
5、 LwIP 的内存管理
1 、几种内存分配策略
LwIP 本质就是对数据的处理,网络中的数据是非常多的,那么 LwIP 对这些数据的处理必然是需要消耗系统资源的,而有好的内存管理策略就显得非常必要了,内存分配策略、内存分配效率等都是衡量系统性能的重要因素。
常见的内存分配策略有两种,一种是分配固定大小的内存块;另一种是利用内存堆进行动态分配,属于可变长度的内存块。
这两种内存分配策略都会在 LwIP 中被使用到,他们各有所长, LwIP 的作者根据不同的应用场景选择不同的内存分配策略,这样子使得系统的内存开销、分配效率等都得到很大的提高。 此外 LwIP 还支持使用 C 标准库中的 malloc和 free 进行内存分配,但是这种内存分配我们不建议使用,因为 C 标准库在嵌入式设备中使用会有很多问题,系统每次调用这些函数执行的时间可能都不一样,这是致命的,因为内存分配中最重要的就是分配时间效率的问题。 内存分配的本质就是事先准备一大块内存堆(可以理解为一个巨大的数组),然后将该空间起始地址返回给申请者, 这就需要内核必须采用自己独有的一套数据结构来描述、记录哪些内存空间已经分配,哪些内存空间是未使用的,根据使用的机制不同,延伸出多种类型的内存分配策略。
1.1、 固定大小的内存块
使用固定大小的内存块分配策略,用户只能申请大小固定的内存块,在内存初始化的时候,系统会将所有可用的内存区域划分为 N 块固定大小的内存,然后将这些内存块通过单链表的方式连接起来,用户在申请内存块的时候就直接从链表的头部取出一个内存块进行分配,同理释放内存块的时候也是很简单,直接将内存块释放到链表的头部即可,这样子分配内存的时间就是固定的,非常高效。但是缺点也是很明显的,用户只能申请固定大小的内存块,如果内存块无法满足用户的需求,那么则无法申请成功,而如果将内存块大小变大,那么在用户需要极小的内存的时候就会造成内存的浪费,这也是不适合的。
可能会有人问了,那这种内存分配策略不好用,为什么 LwIP 作者会使用呢?其实不然, LwIP 中有很多固定的数据结构空间,如 TCP 首部、 UDP 首部, IP 首部,以太网首部等都是固定的数据结构,其大小就是一个固定的值,那么我们就能采用这种方式分配这些固定大小的内存空间,这样子的效率就会大大提高,并且无论怎么申请与释放,都不会产生内存碎片,这就让系统能很稳定地运行。这种分配策略在 LwIP 中被称之为动态内存池分配策略,内存池示意图具体见下图:
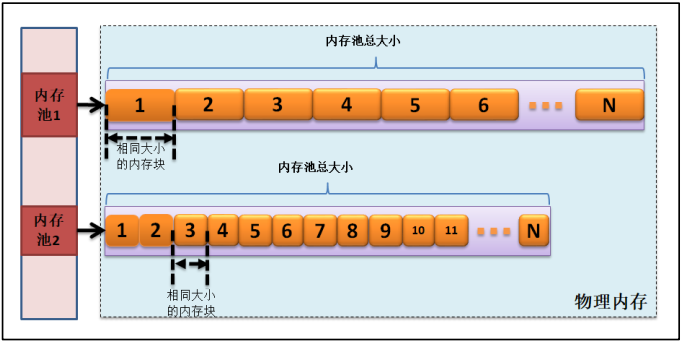
1.2、可变长度分配
这种内存分配策略在很多系统中都会被使用到,系统运行的时候,各个空闲内存块的大小是不固定的,它会随着用户的申请而改变,刚开始的时候,系统就是一块大的内存堆,随着系统的运行,用户会申请与释放内存块,所以系统的内存块的大小。数量都会随之改变,并且对于这种内存分配策略是有多种不同的算法的。
LwIP 中也会使用这种内存分配策略,它采用 First Fit(首次拟合)内存管理算法, 申请内存时只要找到一个比所请求的内存大的空闲块,就从中切割出合适的块,并把剩余的部分返回到动态内存堆中, 这种分配策略分配的内存块大小有限制,要求请求的分配大小不能小于 MIN_SIZE,否则请求会被分配到 MIN_SIZE 大小的内存空间, 一般 MIN_SIZE大小为 12 字节,在这 12 个字节中前几个字节会存放内存分配器管理用的私有数据,该数据区域不能被用户程序修改,否则导致致命问题。内存释放的过程是相反的过程,但分配器会查看该节点前后相邻的内存块是否空闲,如果空闲则合并成一个大的内存空闲块。 当然,采用这种内存堆的分配方式,在申请和释放的时候肯定需要消耗时间,可以类似地看做是以时间换空间的策略。 采用这种分配策略,其优点就是内存浪费小,比较简单,适合用于小内存的管理,其缺点就是如果频繁的动态分配和释放,可能会造成严重的内存碎片,如果在碎片情况严重的话,可能会导致内存分配不成功从而导致系统崩溃。
补充:存碎片导致系统崩溃的原因并不是因为系统没有可用内存了,而是内存块被分割成很多不连续的小内存块,当用户需要申请一个更大的内存块的时候,系统没办法提供这样子的内存块,就会导致申请失败。
当然 LwIP 也支持 C 标准库的 malloc()和 free(),因为不建议使用这种情况,所以此处我们就不做过多的讲解。
2、动态内存池(POOL)
申请大小必须是指定固定大小字节的值(如 4、 8、 16 等等),系统将所有可用区域以固定大小的字节单位进行划分,然后用单链表将所有空闲内存块连接起来。链表中所有节点大小相同,分配,释放都非常简单。
LwIP 源文件中 memp.c 和 memp.h 就是动态内存池分配策略,为什么 LWIP 需要有POOL?因为协议栈里面有大量的协议首部,这些协议首部长度都是固定不变的,所以我们可以首先分配固定内存,给这些固定长度的协议首部,以后每次需要处理协议首部的时候,都直接使用这些已经分配的内存,不需要重新分配内存区域,这样子就达到一个地方分配,多个地方使用的方便与效率。
2.1、内存池的预处理
在内核初始化时,会事先在内存中初始化相应的内存池, 内核会将所有可用的区域根据宏定义的配置以固定的大小为单位进行划分,然后用一个简单的链表将所有空闲块连接起来,这样子就组成一个个的内存池。由于链表中所有节点的大小相同,所以分配时不需要查找,直接取出第一个节点中的空间分配给用户即可。
注意了,内核在初始化内存池的时候,是根据用户配置的宏定义进行初始化的,比如,用户定义了 LWIP_UDP 这个宏定义, 在编译的时候, 编译器就会将与 UDP 协议控制块相关的数据构编译编译进去,这样子就将 LWIP_MEMPOOL(UDP_PCB,MEMP_NUM_UDP_PCB, sizeof(struct udp_pcb),"UDP_PCB")包含进去,在初始化的时候,UDP 协议控制块需要的 POOL 资源就会被初始化,其数量由 MEMP_NUM_UDP_PCB 宏定义决定, 注意了,不同协议的 POOL 内存块的大小是不一样的,这由协议的性质决定,如UDP 协议控制块的内存块大小是 sizeof(struct udp_pcb), 而 TCP 协议控制块的 POOL 大小则为 sizeof(struct tcp_pcb)。通过这种方式,就可以将一个个用户配置的宏定义功能需要的POOL 包含进去,就使得编程变得更加简便。
在这里有一个很有意思的文件,那就是 memp_std.h 文件, 该文件位于 include/lwip/priv目录下, 它里面全是宏定义, LwIP 为什么要这样子写呢, 其实很简单,当然是为了方便,在不同的地方调用#include "lwip/priv/memp_std.h"就能产生不同的效果。
该文件中的宏值定义全部依赖于宏 LWIP_MEMPOOL(name,num,size,desc),这样,只要外部提供的该宏值不同,则包含该文件的源文件在编译器的预处理后,就会产生不一样的结果。这样,就可以通过在不同的地方多次包含该文件,前面必定提供宏值 MEMPOOL以产生不同结果。可能有些人看得一脸懵逼,其实我一开始也是这样子,不得不说 LwIP源码的作者还是很厉害的。
简单来说,就是在外边提供 LWIP_MEMPOOL 宏定义, 然后在包含 memp_std.h 文件,编译器就会帮我们处理。
2.2 、内存池的初始化
在 LwIP 协议栈初始化的时候, memp_init()会对内存池进行初始化,真正的内存初始化函数是 memp_init_pool()函数
3、动态内存堆
在嵌入式开发中,内存管理以及使用是至关重要的,内存使用的多少、内存泄漏等时刻需要注意。合理的内存管理策略将从根本上决定内存分配和回收效率,最终决定系统的整体性能。 LwIP 为了能够灵活的使用内存,为使用者提供两种简单却又高效的动态内存管理策略:动态内存堆管理(heap)、动态内存池管理(pool),而内存池管理策略在前面的章节已经讲解,那么现在就来看看内存堆的管理。
其中,动态内存堆管理(heap)又可以分为两种: 一种是 C 标准库自带的内存管理策略,另一种是 LwIP 自身实现的内存堆管理策略。这两者的选择需要通过宏值MEM_LIBC_MALLOC 来选择,且二者只能选择其一。
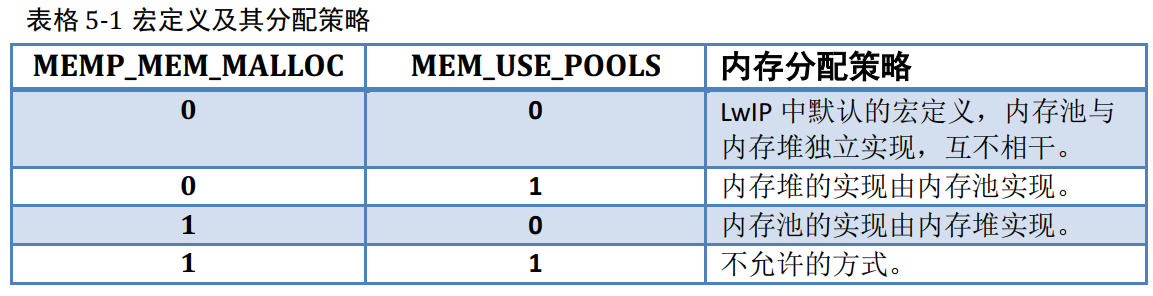
其次, LwIP 在自身内存堆和内存池的实现上设计得非常灵活。内存池可由内存堆实现,反之,内存堆也可以由内存池实现。通过 MEM_USE_POOLS 和 MEMP_MEM_MALLOC这两个宏定义来选择,且二者只能选择其一。
4、使用 C 库的 malloc 和 free 来管理内存
LwIP 支持使用 C 标准库的 malloc 与 free 进行内存的管理, 当宏定义 MEM_LIBC_MALLOC 被定义的时候, 编译器就会把以下代码编译进去, 就会采用C 标准库的 malloc 与 free 函数。
5、LwIP 中的配置
LwIP 中,内存的选择是通过以下这几个宏值来决定的,根据用户对宏值的定义值来判断使用那种内存管理策略,具体如下:
MEM_LIBC_MALLOC: 该宏定义是否使用 C 标准库自带的内存分配策略。该值默认情况下为 0,表示不使用 C 标准库自带的内存分配策略。即默认使用 LwIP提供的内存堆分配策略。如果要使用 C 标准库自带的分配策略,则需要把该值定义为 1。当该宏定义为 0 表示使用 LwIP 自己实现的动态内存管理策略。 LwIP 的动态内存管理策略又分为两种实现形式:一种通过内存堆(HEAP)管理策略来实现内存管理(大数组),另一种是通过内存池(POOL)管理策略来实现内存管理(事先开辟好的内存池)。
MEMP_MEM_MALLOC: 该宏定义表示是否使用 LwIP 内存堆分配策略实现内存池分配(即:要从内存池中获取内存时,实际是从内存堆中分配)。默认情况下为 0,表示不从内存堆中分配,内存池为独立一块内存实现。与MEM_USE_POOLS 只能选择其一。
MEM_USE_POOLS: 该宏定义表示是否使用 LwIP 内存池分配策略实现内存堆的分配(即:要从内存堆中获取内存时,实际是从内存池中分配)。默认情况下为0,表示不使用从内存池中分配,内存堆为独立一块内存实现。与MEMP_MEM_MALLOC 只能选择其一。
要使用内存池的方式实现内存堆分配,则需要将 MEM_USE_POOLS 与MEMP_USE_CUSTOM_POOLS 定义为 1,并且宏定义 MEMP_MEM_MALLOC 必须为 0,除此之外还需要做一下处理:
创建一个 lwippools.h 文件, 在该文件中添加类似代码清单 5-15 初始化内存池相关的代码, 内存池的大小及数量是由用户自己决定的。
LWIP_MALLOC_MEMPOOL_START LWIP_MALLOC_MEMPOOL(20, 256) LWIP_MALLOC_MEMPOOL(10, 512) LWIP_MALLOC_MEMPOOL(5, 1512) LWIP_MALLOC_MEMPOOL_END
此处需要注意一点的是, 内存池的大小要依次增大, 在编译阶段, 编译器就会将这些内存个数及大小添加到系统的内存池之中,用户在申请内存的时候,根据其需要的大小在这些内存池中选择最合适的大小的内存块进行分配,如果具有最匹配的内存池中的内存块已经用完,则选择更大的内存池进行分配,只不过这样子会浪费更多的内存,当然,内存池的分配效率也是最高的,也相对于是我们常说的以空间换时间。
关于如何选择这些宏定义及其分配策略,具体见表格 5-1。
总结来说,无论宏值怎么配置, LIP 都有两种内存管理策略:内存堆和内存池。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号