
目标检测的评价指标mAP
一、AP & mAP
AP:PR 曲线下面积(下面会说明)
mAP:mean Average Precision, 即各类别 AP 的平均值
二、TP、FP、FN、TN
- True Positive (TP,真正例): IoU>
(
- False Positive (FP,假正例): IoU<=
- False Negative (FN,假负例): 没有检测到的 GT 的数量
- True Negative (TN,真负例): 在 mAP 评价指标中不会使用到
注:ground truth为目标的实际边框(真实标签)。
TP+FP=all detections(也就是所有的预测框数量)
TP+FN=all ground truths(也就是所有的真实框数量)
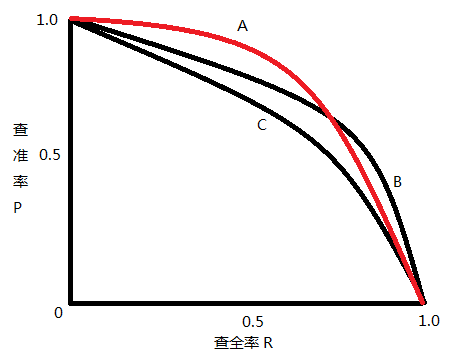
三、查准率、查全率
- 查准率(Precision): TP/(TP + FP)
- 查全率(Recall): TP/(TP + FN)
即: preicision是在你做出的所有预测框中, 有多大比例真的是正样本; recall则是在真正的目标中, 有多少被你找到了。
二者绘制的曲线称为 P-R 曲线
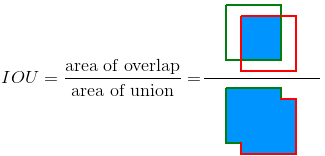
四、交并比 - Intersection Over Union (IOU)
交并比(IOU)是度量两个检测框(对于目标检测来说)的交叠程度,公式如下:
B_gt 代表的是目标实际的边框(Ground Truth,GT),B_p 代表的是预测的边框,通过计算这两者的 IOU,可以判断预测的检测框是否符合条件,IOU 用图片展示如下:
五、评价指标 mAP
下面用一个例子说明 AP 和 mAP 的计算:
先规定两个公式,一个是 Precision,一个是 Recall,这两个公式同上面的一样,我们把它们扩展开来,用另外一种形式进行展示,其中 all detections 代表所有预测框的数量, all ground truths 代表所有 GT 的数量。
AP 是计算某一类 P-R 曲线下的面积,mAP 则是计算所有类别 P-R 曲线下面积的平均值。
假设我们有 7 张图片(Images1-Image7),这些图片有 15 个目标(绿色的框,GT 的数量,上文提及的 all ground truths=15)以及 24 个预测边框(红色的框,A-Y 编号表示,并且有一个置信度值)
并且假设这15个目标都属于同一个类别(class)。
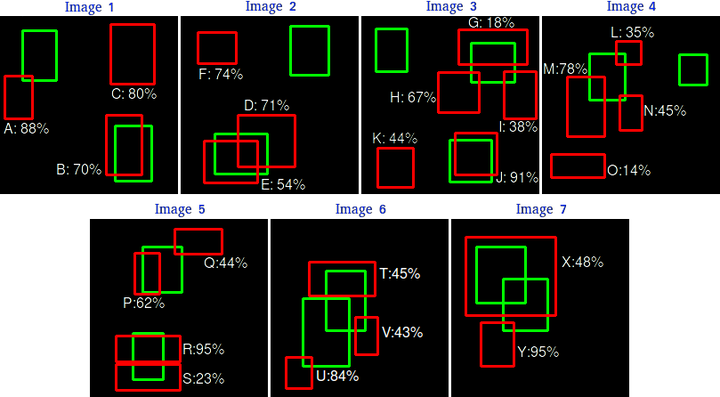
根据上图以及说明,我们可以列出以下表格,其中 Images 代表图片的编号,Detections 代表预测边框的编号,Confidences 代表预测边框的置信度,TP or FP 代表预测的边框是标记为 TP 还是 FP(认为预测边框与 GT 的 IOU 值大于等于 0.3 就标记为 TP;若一个 GT 有多个预测边框,则认为 IOU 最大且大于等于 0.3 的预测框标记为 TP,其他的标记为 FP,即一个 GT 只能有一个预测框标记为 TP),这里的 0.3 是随机取的一个值(threshold)。

通过上表,我们可以绘制出 P-R 曲线(因为 AP 就是 P-R 曲线下面的面积),但是在此之前我们需要计算出 P-R 曲线上各个点的坐标,根据置信度从大到小排序所有的预测框,然后就可以计算 Precision 和 Recall 的值,见下表。(需要记住一个叫累加的概念,就是下图的 ACC TP 和 ACC FP)
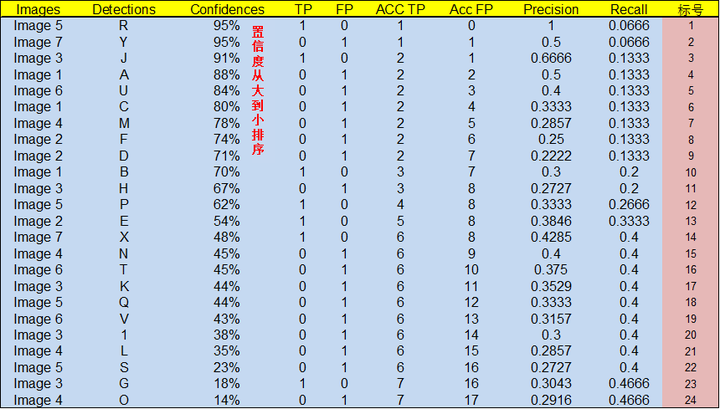
- 标号为 1 的 Precision 和 Recall 的计算方式:Precision=TP/(TP+FP)=1/(1+0)=1,Recall=TP/(TP+FN)=TP/(
all ground truths)=1/15=0.0666 - 标号 2:Precision=TP/(TP+FP)=1/(1+1)=0.5,Recall=TP/(TP+FN)=TP/(
all ground truths)=1/15=0.0666 - 标号 3:Precision=TP/(TP+FP)=2/(2+1)=0.6666,Recall=TP/(TP+FN)=TP/(
all ground truths)=2/15=0.1333 - 其他的依次类推
注:这里的TP和FP就是上图中计算出来的Acc TP和Acc FP。
然后就可以绘制出 P-R 曲线:
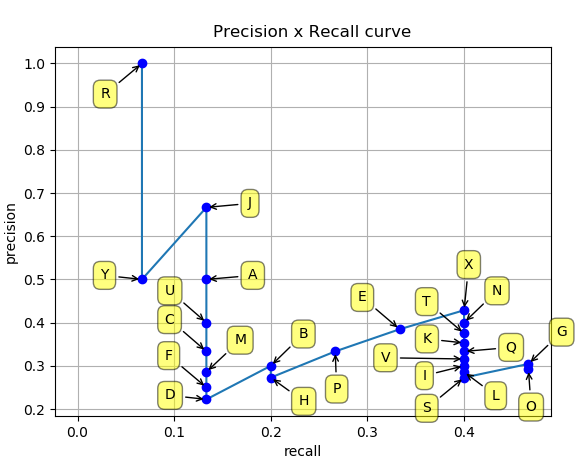
得到 P-R 曲线就可以计算 AP(P-R 曲线下的面积),要计算 P-R 下方的面积,一般使用的是插值的方法,取 11 个点 [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1] 的插值所得
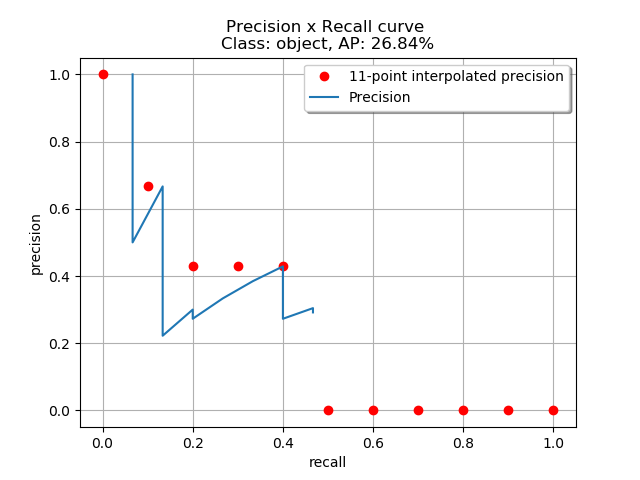
得到一个类别的 AP 结果如下:
要计算 mAP,就把所有类别的 AP 计算出来,然后求取平均即可。
以上转自:https://www.zhihu.com/question/53405779/answer/993913699 作者:平平无奇的AI
**********************************************************************************************************************************************************************************************************************************************
1.但是以上只是一种计算mAP的方法,当然还有其他计算mAP的方法。
2.至少有两个变量会影响Precision和Recall,即IoU阈值和置信度阈值(confidence threshold)。
IoU阈值对Precision和Recall的影响显而易见,下面从两个方面来看看置信度阈值对Precision和Recall的影响。
(1)通俗理解。
假设现在是对于行人的检测:
- 如果confidence threshold设置的太高, prediction就会非常严格, 所以我们认为预测出来的bounding box基本上都是行人,precision就高了;但也因为筛选太严格, 我们可能忽略了一些置信度(confidence score)比较低的行人, 所以recall就低了。
- 如果confidence threshold设置的太低, 什么都会被当成行人, precision就会很低, 相反recall就会很高。
(2)公式理解。
confidence threshold对TP和FN的影响,从而影响Precision和Recall:
比如一个confidence score(置信度)为0.7的bounding box,尽管是IoU可能大于0.5,但是在置信度过滤那一步已经被过滤掉了(当此时的置信度阈值设为0.9的时候)。所以,该bounding box本来可能是TP,但是现在由于置信度阈值设置的过大,将其由positive变成了negative,所以现在应该为FN。
所以要具体问题具体分析,看看论文中是否有做置信度阈值的要求。
2.当比较mAP值,记住以下要点:
(1)mAP通常是在一个数据集上计算得到的。
(2)根据训练数据中各个类的分布情况,mAP值可能在某些类(具有良好的训练数据)非常高,而其他类(具有较少/不良数据)却比较低。所以你的mAP可能是中等的,但是你的模型可能对某些类非常好,对某些类非常不好。因此,建议在分析模型结果时查看各个类的AP值。这些值也许暗示你需要添加更多的训练样本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号