数据质量分析
一、实验目的:
- 读取catering_sale.csv信息,输出最大值、最小值、平均值
- 统计缺失的变量和样本个数
- 通过箱式图判断异常点,并显示疑似异常点的销量值。
二、实验过程
对catering_sale.csv进行分析,catering_sale.csv是这样的:
1. 读取catering_sale.csv信息,输出最大值、最小值、平均值
data = pd.read_csv('catering_sale.csv')
# describe()可以得到数据相关参数,比如最大值、最小值
descriptor = data.describe()['销量']
# 销量最大值
max_value = descriptor['max']
# 销量最小值
min_value = descriptor['min']
# 销量平均值
mean_value = descriptor['mean']
print("销量最大值:", max_value)
print("销量最小值:", min_value)
print("销量平均值:", mean_value)
输出:

2. 统计缺失的变量和样本个数
# 样本个数
count_sample = data['销量'].shape[0]
# 缺失值个数
count_missing = data['销量'].isnull().sum()
print("样本个数:", count_sample)
print("销量缺失值个数:", count_missing)
输出:

3. 通过箱式图判断异常点,并显示疑似异常点的销量值。
ata.dropna(axis=0, how='any') #删除确实值的行
plt.rcParams['font.sans-serif'] = ['SimHei'] #显示正常中文标签
plt.rcParams['axes.unicode_minus'] = False #显示正常正负号
plt.figure()
p = data.boxplot(return_type='dict') #画箱线图
x = p['fliers'][0].get_xdata() # 'flies'即为异常值的标签
y = p['fliers'][0].get_ydata()
y.sort()
for i in range(len(x)):
if i>0:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.08,y[i]))
plt.show() #展示箱线图
显示的箱形图如下:
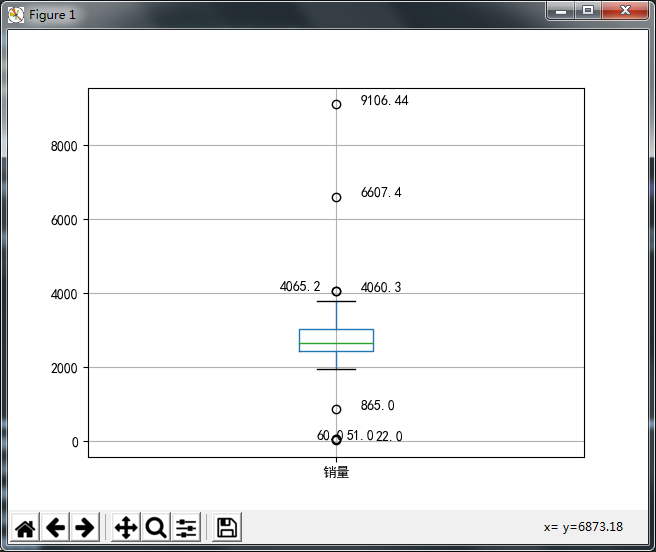
图中中间的5个圆圈就是异常点。
posted on 2021-03-13 13:24 FreestyleCoding 阅读(264) 评论(4) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号