
目录:
一、介绍
(一)collection
1、基本操作
2、set集合
2.1 hashset
2.2 LinkedHashSet
2.3 TreeSet
2.4 EnumSet
3、List集合
3.1 ArrayList
3.2 LinkList
4.queue
三、Map
数组可以存储具有相同类型的元素集合,但是不支持动态内存分配,即长度是固定的,不能改变。固有统一的collection框架来支持这种动态分配的数据结构。
(一)collection是单列集合,是集合类 Set和list、queue的上级接口
① add(Object o):增加元素
② addAll(Collection c):...
③ clear():...
④ contains(Object o):是否包含指定元素
⑤ containsAll(Collection c):是否包含集合c中的所有元素
⑥ iterator():返回Iterator对象,用于遍历集合中的元素
⑦ remove(Object o):移除元素
⑧ removeAll(Collection c):相当于减集合c
⑨ retainAll(Collection c):相当于求与c的交集
⑩ size():返回元素个数
⑪ toArray():把集合转换为一个数组
contains(Object o)的案例:
import java.util.*; public class ArrayDequeDemo { public static void main(String[] args) { //创建容量为8的一个队列 Deque<Integer> deque = new ArrayDeque<Integer>(8); //添加元素到队列中 deque.add(20); deque.add(21); deque.add(10); deque.add(11); // 判断是否包含10,有则返回true boolean retval = deque.contains(10); if (retval == true) { System.out.println("element 10 is contained in the deque"); }else { System.out.println("element 10 is not contained in the deque"); } // 判断是否包含25,有则返回true boolean retval2 = deque.contains(25); if (retval2 == true) { System.out.println("element 25 is contained in the deque"); }else { System.out.println("element 25 is not contained in the deque"); } } } //输出结果: /** element 10 is contained in the deque element 25 is not contained in the deque */
iterator()的案例:
import java.util.*; public class ArrayDequeDemo { public static void main(String[] args) { List<Integer> list = new ArrayList<Integer>(); list.add(1); list.add(2); list.add(3); //用for循环遍历 System.out.println("增强for==================="); for (int i = 0; i < list.size(); i++) { System.out.println(list.get(i)); } //用增强for循环 System.out.println("增强for==================="); for (Integer i : list) { System.out.println(i); } //用iterator+while System.out.println("iterator+while==================="); Iterator<Integer> it = list.iterator(); while (it.hasNext()) {//读取下一个目标,判断它是否存在,返回true int i = (Integer) it.next();//读取输入的字符,以空格为分隔符,返回输入的字符 System.out.println(i); } //用iterator+for System.out.println("iterator+forr==================="); for (Iterator<Integer> iter = list.iterator(); iter.hasNext();) { int i = (Integer) iter.next(); System.out.println(i); } } }
2、set集合:无序不重复(Set集合是用equals来比较两个字符串的)
2.1 HashSet:按照哈希算法来存储集合中的元素,不安全,存取快
例子:
import java.util.HashSet; import java.util.Set; /** * == 比较的是两个变量的值(首地址)是否相等 * equals 比较的是两个独立对象的内容是否相等 */ public class TestArrayList { public static void main(String[] args) { HashSet<String> map = new HashSet<String>(); map.add("站站"); map.add("湛湛"); map.add(new String("你好")); map.add(new String("你好")); System.out.println(map); System.out.println("共创建" + map.size() + "个"); } }
输出结果:

2.2 LinkedHashSet集合:HashSet的一个子类,使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的
import java.util.LinkedHashSet; import java.util.Set; public class TestArrayList { public static void main(String[] args) { LinkedHashSet<String> map = new LinkedHashSet<String>(); map.add("站站"); map.add("湛湛"); map.add("昨天"); map.add("今天"); System.out.println("正常插入数据: "+map); map.remove("昨天"); System.out.println("移除昨天数据: "+map); map.add("昨天"); System.out.println("再添加昨天数据: "+map); } } /** 输出结果: 正常插入数据: [站站, 湛湛, 昨天, 今天] 移除昨天数据: [站站, 湛湛, 今天] 再添加昨天数据: [站站, 湛湛, 今天, 昨天] * /
常用的方法:
▶Comparator comparator():返回当前Set使用的Comparator,或者返回null,表示以自然方式排序
▶Object first():返回集合中的第一个元素
▶Object last():返回集合中的最后一个元素
▶Object lower(Object e):返回集合中小于指定元素的最大元素
▶Object higher(Object e):返回集合中大于指定元素的最小元素
▶SortedSet subSet(fromElement,toElement):返回此Set的子集合,范围从fromElement(包含)到toElement(不包含)。
▶SortedSet headSet(toElement):返回此Set的子集合,由小于toElement的元素组成
▶SortedSet tailSet(fromElement):返回此Set的子集合,由大于fromElement的元素组成
例子:
import java.util.TreeSet; import java.util.Set; public class TestArrayList { public static void main(String[] args) { TreeSet<String> map = new TreeSet<String>(); map.add("豆豆"); map.add("胖胖"); map.add("乐乐"); map.add("财发"); System.out.println("集合元素有: "+map); System.out.println("集合第一个元素有: "+map.first()); System.out.println("集合最后一个元素有: "+map.last()); System.out.println("返回比豆豆小的集合: "+map.headSet("豆豆")); System.out.println("返回大于等于豆豆的集合: "+map.tailSet("豆豆")); System.out.println("返回大于胖胖的元素的最小元素: "+map.higher("胖胖")); System.out.println("返回小于胖胖的元素的最小元素: "+map.lower("豆豆")); System.out.println("返回从胖胖(包含)到财发(不包含)的集合: "+map.subSet("胖胖","财发")); } } /** 输出结果: * 集合元素有: [乐乐, 胖胖, 豆豆, 财发] 集合第一个元素有: 乐乐 集合最后一个元素有: 财发 返回比豆豆小的集合: [乐乐, 胖胖] 返回大于等于豆豆的集合: [豆豆, 财发] 返回大于胖胖的元素的最小元素: 豆豆 返回小于胖胖的元素的最小元素: 胖胖 返回从胖胖(包含)到财发(不包含)的集合: [胖胖, 豆豆] * /
2.4 EnumSet:是一个专为枚举类设计的集合类,EnumSet中所有值都必须是指定枚举类型的枚举值。不允许加入null元素
import java.util.Collection; import java.util.EnumSet; import java.util.HashSet; enum Season { SPRING,SUNMMER,FALL,WINTER } public class TestEnumSet { public static void main(String[] args) { //allof(Class elementType):创建一个包含指定枚举类里所有枚举值的EnumSet es4对象。 EnumSet es1=EnumSet.allOf(Season.class); System.out.println("集合es1中的元素包括:"+es1); //noneOf(Class elementType):创建一个元素类型为指定枚举类型的空EnumSet EnumSet es2=EnumSet.noneOf(Season.class); System.out.println("集合es2中的元素包括:"+es2); es2.add(Season.SUNMMER); es2.add(Season.SPRING); System.out.println("集合es2中的元素包括:"+es2); //of(E first,E...rest):创建一个包含一个或多个枚举值的EnumSet,传入的多个枚举值必须属于同一个枚举类。 EnumSet es3=EnumSet.of(Season.SUNMMER, Season.WINTER, Season.FALL); System.out.println("集合es3中的元素包括:"+es3); //range(E from,E to):创建包含从from枚举值,到to枚举值范围内所有枚举值的EnumSet集合。 EnumSet es4=EnumSet.range(Season.SUNMMER, Season.WINTER); System.out.println("集合es4中的元素包括:"+es4); //complementOf(EnumSet s):创建一个其元素类型与指定EnumSet里的元素类型相同的 EnumSet es5=EnumSet.complementOf(es4); System.out.println("集合es5中的元素包括:"+es5); Collection c1=new HashSet(); System.out.println("集合c1中的元素包括:"+c1); //copyOf(Collection c):使用一个普通集合来创建EnumSet集合 c1.add(Season.SPRING); c1.add(Season.WINTER); EnumSet es6=EnumSet.copyOf(c1); System.out.println("集合c1中的元素包括:"+c1); System.out.println("集合es6中的元素包括:"+es6); } } /** 输出结果: * 集合es1中的元素包括:[SPRING, SUNMMER, FALL, WINTER] 集合es2中的元素包括:[] 集合es2中的元素包括:[SPRING, SUNMMER] 集合es3中的元素包括:[SUNMMER, FALL, WINTER] 集合es4中的元素包括:[SUNMMER, FALL, WINTER] 集合es5中的元素包括:[SPRING] 集合c1中的元素包括:[] 集合c1中的元素包括:[WINTER, SPRING] 集合es6中的元素包括:[SPRING, WINTER] * /
总结:HashSet的性能比TreeSet好(特别是最常用的添加,查询元素等操作).只有当需要一个保持排序的Set时,才应该使用TreeSet,否则使用HashSet
对于普通的插入删除操作,LinkedHashSet比HashSet慢,但遍历会更快。
Set的三个实现类HashSet,TreeSet和EnemSet都是线程不安全的,如果有多个线程访问一个Set集合,则必须手动保持同步
3.1 ArrayList:不安全,查询快,底层数组结构是数组结构
import java.util.Collection; import java.util.ArrayList; import java.util.List; import java.util.ListIterator; public class TestListIterator { public static void main(String[] args) { String[] person = {"南烊璟瑜", "付易"}; ArrayList al = new ArrayList(); for(var i=0; i<person.length; i++){ al.add(person[i]); } ListIterator listIterator = al.listIterator();//获取迭代器 while (listIterator.hasNext()) {//校验后面还有没有元素,前往后找 System.out.println(listIterator.next());//获取下一个元素 listIterator.add("-------分隔符-------"); } System.out.println("========反向迭代======="); while (listIterator.hasPrevious()) {//校验前一个还有没有元素,后往前找 System.out.println(listIterator.previous());//获取前一个元素 } } } /** 输出结果: 南烊璟瑜 付易 ========反向迭代======= -------分隔符------- 付易 -------分隔符------- 南烊璟瑜 */
迭代:迭代是重复反馈过程的活动,其目的通常是为了逼近所需目标或结果。每一次对过程的重复称为一次“迭代”,而每一次迭代得到的结果会作为下一次迭代的初始值。
使用 hasPrevious()方法和previous()这两种方法的使用前提是必须是在进行完 正向迭代 ,也就是 使用完 hasNext 和next 才能使用 hasPrevious 和 previous 。
3.2 LinkList:不安全,增删快,底层结构是链表结构
import java.util.*; public class TestLinkedList{ public static void main(String[] args){ LinkedList books = new LinkedList(); books.offer("Java");//将字符串元素加入队列的尾部 books.push("J2EE");//将一个字符串元素入栈 books.offerFirst("Android");//将字符串元素添加到队列的头部 for(int i = 0; i < books.size() ;i ++ ){ System.out.println(books.get(i)); } System.out.println("======================="); System.out.println(books.peekFirst());//访问、并不删除队列的第一个元素 System.out.println(books.peekLast());//访问、并不删除队列的最后一个元素 System.out.println(books.pop());//采用出栈的方式将第一个元素pop出队列 System.out.println(books);//下面输出将看到队列中第一个元素被删除 System.out.println(books.pollLast());//访问、并删除队列的最后一个元素 System.out.println(books);//下面输出将看到队列中只剩下中间一个元素:轻量级J2EE企业应用实战 } } /** 输出结果: Android J2EE Java Android Java Android [J2EE, Java] Java [J2EE] */
常见方法:
add(E e): 将指定的元素插入此队列(如果立即可行且不会违反容量限制),在成功时返回 true,如果当前没有可用的空间,则抛出IllegalStateException。
element(): 获取队列头部元素,但不删除该元素。
offer(E e): 将指定的元素插入此队列,当使用有容量限制的队列时,此方法通常要优于add(E)。
peek(): 获取但不移除此队列的头;如果此队列为空,则返回 null。
poll(): 获取并移除此队列的头,如果此队列为空,则返回 null。
remove(): 获取并移除此队列的头。
例子:
import java.util.*; public class TestPriorityQueue{ public static void main(String[] args){ PriorityQueue pq = new PriorityQueue(); //下面代码依次向pq中加入四个元素 pq.offer(6); pq.offer(-3); pq.offer(9); pq.offer(0); //输出pq队列,并不是按元素的加入顺序排列,而是按元素的大小顺序排列 System.out.println(pq); //访问队列第一个元素,其实就是队列中最小的元素:-3 System.out.println(pq.peek()); } } /** 输出结果: [-3, 0, 9, 6] -3 */
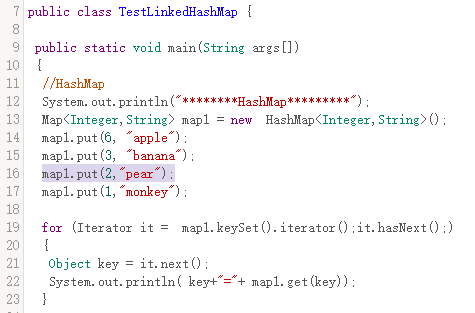
1、HashMap:线程不安全,速度慢;底层也是哈希表数据结构。是不同步的;允许null作为键,null作为值;默认初始容量 (16);替代了Hashtable。
2、Hashtable:线程安全,速度快;底层是哈希表数据结构;是同步的;不允许null作为键,null作为值。(被淘汰了)
3、LinkedHashMap:可以保证HashMap集合有序;存入的顺序和取出的顺序一致。
4、TreeMap:可以用来对Map集合中的键进行排序
HashMap(哈希表数据结构)和TreeMap(二叉树数据结构)的区别:HashMap适用于在Map中插入、删除和定位元素;TreeMap适用于按自然顺序或自定义顺序遍历键(key)。HashMap通常比TreeMap快一点(树和哈希表的数据结构使然),建议多使用HashMap,在需要排序的Map时候才用TreeMap。


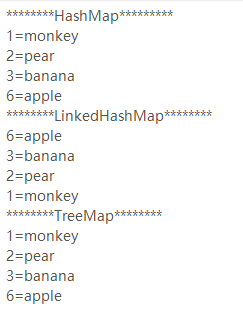
输出结果:
collection是集合类的上级接口,继承与他的接口主要有set和list;
collections是针对集合类的一个帮助类。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号