ZYNQ中PL和PS协同工作的几种机制
1、PL与PS协同工作的几种机制
在Xilinx Zynq SoC中,FPGA(PL,可编程逻辑)和ARM处理器(PS,处理系统)的协同工作主要通过以下几种机制实现,其中DDR内存确实扮演了重要角色:
(1)、共享DDR内存(主要数据交互方式)
机制:
PS和PL通过AXI总线(如AXI HP/AXI ACP接口)共享DDR内存。
FPGA通过AXI HP(高性能)或AXI ACP(加速器一致性端口)直接访问DDR,无需CPU干预。
CPU(ARM)将数据写入DDR,FPGA通过DMA读取处理后再写回DDR,CPU读取结果。
优势:
适合大数据量传输(如图像、视频处理)。
利用DMA减少CPU负载。
典型应用:
视频帧处理:CPU准备数据→存入DDR→FPGA加速处理→结果写回DDR→CPU读取。
(2)、片上共享资源(低延迟交互)
OCM(On-Chip Memory):
PS的片上RAM(256KB),PL可通过AXI GP接口访问PS的片上内存(OCM)。
特点:延迟极低(~10ns),适合小数据量实时交互(如控制参数、状态字)。
实现:在Vivado中配置AXI总线连接OCM,PS/PL通过地址直接读写。
BRAM(FPGA内部存储器):
FPGA内部的存储器,可通过AXI BRAM控制器映射到PS地址空间,CPU直接访问FPGA内部的BRAM。
特点:灵活性高,PL可快速读写,PS通过内存映射访问(类似外设寄存器)。
典型应用:共享查找表(LUT)、小型缓冲区。
(3)、寄存器级交互(控制/状态通信)
AXI Lite总线:
PS通过AXI Lite配置FPGA内部的寄存器(如启动/停止加速器、读取状态)。
适合低频控制信号(如设置参数、中断触发)。
中断机制:
FPGA通过IRQ通知PS任务完成或异常(如DMA传输完成)。
自定义IP核寄存器:
在PL中设计寄存器映射的IP核,PS通过AXI Lite直接读写。
(4)、流式数据传输(无DDR参与)
AXI Stream:
PS和PL通过AXI Stream直接传输数据流(如视频流、ADC采样数据)。
无需DDR中转,实时性高,但需FPGA设计流处理逻辑。
实现:
使用AXI DMA IP核将流数据与PS内存(如OCM)交换。
或PS通过AXI Stream FIFO直接与PL交互。
(5)高速接口(专用链路)
HP(High Performance)或ACP(Accelerator Coherency Port)接口:即使不通过DDR,HP/ACP接口也可用于PL与PS Cache的直接通信(ACP支持缓存一致性)。
优势:降低访问延迟,避免DDR带宽竞争。
(6)中断与事件通知
PL-to-PS中断:PL通过IRQ通知PS(如任务完成、错误触发)。
实现:
在Vivado中连接PL中断信号到PS的IRQ控制器。
PS端注册中断服务程序(ISR)。
(7)处理器本地总线(PLB)或专用接口
GPIO/EMIO:将PL信号通过EMIO导出到PS的GPIO,适合极简控制(如复位信号、状态灯)。
自定义协议:在PL中实现SPI/I2C等串行协议,与PS通信(需PS端驱动支持)。
2、协作模式总结
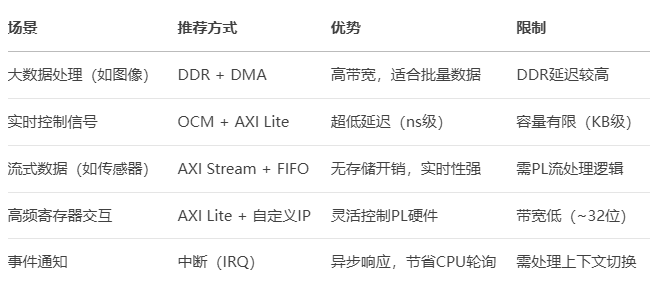
3、设计示例
(1)视频处理流水线:CPU初始化帧数据→存入DDR→FPGA通过DMA读取→硬件加速(如滤波)→结果写回DDR→CPU显示。
(2)实时控制:FPGA通过AXI Lite接收CPU参数→处理传感器数据→通过中断通知CPU。
4、关键配置步骤
在Vivado中启用AXI HP/ACP接口。
为PL分配DDR内存区域(通过xparameters.h定义地址)。
使用DMA控制器(如AXI DMA IP)管理数据传输。
在Linux中可映射DDR内存为mmap,或使用裸机程序直接访问。
通过合理选择交互方式,可以平衡带宽、延迟和资源开销,实现高效的PS-PL协同计算。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号