理解字节对齐
理解字节对齐
1.什么是字节对齐?
现代计算机中,内存空间按照字节划分,理论上可以从任何起始地址访问任意类型的变量。但实际中在访问特定类型变量时经常在特定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序一个接一个地存放,这就是对齐。
变量存的起始地址必须具备某些特性----“对齐”,比如4字节的int型,其起始地址应该位于4字节的边界上,即起始地址能够被4整除。
对齐跟数据在内存中的位置有关。为了使得CPU能快速对变量进行访问,变量存的起始地址必须具备某些特性,即“对齐”,比如4字节的int型,其起始地址应该位于4字节的边界上,即起始地址能够被4整除。====>>>>cpu类型,编译器类型。
2.为什么要字节对齐
①首先,不同硬件平台对存储空间的处理上存在不同;
某些平台对特定类型的数据只能从特定地址开始存取,而不允许其在内存中任意存放。例如,Motorola 68000 处理器不允许16位的字存放在奇地址,否则会触发异常,因此在这种架构下编程必须保证字节对齐。
②根本原因在于CPU访问数据的效率问题;
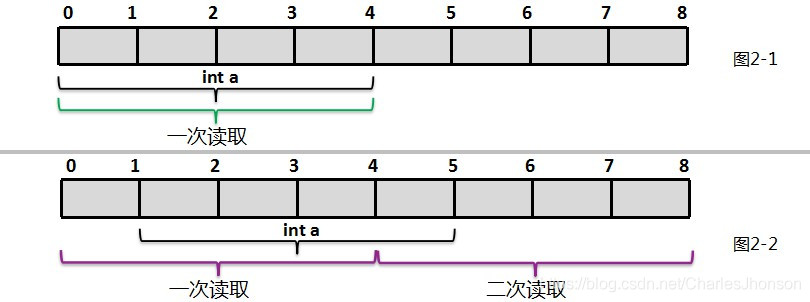
以32位机为例,它每次取32个位,也就是4个字节。以int型数据为例,如果它在内存中存放的位置按4字节对齐,也就是说1个int的数据全部落在计算机一次取数的区间内,那么只需要取一次就可以了。如图2-1。如果不对齐,很不巧,这个int数据刚好跨越了取数的边界,这样就需要取两次才能把这个int的数据全部取到,如图2-2,这样效率也就降低了。
③其次节约空间。
应该辩证地看:合理对齐,则节约空间;否则浪费空间。如下例:

结构体TEST1中包含一个4字节的int数据,一个1字节char数据和一个2字节short数据;TEST2也一样。按理说TEST1和TEST2的大小应该都是7字节。之所以出现上述结果,就是因为编译器要对数据成员在空间上进行对齐。
3.如何对齐
3.1 标准类型(基本数据类型):
基本类型包括char、int、float、double、short、long等基本数据类型。
对齐要求:起始地址为其长度的整数倍即可。如,int类型的变量起始地址要求为4的整数倍。
3.2 数组:
按照基本数据类型对齐,第一个对齐了后面的自然也就对齐了。
3.3 结构体
成员可以为:基本类型,复合类型(基本类型、数组、结构、联合、函数指针)
结构体中每个数据类型都要对齐,对齐值为其成员中自身对齐值最大的那个值。


3.4 联合体
联合体的内存除了取最大成员内存外,还要保证是所有成员类型size的最小公倍数。

当然只取最大的int数组的大小12没错,但是double是8字节的,而此时联合体已经按int的4字节对齐了,所以还要额外多加4字节的内存来保证8的倍数。所以最后结果是16。
所以联合体的内存除了取最大成员内存外,还要保证是所有成员类型size的最小公倍数
3.5 指定对齐方式
#pragma pack(n) //设置n字节对齐
#pragma pack() //取消自定义字节对齐方式
以n和结构体中最长的成员的长度中较小者为其值。
__attribute((aligned (n))) //设置n字节对齐
attribute ((packed)) //设置1字节对齐
(gcc特性)
让所作用的结构成员对齐在n字节自然边界上。如果结构中有成员的长度大于n,则按照最大成员的长度来对齐。

微软的 __alignof( type )
如:
typedef __declspec(align(32)) struct { int a; } S;
_alignof(S) 等于 32
总结:
①基本类型:自身对齐
②数组:
③联合:成员最大对齐值,公倍数;
④结构体:其成员中自身对齐值最大的那个值。
⑤指定对齐方式:
#pragma pack (n)和pragma pack ();
attribute((aligned(n)))和__attribute__((packed))。
⑥数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中较小者,即有效对齐值=min{自身对齐值,当前指定的pack值};注意_attribute__。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号