里不一样呢?以前我们调用len方法会得到一个值,我们必须用一个变量来接收这个值。
str_len = len('hello,world')
这个str_len就是‘hello,world’的长度。那我们自己写的函数能做到这一点么?我们也来试一下。
#函数定义 def mylen(): """计算s1的长度""" s1 = "hello world" length = 0 for i in s1: length = length+1 print(length) #函数调用 str_len = mylen() print('str_len : %s'%str_len) 函数调用的结果
很遗憾,如果你执行这段代码,得到的str_len 值为None,这说明我们这段代码什么也没有给你返回。
那如何让它也想len函数一样返回值呢?
#函数定义 def mylen(): """计算s1的长度""" s1 = "hello world" length = 0 for i in s1: length = length+1 return length #函数调用 str_len = mylen() print('str_len : %s'%str_len)
我们只需要在函数的最后加上一个return,return后面写上你要返回的值就可以了。
接下来,我们就来研究一下这个return的用法。
return关键字的作用
return 是一个关键字,在pycharm里,你会看到它变成蓝色了。你必须一字不差的把这个单词给背下来。
这个词翻译过来就是“返回”,所以我们管写在return后面的值叫“返回值”
要研究返回值,我们还要知道返回值有几种情况:分别是没有返回值、返回一个值、返回多个值
没有返回值
不写return的情况下,会默认返回一个None:我们写的第一个函数,就没有写return,这就是没有返回值的一种情况。
#函数定义 def mylen(): """计算s1的长度""" s1 = "hello world" length = 0 for i in s1: length = length+1 print(length) #函数调用 str_len = mylen() #因为没有返回值,此时的str_len为None print('str_len : %s'%str_len) 不写return
只写return,后面不写其他内容,也会返回None,有的同学会奇怪,既然没有要返回的值,完全可以不写return,为什么还要写个return呢?这里我们要说一下return的其他用法,就是一旦遇到return,结束整个函数。
def ret_demo(): print(111) return print(222) ret = ret_demo() print(ret) 只写return
return None:和上面的两种情况一样,我们一般不这样写。
def ret_demo(): print(111) return None print(222) ret = ret_demo() print(ret) return None
返回一个值
刚刚我们已经写过一个返回一个值的情况,只需在return后面写上要返回的内容即可。
#函数定义 def mylen(): """计算s1的长度""" s1 = "hello world" length = 0 for i in s1: length = length+1 return length #函数调用 str_len = mylen() print('str_len : %s'%str_len) 返回一个值
注意:return和返回值之间要有空格,可以返回任意数据类型的值
返回多个值
可以返回任意多个、任意数据类型的值
def ret_demo1(): '''返回多个值''' return 1,2,3,4 def ret_demo2(): '''返回多个任意类型的值''' return 1,['a','b'],3,4 ret1 = ret_demo1() print(ret1) ret2 = ret_demo2() print(ret2) 返回多个值
返回的多个值会被组织成元组被返回,也可以用多个值来接收
def ret_demo2(): return 1,['a','b'],3,4 #返回多个值,用一个变量接收 ret2 = ret_demo2() print(ret2) #返回多个值,用多个变量接收 a,b,c,d = ret_demo2() print(a,b,c,d) #用多个值接收返回值:返回几个值,就用几个变量接收 a,b,c,d = ret_demo2() print(a,b,c,d) 多个返回值的接收
函数的参数
现在,我们已经把函数返回值相关的事情研究清楚了,我们自己已经完成了一个可以返回字符串长度的函数。但是现在这个函数还是不完美,之前我们使用len函数的时候得是length = len("hello world"),这样我可以想计算谁就计算谁的长度。但是现在我们写的这个函数,只能计算一个“hello world”的长度,换一个字符串好像就是不行了。这可怎么办?
#函数定义 def mylen(s1): """计算s1的长度""" length = 0 for i in s1: length = length+1 return length #函数调用 str_len = mylen("hello world") print('str_len : %s'%str_len) 带参数的函数
我们告诉mylen函数要计算的字符串是谁,这个过程就叫做 传递参数,简称传参,我们调用函数时传递的这个“hello world”和定义函数时的s1就是参数。
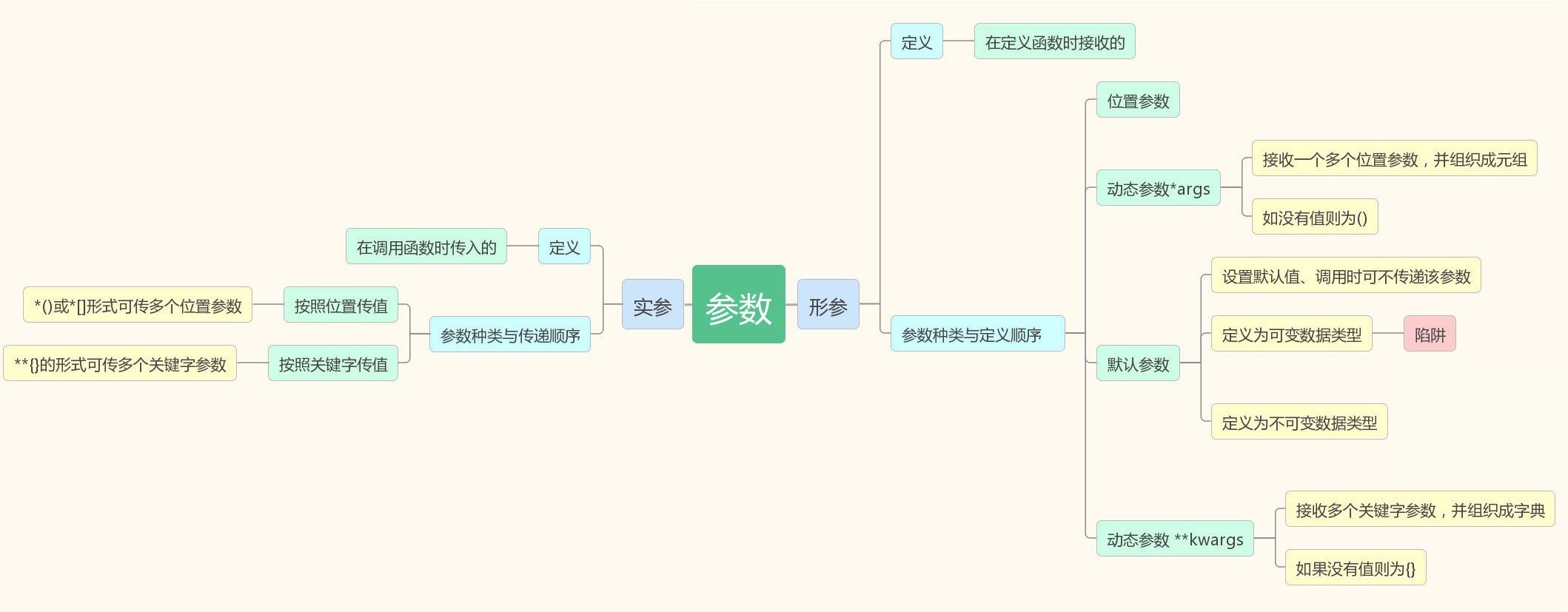
实参与形参
参数还有分别:
我们调用函数时传递的这个“hello world”被称为实际参数,因为这个是实际的要交给函数的内容,简称实参。
定义函数时的s1,只是一个变量的名字,被称为形式参数,因为在定义函数的时候它只是一个形式,表示这里有一个参数,简称形参。
传递多个参数
参数可以传递多个,多个参数之间用逗号分割。
def mymax(x,y): the_max = x if x > y else y return the_max ma = mymax(10,20) print(ma) 传递多个参数
也正是因为需要传递多个参数、可以传递多个参数,才会有了后面这一系列参数相关的故事。。。
位置参数
站在实参角度
1.按照位置传值
def mymax(x,y): #此时x=10,y=20 the_max = x if x > y else y return the_max ma = mymax(10,20) print(ma) 按照位置传参
2.按照关键字传值
def mymax(x,y): #此时x = 20,y = 10 print(x,y) the_max = x if x > y else y return the_max ma = mymax(y = 10,x = 20) print(ma) 按照关键字传参
3.位置、关键字形式混着用
def mymax(x,y): #此时x = 10,y = 20 print(x,y) the_max = x if x > y else y return the_max ma = mymax(10,y = 20) print(ma) 位置、关键字混用传参
正确用法
问题一:位置参数必须在关键字参数的前面
问题二:对于一个形参只能赋值一次
站在形参角度
位置参数必须传值
def mymax(x,y): #此时x = 10,y = 20 print(x,y) the_max = x if x > y else y return the_max #调用mymax不传递参数 ma = mymax() print(ma) #结果 TypeError: mymax() missing 2 required positional arguments: 'x' and 'y' 位置参数必须传参
默认参数
1.正常使用
使用方法
为什么要有默认参数:将变化比较小的值设置成默认参数
2.默认参数的定义
def stu_info(name,sex = "male"): """打印学生信息函数,由于班中大部分学生都是男生, 所以设置默认参数sex的默认值为'male' """ print(name,sex) stu_info('班长') stu_info('班长女朋友','female') 默认参数
3.参数陷阱:默认参数是一个可变数据类型
def defult_param(a,l = []): l.append(a) print(l) defult_param('张三') defult_param('李四')
动态参数
按位置传值多余的参数都由args统一接收,保存成一个元组的形式
def mysum(*args): the_sum = 0 for i in args: the_sum+=i return the_sum the_sum = mysum(1,2,3,4) print(the_sum) *args求和函数应用
def stu_info(**kwargs): print(kwargs) print(kwargs['name'],kwargs['sex']) stu_info(name = 'alex',sex = 'male')
实际开发中:
未来还会用到的场景。。。
问题:
位置参数、默认参数、动态参数定义的顺序以及接收的结果?
参数总结:
命名空间和作用域
命名空间的本质:存放名字与值的绑定关系
在python之禅中提到过:命名空间是一种绝妙的理念,让我们尽情的使用发挥吧!
命名空间一共分为三种:
全局命名空间
局部命名空间
内置命名空间
*内置命名空间中存放了python解释器为我们提供的名字:input,print,str,list,tuple...它们都是我们熟悉的,拿过来就可以用的方法。
三种命名空间之间的加载与取值顺序:
加载顺序:内置命名空间(程序运行前加载)->全局命名空间(程序运行中:从上到下加载)->局部命名空间(程序运行中:调用时才加载)
取值:
在局部调用(优先级):局部命名空间->全局命名空间->内置命名空间
x = 1 def f(x): print(x) print(10)
在全局调用(优先级):全局命名空间->内置命名空间
x = 1 def f(x): print(x) f(10) print(x) 在全局引用变量x
print(max)
作用域
作用域就是作用范围,按照生效范围可以分为全局作用域和局部作用域。
全局作用域:包含内置名称空间、全局名称空间,在整个文件的任意位置都能被引用、全局有效
局部作用域:局部名称空间,只能在局部范围内生效
globals和locals方法
print(globals())
print(locals())
def func(): a = 12 b = 20 print(locals()) print(globals()) func() 在局部调用globals和locals
global关键字
a = 10 def func(): global a a = 20 print(a) func() print(a) global关键字
函数的嵌套和作用域链
函数的嵌套调用
def max2(x,y): m = x if x>y else y return m def max4(a,b,c,d): res1 = max2(a,b) res2 = max2(res1,c) res3 = max2(res2,d) return res3 # max4(23,-7,31,11) 函数的嵌套调用
函数的嵌套定义
def f1(): print("in f1") def f2(): print("in f2") f2() f1() 函数的嵌套定义(一)
def f1(): def f2(): def f3(): print("in f3") print("in f2") f3() print("in f1") f2() f1() 函数的嵌套定义(二)
函数的作用域链
def f1(): a = 1 def f2(): print(a) f2() f1() 作用域链(一)
def f1(): a = 1 def f2(): def f3(): print(a) f3() f2() f1() 作用域链(二)
def f1(): a = 1 def f2(): a = 2 f2() print('a in f1 : ',a) f1() 作用域链(三)
nonlocal关键字
# 1.外部必须有这个变量
# 2.在内部函数声明nonlocal变量之前不能再出现同名变量
# 3.内部修改这个变量如果想在外部有这个变量的第一层函数中生效
def f1(): a = 1 def f2(): nonlocal a a = 2 f2() print('a in f1 : ',a) f1() nonlocal关键字
函数小结
面向过程编程的问题:代码冗余、可读性差、可扩展性差(不易修改)
定义函数的规则:
1.定义:def 关键词开头,空格之后接函数名称和圆括号()。 2.参数:圆括号用来接收参数。若传入多个参数,参数之间用逗号分割。
参数可以定义多个,也可以不定义。
参数有很多种,如果涉及到多种参数的定义,应始终遵循位置参数、*args、默认参数、**kwargs顺序定义。
如上述定义过程中某参数类型缺省,其他参数依旧遵循上述排序 3.注释:函数的第一行语句应该添加注释。 4.函数体:函数内容以冒号起始,并且缩进。 5.返回值:return [表达式] 结束函数。不带表达式的return相当于返回 None def 函数名(参数1,参数2,*args,默认参数,**kwargs): """注释:函数功能和参数说明""" 函数体 …… return 返回值
调用函数的规则:
1.函数名()
函数名后面+圆括号就是函数的调用。
2.参数:
圆括号用来接收参数。
若传入多个参数:
应按先位置传值,再按关键字传值
具体的传入顺序应按照函数定义的参数情况而定
3.返回值
如果函数有返回值,还应该定义“变量”接收返回值
如果返回值有多个,也可以用多个变量来接收,变量数应和返回值数目一致
无返回值的情况:
函数名()
有返回值的情况:
变量 = 函数名()
多个变量接收多返回值:
变量1,变量2,... = 函数名()
命名空间:
一共有三种命名空间从大范围到小范围的顺序:内置命名空间、全局命名空间、局部命名空间
作用域(包括函数的作用域链):
小范围的可以用大范围的
但是大范围的不能用小范围的
范围从大到小(图)
练习题
1、一个文本文件内容如下,统计其中的每个单词出现的个数,注意是每个单词。。
hello,wind,how are you?are you eating?
2、写函数,计算传入数字参数的和。(动态传参)
3、写函数,用户传入修改的文件名,与要修改的内容,执行函数,完成整个文件的批量修改操作
4、写函数,返回一个扑克牌列表,里面有52项(没有大小王),每一项是一个元组
例如:[("红心",2),("草花",2),("方块",2) …("黑桃","A")]
# 思路: a = [2,3,4,5,6,7,8,9,10,'J','Q','K','A']
b=['红心','草花','方块','黑桃']
5、写函数,专门计算图形的面积
- 其中嵌套函数,计算圆的面积,正方形的面积和长方形的面积
- 调用函数area(‘圆形’,圆半径) 返回圆的面积
- 调用函数area(‘正方形’,边长) 返回正方形的面积
- 调用函数area(‘长方形’,长,宽) 返回长方形的面积
#代码模板 def area(): def 计算长方形面积(): pass def 计算正方形面积(): pass def 计算圆形面积(): pass

 浙公网安备 33010602011771号
浙公网安备 33010602011771号