某校某院学生信息分析
1. 分析设计
数据分析首先要明确分析什么内容和思路。
这里对某师范院校某院的学生信息进行分析,主要分析:学生男女比例、学生年龄比例、学生来自的省份比例、星座比例。
分析思路很简单,遍历所有的学生信息,然后统计出男女各多少人、不同年龄的各多少人、来自不同省份的各多少人,然后图形化展示出来。
2. 数据收集
要分析上述这些信息,先要有数据才行,所以先要获取数据。
数据获取可以自己去爬,也可以通过自己的渠道获取,也可以自己瞎编。。。。
对于这篇文章使用的数据,通过某渠道获取的,是以csv文件的形式。
3. 数据处理
一般数据处理需要清洗数据,如选择子集、列名重命名、删除重复值、缺失值处理、一致化处理、数据排序、异常值处理...。
这里的数据原本就是很干净的,在分析上述需求需要处理的地方很少,由于这里的所有学生信息是包含在一张表里面的,所以对于不同年级,需要选择子集,不同的年级分别处理。
按不同年级分离数据:
下面代码就是通过学号前4位来分离出不同年级的学生:
columns = ['学号','姓名','学院','身份证号','生日']
total_stu_data = pd.read_csv('stu_info.csv')
total_stu_data.columns = columns
total_stu_data.set_index(columns[0])
# 从总的学生信息取出子集,分离出各个年级的学生
stu_data_2016 = total_stu_data.loc[[str(row).startswith("2016") for row in total_stu_data[columns[0]]],]
stu_data_2017 = total_stu_data.loc[[str(row).startswith("2017") for row in total_stu_data[columns[0]]],]
stu_data_2018 = total_stu_data.loc[[str(row).startswith("2018") for row in total_stu_data[columns[0]]],]
stu_data_2019 = total_stu_data.loc[[str(row).startswith("2019") for row in total_stu_data[columns[0]]],]
stu_data_2020 = total_stu_data.loc[[str(row).startswith("2020") for row in total_stu_data[columns[0]]],]
数据的封装:
对于不同的数据比较零散,根据面向对象的设计思想,把同一年级的数据封装到一个对象中,便于传输,并且后期分析时,只需要分析对象就行了。
该对象应包含:该年级男女人数、该年级不同出生年份的学生多少人、该年级来自不同省份各有多少人、不同星座各有多少人,而且不同年级对象应该可以进行整合到一起,因此需要一个merge方法,将多个Grade对象整合成一个对象。
这里用于保存数据的年级类Grade设计如下:
class Grade():
def __init__(self=None, name=None,size=0,sex=None,birth=None,constellation=None,province=None) -> None:
self.name = name
self.size = size
if sex is None:
self.sex = {}
else:
self.sex = sex
if birth is None:
self.birth = {}
else:
self.birth = birth
if constellation is None:
self.constellation = {}
else:
self.constellation = constellation
if province is None:
self.province = {}
else:
self.province = province
def __str__(self) -> str:
return f"Grade[size={self.size}, name={self.name}, \
sex={self.sex}, birth={self.birth}, \
constellation={self.constellation}, province={self.province}]"
def merge(self, grades:tuple):
for grade in grades:
self.size += grade.size
self.sex = self.__merge_dict(self.sex, grade.sex)
self.birth = self.__merge_dict(self.birth, grade.birth)
self.constellation = self.__merge_dict(self.constellation, grade.constellation)
self.province = self.__merge_dict(self.province, grade.province)
return self
def __merge_dict(self, d1:dict, d2:dict) -> dict:
new_dict = d1.copy()
for key in d2:
if(key in new_dict):
new_dict[key] += d2[key]
else:
new_dict[key] = d2[key]
return new_dict
4. 数据分析
数据准备好了,就可以进行分析了。
思路很简单,首先是要分析表格数据,然后将分析好的数据存入上面说的Grade年级对象中。
也就是遍历同一个年级表格所有行,每一行都是一位学生的信息,然后把学生信息经过统计,放入一个Grade对象中。
这里,将表格数据统计封装成对象的过程封装到一个函数里面,代码如下:
def get_grade_info(grade_name:str, data_set:DataFrame) -> Grade:
"""
将一个DataFrame,进行统计,一个Grade对象
Grade对象包括了一个年级的
名称:name
总人数:size
男女人数:sex,字典类型{0:女生人数,1:男生人数}
各个年龄人数:birth,字典类型{出生年份:人数}
各个省份人数:province{省份:人数}
各个星座人数:
"""
grade = Grade(grade_name)
# row_data : [学号 '姓名' '专业' '身份证号' '生日']
for row_data in data_set.values:
# 分析身份证号
info = validator.get_info(row_data[3])
# 如果该身份证不合法
if(info == False):
continue
grade.size += 1
# 分析该学生性别
sex = int(info['sex'])
if(sex in grade.sex):
grade.sex[sex] += 1
else:
grade.sex[sex] = 1
# 分析出生年份
birth = int(info['birthday_code'][0:4])
if(birth in grade.birth):
grade.birth[birth] += 1
else:
grade.birth[birth] = 1
# 分析星座
constellation = info['constellation']
if(constellation in grade.constellation):
grade.constellation[constellation] += 1
else:
grade.constellation[constellation] = 1
#分析省份
# address_tree格式:['省', '市', '县/区']
province = info['address_tree'][0]
if(province in grade.province):
grade.province[province] += 1
else:
grade.province[province] = 1
return grade
当完成不同年级对象的封装后,查看封装后的对象,就基本已经分析完毕了,每个年级对象Grade已经包含了我们需要的所有数据:男女人数、不同出生年份的学生人数、不同省份各人数、不同星座人数。。。
5. 数据展现
当把数据封装到Grade对象后,Grade对象已经包含了所有需要分析的内容了,比如下面是其中一个Grade对象的内容(为了方便看,改成dict格式了):
{'name': '2016',
'size': 428,
'sex': {
'1': 192,
'0': 236
},
'birth': {
'1999': 39,
'1998': 208,
'1997': 125,
'1996': 46,
'1995': 5,
'2000': 3,
'1993': 1,
'1994': 1
},
'constellation': {
'巨蟹座': 23,
'狮子座': 49,
'白羊座': 28,
'摩羯座': 31,
'金牛座': 29,
'射手座': 35,
'天蝎座': 42,
'双子座': 37,
'天秤座': 45,
'双鱼座': 38,
'水瓶座': 32,
'处女座': 39
},
'provence': {
'湖北省': 330,
'黑龙江省': 3,
'安徽省': 9,
'贵州省': 5,
'河北省': 1,
'江苏省': 4,
'云南省': 6,
'山东省': 3,
'山西省': 9,
'陕西省': 2,
'四川省': 11,
'浙江省': 2,
'湖南省': 5,
'广东省': 1,
'江西省': 3,
'广西壮族自治区': 9,
'河南省': 15,
'内蒙古自治区': 1,
'重庆市': 4,
'甘肃省': 2,
'福建省': 2,
'天津市': 1
}
}
所有需要展示的数据都封装到了Grade对象中了。
只需要把构建好的Grade对象,分别展示出来,
学生性别比例:
性别比例,在Grade对象的sex属性中,sex属性是一个dict,包含了男女的人数。
'sex': {
'1': 192,
'0': 236
}
把每个年级的Grade对象中的sex属性都取出来,然后可视化如下:
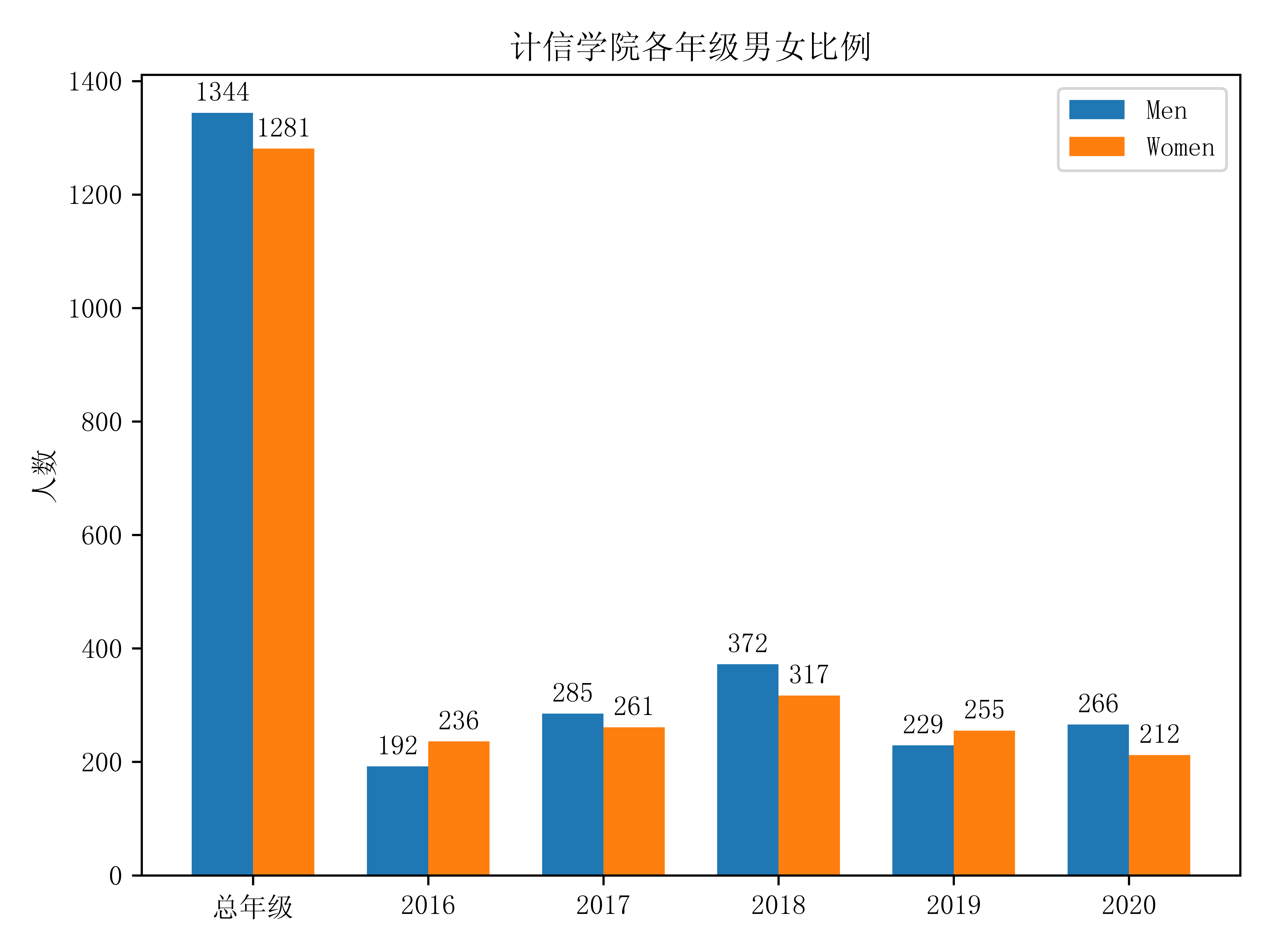
上图可以看出该校该学院学生的男女比例还是比较平均的。。。
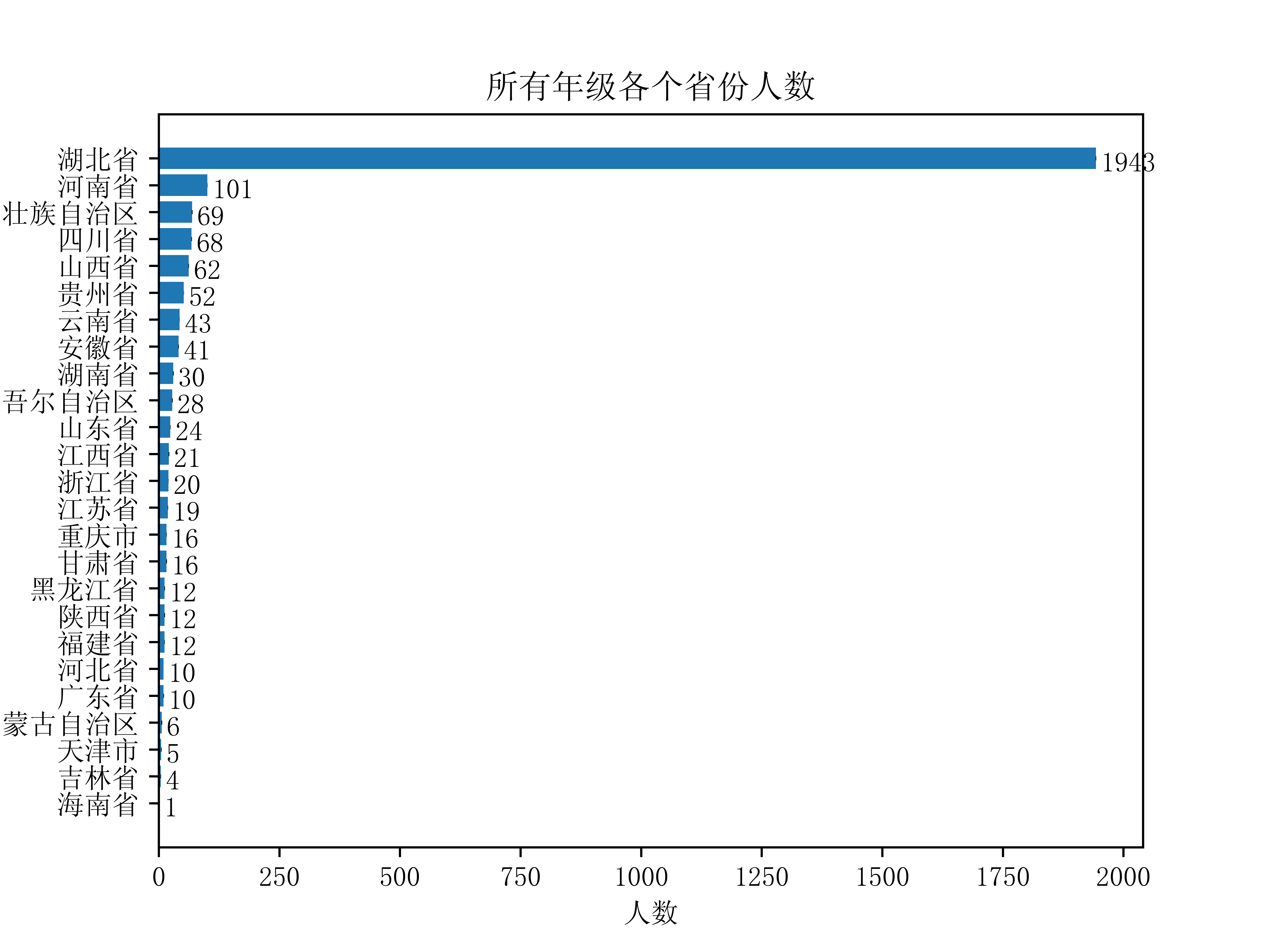
学生来自的省份
同样的,获取学生来自的省份的数据,也只需要从Grade对象中取出province属性即可,可视化如下图:
不同学院的学生年龄(出生年份):
获取学生的出生年份,只需从不同的Grade对象取出birth属性即可,可视化如下图:
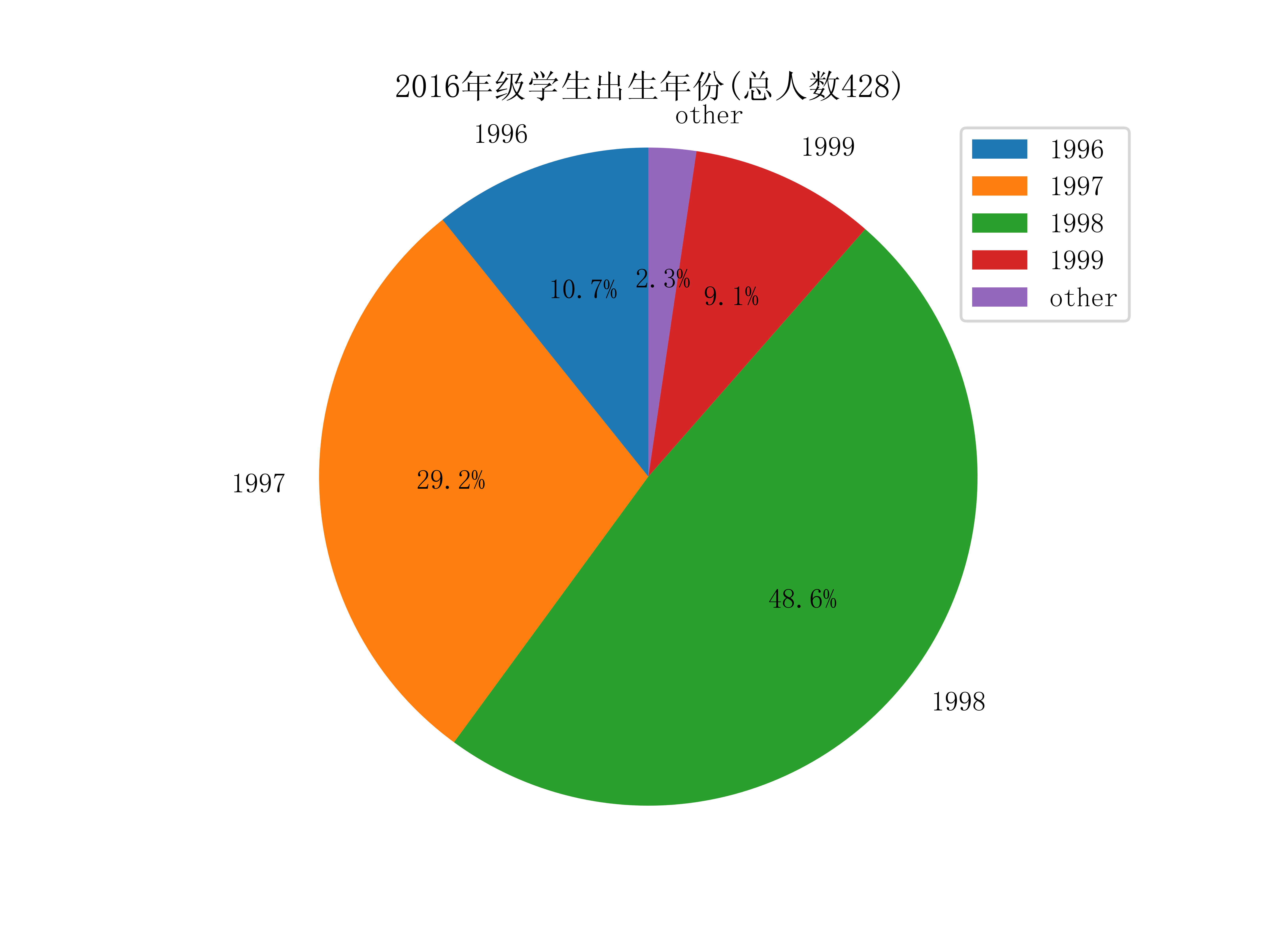
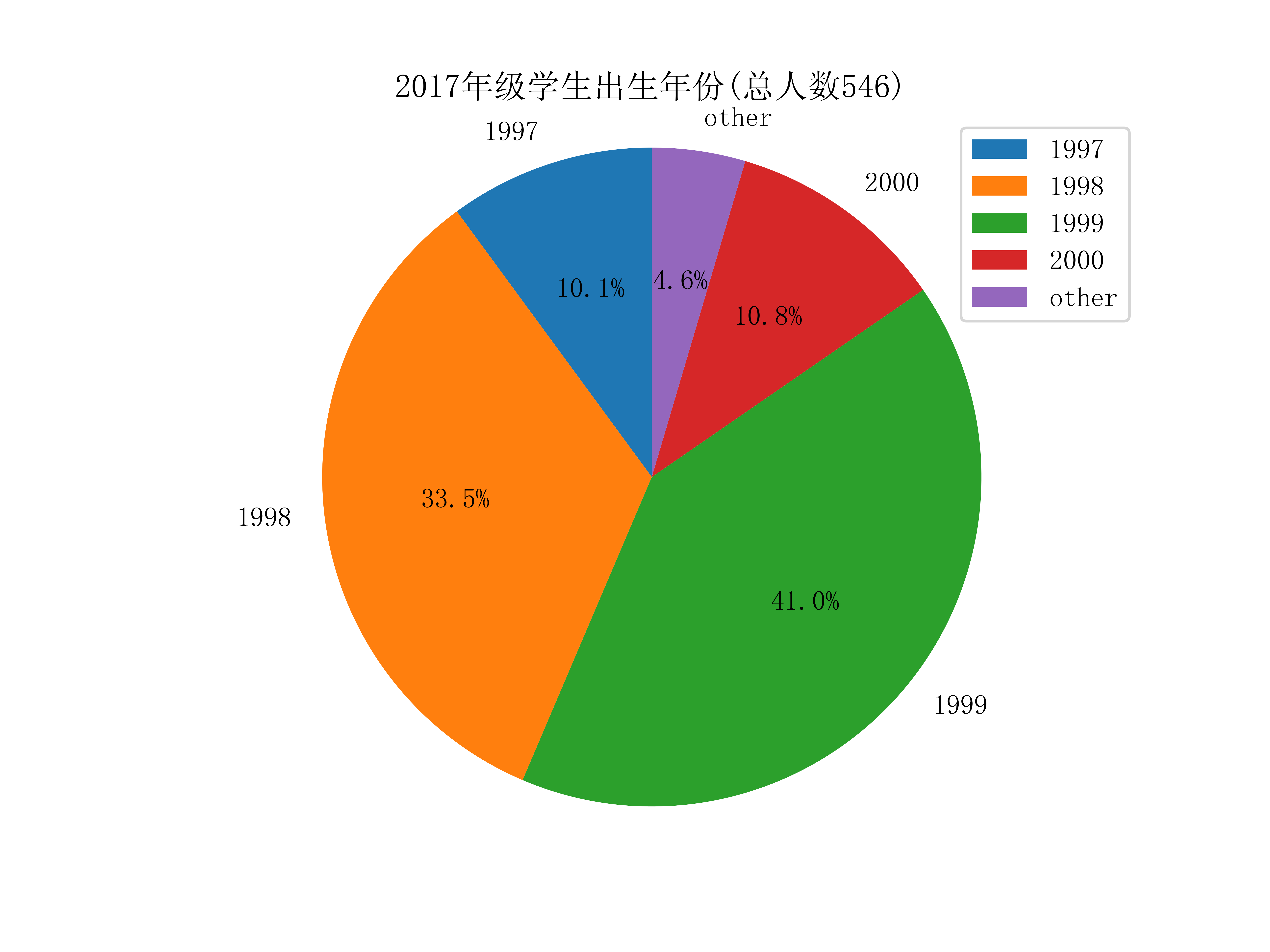
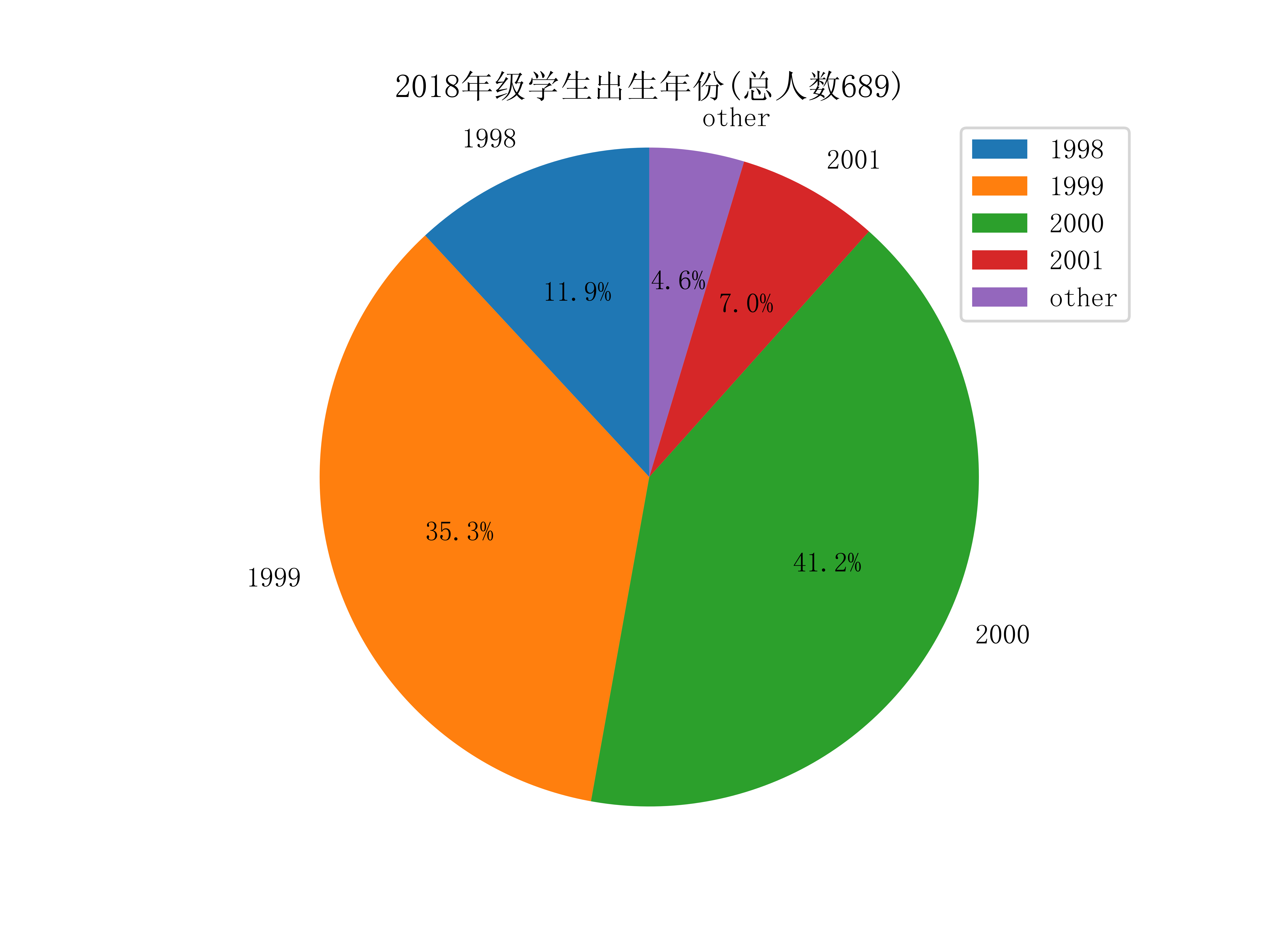
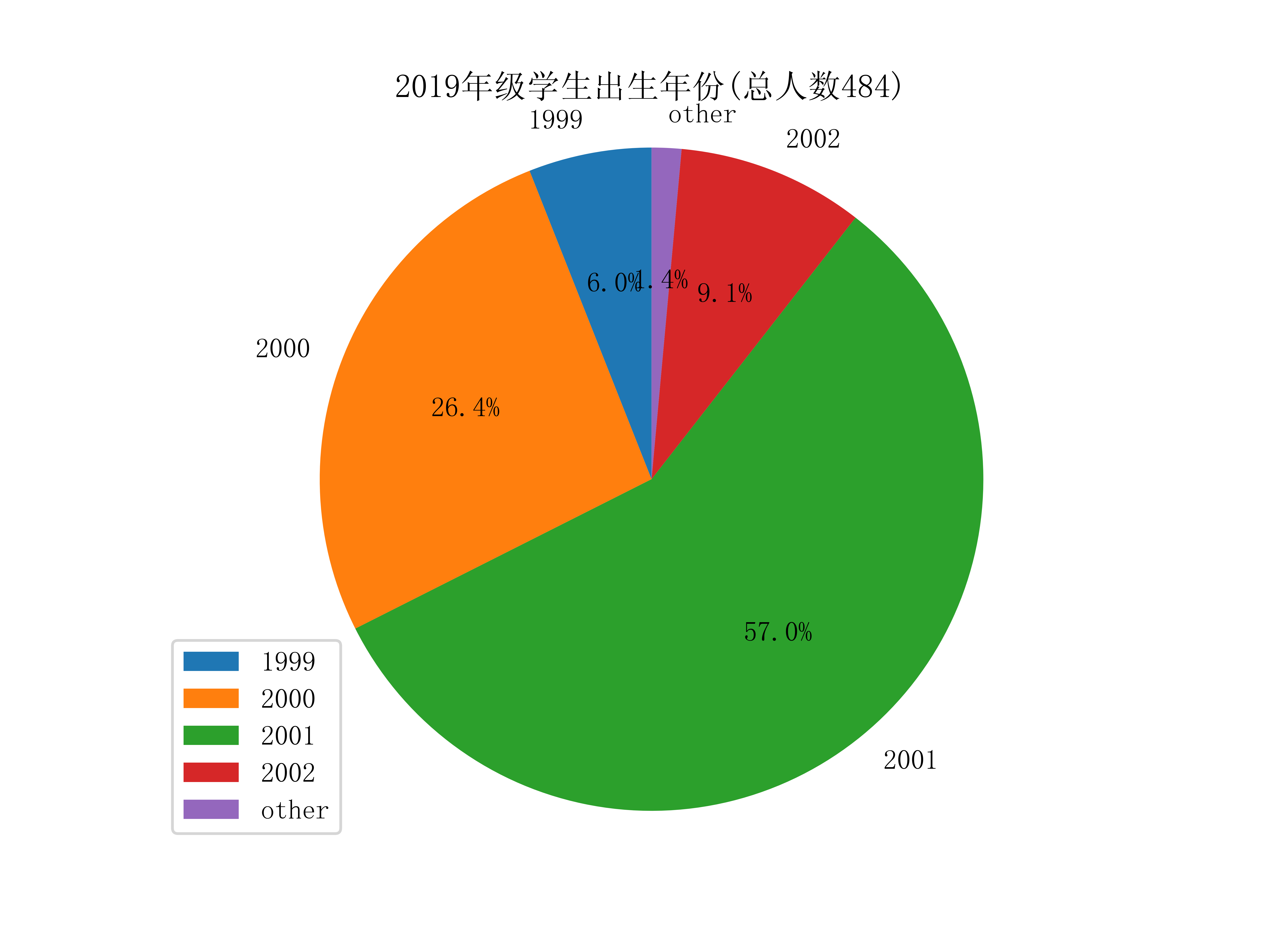
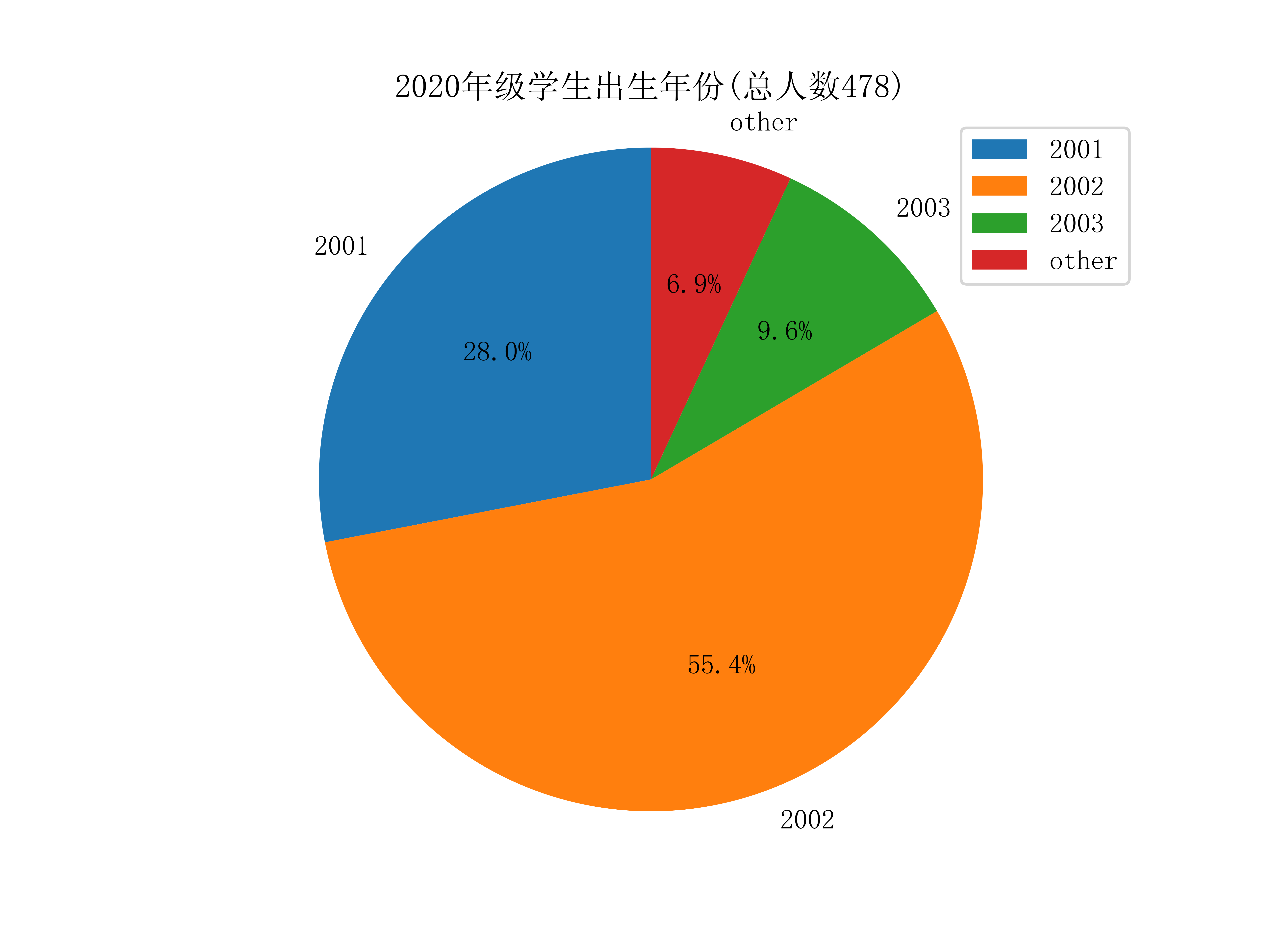
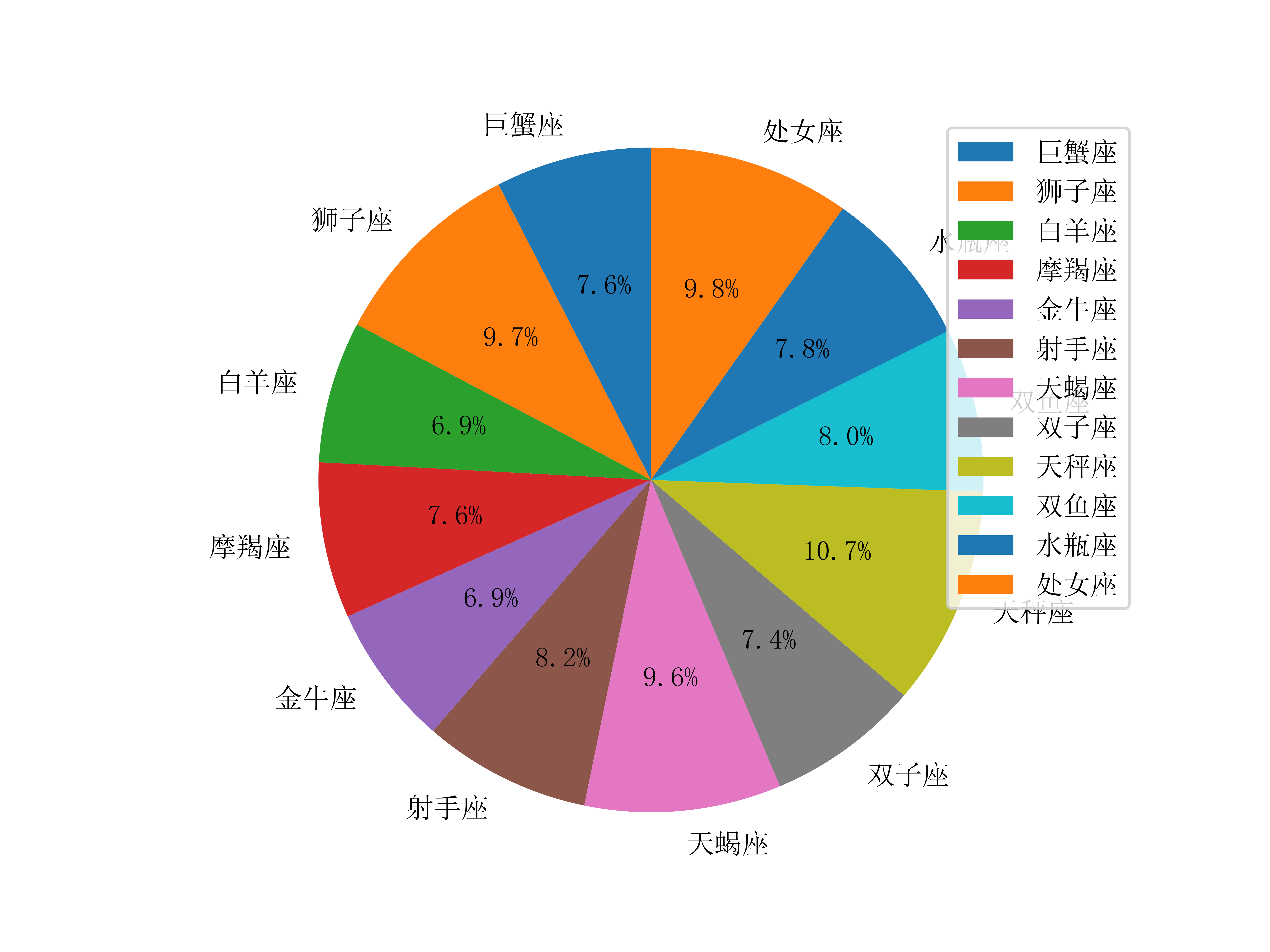
学生的星座比例:
星座比例数据也是如此,从Grade对象中取出constellation属性即可,由于这个星座的数据在不同年级中都比较均匀,这里只展示全院的星座比例。
6. 总结
上述就是分析某校某院学生信息的过程,主要是提出去每个学生的信息(表格的每一行)进行统计(主要是统计男女人数、来自的省份、出生年份),然后把统计好的数据封装成一个对象(一个年级的数据封装到一个Grade对象中),数据封装完就已经分析完毕了。后面再把数据从Grade对象中取出,可视化表示。
posted on 2021-01-06 14:38 FreestyleCoding 阅读(198) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号