java编程思想之正则表达式
正则表达式是一种强大而灵活的文本处理工具。使用正则表达式,我们能够以编程的方式,构造复杂的文本模式,并对输入的字符串进行搜索。一旦找到了匹配这些模式的部分,你就能随心所欲的对他们进行处理。
1.正则表达式基础
正则表达式就是一种描述字符串的一种方式,用人话说就是:“如果一个字符串中含有这些东西,那么他就是我正在找的东西”。
比如说我要找一个整数,这个整数前面可能有一个负号。我们可以写成这样
-?\\d+
-?表示了可能有一个-在最前面,显而易见?表示的就是有或者没有这个表达式
我们知道整数可能有一位或者多位的阿拉伯数字。在正则表达式当中我们用 \d表示一位数字。但是需要注意的是,在其他语言中,\\表示:
我想要在正则表达式中插入一个普通的(字面上的)反斜杠,请不要给他任何特殊的意义
而java语言对反斜杠的处理比较特殊,在java中\\的意思是:
我要插入一个正则表达式的反斜线,所以其后的字符具有特殊意义
所以在此我们想要表达一位数字就变成了\\d,如果我们想要插入一个普通的反斜杠就应该要写成这样\\\\。不过换行符、制表符之类的东西只需要使用单反斜杠:\n、\t。
我们可以使用+表示一个或者多个之前的表达式。所以d+就变成了有一位或者多位数字。
String中的matches()方法
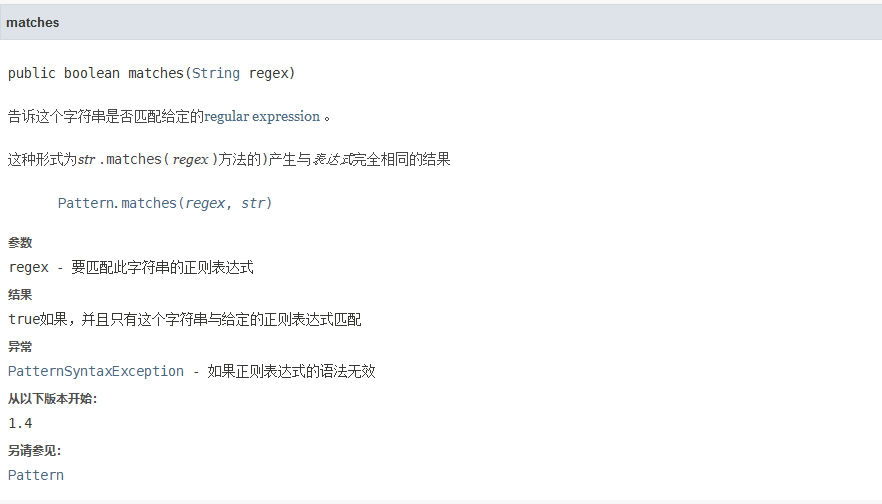
我们可以通过matches()方法来检查一个String是否匹配某个正则表达式,比如:
public class IntegerMatch {
public static void main(String[] args) {
System.out.println("-1234".matches("-?\\d+"));
System.out.println("1234".matches("-?\\d+"));
System.out.println("+1234".matches("-?\\d+"));
System.out.println("+1234".matches("(-|\\+)?\\d+"));
}
}
true
true
false
true
前两个字符串满足对应的正则表达式,匹配成功。第三个字符串开头有一个+,与对应的正则表达式不匹配。所以,我们在第四个中将正则表达式改为可能以-或者+开头,也就有了
(-|\\+)?\\d+
其中|表示或的意思,括号有将表达式分组的效果。而+在前面提到表示一个或多个的意思,所以我们在此要表示+需要使用\\+进行转义。
String中的split()方法
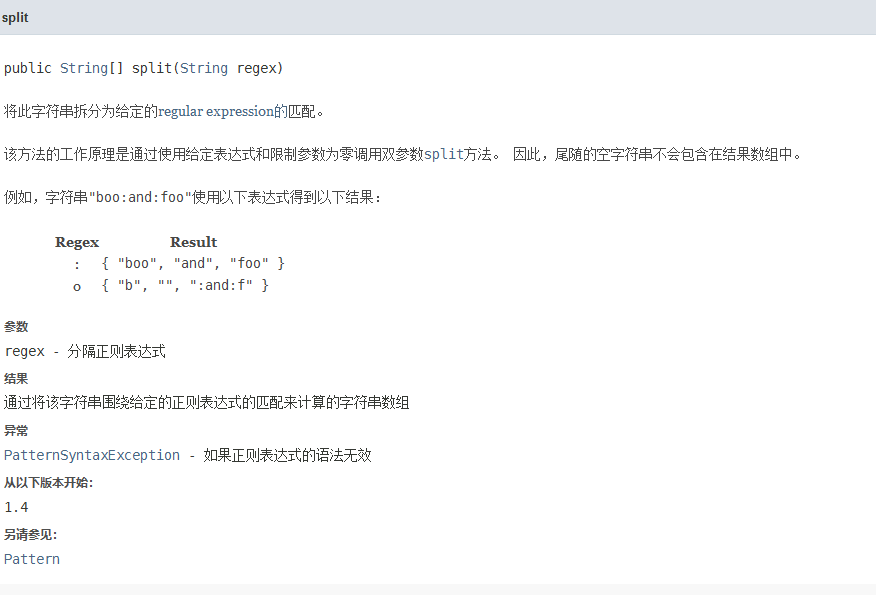
splite()可以将字符串从正则表达式匹配的地方切开,返回一个String数组。比如说:
public class Splitting {
public static String knights =
"Then, when you have found the shrubbery. you must "+
"cut down the mightiest tree in the forest..." +
"with... a herring!";
public static void split(String regex) {
System.out.println(Arrays.toString(knights.split(regex)));
}
public static void main(String[] args) {
split(" ");//按空格划分
split("\\W+");//按非单词字符划分
split("n\\W+");//按n开头的非单词字符划分
}
}
[Then,, when, you, have, found, the, shrubbery., you, must, cut, down, the, mightiest, tree, in, the, forest...with..., a, herring!]
[Then, when, you, have, found, the, shrubbery, you, must, cut, down, the, mightiest, tree, in, the, forest, with, a, herring]
[The, whe, you have found the shrubbery. you must cut dow, the mightiest tree i, the forest...with... a herring!]
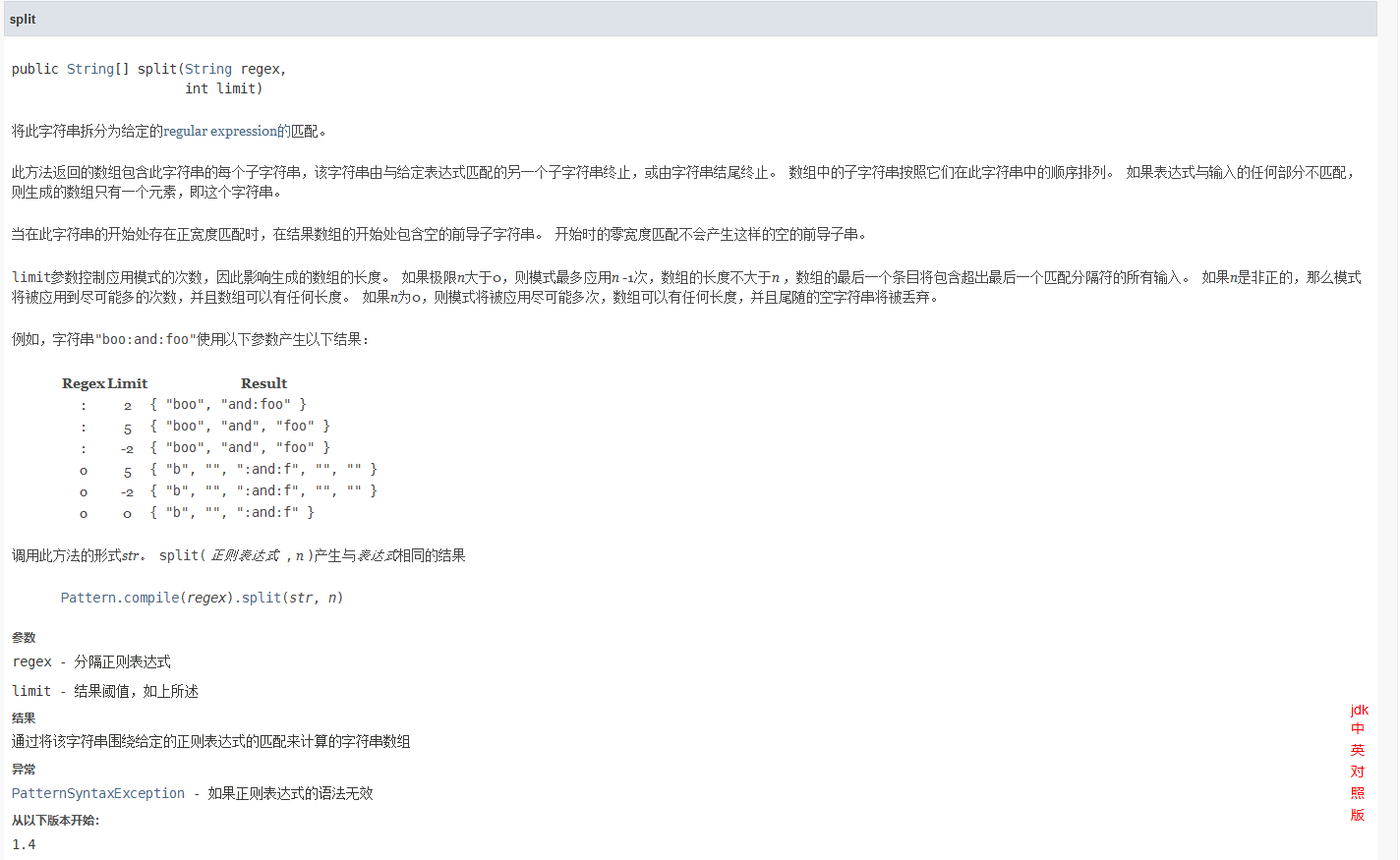
当然,String.splite()还有一个重载版本,它允许你限制字符串分割的个数
String中的replaceFirst() && replaceAll()
这两个方法可以替换正则表达式第一个匹配的子串,或者替换所有匹配的地方
public class Replacing {
static String s = "Then, when you have found the shrubbery. you must "+
"cut down the mightiest tree in the forest..." +
"with... a herring!";
public static void main(String[] args) {
//将第一个f开头的单词替换成located
System.out.println(s.replaceFirst("f\\w+", "located"));
//将shrubbery tree herring三个单词替换成banana
System.out.println(s.replaceAll("shrubbery|tree|herring","banana"));
}
}
2.创建正则表达式
要想使用好正则表达式,必须得学会字符类的使用,以下是一些创建字符类的典型方式

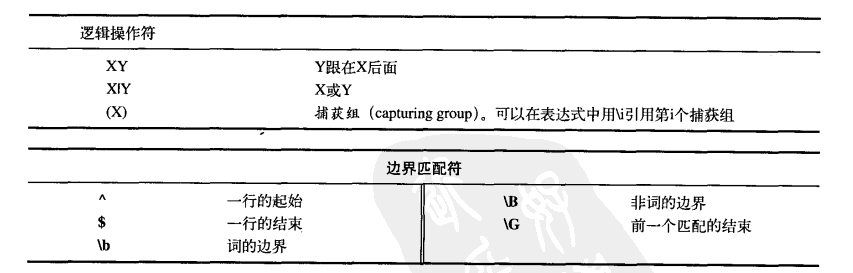
更多可以了解:https://www.runoob.com/java/java-regular-expressions.html
比如说我有一个字符序列
Rudolph
现在我通过构建不同的正则表达式都能够匹配上面的字符串
[rR]udolph //第一种
[rR][aeiou][a-z]ol.* //第二种
R.* //第三种
当然,我们应该尽量编写能够完成任务的,最简单的以及最必要的正则表达式。并且,我们在实际使用中都是参考代码中已经使用到的正则表达式。
3.量词
量词描述了一个模式吸收文本的方式,分为以下几种类型:
-
贪婪型:量词总是贪婪的,除非有其他的选项被设置。贪婪表达式会为所有可能的模式发现尽可能多的匹配。导致此向题的一个典型理由就是假定我们的模式仅能匹配第一个可能的字符组,如果它是贪婪的,那么它就会继续往下匹配。
-
勉强型:用问号来指定,这个量词匹配满足模式所需的最少字符数。因此也称作懒惰的、最少匹配的、非贪婪的、不贪婪的。
-
占有型:目前,这种类型的量词只有在Java语言中才可用(在其他语言中不可用),并且也更高级,因此我们大概不会立刻用到它。当正则表达式披应用于字符串时,它会产生相当多的状态,以便在匹配失败时可以回溯。而“占有的”量词并不保存这些中间状态,因 此它们可以防止回溯。它们常常用于防止正则表达式失控,因此可以使正则表达式执行起 来更有效。

4.Pattern && Matcher
我们上文介绍的都是使用String来构造、匹配正则表达式,但是很明显String的功能很有限,所以我们引入了Pattern和Matcher类来实现更为强大的功能。
使用Pattern和Matcher类我们需要导入java.util.regex包,接着用static Pattern.compile()方法来编译正则表达式,它会根据我们传入的String类型的正则表达式来生成一个Pattern对象。接下来在利用生成的Pattern对象中的matcher()方法生成一个Matcher对象。Matchcer中提供许多的功能供我们使用,比如String中同样提供了的replaceAll()。
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class TestRegularExpression {
public static void main(String[] args) {
args = new String[]{"abcabcabcdefabc", "abc+", "(abc)+", "(abc){2,}"};
if (args.length < 2) {
System.out.println("Usage:\njava TestRegularExpression " +
"characterSequence regularExpression+");
System.exit(0);
}
System.out.println("Input: \"" + args[0] + "\"");
for (String arg : args) {
System.out.println("Regular expression: \"" + arg + "\"");
Pattern p = Pattern.compile(arg);
Matcher m = p.matcher(args[0]);
while (m.find()) {
System.out.println("Match \"" + m.group() + "\"at position " +
m.start() + "-" + (m.end() - 1));
}
}
}
}
Input: "abcabcabcdefabc"
Regular expression: "abcabcabcdefabc"
Match "abcabcabcdefabc"at position 0-14
Regular expression: "abc+"
Match "abc"at position 0-2
Match "abc"at position 3-5
Match "abc"at position 6-8
Match "abc"at position 12-14
Regular expression: "(abc)+"
Match "abcabcabc"at position 0-8
Match "abc"at position 12-14
Regular expression: "(abc){2,}"
Match "abcabcabc"at position 0-8
以上代码可以通过控制台传入参数来判断一个正则表达式是否正确,当然为了测试我直接在代码中已经给args[]赋值,实际使用时可以删除。
Pattern与Matcher的具体方法建议查看api文档,也可以查看上方链接
组(Groups)
组是用括号划分的正则表达式,可以根据组的编号来引用某个组。组号为0表示整个表达式,组号1表示被第一对括号括起来的组,依此类推。比如:
A(B(C))D
在上面的表达式中:组0是ABCD, 组1是BC, 组2是C
Macher对象中提供了一系列的方法可以供我们获取分组信息:
| 方法 | 作用 |
|---|---|
| public int groupCount() | 返回该匹配器中的模式中的分组数目,不包含第0组 |
| public String group() | 返回前一次匹配操作的第0组 |
| public String group(int i) | 返回在前一次匹配操作期间指定的组号,如果匹配成功, 但是在指定的组没有匹配输入字符串的任何部分,将会返回null |
| public int start(int group) | 返回在前一次匹配操作中寻找到的组的起始索引 |
| public int end(int group) | 返回在前一次匹配操作中寻找到的组的最后一个字符索引加一的值 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号