ConceptNet 常识知识库(knowledge base, KB)
什么是 ConceptNet
ConceptNet是一个免费提供的语义网络(semantic network),旨在帮助计算机理解人们使用的词语的含义。ConceptNet起源于众包项目Open Mind Common Sense,该项目于1999年在麻省理工学院媒体实验室启动。自那以后,该项目已经发展到包括来自其他众包资源的知识、专家创造的资源和有目的的游戏。(上面翻译自官网 http://conceptnet.io/)。
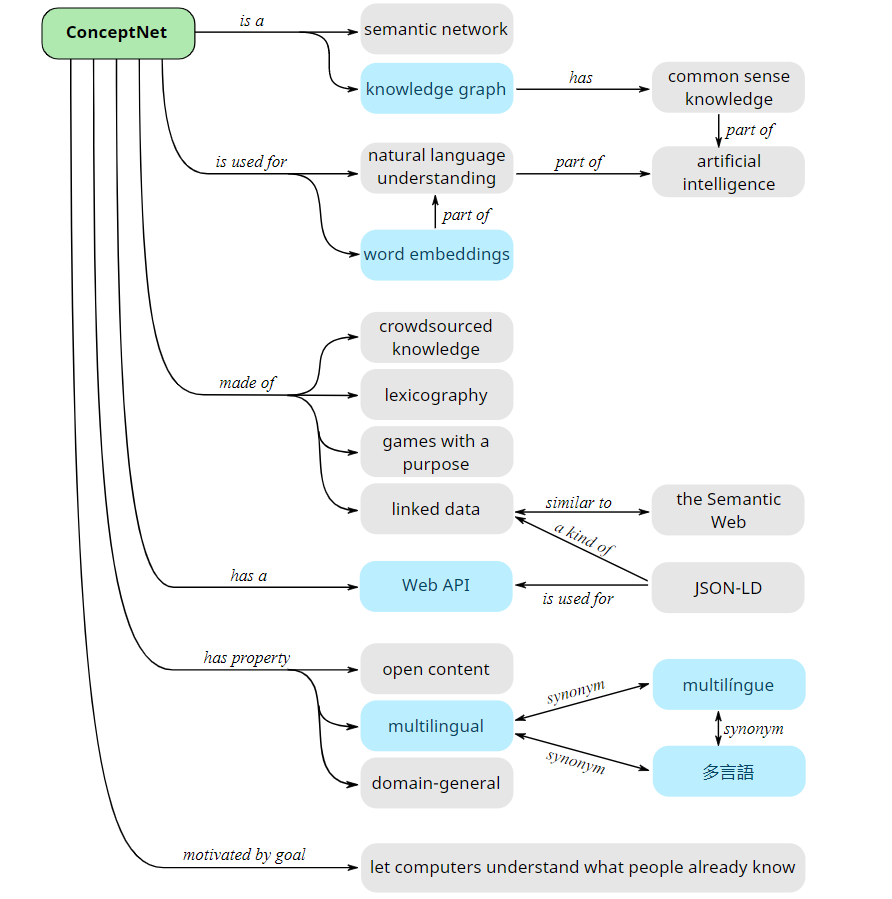
联系与区别
从上图中可以看出,ConceptNet既是一个语义网络也是一个知识图谱。但是网络上很多地方也将 ConceptNet 叫做常识知识库(knowledge base, KB)。知识库是用于信息系统中的结构化或非结构化数据的大型存储库。最初创造这个术语是为了区分数据库(当时的数据库包含扁平的表格数据)和具有关系和层次数据的新知识库。今天的数据库可以像以前的知识库一样具有多面性。这意味着今天的知识库更接近语义和组织的多层面数据。当一些研究者交替使用术语知识库和知识图时,术语图的使用是有意的,它们是有区别的。所有的知识图都是知识库,但并不是所有的知识库都是知识图。知识图和基础之间的关键区别在于,图以实体之间的关系为中心。图是可变的,也是语义的,这意味着数据的含义是与数据一起编码的。这为机器学习在自动化知识库或知识图等方面提供了巨大的可能性。知识库中的知识有很多种不同的形式,例如本体知识、关联性知识、规则库、案例知识等。相比于知识库的概念,知识图谱更加侧重关联性知识的构建,如三元组。semantic network是语义网络。语义网络最早是1960年由认知科学家Allan M. Collins作为知识表示的一种方法提出。WordNet是最典型的语义网络。相比起知识图谱,早期的语义网络更加侧重描述概念以及概念之间的关系,而知识图谱更加强调数据或事物之间的链接。
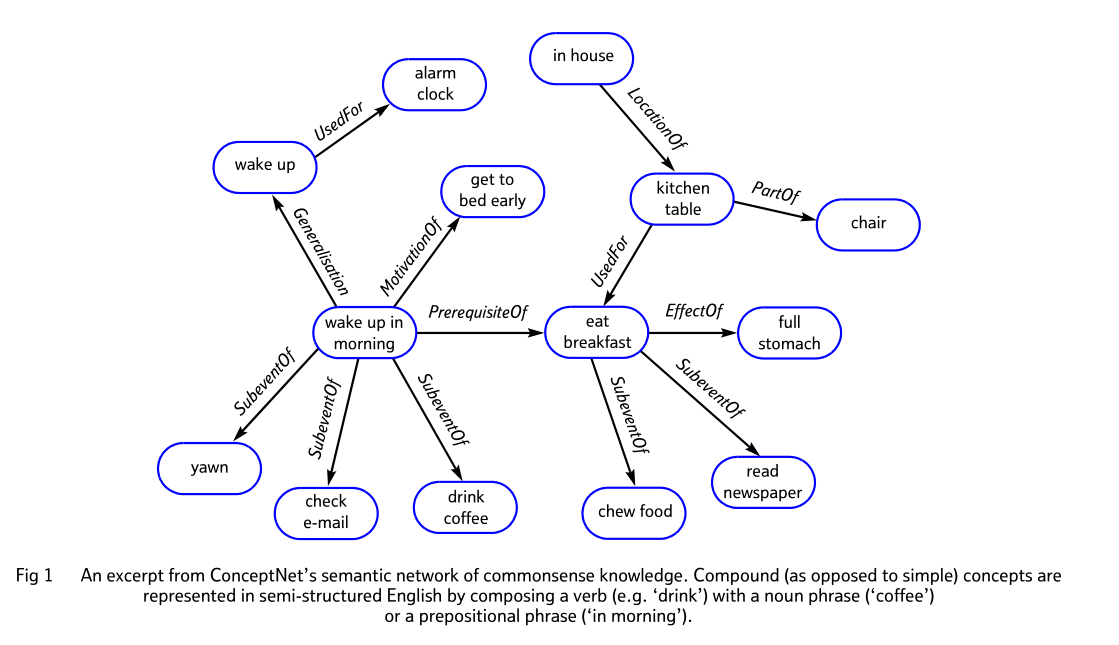
ConceptNet知识库以三元组形式的关系型知识构成。ConceptNet5版本已经包含有2800万关系描述。与Cyc相比,ConceptNet采用了非形式化、更加接近自然语言的描述,而不是像Cyc那样采用形式化的谓词逻辑。与链接数据和谷歌知识图谱相比,ConceptNet比较侧重于词与词之间的关系。从这个角度看,ConceptNet更加接近于WordNet,但是又比WordNet包含的关系类型多。
概念演变

使用 ConceptNet
数据格式
原始 ConceptNet 数据集是 csv 格式,下面这样
| uri | relation | start | end | json |
|---|---|---|---|---|
| /a/[/r/Synonym/,/c/zh/馬匹/,/c/zh/马匹/] | /r/Synonym | /c/zh/馬匹 | /c/zh/马匹 | {"dataset": "/d/cc_cedict", "license": "cc:by-sa/4.0", "sources": [{"contributor": "/s/resource/cc_cedict/2017-10"}], "weight": 1.0} |
| /a/[/r/Synonym/,/c/zh/馬匹/,/c/en/horse/] | /r/Synonym | /c/zh/馬匹 | /c/en/horse | {"dataset": "/d/cc_cedict", "license": "cc:by-sa/4.0", "sources": [{"contributor": "/s/resource/cc_cedict/2017-10"}], "weight": 1.0} |
| /a/[/r/Synonym/,/c/zh/马匹/,/c/en/horse/] | /r/Synonym | /c/zh/马匹 | /c/en/horse | {"dataset": "/d/cc_cedict", "license": "cc:by-sa/4.0", "sources": [{"contributor": "/s/resource/cc_cedict/2017-10"}], "weight": 1.0} |
| /a/[/r/Synonym/,/c/zh/馬南邨/,/c/zh/马南邨/] | /r/Synonym | /c/zh/馬南邨 | /c/zh/马南邨 | {"dataset": "/d/cc_cedict", "license": "cc:by-sa/4.0", "sources": [{"contributor": "/s/resource/cc_cedict/2017-10"}], "weight": 1.0} |
| 符号与含义之间的对应关系如下 | ||||
| 符号 | 含义 | |||
| ---- | -------------------------- | |||
| /r | 关系,relation,边 | |||
| /c | 概念,concept,节点 | |||
| /en | 英文 | |||
| /zh | 中文 | |||
| uri | 把(关系,起点,终点)三元组拼接成字符串,可作为索引 | |||
| json | 附加信息 |
除了这种数据格式,ConceptNet还提供一个 REST API 可以获取 JSON-LD 格式的数据。在python中可以使用如下的方式获取数据。
>>> import requests
>>> obj = requests.get('http://api.conceptnet.io/c/en/example').json()
>>> obj.keys()
dict_keys(['view', '@context', '@id', 'edges'])
>>> len(obj['edges'])
20
>>> obj['edges'][2]
{'@id': '/a/[/r/IsA/,/c/en/example/n/,/c/en/information/n/]',
'dataset': '/d/wordnet/3.1',
'end': {'@id': '/c/en/information/n',
'label': 'information',
'language': 'en',
'sense_label': 'n',
'term': '/c/en/information'},
'license': 'cc:by/4.0',
'rel': {'@id': '/r/IsA', 'label': 'IsA'},
'sources': [{'@id' : '/s/resource/wor dnet/rdf/3.1',
'contributor': '/s/resource/wordnet/rdf/3.1'}],
'start': {'@id': '/c/en/example/n',
'label': 'example',
'language': 'en',
'sense_label': 'n',
'term': '/c/en/example'},
'surfaceText': [[example]] is a type of [[information]]',
'weight': 2.0}
节点和边
节点 Node
ConceptNet 的节点是自然语言的单词或者短语。每个节点在 ConceptNet中 都有一个以/c/开头的 URI 和一个语言代码,比如/c/en/example。如果已知一个节点的URI,就可以通过http://api.conceptnet.io + URI获取节点,例如,单词 example 对应的链接是http://api.conceptnet.io/c/en/example
当使用API查找节点的时候,可以得到如下格式的一个数据
{
"@context": [
"http://api.conceptnet.io/ld/conceptnet5.7/context.ld.json"
],
"@id": "/c/en/example",
"edges": [...],
"view": {
"@id": "/c/en/example?offset=0&limit=20",
"firstPage": "/c/en/example?offset=0&limit=20",
"nextPage": "/c/en/example?offset=20&limit=20",
"paginatedProperty": "edges"
}
}
真正有意思的信息在edges里面,稍后讨论。
首先,上面的数据是个标准的JSON格式,但是有些属性前面有一个@,这些属性是为了JSON-LD存在的。JSON-LD是一个关联数据API(Linked Data APIs)的标准。通过使用JSON-LD,可以提供随元数据而来的信息,这些信息是关于它的含义以及如何检索它,并且这些信息可以被转换、重用并链接到其他系统。
@context链接到一个含有帮助JSON-LD工具理解这个API的信息的文件(就像上面代码中的那个连接,打开看一下就明白了),这个文件还包含帮助人类理解的注释。这个上下文文件(context)用RDF格式和英文解释了那些前面没有@的属性,例如:edges 和 view 都是什么意思。
大部分从API返回的对象都有一个@id属性,这个属性可以告诉我们这个对象的URI。最顶层的@id表示的是本次查找的对象,在查询返回中可能有更多的@id指向一些相关的信息。
有一些对象有大量的信息,但是有时候我们并不想让它一次性返回。其中的view对象就描述了一个长列表的分页方式:这个对象有一个@id属性,指向你正在看的页面,还有firstPage,previousPage和lastPage属性,它们的值指向其他的多种页面。"paginatedProperty": "edges"属性是告诉你,你当前一页一页浏览的是edges列表。
有三种方式可以通过ConceptNet 5 API访问数据:
- Loopup,当已知URI,求包含这个URI的边(edges)时使用
- Search,找到满足当前条件的边(edges)的列表
- Association,寻找一个或者多个概念的相似概念时使用
edge 的结构
在edges列表中,可以看到代表图的边的对象。边是连接一个节点和另一个节点的知识单元。下面就是一个边(edge):
{
"@id": "/a/[/r/UsedFor/,/c/en/example/,/c/en/explain/]",
"dataset": "/d/conceptnet/4/en",
"end": {
"@id": "/c/en/explain",
"label": "explain something",
"language": "en",
"term": "/c/en/explain"
},
"license": "cc:by-sa/4.0",
"rel": {
"@id": "/r/UsedFor",
"label": "UsedFor"
},
"sources": [
{
"@id": "/and/[/s/activity/omcs/omcs1_possibly_free_text/,/s/contributor/omcs/pavlos/]",
"activity": "/s/activity/omcs/omcs1_possibly_free_text",
"contributor": "/s/contributor/omcs/pavlos"
}
],
"start": {
"@id": "/c/en/example",
"label": "an example",
"language": "en",
"term": "/c/en/example"
},
"surfaceText": "You can use [[an example]] to [[explain something]]",
"weight": 1.0,
"@context": [
"http://api.conceptnet.io/ld/conceptnet5.5/context.ld.json",
"http://api.conceptnet.io/ld/conceptnet5.5/pagination.ld.json"
]
}
这个边的@id属性是 /a/[/r/UsedFor/,/c/en/example/,/c/en/explain/]。这个看起来比较复杂的URI,通过包含连接的节点以及它们是如何连接的来唯一标识一个边。不必从这个URI中提取信息,这些信息在start, end和rel属性中以更方便的格式表示了出来。
start 和 end
"start": {
"@id": "/c/en/example",
"label": "an example",
"language": "en",
"term": "/c/en/example"
}
start和end指向ConceptNet中的节点。他们包含@id属性,可以从这个属性的值URI中查看这个节点的信息。start和end还提供:
- 人类可读的
label,可能是个更完整的短语而不仅仅是URI中的简单的单词(我想,大概就类似web应用的API接口文档中的 description 吧) language,label中使用的语言代码(总是和URI中的语言代码相同)term,指向这个词条的最通用的版本。在大多数情况下,这个是和URI一样的。但是,如果查询的是某个特殊的词性,例如使用/c/en/example/n来查询"example"的名词条目,这个term链接就会指向更通用的/c/en/example。
rel
"rel": {
"@id": "/r/UsedFor",
"label": "UsedFor"
}
rel描述ConceptNet中定义的连接节点的大概40(40-ish,大概40个,到写博客的时候是34个,https://github.com/commonsense/conceptnet5/wiki/Relations)个关系之一,关系用诸如“UsedFor”这样的人造名称来标记。即使它们用不同的语言或来自不同的数据源描述信息,它们也保持不变。
surfaceText
"surfaceText": "You can use [[an example]] to [[explain something]]"
一些ConceptNet的数据是从自然语言文本中提取的,surfaceText的值展示提取这个数据的原始文本是什么。
sources
"sources": [
{
"@id": "/and/[/s/activity/omcs/omcs1_possibly_free_text/,/s/contributor/omcs/pavlos/]",
"activity": "/s/activity/omcs/omcs1_possibly_free_text",
"contributor": "/s/contributor/omcs/pavlos"
}
]
sources告诉我们为什么ConceptNet相信这个信息。每个边(edge)可能来自一个或多个源。每个源(sources)都是一个对象,并且有它自己的@id属性。但是这个ID只包含对象的其余部分中的信息(为了让RDF数据更好,我们使用了冗余)(这个不是太懂)
source可以包含提供这些知识的各种因素。例如,contributor代表一个参与众包网站来提供数据的人。activity代表他们正在做什么,或者process代表自动提取知识的过程。
因此,如果source是一个叫"pavlos"的contributor,很久之前这个人从Open Mind Common Sense (OMCS)网站键入信息。我们那时的记录方式并不完美,但我们认为他们是在把句子输入OMCS的自由文本框,所以我们将其叫做omcs1_possibly_free_text。
license
"license": "cc:by-sa/4.0"
许可证(license)告诉我们可以如何使用获取到的信息。这个内容并不指向ConceptNet中的API,而是指向知识共享(Creative Common)的链接数据API。前缀cc:是由http://creativecommons.org/licenses/里的内容文件定义的。这意味着你可以在 http://creativecommons.org/licenses/by-sa/4.0 找到这个边(edge)的许可证信息,包含人类可读的许可证以及计算机可读的许可证。
(有些边(edge)没有相同方式分享(ShareAlike)的要求,但是既然整体上是使用的ConceptNet就要遵循相同方式分享(ShareAlike)的要求。详见 https://github.com/commonsense/conceptnet5/wiki/Copying-and-sharing-ConceptNet)
weight
"weight": 1.0
weight值显示这个信息有多可信。一个典型的权重是1.0,当信息来自更多的来源或更可靠的来源时,这个数字会更高。
dataset
dataset值是在ConceptNet构建的过程中记录使用的,并不是很重要。
术语的层级
这些术语(term)的URI(或者叫这些概念(concept)的URI)。都是由/c/开始,并且遵循一个从语言(zh, en,...)到术语(term)再到术语的词性(senses of terms)的层次结构。例如这个术语/c/it/esempio/n代表意大利语的名词 "esempio"。
而/c/it/esempio就仅仅代表意大利语的"esempio",不管是不是名词。当你浏览/c/it/esempio/n的时候可以得到这个结果。任何术语URI都隐式地包含其所有更特定的URI。
/c/it代表所有意大利语的ConceptNet的知识,可以浏览它来获取ConceptNet中的意大利语部分的样例。在长长的分页列表的某个地方将是/c/it/esempio/n的信息。
当/c不是一个可用的URI的时候,层级关系就结束了。
对于各种各样的URI的含义的信息,可以查看 https://github.com/commonsense/conceptnet5/wiki/URI-hierarchy 。
获取短语的URI
给你一个自然语言中的短语,你大概可以知道它的ConceptNet URI是什么。将空格替换为_,在前面加上代表语言的代码,短语"french toast" 的URI就是/c/en/french_toast。
这在ConceptNet的旧版本中是比较复杂的。
如果你想更清楚地得到一个URI,或者你是一个使用Linked Data API的计算机,那你可以向http://api.conceptnet.io/uri发送GET请求,同时带上以下参数:
text:文本language:文本的语言类型
因为是GET请求,这些参数最终被编码在URI中:http://api.conceptnet.io/uri?language=en&text=french+toast
可以查询的其他内容
ConceptNet中的其他对象也有URI。
就像之前提到的,你可以通过URI /a/[/r/UsedFor/,/c/en/example/,/c/en/explain/] 来查询一个边(edge)
通过使用/r/Antonym可以查找一个关系,查看边的示例。
通过使用/s/contributor/omcs/dev来查询一个来源(source)获得它贡献的边(edges)
复杂查询
为了过滤一些特定的信息,可以通过向 http://api.conceptnet.io/query传递参数,然后就会得到符合条件的边(edge)的列表。
你可以指定任意下面的参数:
start:start或subject位置必须匹配的URIend:end或者object位置必须匹配的URIrel:一个关系node:必须与开始(start)或者结束(end)匹配的URIother:必须与开始(start)或者结束(end)匹配的URI,并且与node不同sources:必须与边(edge)的源(source)之一匹配的URI
查看连接dog和dark的所有关系/query?node=/c/en/dog&other=/c/en/bark
查看原始的 OMCS dev team 记录的关于ferrets的信息/query?node=/c/en/ferret&sources=/s/contributor/omcs/dev
查看日语中的所有关于猫的断言/query?node=/c/ja/猫&other=/c/ja
下面有一个例子是在python中使用这个API获取与ConceptNet中的"apple"联系的所有的外部连接数据(external Linked Data)
查询相关术语(term)
这个API使用从ConceptNet和其他输入构建的词嵌入(word embedding)来查找相关术语(related terms)。这个词嵌入(word embedding)是ConceptNet Numberbatch(https://github.com/commonsense/conceptnet-numberbatch)的一个版本,减少了一些词汇量来适应网络传输。
例如,查找"tea kettle"相关的术语,/related/c/en/tea_kettle (http://api.conceptnet.io/related/c/en/tea_kettle)
{
"@id": "/c/en/tea_kettle",
"related": [
{
"@id": "/c/en/tea_kettle",
"weight": 1.0
},
{
"@id": "/c/en/teakettle",
"weight": 0.771
},
{
"@id": "/c/nl/ketel",
"weight": 0.723
},
{
"@id": "/c/ja/釜",
"weight": 0.718
},
{
"@id": "/c/zh/水壶",
"weight": 0.712
},
...
]
}
默认这个返回结果将包含ConceptNet的核心语言(https://github.com/commonsense/conceptnet5/wiki/Languages)中的任意10个。可以使用filter参数获取指定语言的数据。因此,"tea kettle"最接近的英文条目是/related/c/en/tea_kettle?filter=/c/en
一组特定术语之间的关联值
/relatednessAPI和/related很想,但是前者并不是返回查询的相关的术语的列表,而是返回一组指定术语的关联值(relatedness value )
例子:
/relatedness?node1=/c/en/tea_kettle&node2=/c/en/coffee_pot (http://api.conceptnet.io/relatedness?node1=/c/en/tea_kettle&node2=/c/en/coffee_pot)
{
"@id": "/relatedness?node1=/c/en/tea_kettle&node2=/c/en/coffee_pot",
"value": 0.543
}
本地 python API
如果你的计算机上安装了ConceptNet的代码和数据,你也可以通过Python的AssertionFinder.lookup()和AssertionFinder.query()方法访问这个API。
>>> from conceptnet5.db.query import AssertionFinder
>>> cnfinder = AssertionFinder()
>>> cnfinder.lookup('/c/en/example')
[... lots of edges ...]
>>> cnfinder.query({'node': '/c/en/example'})
[... the same edges ...]
版本信息
在ConceptNet 5.5版本中,重构了API以支持JSON-LD数据格式,并且让每个术语的URI更加明显(意思应该是类似上面的获取短语的URI中的可以更容易地从自然语言的术语猜出它的URI吧)。ConceptNet 5.1 到 5.4 版本的API稍有不同,可以在 https://github.com/commonsense/conceptnet5/wiki/API/2349f2bbd1d7fb726b3bbdc14cbeb18f0a40ef18 位置查看它们的历史文档。
速度限制
每个小时你可以向ConceptNet发送3600个请求。峰值是每分钟120个请求。related和relatedness是作为两个请求来算的。
这意味着需要好好设计对API的使用,平均每秒不超过一个请求。
参考
ConceptNet官网 http://conceptnet.io/
知识图谱相关的名词解释 http://wp.openkg.cn/?p=105
什么是JSON-LD http://wp.openkg.cn/?p=69
什么是知识图谱 http://wp.openkg.cn/?p=119
Knowledge Base https://blog.diffbot.com/knowledge-graph-glossary/knowledge-base/
MIT - ConceptNet5的中文部分-截至2017年1月 http://openkg.cn/dataset/conceptnet5-chinese
ConceptNet — A Practical Commonsense Reasoning Tool-Kit https://agents.media.mit.edu/projects/commonsense/ConceptNet-BTTJ.pdf
API文档(文中有一大部分由此翻译而来) https://github.com/commonsense/conceptnet5/wiki/API

 浙公网安备 33010602011771号
浙公网安备 33010602011771号