【PAT刷题】快速产出垃圾——2020-3-29
A1155
感觉处理大顶堆小顶堆的时候有些问题,可以再优化一下
1 #include <cstdio> 2 #include <algorithm> 3 #include <vector> 4 using namespace std; 5 6 vector<int> out; 7 8 struct node 9 { 10 int key; 11 int lchild, rchild; 12 }; 13 node nodes[1010]; 14 vector<int> swt; 15 16 int sum(vector<int> arr) { 17 int sum = 0; 18 for (int i = 0; i < arr.size(); i++) { 19 sum += arr[i]; 20 } 21 return sum; 22 } 23 24 void DFS(int idx) { 25 out.push_back(nodes[idx].key); 26 if (nodes[idx].rchild == -1 && nodes[idx].lchild == -1) { 27 int much = 0; 28 int minor = 0; 29 for (int i = 0; i < out.size(); i++) { 30 printf("%d", out[i]); 31 if (i != out.size() - 1) printf(" "); 32 else printf("\n"); 33 if (i != 0) { 34 if (out[i] >= out[i - 1]) minor++; 35 if (out[i] <= out[i - 1]) much++; 36 } 37 } 38 if (much == out.size() - 1) swt.push_back(2); 39 else if (minor == out.size() - 1) swt.push_back(1); 40 else swt.push_back(0); 41 } 42 if(nodes[idx].rchild != -1) { 43 DFS(2 * idx + 1); 44 } 45 if(nodes[idx].lchild != -1) { 46 DFS(2 * idx); 47 } 48 out.pop_back(); 49 } 50 51 int main() { 52 node tmp; 53 tmp.key = -1; 54 tmp.lchild = -1; 55 tmp.rchild = -1; 56 fill(nodes, nodes+1010, tmp); 57 int n; 58 scanf("%d", &n); 59 for (int i = 1; i <= n; i++) { 60 scanf("%d", &nodes[i].key); 61 if(2*i<=n) nodes[i].lchild = 2 * i; 62 if(2*i+1<=n) nodes[i].rchild = 2 * (i + 1); 63 64 } 65 DFS(1); 66 int sum1 = sum(swt); 67 if (sum1 == swt.size() * 2) printf("Max Heap"); 68 else if (sum1 == swt.size()) printf("Min Heap"); 69 else printf("Not Heap"); 70 }
这东西层次遍历很方便,而且判断反面就好。
1 for (int i = 2; i <= n; i++) { 2 if (a[i/2] > a[i]) isMin = 0; 3 if (a[i/2] < a[i]) isMax = 0; 4 }
A1154
感觉现在就是读题不够认真。。
1 #include <cstdio> 2 #include <algorithm> 3 #include <vector> 4 #include <set> 5 using namespace std; 6 7 const int maxn = 10010; 8 9 struct edge { 10 int a, b; 11 }; 12 int nodes[maxn]; 13 vector<edge> edges; 14 set<int> colors; 15 16 17 int main() { 18 int n, m; 19 scanf("%d%d", &n, &m); 20 for (int i = 0; i < m; i++) { 21 int a, b; 22 scanf("%d%d", &a, &b); 23 edge tmp; 24 tmp.a = a; 25 tmp.b = b; 26 edges.push_back(tmp); 27 } 28 int K; 29 scanf("%d", &K); 30 for (int i = 0; i < K; i++) { 31 for (int j = 0; j < n; j++) { 32 scanf("%d", &nodes[j]); 33 colors.insert(nodes[j]); 34 } 35 bool isColor = true; 36 for (int k = 0; k < m; k++) { 37 if (nodes[edges[k].a] == nodes[edges[k].b]) isColor = false; 38 } 39 if (isColor) printf("%d-coloring\n", colors.size()); 40 else printf("No\n"); 41 colors.clear(); 42 } 43 44 }
要不就遍历边要不就深度优先,这题点的索引不一定是按顺序的,同时注意遍历的时候的索引别搞乱了。
A1153
1 #include <cstdio> 2 #include <string> 3 #include <iostream> 4 #include <algorithm> 5 #include <vector> 6 using namespace std; 7 8 const int maxn = 10010; 9 10 struct stu { 11 string cardnum; 12 char level; 13 int site, date, num, score; 14 }stus[maxn]; 15 16 struct out3 { 17 int site, count = 0; 18 }; 19 20 vector<stu> out; 21 22 int toInt(string a) { 23 int sum = 0; 24 for(int i=0;i<a.size();i++){ 25 sum = sum * 10 + (a[i] - '0'); 26 } 27 return sum; 28 } 29 30 bool cmpScore(stu a, stu b) { 31 if(a.score!=b.score) return a.score > b.score; 32 else return a.cardnum <= b.cardnum; 33 } 34 bool cmpCount(out3 a, out3 b) { 35 if (a.count != b.count) return a.count > b.count; 36 else return a.site < b.site; 37 } 38 39 int main() { 40 int N, M; 41 scanf("%d%d", &N, &M); 42 for (int i = 0; i < N; i++) { 43 string tmp; 44 int score; 45 cin >> tmp >> score; 46 stus[i].cardnum = tmp; 47 stus[i].level = tmp.substr(0, 1)[0]; 48 stus[i].site = toInt(tmp.substr(1, 3)); 49 stus[i].date = toInt(tmp.substr(4, 6)); 50 stus[i].num = toInt(tmp.substr(10, 3)); 51 stus[i].score = score; 52 } 53 for (int i = 1; i <= M; i++) { 54 int type; 55 scanf("%d", &type); 56 57 if (type == 1) { 58 char a; 59 scanf(" %c", &a); 60 printf("Case %d: %d %c\n", i, type, a); 61 for (int j = 0; j < N; j++) { 62 if (stus[j].level == a) { 63 out.push_back(stus[j]); 64 } 65 } 66 sort(out.begin(), out.end(), cmpScore); 67 for (int j = 0; j < out.size(); j++) { 68 printf("%c%d%06d%03d %d\n", out[j].level, out[j].site, 69 out[j].date, out[j].num, out[j].score); 70 } 71 if (out.size() == 0) printf("NA\n"); 72 } 73 74 else if (type == 2) { 75 int site; 76 scanf("%d", &site); 77 printf("Case %d: %d %03d\n", i, type, site); 78 for (int j = 0; j < N; j++) { 79 if (stus[j].site == site) { 80 out.push_back(stus[j]); 81 } 82 } 83 int num = 0, sum = 0; 84 for (int j = 0; j < out.size(); j++) { 85 num++; 86 sum += out[j].score; 87 } 88 if(out.size()!=0) printf("%d %d\n", num, sum); 89 else printf("NA\n"); 90 } 91 else if (type == 3) { 92 int date; 93 scanf("%d", &date); 94 printf("Case %d: %d %06d\n", i, type, date); 95 out3 count[maxn]; 96 int num = 0; 97 for (int j = 0; j < N; j++) { 98 if (stus[j].date == date) { 99 if (count[stus[j].site].count == 0) num++; 100 count[stus[j].site].site = stus[j].site; 101 count[stus[j].site].count++; 102 } 103 } 104 sort(count, count + maxn, cmpCount); 105 for (int j = 0; j < num; j++) { 106 printf("%03d %d\n", count[j].site, count[j].count); 107 } 108 if (num == 0) printf("NA\n"); 109 } 110 out.clear(); 111 112 } 113 }
没做出来一定是因为题读的有问题,这里的问题就是输出的时候没看到如果存在分数相同的情况下需要按照卡号排序。
A1152
#include <cstdio> #include <cmath> #include <iostream> #include <string> using namespace std; const int maxn = 1010; bool isPrime(int a) { int max = sqrt(a); for (int i = 2; i <= max; i++) { if (a%i == 0) return false; } return true; } int toInt(string str) { int ans = 0; for (int i = 0; i < str.size(); i++) { ans = ans * 10 + (str[i]-'0'); } return ans; } int main() { int n, m; scanf("%d%d", &n, &m); string num; cin >> num; int end = m - 1; bool ok = false; while (end < n) { string tmpNum = ""; for (int i = end-m+1; i <=end; i++) { tmpNum = tmpNum + num[i]; } if (isPrime(toInt(tmpNum))) { cout << tmpNum; ok = true; break; } end++; } if (ok == false) printf("%d", 404); }
算是比较简单的题了。
A1151
这个题打算从网上找几种解法深入理解一下。其主要考察点即LCA:寻找二叉树两个结点最深祖先。
解法1:
将二叉树映射到BST上,在BST上查找结果并映射回去。
首先先看下A1143这道题:去找一棵BST的LCA。
1 #include <iostream> 2 #include <map> 3 #include <vector> 4 using namespace std; 5 map<int, bool> mp; 6 int main() { 7 int m, n, u, v, a; 8 cin >> m >> n; 9 vector<int> pre(n); 10 for (int i = 0; i < n; i++) { 11 cin >> pre[i]; 12 mp[pre[i]] = true; 13 } 14 for (int i = 0; i < m; i++) { 15 cin >> u >> v; //两个需要查找的结点值 16 for (int j = 0; j < n; j++) { 17 a = pre[j]; //暂存每个先序结果 18 if ((a > u&& a < v) || (a > v&& a < u) || (a == u) || (a == v)) break; 19 //二叉查找树的中序遍历本身是有序的。 20 //在先序遍历结果中查找一个介于u和v之间的值,那么这个就是根。 21 } 22 if (mp[u] == false && mp[v] == false) { 23 //首先map中默认为false; 24 //这里先存储了查找结果,也就是某个值在不在树中, 25 //节约了查找消耗的资源 26 printf("ERROR: %d and %d are not found.\n", u, v); 27 } 28 else if (mp[u] == false || mp[v] == false) { 29 printf("ERROR: %d is not found.\n", mp[u] == false ? u : v); 30 } 31 else if (a == u || a == v) { 32 printf("%d is an ancestor of %d.\n", a, a == u ? v : u); 33 } 34 else printf("LCA of %d and %d is %d.\n", u, v, a); 35 } 36 return 0; 37 }
思路是在输入时存储先序遍历,并建立映射看某个值是否存在树中。
然后检查需要查找的两个值,查找在树中这两个值中间的一个值(闭区间)。如果u,v都在树中,这个是一定能找到的。
然后u和v如果有不在树中的,再分类讨论。
如果都在树中,那么就来判断a是否是u或者v,再分类讨论即可。
关于为什么一定需要给出先序遍历,如果二叉查找树退化成为链表 ,那么小的值就成为了大的值得根。下边是一个全是右子树的例子,在这个算法中我们会首先找到第一个在要求范围内部的值记作a,而先序遍历决定了根优先于右,所以在先序遍历时LCA一定是最先找到的。总之先序遍历是必要的。
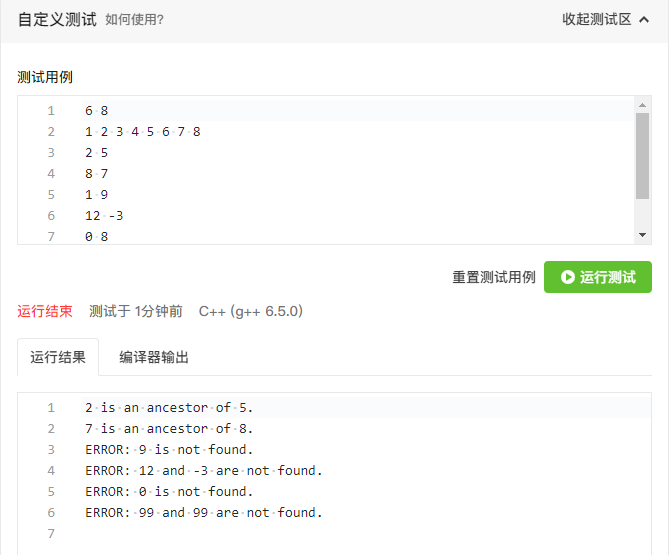
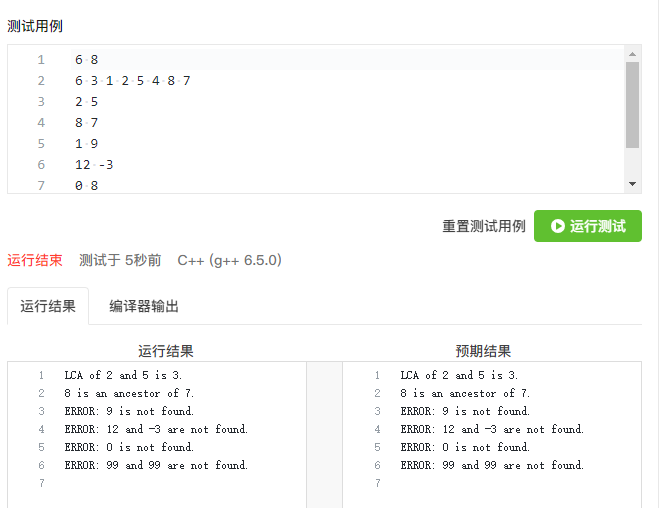
再看回A1151
关键是如何把普通二叉树变成BST这件事。实际上就是两颗结构完全相同的树,值不同。相互映射即可。最后再映射回去来打印。
1 #include <iostream> 2 #include <vector> 3 #include <cstring> 4 #include <cstdio> 5 #include <map> 6 7 using namespace std; 8 9 int m, n; 10 int opre[10009], oin[10009]; 11 int pre[10009], in[10009]; 12 map<int, int> otos, stoo; 13 14 int main() { 15 cin >> m >> n; 16 for (int i = 0; i < n; i++) { 17 cin >> oin[i]; //oin是原本的中序遍历 18 otos[oin[i]] = i; //中序的普通二叉树->BST 19 stoo[i] = oin[i]; //中序的BST->普通二叉树 20 } 21 for (int i = 0; i < n; i++) { 22 cin >> opre[i]; //原本的先序遍历 23 pre[i] = otos[opre[i]]; //最终的目的将原树映射为二叉查找数。先序遍历。 24 //二叉排序树的先序 25 } 26 27 for (int i = 0; i < m; i++) { 28 int u, v; 29 int a; 30 bool flag1 = true, flag2 = true; 31 cin >> u >> v; 32 if (otos.find(u) == otos.end()) flag1 = false; //能否查找到 33 if (otos.find(v) == otos.end()) flag2 = false; //能否查找到 34 35 if (!flag1 || !flag2) { 36 if (!flag1 && !flag2) { 37 printf("ERROR: %d and %d are note found.\n", u, v); 38 } 39 else { 40 printf("ERROR: %d is not found.\n", flag1 == false ? u : v); 41 } 42 continue; 43 //树里没这值,直接跳过 44 } 45 46 u = otos[u]; //转化为BST 47 v = otos[v]; 48 for (int j = 0; j < n; j++) { 49 a = pre[j]; //BST的先序 50 if (a > u && a < v || a<u && a>v || a == u || a == v) { 51 break; 52 } 53 } 54 //转化回去 55 u = stoo[u]; 56 v = stoo[v]; 57 a = stoo[a]; 58 if (a == u || a == v) { 59 printf("%d is an ancestor of %d.\n", a, a == u ? v : u); 60 } 61 else 62 { 63 printf("LCA of %d and %d is %d.\n", u, v, a); 64 } 65 } 66 return 0; 67 68 }
A1150
过不了看答案
1 #include <iostream> 2 #include <vector> 3 #include <set> 4 using namespace std; 5 int e[300][300], n, m, k, ans = 99999999, ansid; 6 vector<int> v; 7 void check(int index) { 8 int sum = 0, cnt, flag = 1; 9 scanf("%d", &cnt); 10 set<int> s; 11 vector<int> v(cnt); 12 for (int i = 0; i < cnt; i++) { 13 scanf("%d", &v[i]); 14 s.insert(v[i]); 15 } 16 for (int i = 0; i < cnt - 1; i++) { 17 if (e[v[i]][v[i + 1]] == 0) flag = 0; 18 sum += e[v[i]][v[i + 1]]; 19 } 20 if (flag == 0) { 21 printf("Path %d: NA (Not a TS cycle)\n", index); 22 } 23 else if (v[0] != v[cnt - 1] || s.size() != n) { 24 //集合可以拿来判断是否遍历全 25 printf("Path %d: %d (Not a TS cycle)\n", index, sum); 26 } 27 else if (cnt != n + 1) { 28 printf("Path %d: %d (TS cycle)\n", index, sum); 29 if (sum < ans) { 30 ans = sum; 31 ansid = index; 32 } 33 } 34 else { 35 printf("Path %d: %d (TS simple cycle)\n", index, sum); 36 if (sum < ans) { 37 ans = sum; 38 ansid = index; 39 } 40 } 41 } 42 43 int main() { 44 scanf("%d%d", &n, &m); 45 for (int i = 0; i < m; i++) { 46 int t1, t2, t; 47 scanf("%d%d%d", &t1, &t2, &t); 48 e[t1][t2] = e[t2][t1] = t; 49 } 50 scanf("%d", &k); 51 for (int i = 1; i <= k; i++) { 52 check(i); 53 } 54 printf("Shortest Dist(%d) = %d\n", ansid, ans); 55 return 0; 56 }
这道题学到的是活用set的去重性,本质上不应该判断数字大小的。
A1149
1 #include <iostream> 2 #include <vector> 3 #include <map> 4 using namespace std; 5 int main() { 6 int n, k, t1, t2; 7 map<int, vector<int>> m; 8 scanf("%d%d", &n, &k); 9 for (int i = 0; i < n; i++) { 10 scanf("%d%d", &t1, &t2); 11 m[t1].push_back(t2); 12 m[t2].push_back(t1); 13 } 14 //到这里还是一样的 15 while (k--) 16 { 17 int cnt, flag = 0, a[100000] = { 0 }; 18 scanf("%d", &cnt); 19 vector<int> v(cnt); 20 for (int i = 0; i < cnt; i++) { 21 scanf("%d", &v[i]); 22 a[v[i]]=1; 23 } 24 for (int i = 0; i < v.size; i++) { 25 for (int j = 0; j < m[v[i]].size; j++) { 26 if (a[m[v[i]][j]] == 1) flag = 1; 27 } 28 29 } 30 printf("%s\n", flag ? "No" : "Yes"); 31 } 32 }
A1148
1 #include <cstdio> 2 #include <algorithm> 3 #include <vector> 4 #include <iostream> 5 using namespace std; 6 const int maxn = 110; 7 8 int main() { 9 int n; 10 cin >> n; 11 vector<int> ins(n + 1); 12 for (int i = 1; i <= n; i++) { 13 cin >> ins[i]; 14 } 15 for (int i = 1; i <= n; i++) { 16 for (int j = i+1; j <= n; j++) { 17 vector<int> a(n + 1, 1), liers; 18 a[i] = -1; 19 a[j] = -1; 20 for (int k = 1; k < n + 1; k++) { 21 if (ins[k] * a[abs(ins[k])] < 0) liers.push_back(k); 22 } 23 if (liers.size() == 2 && a[liers[0]] + a[liers[1]] == 0) { 24 cout << i << " " << j; 25 return 0; 26 } 27 } 28 } 29 cout << "No Solution"; 30 return 0; 31 }
这道题应该认真学习一下。
首先得改正下思想,能用容器尽可能用,然后其思路就是假设出那两个是狼的人。然后通过乘法判断这种假设的情况是否成立。
这里的乘法是让输入人的说法和本身假设的情况进行乘积,如果小于0说明这两种情况是相反的,然后就能判断这个人说谎。
然后如果有两个说谎的人,而且这两个人包含一个狼和一个人,那么就说明这种情况成立,函数就可以结束了(别break flag啥的了,浪费代码也容易错)
总结这个题的几个重点:
1.很容易想到每个人都有说的什么和本身是什么身份两种情况,所以存储这两个数组,如果这个人的说法和指定的人的身份不符,就是负的,那么就能判断说谎的人了。
2.跳出两层循环的方法某些情况下可以直接结束函数。
A1147
1 v#include <cstdio> 2 #include <iostream> 3 #include <vector> 4 using namespace std; 5 6 int n, m; 7 8 9 void postorder(vector<int> v,int root) { 10 if (root > m) return; 11 postorder(v, root * 2); 12 postorder(v, root * 2 + 1); 13 if (root == 1) printf("%d\n", v[root]); 14 else printf("%d ", v[root]); 15 } 16 17 int main() { 18 scanf("%d %d", &n, &m); 19 for (int k = 0; k < n; k++) { 20 vector<int> v(m+1); 21 int maxa = 1, mina = 1; 22 for (int i = 1; i <= m; i++) { 23 cin >> v[i]; 24 } 25 for (int i = 2; i <= m; i++) { 26 if (v[i] > v[i / 2]) maxa = 0; 27 if (v[i] < v[i / 2]) mina = 0; 28 } 29 if (maxa == 1) printf("Max Heap\n"); 30 else if (mina == 1) printf("Min Heap\n"); 31 else printf("Not Heap\n"); 32 postorder(v, 1); 33 34 v.clear(); 35 } 36 }
堆的话还是没事别递归了,根据索引就能判断前后关系,(递归会超时)。
A1146
首先百度一下怎么求拓扑序列
1.找到一个入度为0的点作为拓扑序列的第一个点
2.把该点和该店所有的边从图中删去
3.再在新的图中选择一个入度为0的点作为拓扑序列的第二个点
以此类推,如果在所有节点尚未删去时找不到入度为0的点则说明剩余节点存在环路,不存在拓扑序列。
那么如果给出了拓扑序列,当前结点入度不为0则表示不是拓扑序列,每次选中某个结点后要将它所指向的所有节点入度减-1。
1 #include <cstdio> 2 #include <vector> 3 using namespace std; 4 5 const int maxn = 1010; 6 vector<int> g[maxn]; 7 int in[maxn]; 8 vector<int> out; 9 int main() { 10 int n, m; 11 scanf("%d%d", &n, &m); 12 for (int i = 0; i < m; i++) { 13 int a, b; 14 scanf("%d%d", &a, &b); 15 g[a].push_back(b); 16 in[b]++; 17 } 18 int k; 19 scanf("%d", &k); 20 for (int i = 0; i < k; i++) { 21 bool judge = true; 22 vector<int> tin(in, in + n + 1); 23 for (int j = 0; j < n; j++) { 24 int tmp; 25 scanf("%d", &tmp); 26 for (int x = 0; x < g[tmp].size(); x++) { 27 tin[g[tmp][x]]--; 28 } 29 if (tin[tmp] != 0) judge = false; 30 } 31 if (!judge) out.push_back(i); 32 } 33 for (int i = 0; i < out.size(); i++) { 34 printf("%d%s", out[i], i == out.size() - 1 ? "" : " "); 35 } 36 }
注意创建C++数组的神奇方法。然后就是每次循环记得重置。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号