编译原理 | 实验一 | 设计词法分析器
目录
一.题目
如源程序为C语言,输入如下一段:
main()
{
int a=-5, b=4, j;
if(a>=b)
j=a-b;
else
j=b-a;
}
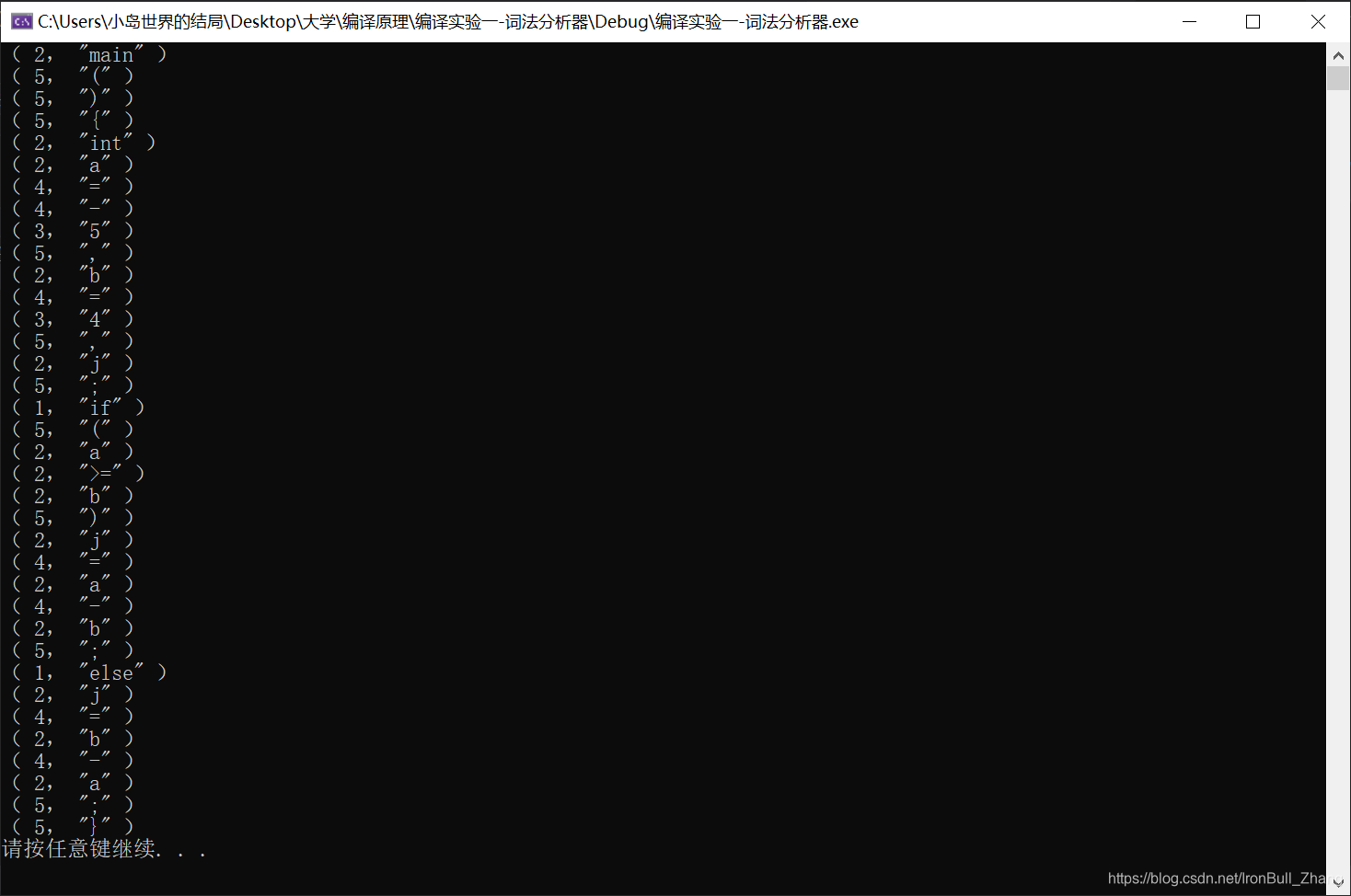
输出以下二元序列:

其中,序号分别意味着:

二.问题分析
分两步走:
1.将语句分成若干单独的元素. 这个问题是最关键的.
2.将每个元素分门别类,输出.
分词子问题:
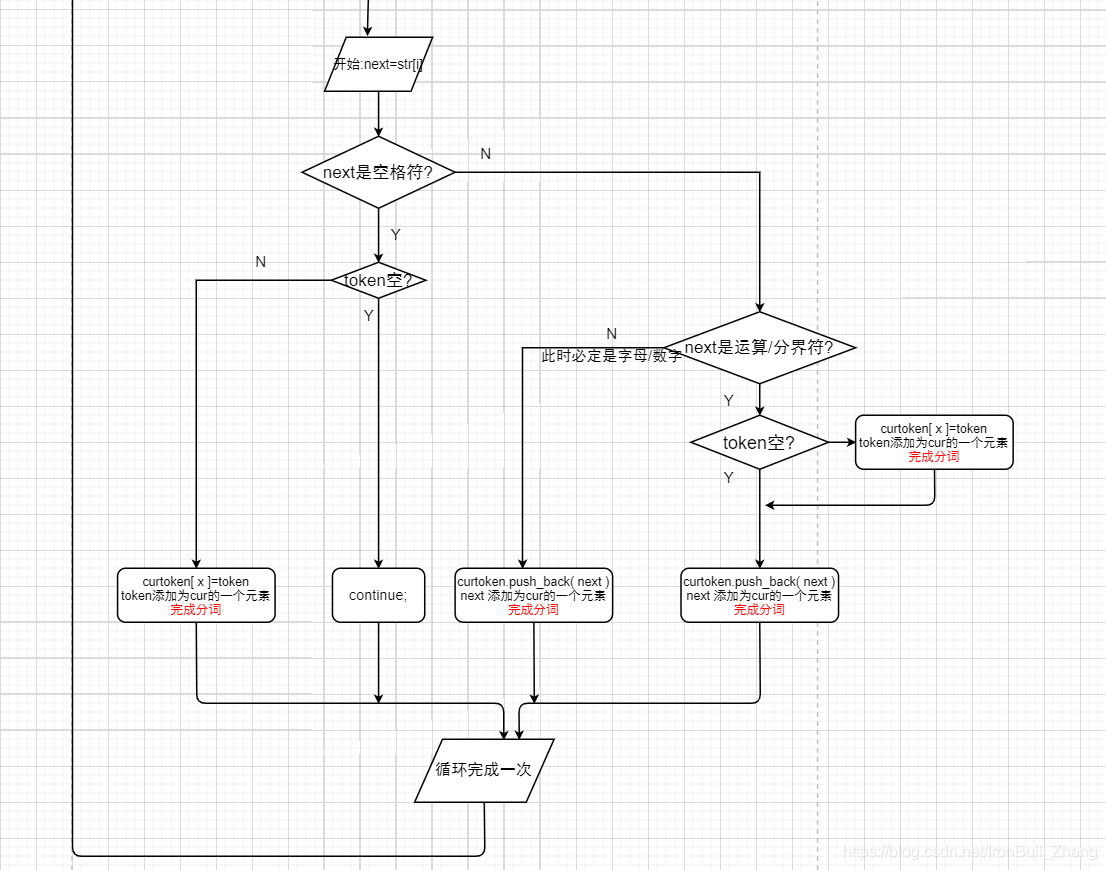
在遍历字符串( 一行代码 )的过程中,遇到空格、换行符、tab、限界符、单独的运算符, 分词
遇到字母或数字, 不分词.
为了实现这一效果,设立
一个 char 类型的变量,时刻指向readline字符串中的下一个字符
同时建立各个判别函数,如IsBlock() IsSymbol() 等.
对代码文件的每一行,都有:
三.代码实现
1.头文件 & 类的声明
using namespace std;
#include<iostream>
#include<fstream>
#include<string>
#include<vector>
class LexicalAnalysis
{
public:
LexicalAnalysis(); //构造&析构是空函数
~LexicalAnalysis();
void GetFilename(ifstream& filename); //打开文件
void InputFile(ifstream& file); //输入文件,,分析经Segment处理的curtoken向量
void Segment(string str); //将字符串(一行)分为独立的词,不涉及词性分析
//分词,将字符串分为若干段 ( 不包括空格符 ) ,存入curtoken[]
bool IsBlock(string); //换行,空格,制表符. 应当分词
bool IsSymbol(string); //是运算符,分隔符等. 应当分词
//词性分析
bool IsKey(string); //关键字
bool IsConsts(string); //常数
bool IsOperator(string); //操作数
bool IsBorder(string); //限界符
private:
vector <string> token; //暂存一个个字符,用于分词
string temp; //暂存当前token的全部字符,作为curtoken的一个元素
vector<string>curtoken; //暂存一个个分好的词,用于之后的词性分析
};2.各种判断函数
一通分类判断完以后,剩下的只可能是变量名:由字母 / 字母+数字组成
//关键字判断
bool LexicalAnalysis::IsKey(string str)
{
string a[] ={ "if","else","for","break","continue","int","float","double","auto","case","char","const","default","do","enum","long","extern","goto","register","return","short","signed","sizeof","static","struct","switch","typedef","union","unsigned","void","volatile","while" };
for (size_t i = 0; i < a->size(); i++)
{
if(a[i]==str)
{
return true; //此时已终止函数,无需写break;
}
}
return false;
}
//常量判断
bool LexicalAnalysis::IsConsts(string str)
{
if (str == "true" || str=="false") //判断是否是字符型常量
{
return true;
}
else
{
for (size_t i = 0; i < str.size(); i++) //判断是否是数值型常量
{
if (str[i] < '0' || str[i]>'9')
{
return false;
}
}
return true;
}
}
//空格,tab符判断
bool LexicalAnalysis::IsBlock(string str)
{
//换行 换行 tab 空格
if (str == "\n" || str == "\r" || str == "\t" || str == " ")
{
return true;
}
else
{
return false;
}
}
//边界符判断
bool LexicalAnalysis::IsBorder(string str)
{
string border[] = { "," , ";" , "{" ,"}" , "(" , ")" , "[" , "]" , "#" , "." , "%" , "\"" };
for (size_t i = 0; i < 12; i++)
{
if (border[i] == str)
{
return true;
}
}
return false;
}
//操作符判断
bool LexicalAnalysis::IsOperator(string str)
{
string arithmetic[] = { "+","-","*","/","<",">","||","&&","%","=" };
for (size_t i = 0; i < 10; i++)
{
if (arithmetic[i] == str)
{
return true;
}
}
return false;
}
//调用操作符判断 & 边界符判断
bool LexicalAnalysis::IsSymbol(string str)
{
if (IsOperator(str) || IsBorder(str))
{
return true;
}
else
{
return false;
}
}3.★
文件输入函数,起初始化作用
分词函数,将每行代码分成独立的词,存到curtoken[]
input函数,将划分好的词分类Print.
void LexicalAnalysis::GetFilename(ifstream& file)
{
string filename = "program.txt";
file.open(filename);
if (!file)
{
cout << "文件不存在" << endl;
}
}
void LexicalAnalysis::InputFile(ifstream& file)
{
string readline; //每次读取的一行存入该string
while (getline(file,readline)) //将file的当前行--->readline, 并且将this指针下移一行,直至末尾
{
Segment(readline);
}
//对curtoken向量做合并处理,专用于判别2字符运算符: <=, >=, ==, !=, *=, /=
for (vector<string>::iterator it=curtoken.begin();it!=curtoken.end()-1;it++)
{
if ((*(it + 1) == "=") && IsOperator(*it))
{
*it += *(it + 1);
curtoken.erase(it + 1);
}
if ((*(it + 1) == "&") && (*(it) == "&")||
(*(it + 1) == "|") && (*(it) == "|") ||
(*(it + 1) == ":") && (*(it) == ":")
) //专用于判别2字符运算符: && || ::
{
*it += *(it + 1);
curtoken.erase(it + 1);
}
}
for (size_t i = 0; i < curtoken.size(); i++)
{
if (IsKey(curtoken[i]))
{
cout << "( 1, "<<"\""<<curtoken[i]<<"\""<<" )" << "\n";
}
else if (IsConsts(curtoken[i]))
{
cout << "( 3, " << "\"" << curtoken[i] << "\"" << " )" << "\n";
}
else if (IsOperator(curtoken[i]))
{
cout << "( 4, " << "\"" << curtoken[i] << "\"" << " )" << "\n";
}
else if (IsBorder(curtoken[i]))
{
cout << "( 5, " << "\"" << curtoken[i] << "\"" << " )" << "\n";
}
else //剩下的只可能是常量名,变量名
{
cout << "( 2, " << "\"" << curtoken[i] << "\"" << " )" << "\n";
}
}
}
void LexicalAnalysis::Segment(string str) //将每一行的各个词分开,存入curtoken向量
{
string next;
for (size_t i = 0; i < str.size(); i++) //将一行从头到尾分析
{
next = str[i]; //每次读取一个字符
if (IsBlock(next)) //空格符,制表符检查
{
if (!token.empty()) //非空,则将token添加为 curtoken[]的一个元素
{
temp.clear();
for (size_t i = 0; i < token.size(); i++)
{
temp += token[i];
}
curtoken.push_back(temp);
token.clear(); //使用完token,清空.等待下一次使用
}
else
{
continue; //说明碰到了空格,且无toekn值. 跳过本次循环
}
}
else if (IsSymbol(next)) //运算符,边界符检查
{
if (!token.empty()) //当前token,非空,添加为curtoken[]的一个元素
{
temp.clear();
for (size_t i = 0; i < token.size(); i++)
{
temp += token[i];
}
curtoken.push_back(temp);
token.clear();
curtoken.push_back(next);
}
else
{
curtoken.push_back(next);
}
}
else //下一个遇到的是字母/数字,添加到token就行
{
token.push_back(next);
}
}
}
4.main()
int main()
{
LexicalAnalysis la;
ifstream file;
la.GetFilename(file);
la.InputFile(file);
system("pause");
return 0;
}
运行结果:
四.技巧总结
1.文件的读取:
file是ifstream对象,已经打开一个文件
string readline; //每次读取的一行存入该string
while (getline(file,readline)) //将file的当前行--->readline, 并且将this指针下移一行,直至末尾
{
....
}2.string 对象的赋值
vector <string> token;
string temp;
vector<string>curtoken;想要将token的全部元素作为一个整体,赋给temp.可以使用+=:
for (size_t i = 0; i < token.size(); i++)
{
temp += token[i];
}
curtoken.push_back(temp);3.token在每次被读取后要清空,以便读取下一个分词.
temp变量也应该随用随清.
4.对于"==","<=","+="等二字符运算符,在
分词程序Segment()之后,词性判别程序之前
对curtoken向量中的元素进行重新合并
//对curtoken做合并处理,专用于判别2字符运算符: <=, >=, ==, !=, *=, /=
for (vector<string>::iterator it=curtoken.begin();it!=curtoken.end()-1;it++)
{
if ((*(it + 1) == "=") && IsOperator(*it))
{
*it += *(it + 1);
curtoken.erase(it + 1);
}
if ((*(it + 1) == "&") && (*(it) == "&")||
(*(it + 1) == "|") && (*(it) == "|") ||
(*(it + 1) == ":") && (*(it) == ":")
) //专用于判别2字符运算符: && || ::
{
*it += *(it + 1);
curtoken.erase(it + 1);
}
}体现了分步完成工作的思想.
五.不足
1.对意外字符的考虑不够周全.比如★这类字符.重构时应该考虑进去

 浙公网安备 33010602011771号
浙公网安备 33010602011771号