深度推荐系统-学习笔记【传统模型+深度学习典型模型】
传统推荐模型
衡量相关性:
-
向量相关性: 归一化 cos 相似度
-
person 相关性系数:
- 衡量的是线性相关性,尽管r=0,只能证明没有线性相关性,其他的并不知道,如果是独立的话,那么就无任何关系

-
引入物品平均分来降低物品评分bias对结果的影响 P17
CF (协同过滤)
UserCF
公式: \(R_{u,p}=\frac{\sum_{s\in U}{(W_{u,s}\times R_{s,p})}}{\sum_{s \in U} {W_{u,s}}}\) , \(W^{U*U}\) 是 user 相似度矩阵
- 假设:相同的用户具有相同的兴趣爱好
- 缺点:技术角度
- 互联网用户数 远大于 物品数量,为了维护相似度矩阵需要很大的存储开销,\(O(n^2) 增加\)
- 交互稀疏,对于低频交易场景,正反馈难以获得的场景(贵重物品,酒店预定等)或者对于很大的商品集合,找到具有相同购买物品的用户不容易
ItemCF
公式:\(R_{u,p}=\sum_{h\in H}({W_{h,p}\times R_{u,h})}\), 其中 \(H\) 是用户已经购买的list, \(W^{N*N}\) 物品相似度矩阵
- 缺点:
-
推荐结果的头部效应明显(热门商品和其他的物品都有很高的相似度),处理稀疏向量的能力弱。 共现矩阵是 one-hot 形式
A 1 0 0
B 0 1 1
C 1 1 1
C是热门商品,导致和A、B的相似性很高,而 AB 完全不相似
-
UserCF 和 ItemCF 的应用场景
- UserCF 主要是对用户的相似性进行建模,有更强的社交性,发现热点,跟踪热点。发现相似人的兴趣,达到扩展自身兴趣的目的。例如:新闻推荐,相比于发现用户对不同新闻的兴趣偏好,新闻的及时性和热点性是更重要的属性。
- ItemCF 更适合于兴趣变化较为稳定的场景。例如:购物,电影推荐。这种应用用户在一定的时间段都是希望找到更加相同的物品。
MF (矩阵分解)
为了解决 CF 这种 使用 one-hot 向量造成的 头部效应,稀疏向量处理能力弱,泛化能力弱
提出使用 稠密向量 来表征 User 和 Item
公式: \(M\times N=(M\times K )* (K\times N), K\) hidden dim
- K 越大,包含的信息越多,隐向量表示能力越强,但是泛化性越差,计算复杂度高
- 需要找到 推荐效果 和 工程的平衡点
矩阵分解的方法
-
特征值分解,只能用于方阵 \(A=VDV^{-1}\)
-
奇异值分解 SVD \(M=U\Sigma V^T, U^{m*m}, V^{n*n}, \Sigma^{m*n}\)对角阵,从对角阵选取主元作为k个隐含特征,就变成了 mk, kn 了
- 适用于稠密矩阵
- 推荐场景一般都是稀疏的,那么缺失值只能补0
- 传统的SVD复杂度 \(O(mn^2)\),复杂度过高不合适
-
梯度下降
- 最小化 \(min \sum{(r_{u,i}-p_u^Tq_i)}^2+\lambda (||q_i||^2+||p_u||^2)\) MSE+L2正则
-
消除用户和物品的打分偏差
用户对物品的打分可能有些固有bias,比如喜欢打高分
物品本身固有的bias,例如品质高的就容易分高
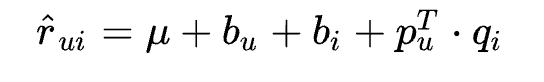
这个预测公式加入了3项偏置 μ,bu,bi , 作用如下:
- μ : 训练集中所有记录的评分的全局平均数。 在不同网站中, 因为网站定位和销售物品不同, 网站的整体评分分布也会显示差异。 比如有的网站中用户就喜欢打高分, 有的网站中用户就喜欢打低分。 而全局平均数可以表示网站本身对用户评分的影响。
- bu : 用户偏差系数, 可以使用用户 u 给出的所有评分的均值, 也可以当做训练参数。 这一项表示了用户的评分习惯中和物品没有关系的那种因素。 比如有些用户比较苛刻, 对什么东西要求很高, 那么他评分就会偏低, 而有些用户比较宽容, 对什么东西都觉得不错, 那么评分就偏高
- bi : 物品偏差系数, 可以使用物品 i 收到的所有评分的均值, 也可以当做训练参数。 这一项表示了物品接受的评分中和用户没有关系的因素。 比如有些物品本身质量就很高, 因此获得的评分相对比较高, 有的物品本身质量很差, 因此获得的评分相对较低。
优缺点:
-
泛化能力强:
基于隐向量的 item, user 表示都是基于全局的表示,有更强的泛化能力,一定程度解决了数据稀疏问题
UserCF: 评价人的相似是通过有相同的物品列表,如果没有就没法计算
ItemCF: 评价物品的相似是通过一个人买过不同的物品,那么这些物品之前有相似关系,如果两个商品没有被一个人购买,那么就无法评价
-
空间复杂度低,(m+n)k 级别,不是 mm, n*n 了
-
更好的扩展性和灵活性,学习到的都是 Embedding, 方便特征组合
逻辑回归 (LR)
一般的线性回归模型:
\(w_0\)可以看成 b,方便编程可以把 b 放入到 \(W\)中一起优化,x只要对应位置置1,就是相当于 \(xw+b\)了

重点:对多种特征建模为一个特征向量
sigmoid: \(f(x)=\frac{e^x}{1+e^x}=\frac{1}{1+e^{-x}}\)
logist regression: \(f(x)=\frac{1}{1+e^{-(x^Tw+b)}}\)
优点:
- 数学含义,逻辑回归是广义线性模型在贝努利分布假设下的表达,贝努力分布就是掷硬币 0,1
- 可解释性强:各个特征的加权和,符合直觉。此外sigmoid输出正好是[0,1]符合 CTR 物理意义
- 工程实现方便
- 易于并行化,梯度并行
- 模型简单,开销小
缺点:
- 模型简单,表达能力不强(就是个加权就和),无法进行特征交叉,筛选等操作,不可避免损失信息
- 仅使用单一特征,而不是用交叉特征:辛普森悖论(在分组时,占优的因素,在总评里面效果不好,甚至相反:电影推荐例子,分组实验(性别+视频id),不分组(视频id))P34
- 发展出 因子分解机 等复杂的高维模型,但是可解释性逐渐下降了
POLY2模型-特征交叉的开始
对所有特征进行两两交叉,并且设置权重(暴力组合)
特征交叉的方法:(人为定义)
- 内积
- 哈达玛积
- 笛卡尔积

缺点:
- 需要计算大量的权重分数 \(O(n^2)\)
- 对于很多场景使用 one-hot 方式进行编码,所以对于one-hot 向量进行特征交叉,依然是十分稀疏的,训练难以收敛
FM - 隐向量特征交叉
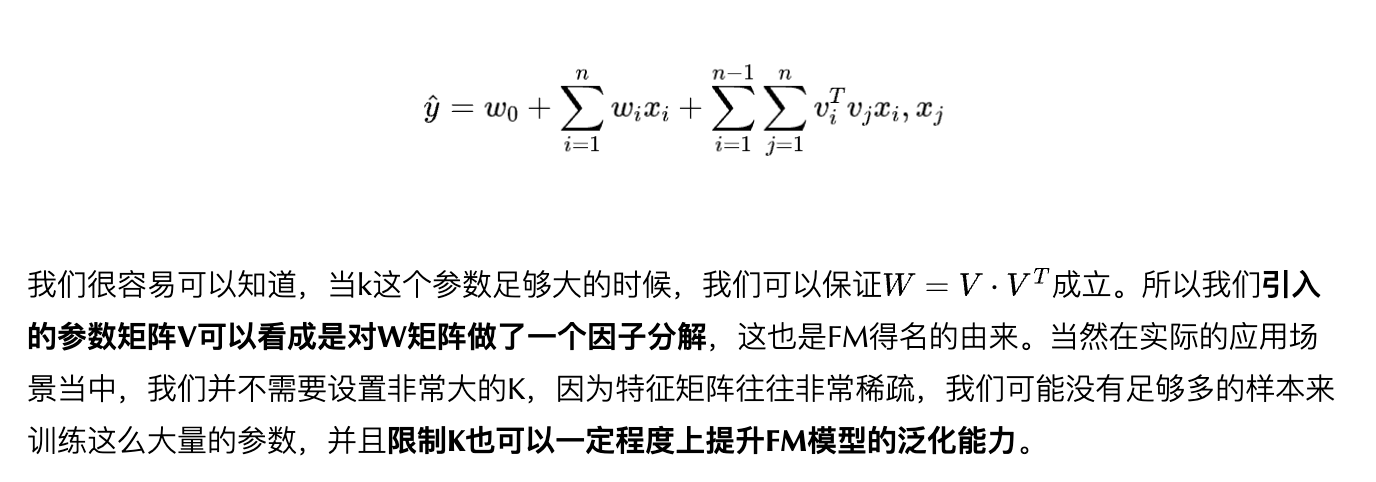
这个 V 就相当于是对 原来 POLY 做了一个特征分解,k类似的理解成 主元 个数,每个 向量 \(v_i\) 就是一个特征向量
GNN里面构建边的特征也是 \(O(N^2)\), NGNN就是用这个降低了复杂度,给每个node的出入学习两个向量,然后就可以构造边特征了
优点:
-
对于稀疏的数据,也会学习一个 embedding,其实可以看做为每个特征id学习了一个embedding,方便得到一个分数,原来的方式对于空数据完全无法计算交叉特征分数
在高度稀疏的条件下能够更好地挖掘数据特征间的相关性,尤其是对于在训练样本中没出现的交叉数据
-
FM在计算目标函数和在随机梯度下降做优化学习时都可以在线性时间内完成。
缺点:
- 特征交互只有2阶,更多阶不好做
- FNN 提高特征阶数
- 对于原始依然是稀疏操作,但也有好处就是记忆性好,之后有很多改进,在权重得分以及特征表达
- NFM 特征表示方面(不在是01,用Embedding)以及特征交叉方面改进(一个固定长度向量表示,不是一个数)
- AFM 在权重分方面
复杂度优化: \(O(k*N^2)\) → \(O(kN)\)
转化公式如下所示,其实就是利用了2xy = (x+y)^2 – x^2 – y^2的思路。
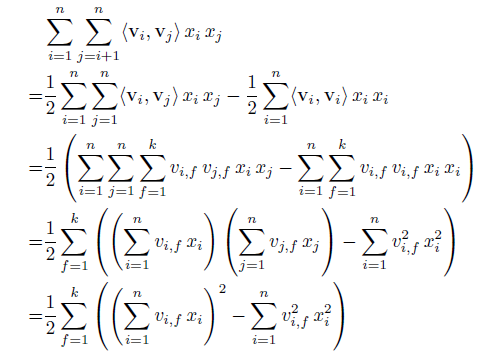
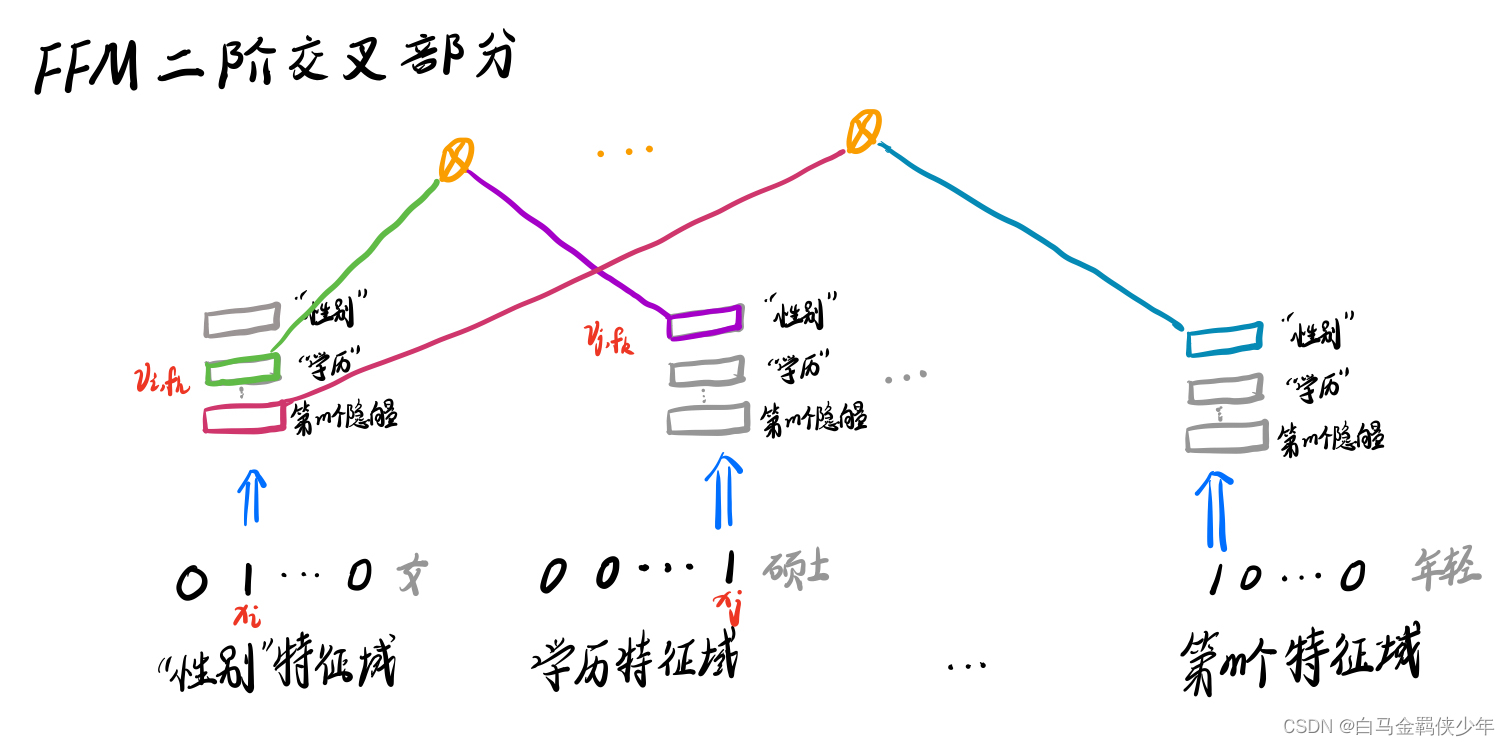
FFM 模型
核心:引入特征域概念,对于每个特征在不同域都有一个表示,可以类比于多视角,即:进行特征组合的时候,根据对方的组合域要挑选自身在对方域表达较好的向量。(有点千人千面的感觉)
E.G. 一个人可以有一个特征,那么也可以把人这个特征拆分在不同的域中,例如:身高,长相,腿长等等。假如要组合(人,美妆博主),那么使用(长相特征+美妆特征)就要好于(人+美妆特征),或者组合(人,游泳成绩),那么使用(腿长/身高,游泳成绩)就好于(人+游泳成绩)。就是相当于把一个embedding 细化了,更获得获得交互。
使用方法:在做特征交叉时,每个特征选与对方域对应的隐向量做内积运算,得到交叉特征的权重。
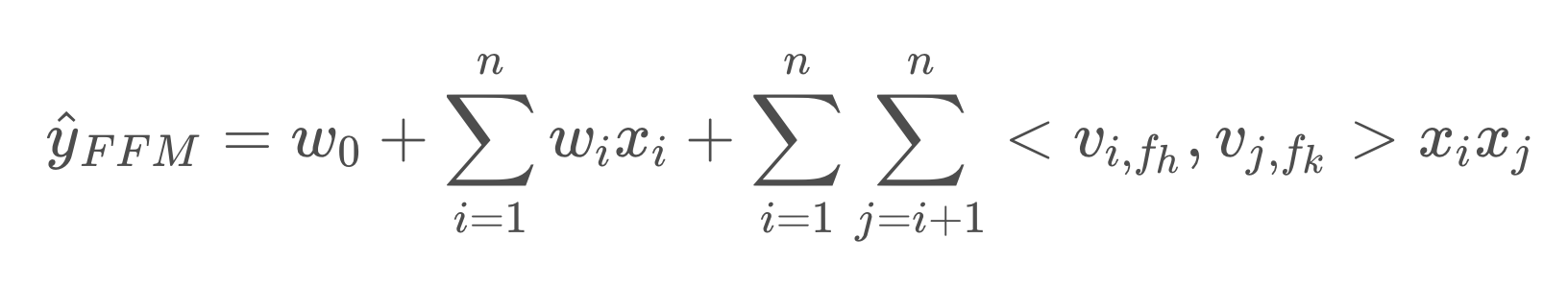

FFM 的改进 WWW21: https://mp.weixin.qq.com/s/6x2VKkAlRBEm5xFVCYInEg
缺点:
- 时间复杂度较高,\(O(k*n^2)\)
- FM,FMM仅仅是二阶特征交互,如果强行提高的话,那么复杂度指数上升以及组合爆炸,太过暴力,缺少高阶特征交互,(GBDT)
常见面试题:
-
FFM相比FM的优缺点
- FFM 引入特征域,模型交互效果更好,效果更好
- 参数量大,容易过拟合,需要 early stopping
- FM: 参数量 \(O(nk)\) 计算量 \(O(nk)\)
- FMM: 参数量 \(O(k*n*f)\) 计算量 \(O(k*n^2)\)
- 在实际工程应用中,需要在模型效果和工程投入之间进行权衡
-
FFM能解决少量记录数据拟合大量参数的问题吗?即稀疏性?
可以的,FM 就可以解决,隐向量是通过全局学习的,不是单个样本的共现性
-
FFM有m个特征域,那每个位置只需要m-1个隐向量吗
是的,自己和自己field交叉无意义,因为one-hot编码,另外一个交叉一定是0,只需要学习 m-1 个其他field就可以。如果是2field,那么就退化成了 FM
-
FFM和FM适用的场景?
-
特征不止存在线性关系,需要交叉:FM和FFM都是在线性拟合的基础上考虑了特征的交叉项,但有些场景特征x和目标y之间只是单纯无邪的线性拟合关系,此时FM和FFM的效果和线性模型差不多。
-
大型稀疏数据集效果好。因为都是利用了共享参数(Embedding)的方法解决了用少量记录数据拟合大量参数的问题。
-
在类别特征比较多的时候比较适合用FM、FFM,而数值特征(如[0.31,0.74,0.25…1.63])占多的情况下,FM、FFM并不比SVM等经典算法好处多少。(怪不得打微信大数据竞赛时用DeepFM模型时,要对一些统计特征进行数据分箱操作)
-
逻辑回归一般要数据分箱:
1.把离散特征的类别进行分箱二次分类(比如,中国的所有城市,通过分箱划分为县区市地区等),可以让模型快读迭代
2.对于连续特征和异常值,有很强的鲁棒性,比如年龄>30是1,否则是0,如果没有离散化,一个异常年龄数据为"年龄300岁"会给模型造成很大的困扰,分箱会降低数据的噪声影响。分箱后的数据有很强的稳定性,比如年龄20-30作为一个箱子。不会因为30岁变成31岁,模型变化就很大。
3.逻辑回归属于广义线性模型,表达能力有限,将连续数据分箱后,进行哑变量或独热编码的处理,每个特征中的每一类别就有了权重,这样相当于为模型引入的非线性,能够提升模型的拟合能力。
4.将所有变量变换到相似的尺度上,稀疏向量内积运算快
注:连续值的分箱不一定是要分成离散数据,而是一种数据平滑的处理,可以几个数据分在一起,然后取其平均值或中位数,降低数据的噪声
-
-
特征交互排序模型:
GBDT+LR 特征工程模块化的开端
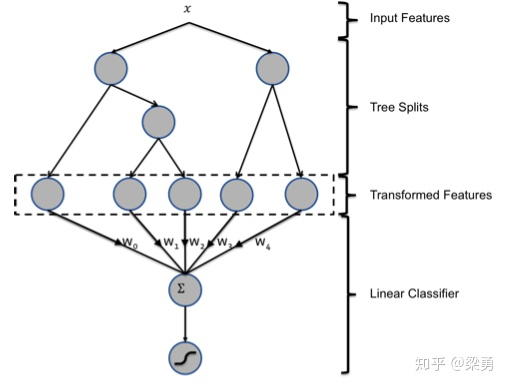
核心: 使用 GBDT 产生新的组合离散特征,然后使用 LR 进行 CRT, pipline形式(不存在梯度跨模块传递)
【待补充学习】:
决策树,随机森林,GBDT,xgBoost,lightGBM
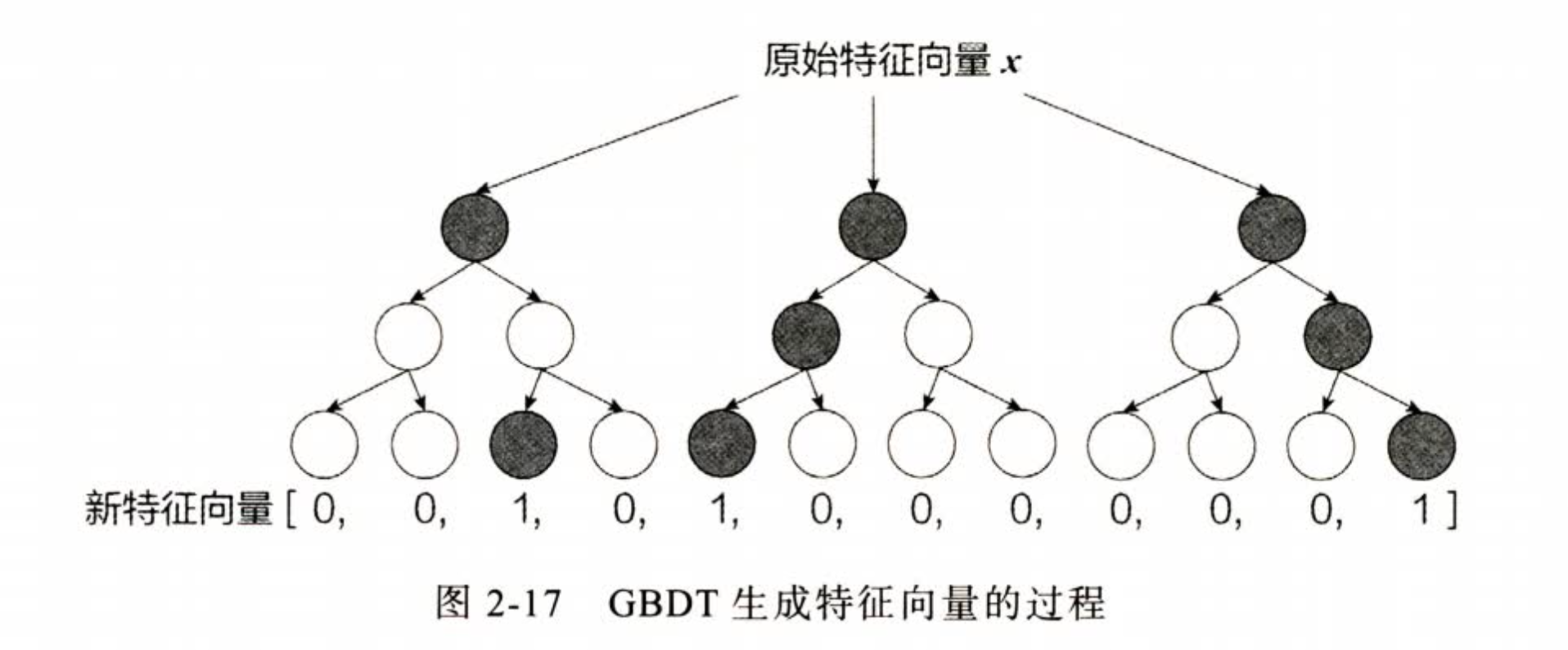
总结:
- GBDT 的特征交叉能力提高,交叉的阶数是树深度-1,上图就是二阶特征交叉
- GBDT 的特征交叉能力高,是FM系列不具备的,但是并不代表 交叉能力 强,推荐效果就好,GBDT这种交叉方式丢失了大量特征的数值信息。
- 最重要的贡献是:推动了推荐领域特征工程模块化,自动化
LS-PLM - 大规模分段线性模型(Alibaba)
核心: 使用分治思想,数据分片(聚类),对于不同的聚类样本应用不同的 逻辑回归。
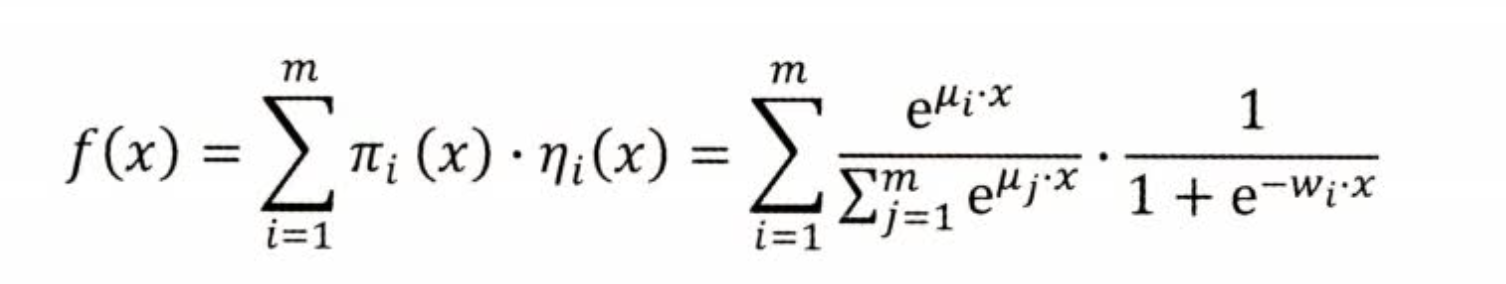
\(\pi\) 是个softmax 函数,也就是聚类结果是个软分类,然后乘以对应的 LR 分数。还有点像MoE哈哈哈
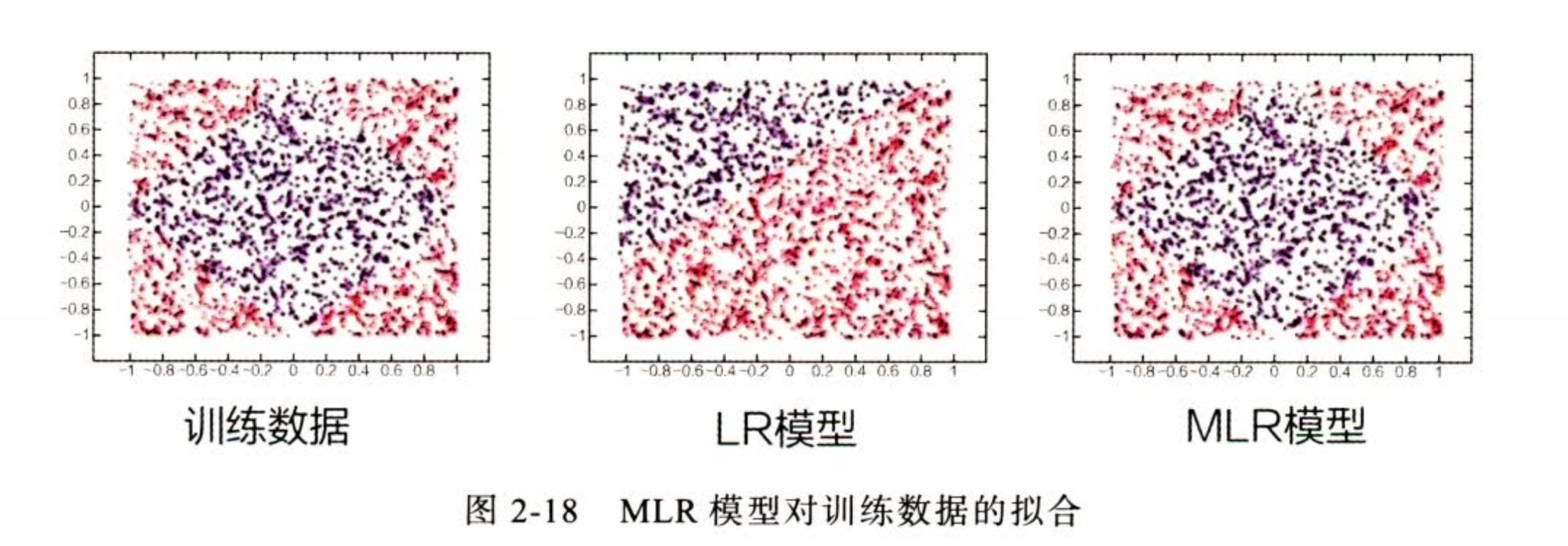
划分数据(结构化先验):
不同的人群具有聚类特性,同一类人群具有类似的广告点击偏好
M 是超参,论文给出 \(M=12\)
优点:
-
End-to-End 的非线性学习能力,可以先通过聚类挖掘数据中的隐藏模式,可以统一使用一个大的模型,建模不同的业务场景
-
此外,模型引入 L1 正则化,使得模型权重稀疏,方便部署推理(只用非零值就可以计算了)
l1为甚可以稀疏: https://www.zhihu.com/question/37096933
稀疏的意思就是:当权重 x=0 的时候,loss 可以取得最小值。为了让0的时候取到极值,那么至少导数为0,或者导数异号,我们需要加入一个函数调整其原点处导数为0,而 \(|x|\)在原点处的导数不存在,有正负两个方向,只要 \(\lambda |x|\) 中的 \(\lambda\) 调整的好(大于原函数在原点的导数值的绝对值,就可以做到异号),那么就很容易让原点处的导数变为0。相反:l2 正则 ,\(|x^2|\) 在原点的导数已经是0,如何调整也不行了,除非原函数就是0,这样就矛盾了。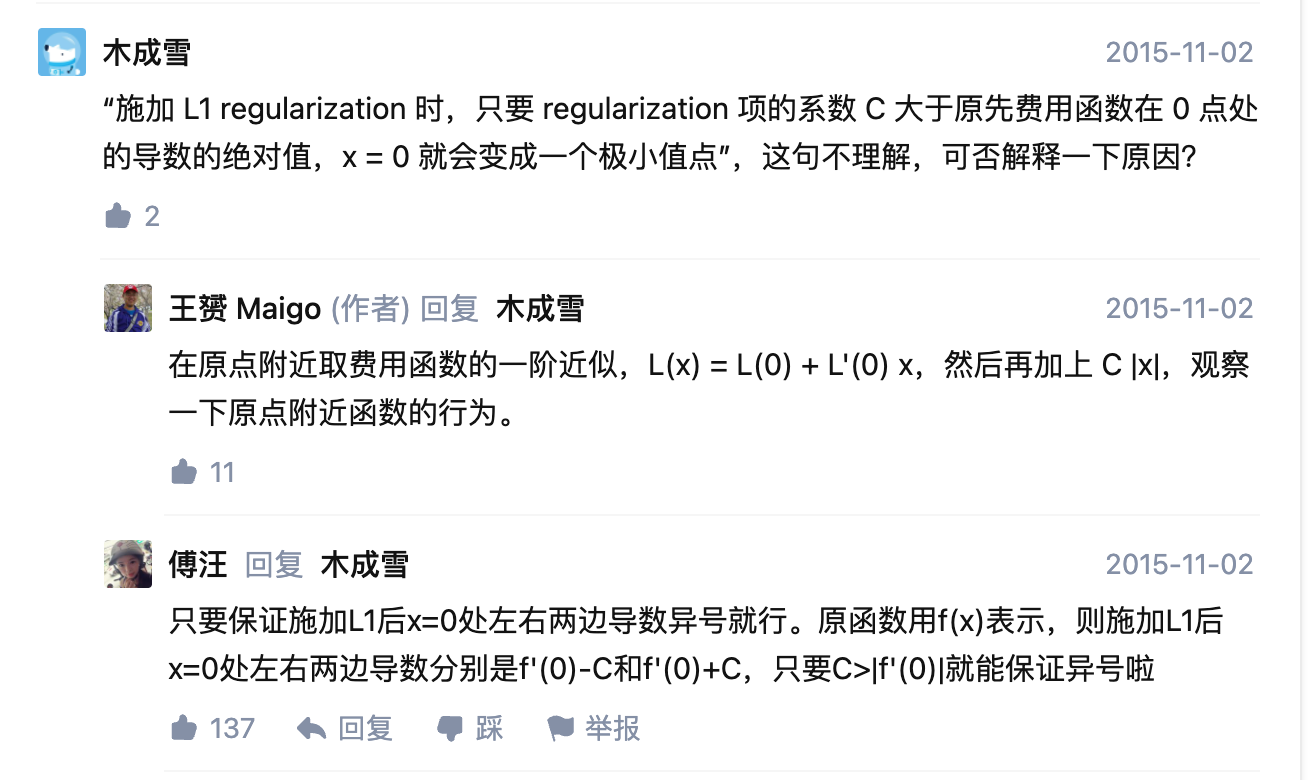
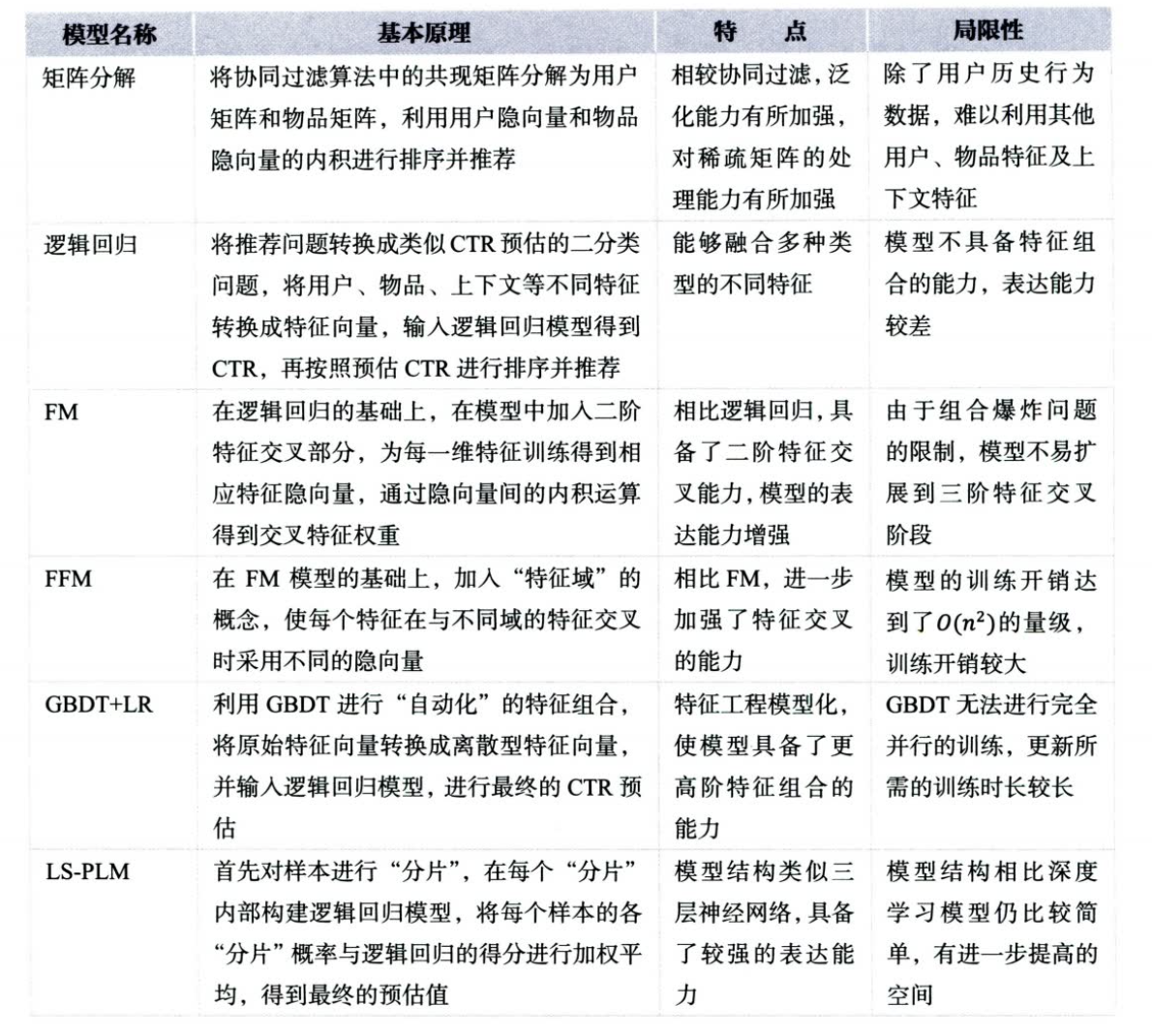
传统模型汇总
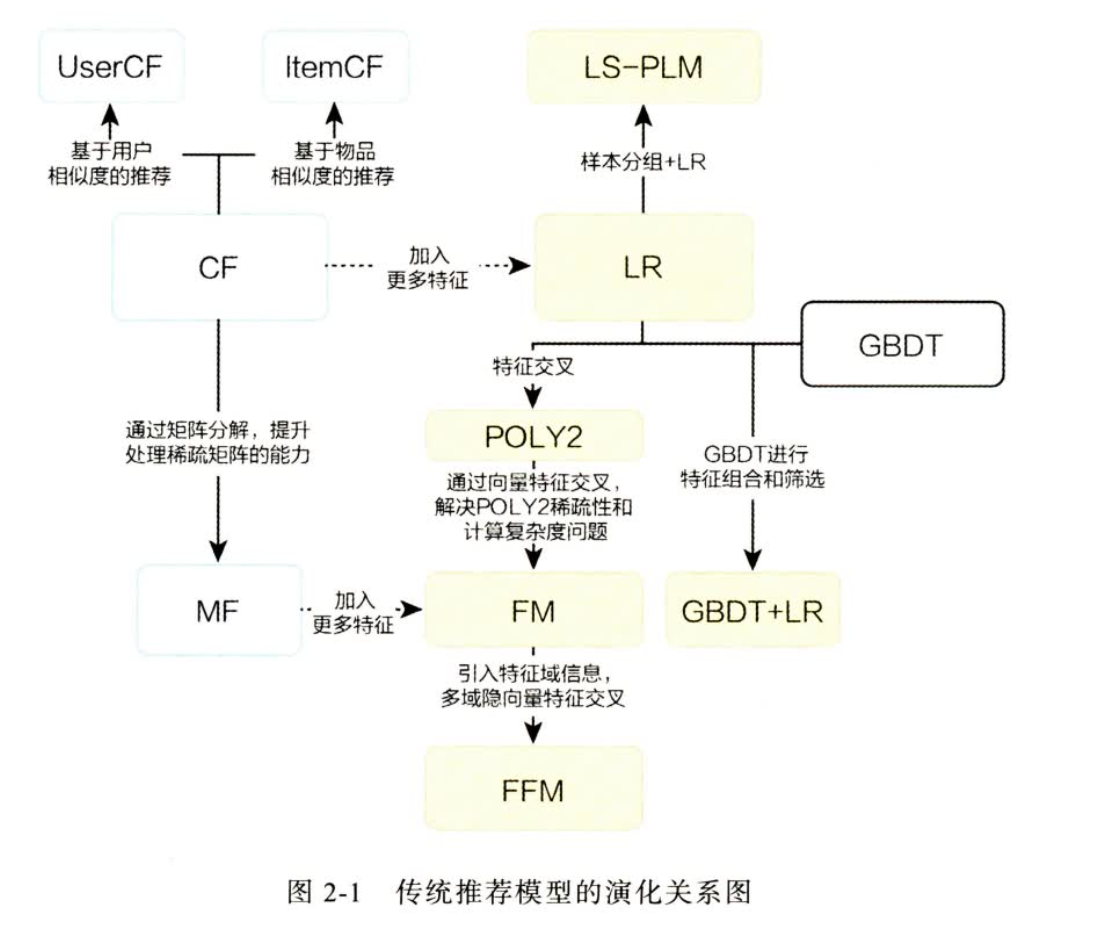
深度学习推荐系统
AutoRec - 单隐层神经网络推荐模型(缺失值如何预测呢?)
属于第一个引入神经网络,来改进 CF 模型。
idea: 直接通过模型建模,共线矩阵(包括对缺失值的预测), 推荐的最终目的就是求解 \(R_{u,p}\) 的得分是多少
AutoRec有两种:
-
User AutoEncoder
对于user向量,直接输入 AutoEncoder ,然后还原user,每个用户处理一遍就得到了所有物品的打分
-
Item AutoEncoder
对于 item 向量,直接输入 AutoEncoder ,然后还原 item, 每个物品处理一遍就得到了所有用户与这个item的得分
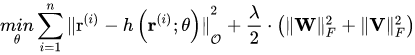
优点:
- 相比User CF, Item CF 还是具有优势,泛化能力有提高
- 一次infer就能得到一个物品对所有用户的score,或者一个用户对所有item的score
缺点:
- User AutoRec ,可能十分稀疏,模型难以收敛,影响性能
Deep Crossing
idea: 提出一个深度学习可以结合的推荐系统架构,解决了一下问题:
- 如何稀疏特征映射到稠密特征
- 如何进行特征交互
- 如何在输出层与优化目标达成一致
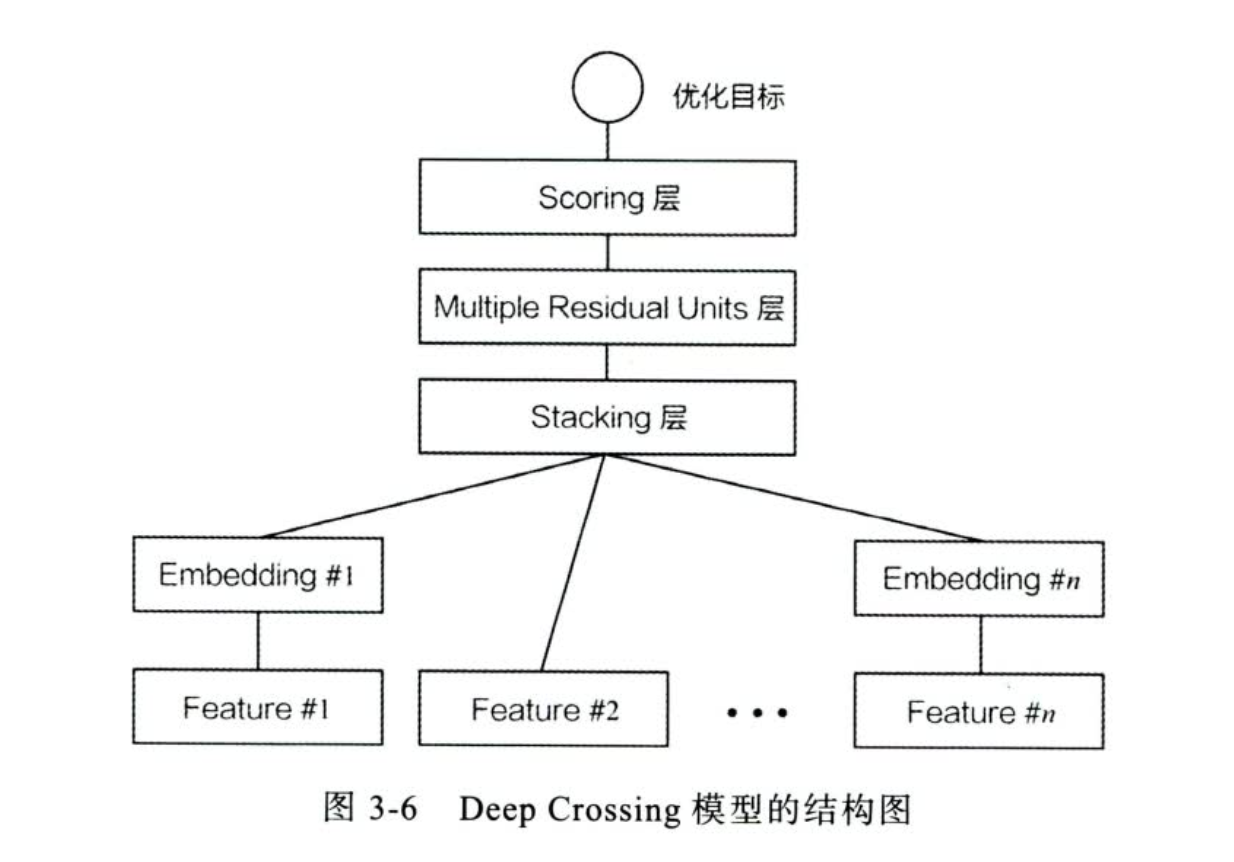
Embedding 层:映射稀疏特征到稠密特征,数值型一般不映射(Feature#2),FC层来实现
Stacking 层:特征拼接层
Multiple Residula Units层:多个mlp进行特征交叉
Scoreing 层:LR 优化目标
优点:
- 没有任何人工设计的特征交互模块
- 稀疏向量变成稠密向量,引入embedding想法,加快模型收敛
缺点:
- 对特征交互较为初级,没有更加复杂的交互,或者引入多种交互操作
- EMbedding 设计较为简单,后续发展出来各种 Embedding 方法
NeuralCF - CF与深度学习的结合
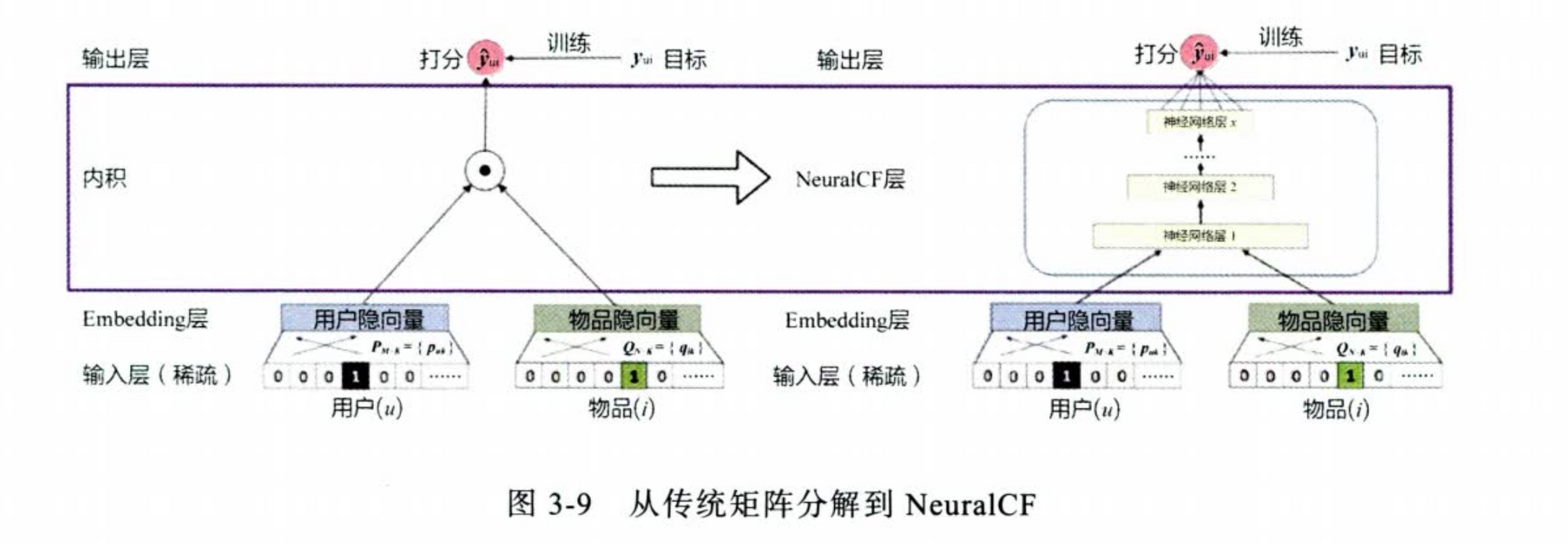
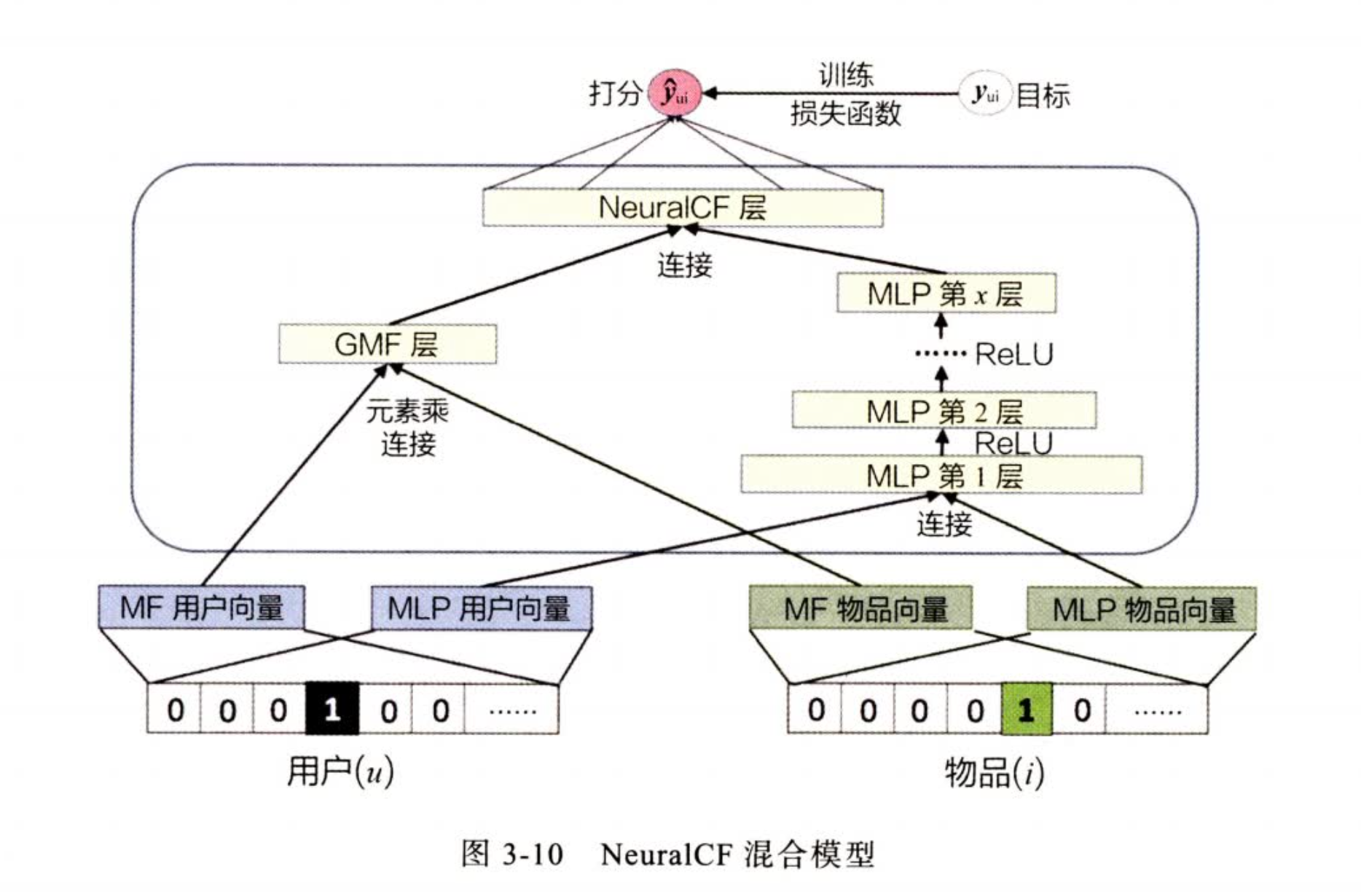
优点:
- 把点积操作变成一个 深度网络 来拟合,不过有过拟合的风险,目前好像还是点乘用的多
- 使用不同的 特征交叉操作,然后进行拼接增加特征交互能力
缺点:
- 基于协同过滤,因此只有user item 特征,缺少其他特征的引入
- 互操作没有进一步说明,只用了元素乘法
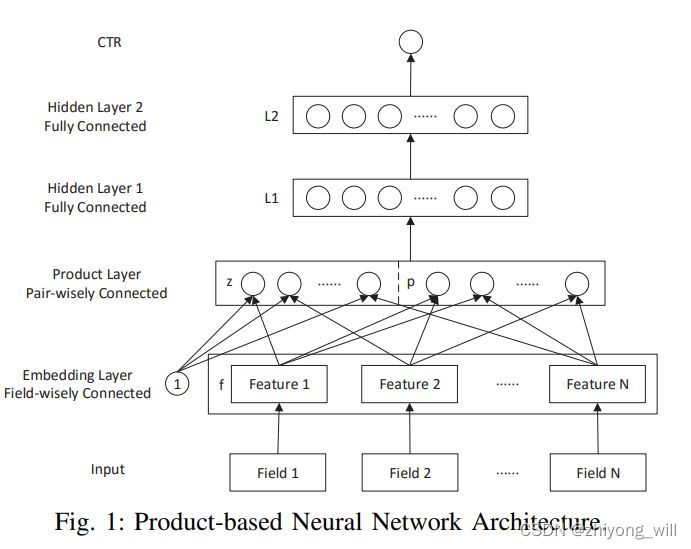
PNN - 加强特征交互
idea:
PNN网络结构在传统的DNN中增加了Product层,从而实现了特征的交叉,在具体的实现过程中,提出了两种Product的计算,分别为Inner Product和Outer Product。在具体的数据中,两种Product的表现并不一致,需要根据具体的数据选择合适的Product计算方法,相比较传统的DNN,从实验结果来看,效果上PNN得到了较大提升。
送入交互层之前,对 \(I_z,I_p\)都进行了\(W\)变换,成了统一维度
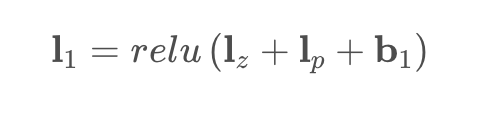
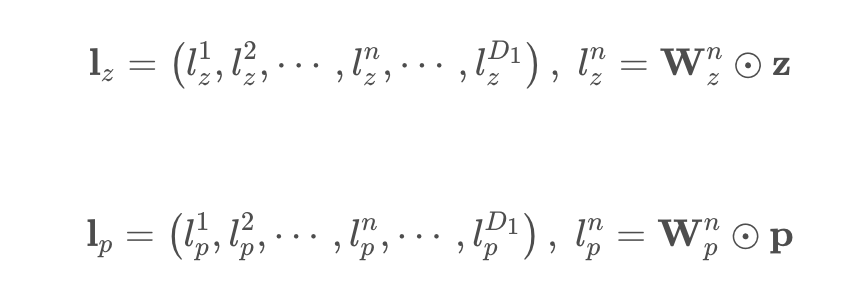
工程上的一个问题:
由于外积操作,直接得到一个矩阵,复杂度太高,优化过程中使用了类似 pooling 的叠加想法,这会引入特征的不一致性,不同的特征跨域pooling会有一些问题
https://blog.csdn.net/google19890102/article/details/122251702
优点:
- PNN 指出, 特征Embedding 之间的特征交叉是多样的,不应该全部直接扔到 MLP 里面,全部让机器去学习
缺点:
- 对于 PNN 的外积操作,为了简化运算复杂度,对所有特征不加区分的进行了交叉,这会损失一些有用的信息,之后的模型在更有效的特征交叉方面进行探索
Wide&Deep - 记忆能力和泛化能力的综合
大型广义线性模型,组合了 DNN 特征 和 直接的系数特征
Wide部分:更像是直接向模型注入,知识,规则(记忆能力),不希望模型去学习甚至没学到还破坏这种先验知识。即“记忆” 历史数据中曾共同出现过的特征对
Deep部分:提取数据之间的隐含相关性,交互等,增加模型的泛化能力
优点:
- 抓住业务特点,融合了传统模型的记忆能力和深度模型的泛化能力!!
- 结构并不复杂,易于实现
- 但提供了一种网络结构的设计思路,采用两部分甚至多部分组合的形式,利用不同网络结构挖掘出不同的信息再进行组合,可以充分利用不同网络结构的特点,一定程度上为网络结构在特征交叉方向上的优化奠定了结构基础。
缺点:
- wide 部分特征过于稀疏,且是手动,需要改进
- deep 改进特征交互不单单 concat mlp
记忆性:原始输入对结果会有一个非常直接的改变关系(强控制),LR 就是这样,因为模型简单,和输入耦合性强,但同时泛化性能不足
工程优化点:
- 需要十分仔细做 wide 部分的特征选择(特征工程部分)
- 对于 wide 部分 和 deep 不分可以选择不同的优化器进行优化,wide部分很稀疏使用 LR 专用优化器(Ftrl+L1正则), deep 不分就AdaGrad,Adam,SGD 这些就好
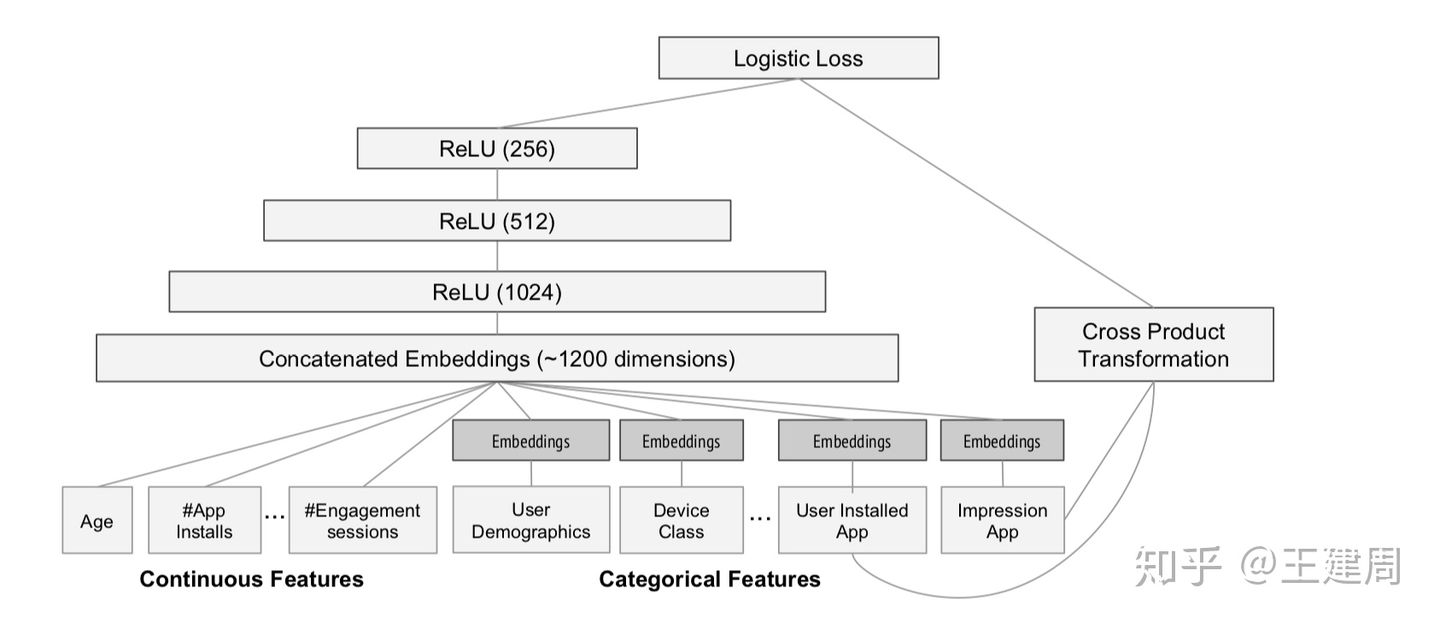
Cross Product Transformation: 交叉积变换,笛卡尔积,一个位置就代表一个AND条件,不是用multi-hot 模拟。 只有一个位置表示AND才可以达到非线性组合+原始线性组合,送入LR提升特征交叉的效果

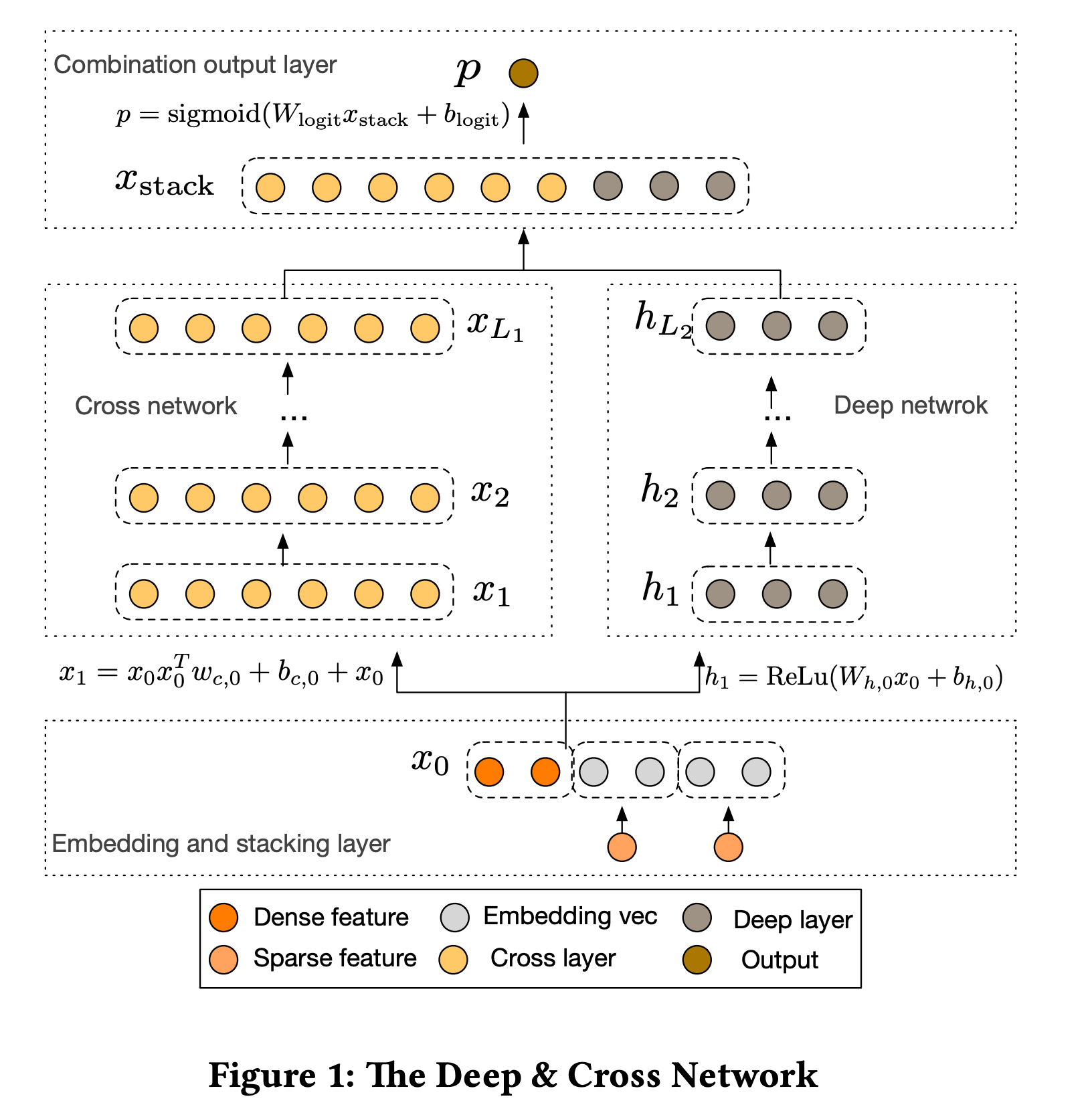
Deep&Cross (DCN) - Wide&Deep的进化
idea:改进 wide 部分,将Wide部分替换为由特殊网络结构实现的Cross,自动构造有限高阶的交叉特征,并学习对应权重,告别了繁琐的人工叉乘
但是并不是用系数特征来做自动高阶特征交叉,而是转换为稠密向量,其实已经损失了wide的基本思想,cross部分只是没有 激活 函数的线性堆叠, 文中说为了降低复杂度
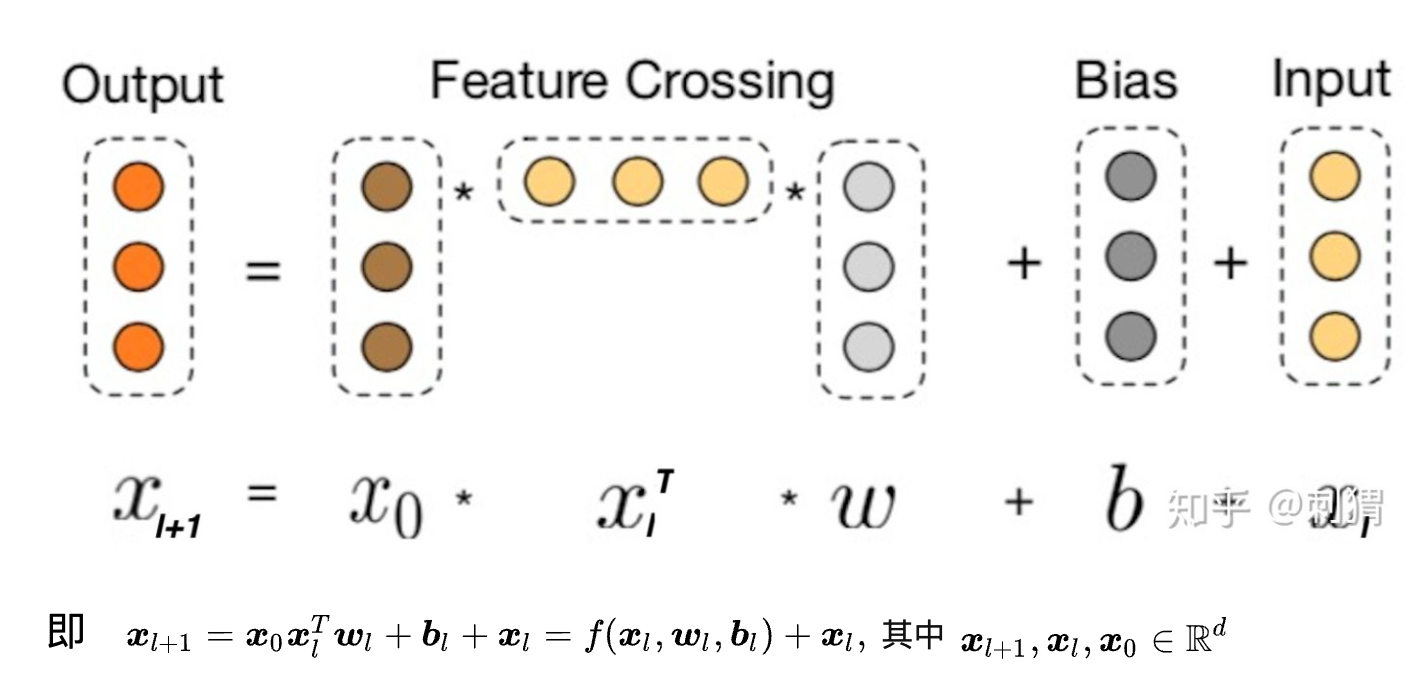
核心: wide部分公式,每次运算一次就会得到更高阶
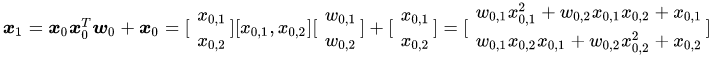

- \(+x_i\) ,每次求和都可以扩展一个维度
- \(X_0\) 每次引入一个阶数
- 拟合的残差,移项一下
FNN- 用FM的隐向量完成Embedding层的初始化
idea: Embedding + MLP
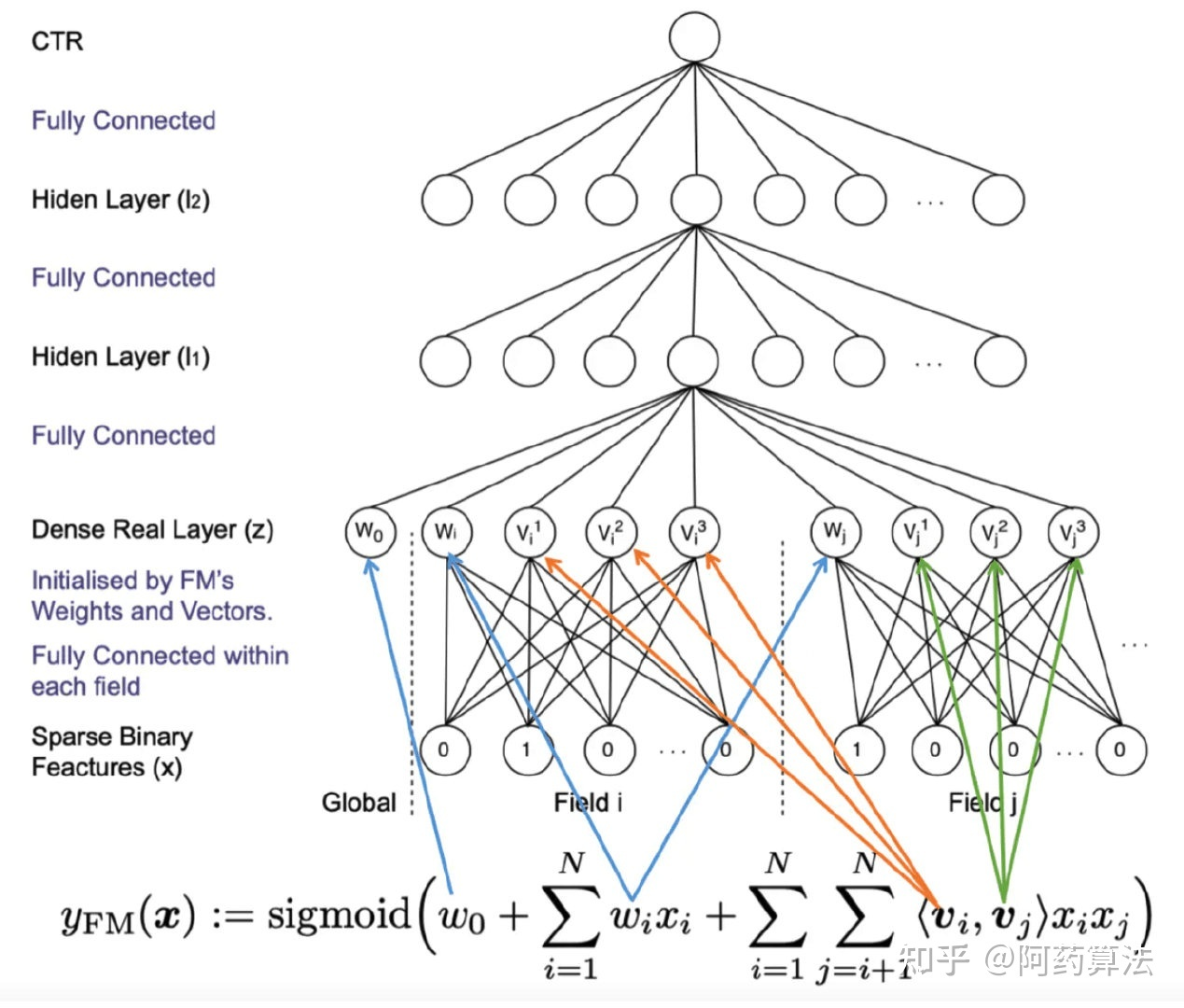
这里的field 只是说,在这个 Field 内只有一个1,方便描述的。和FFM的Field 不是一个概念。
优点:
- 引入DNN对特征进行更高阶组合,减少特征工程,能在一定程度上增强FM的学习能力,这种尝试为后续深度推荐模型的发展提供了新的思路。
- 使用 FM 特征初始化,加快网络学习,不然Embedding 参数量大,不好学习(过于稀疏,是全连接层)
缺点:
- 两阶段训练模式,在应用过程中不方便,且模型能力受限于FM表征能力的上限。
- FNN专注于高阶组合特征,但是却没有对低阶特征进行建模。
DeepFM - FM 代替 wide 部分,并且共享embedding
idea: deep&wide 模型的 wide 部分手工设计2阶交叉,不够灵活
- FM可以自动进行二阶交叉(保留了稀疏特征,记忆性好),这里仅仅是共享了embedding,这样就可以end2end
- deep&cross 是改进高阶交叉,(用了稠密特征,记忆性一般吧)
模型最后的得分就是,两部分相加 \(sigmoid(Score_{wide}+Score_{deep})\)
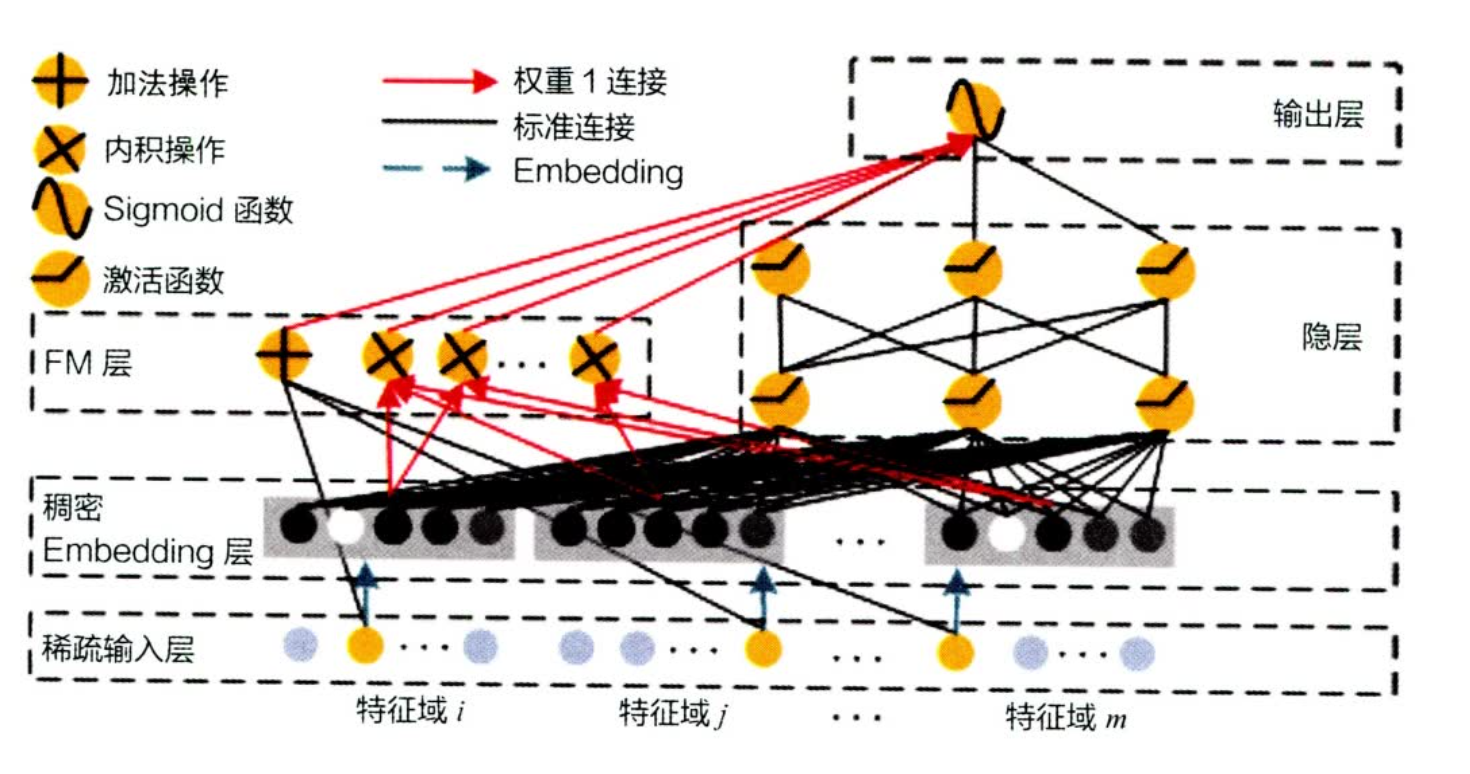
NFM - FM的神经网络尝试
idea: 对二阶特征交叉部分进行改变,利用NN多阶的交叉能力(Sum Pooling 操作)
也可以看作是 deep&wide 对于 deep部分的改进,使用pooling和元素积 代替了 concat操作
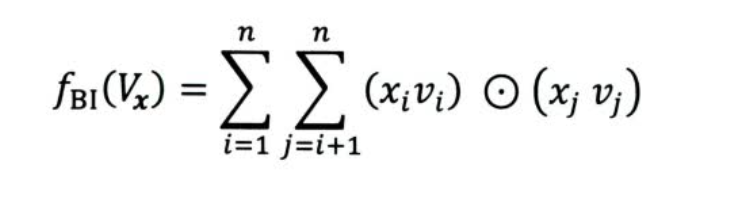
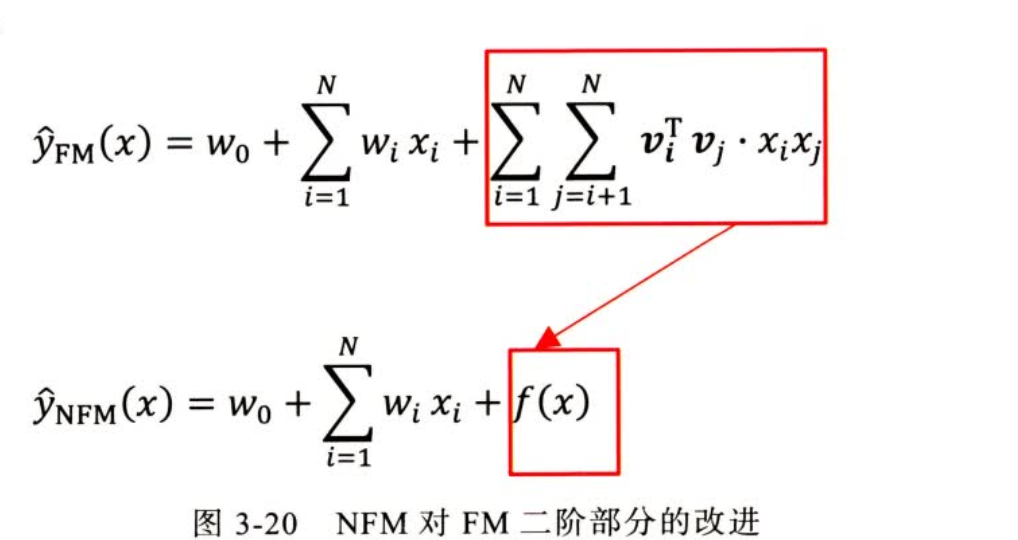
缺点:
对所有特征不加区分的进行 sum pooling,损失了数据中的一些有价值信息,不是每一种组合都应该被同样对待
FM 结合深度学习的优缺点:
优点:
利用深度学习对于特征的交叉能力,设计各种交叉方法
- MLP 堆叠
- PNN,NFM 设计交叉方式
- wide&deep
缺点:
在特征工程上面的各种交叉方式提升有限,一直处于 deep&wide结构
因此需要再模型结构方面有更多创新
- 注意力机制
- 用户历史行为序列建模
- 强化学习
引入注意力机制的推荐模型
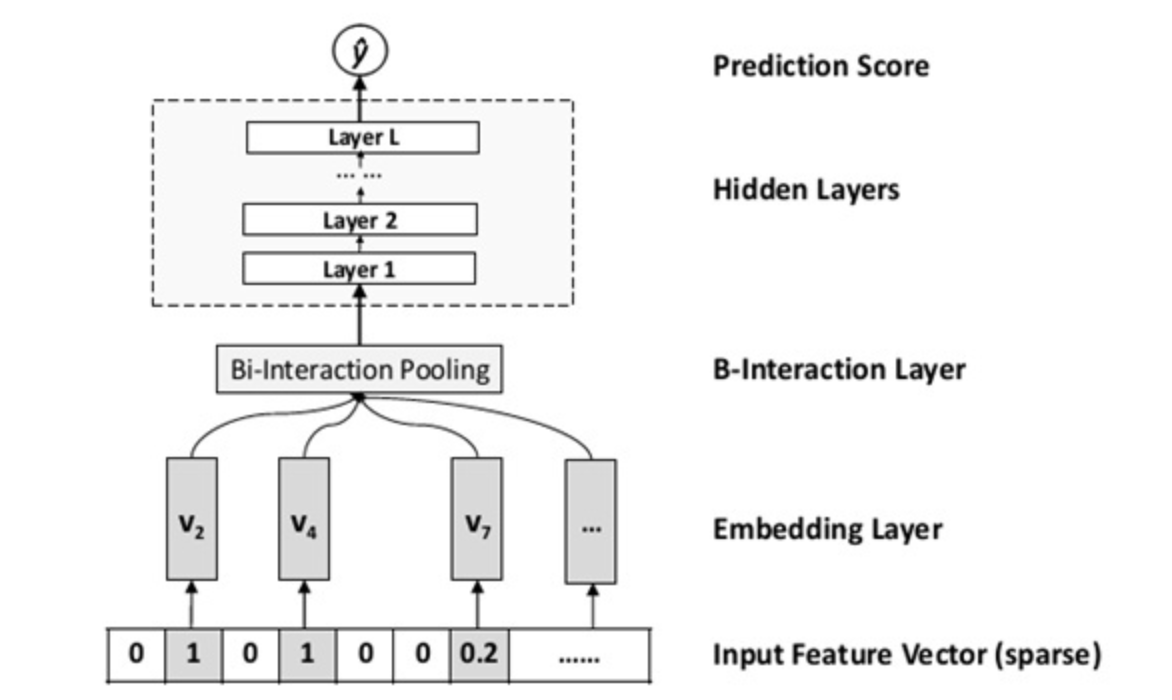
AFM - 引入注意力机制的FM
idea: 改进 NFM Sum Pooling 不加区分的缺点
使用一个注意力网络学习组合特征的重要性分数(和FM学习隐向量打分起到一样的作用)
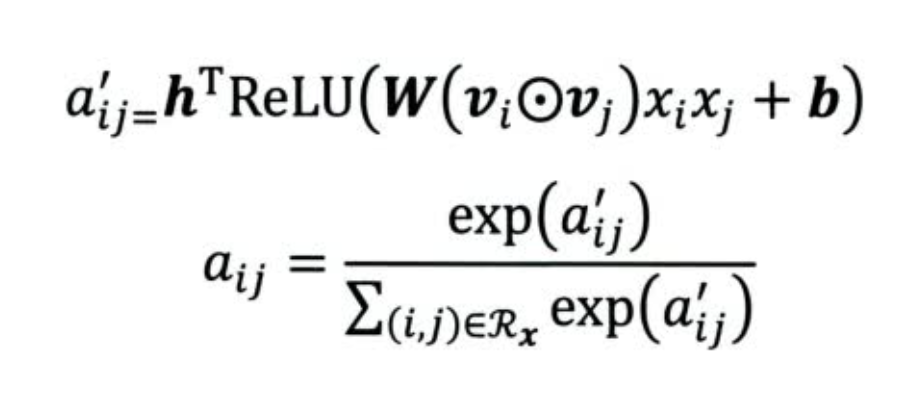
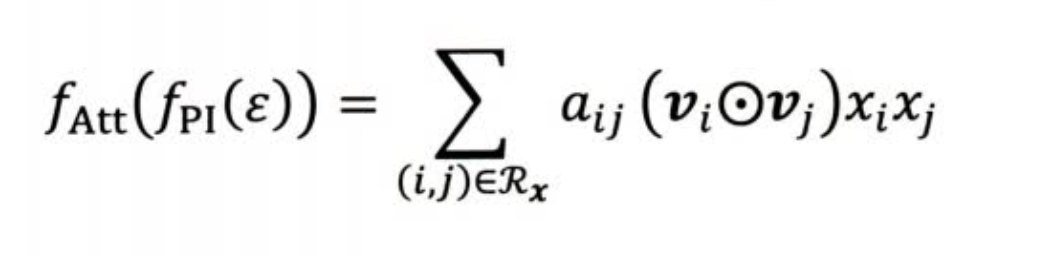
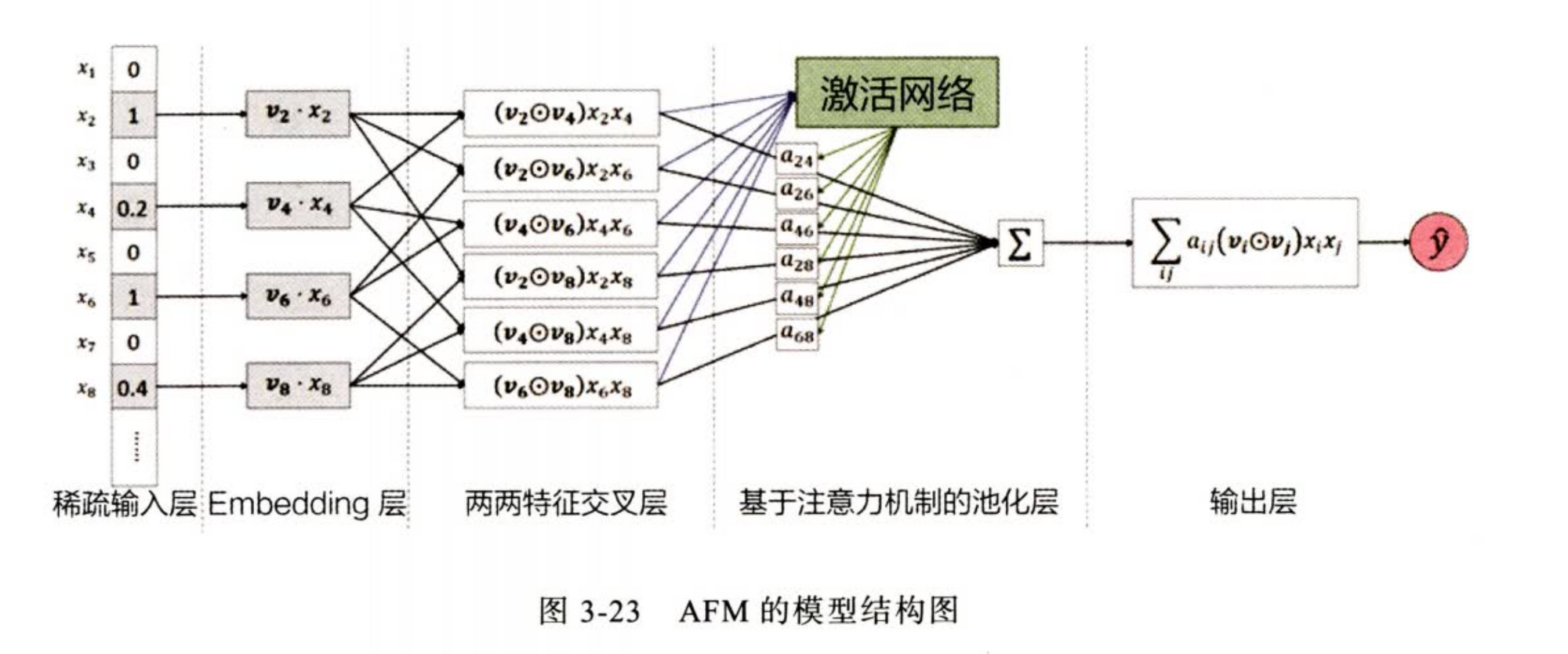
DIN - 引入注意力机制
idea:
- Diversity:多样性是指用户的兴趣是广泛的,一个用户会对多个物品,多个领域感兴趣
- Local activation:部分对应是指只有部分历史数据与目前推荐的物品相关(如推荐零食物品就与用户以前买过什么装备无关)
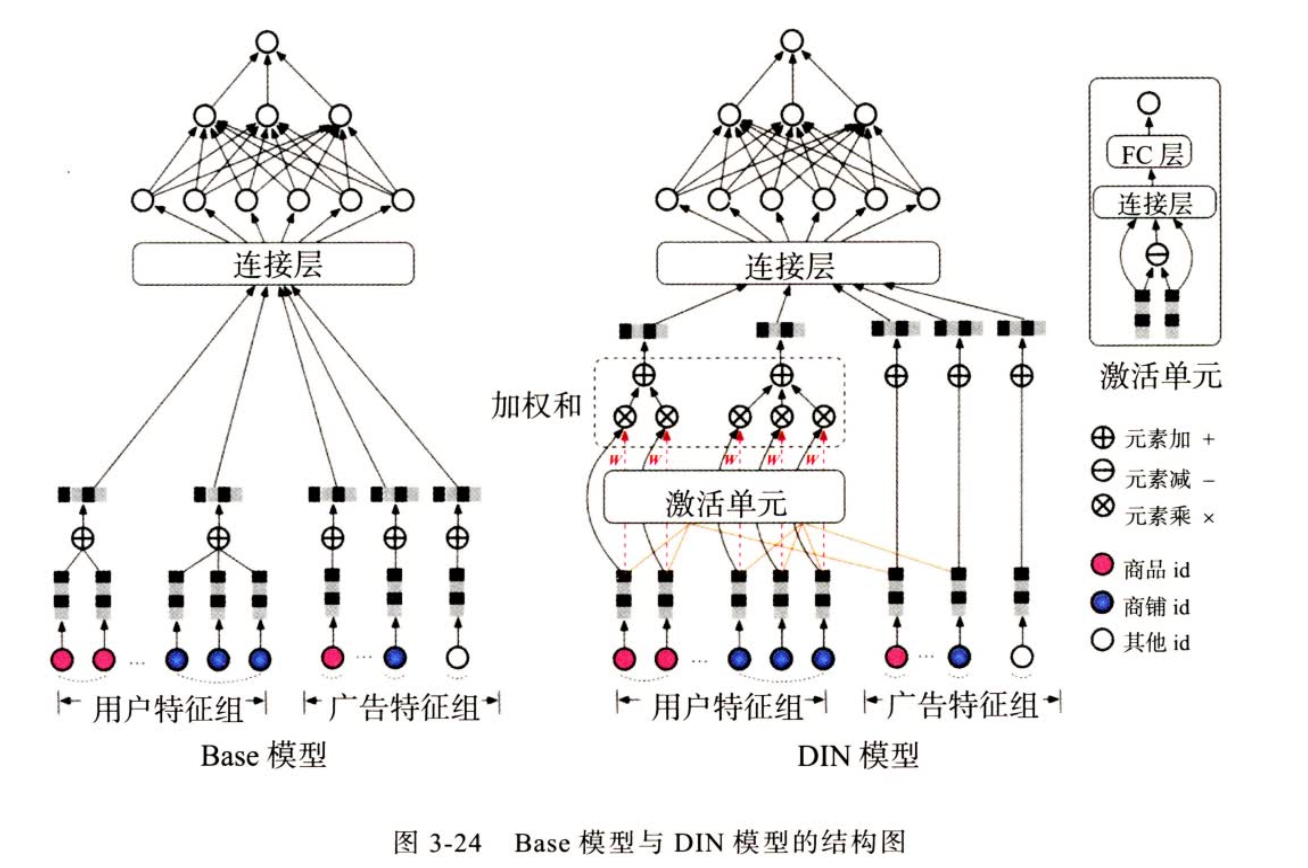
模型方法:
-
注意力权重计算只在相同的 field 进行计算,e.g 历史物品id之和广告物品id计算,店铺同理
-
对用户侧的特征进行了变换,没有在item在进行,也符合逻辑,item要面向不同的用户
-
新的激活函数:
- Dice
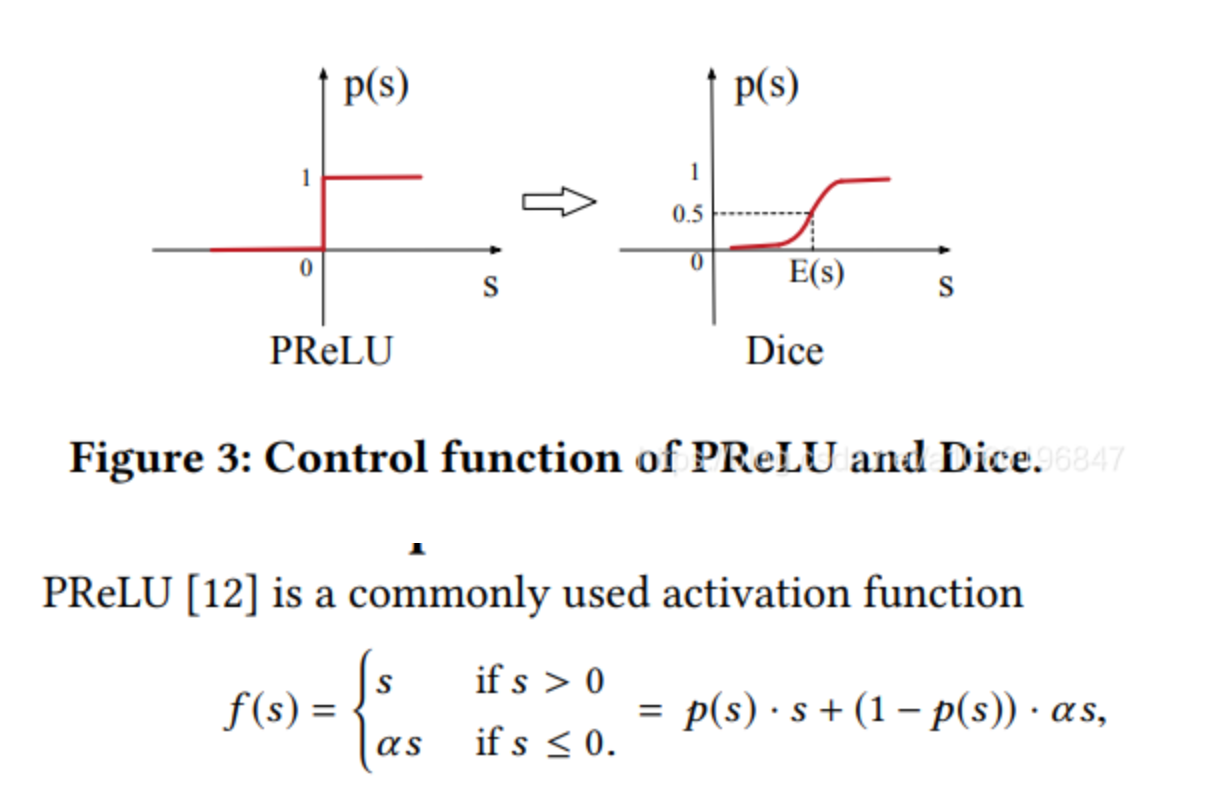
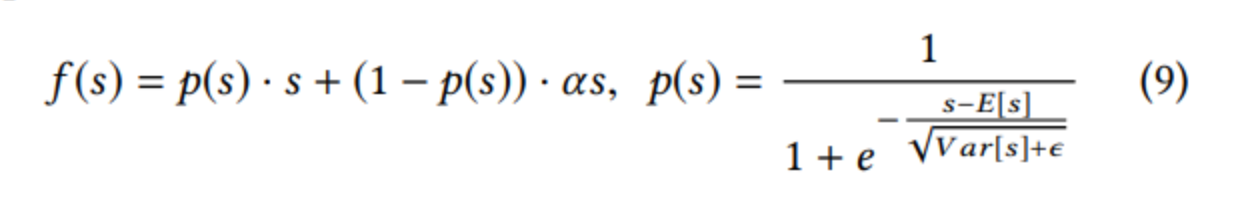
怎么想到这个形式呢,首先 p(s) 必须是(0,1)值域,所以很容易想到 sigmoid ,然后剩下的工作就是移动 sigmoid 的越变点位,使之不是在0处越变,作者采用了 标准化 的方法来决定,优点BN 的味道,但是不如BN复杂,直接计算不需要梯度更新这个值
-
对于长尾item分布问题:
-
Mini-batch Aware Regularization
-
对于特征出现频率高的惩罚要小,对于特征出现频率低的惩罚要大
对于 One-hot, 只要统计列中1的次数就行,次数多的少惩罚,次数少的多惩罚,一个1也没有不计算
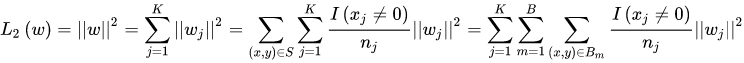
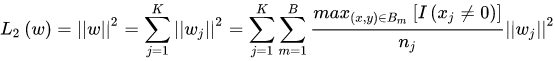
-
-
评价指标:

背景:用AUC当评价指标,线下AUC的提升未必会带来线上AUC的提升,原因有两点:
- AUC反映整体样本的排序能力,对样本不区分用户的计算整体样本的AUC
- AUC的计算过程不仅包含了同一个用户对不同item的预测,也包含了不同用户对不同item的预测,但是线上排序时只针对同一个用户的不同item进行预测
所以由于每个用户的item排序是个性化的,不同用户的排序结果不好比较,可能导致全局AUC并不能反映真实情况,
优点:
- 在模型结构结构上面的一次创新(加权的想法并不是),使用网络来得到权重
缺点:
- 利用了历史数据但是缺乏行为的时序特征
问题解答:
- DIN为什么更适用于电商场景?是否适用于短视频或者信息流?
人们在电商会买各种物件(包括很多不那么感兴趣但生活必需品),所以会出现这个兴趣“多峰”的分布视频推荐也确实发现兴趣多峰的现象,但关键问题是视频和信息流大家的兴趣都相对稳定,所以没有电商那么需要attention机制。
DIEN - 加入行为序列的推荐模型
idea: 用户的购买行为是变化的,而且在短期内具有一定的连续性,因此在CTR中应该把用户兴趣迁移考虑进去(随时间)
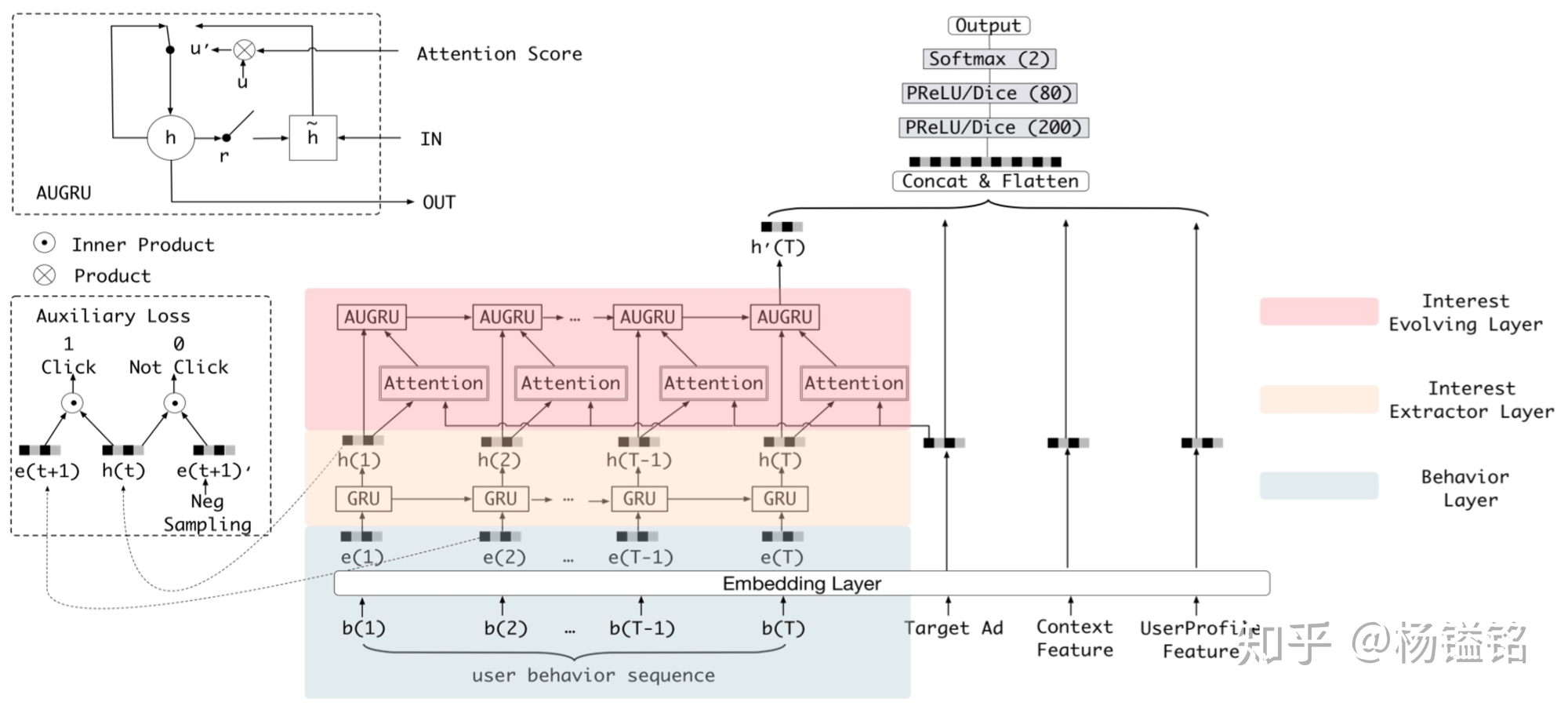
模型:
- behavior layer 就是EMbedding层
- Interest Layer 主要是根据历史事件建模用户兴趣,GRU更多的是建模行为之间的依赖关系
-
为了加强兴趣感知,历史行为序列里面就包括确定的兴趣,后一个买就是前一个兴趣的结果
-
因此采用了 辅助监督 loss,对每一个时间步使用后一个商品进行正监督(分类loss)
辅助loss的引入有多个好处:1、正如作者强调的,辅助loss可以帮助GRU的隐状态更好地表示用户兴趣。2、RNN在长序列建模场景下梯度传播可能并不能很好的影响到序列开始部分,如果在序列的每个部分都引入一个辅助的监督信号,则可一定程度降低优化难度。3、辅助loss可以给embedding层的学习带来更多语义信息,学习到item对应的更好的embedding。
辅助loss也能考虑使用 triplet 把,负采样范围以及策略
-
- Interest Evolving Layer 在历史行为和需要推荐的商品之间建立兴趣关联,着重找到和推荐物品相关的兴趣
缺点:
- 用户历史行为序列的长度,以及间隔时间没有更多的探索,
- 加入GRU系列的串行模型会大大提升模型复杂度,需要大量的工程优化
- 超长用户行为建模:https://zhuanlan.zhihu.com/p/336949535
- 考虑了用户行为的时间间隔座位 Embedding concat上去,或者类似于BERT Position Embedding 的想法
- 序列划分为 session,分而治之。短时seesion,长时seesion,然后建模
强化学习与推荐系统结合
-
强化学习的概念与推荐系统的对应
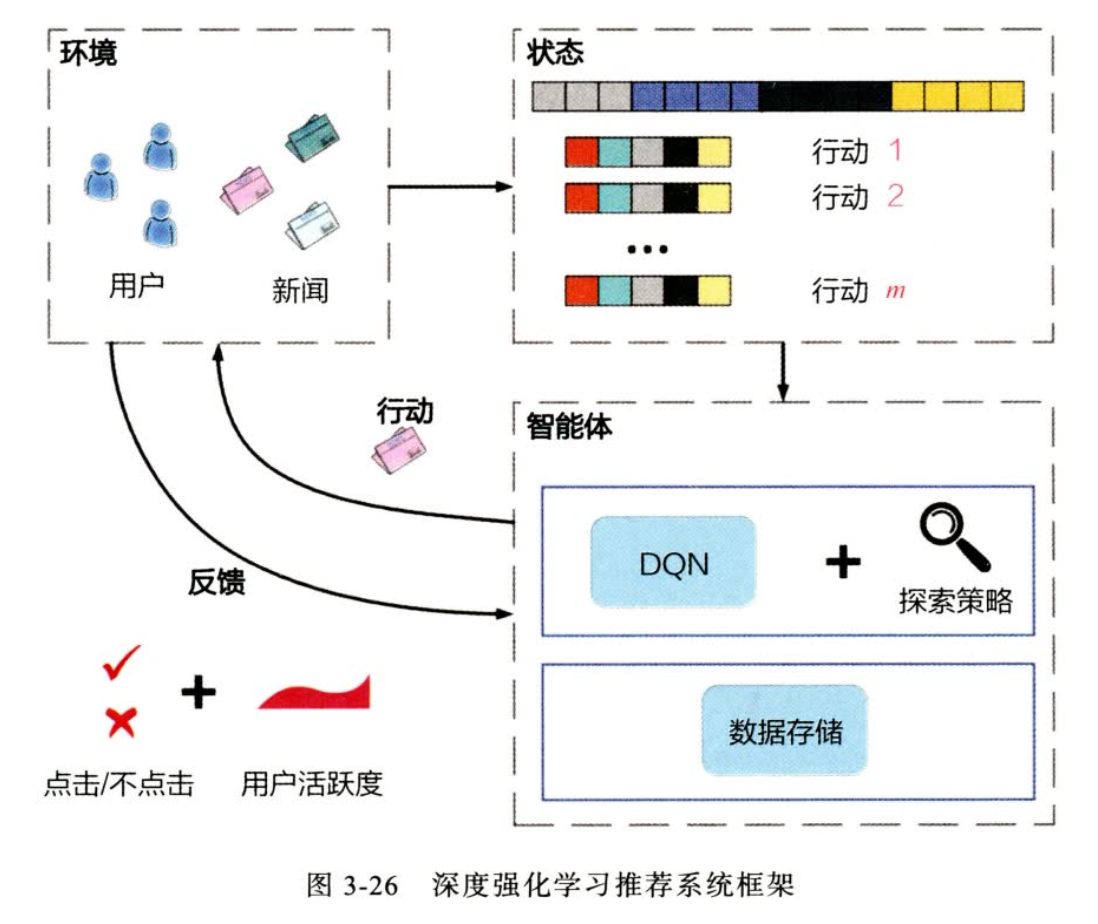
- 状态:对应于训练集
- 智能体:推荐系统所有部件
- 环境:user,item
- 动作:输出的排序列表
- 反馈:记录的日志
-
在线学习过程
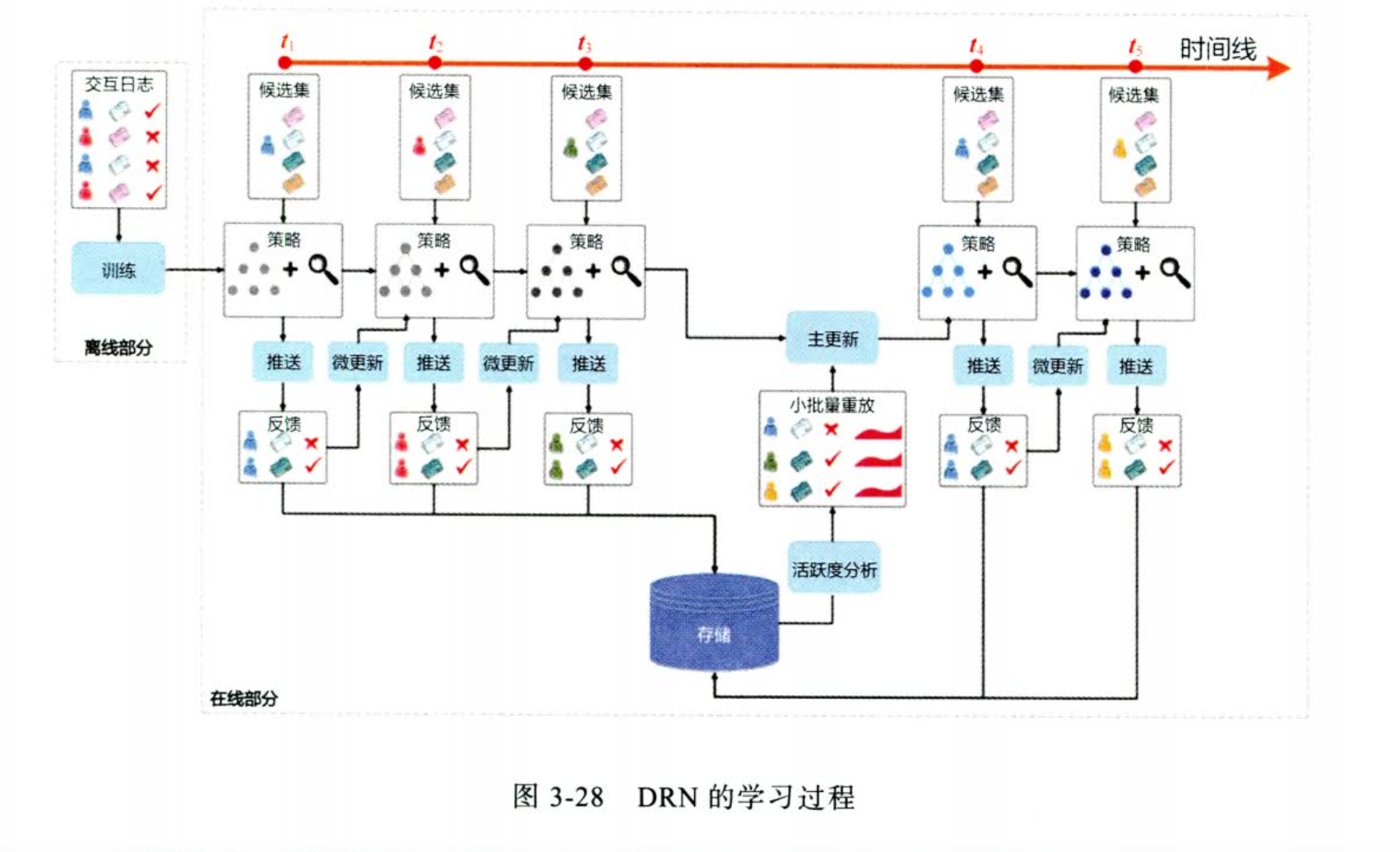
-
模型微小更新
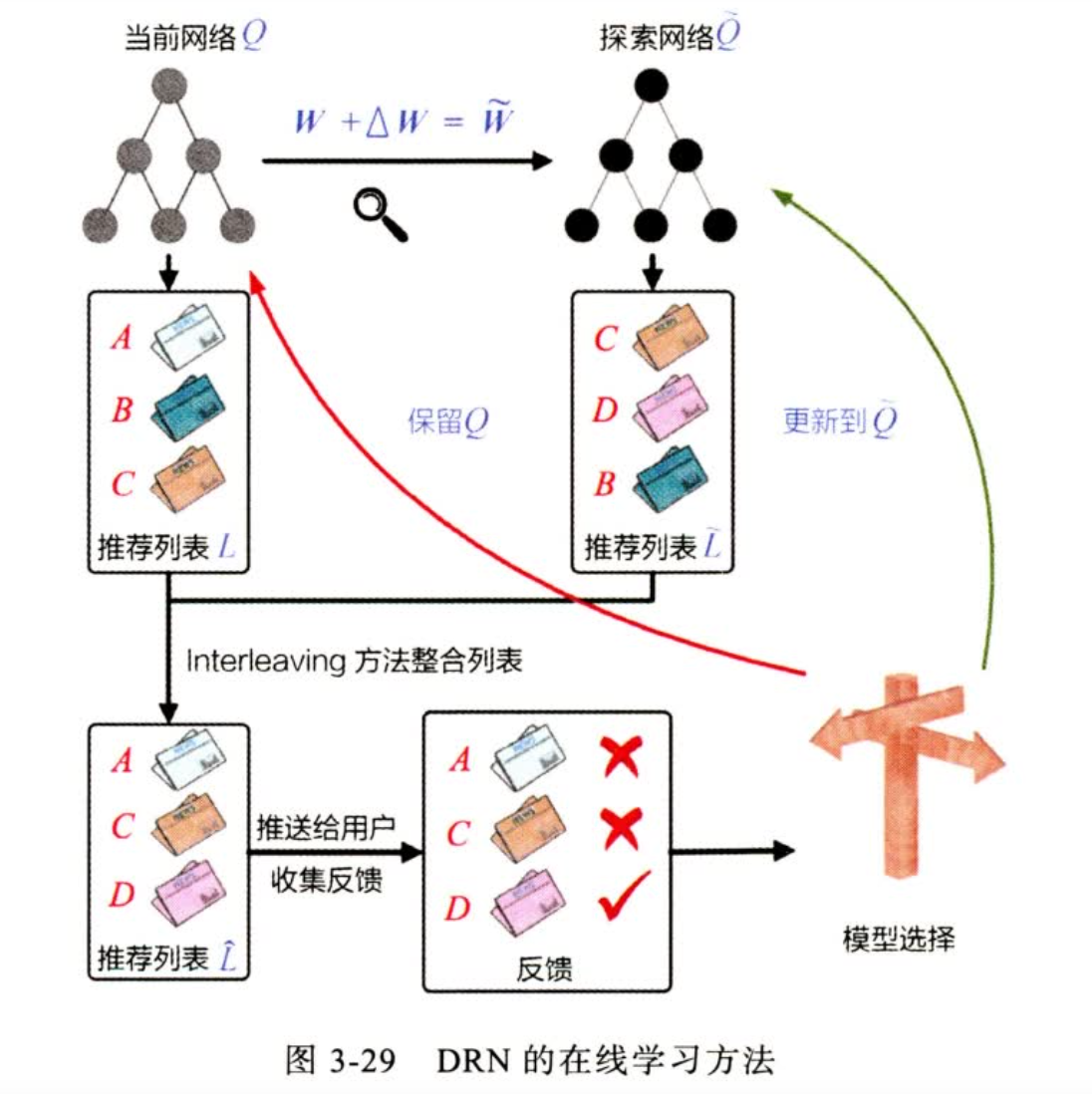
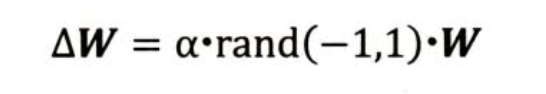
更新步骤:
- 先生成一个随机新的网络
- 使用新的网络生成一个List
- 然后把新旧list 合并,push给用户
- 根据用户反馈,决定使用新模型还是旧模型
-
启发:
- 使用 “重量级”静态模型 还是 “轻量级”动态模型
- 对于推荐架构一种新的视角
深度学习模型汇总



之后的推荐系统发展:
- 阿里巴巴多模态推荐
- 多目标推荐系统
- YouTube 的基于 Session 的推荐系统
- Airbnb 的 Embedding 技术构建推荐系统
评价指标
推荐系统采样评估指标及线上线下一致性问题: https://zhuanlan.zhihu.com/p/262877350
线下AUC提升为什么不能带来线上效果提升?:http://freecoder.me/2019-03-03/30845.html#more

 浙公网安备 33010602011771号
浙公网安备 33010602011771号