
写博客不再为配图发愁!我亲测好用的5款AI图像生成工具推荐
引言
相信很多人在博客园分享内容和心得的时候,写得行云流水,洋洋洒洒几千字干货。但是写完后回头看,密密麻麻的文字全都堆叠在一起。这时候你会想到图文并茂以来增强阅读体验。但提到配图这个过程又会犯难了——既要贴合内容,又要美观专业,自己画不会,网上找又怕侵权,并且现成的图片很难找到合适的。今天就和大家分享一下我的几款ai配图工具,能够有效地降低配图焦虑,写出阅读者友好的文章。
1. 豆包生图
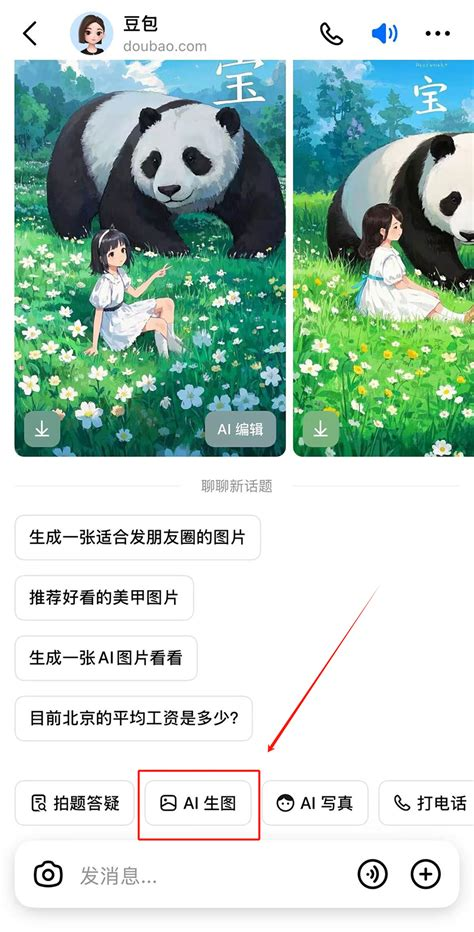
相信很多人都刷到过豆包的生图效果,比如说生成各省人的画像和装修模拟。豆包作为一个国民级AI应用,本身拥有较强的中文理解能力,随着生图功能的出现,可以当作是ChatGPT-4的高级平替了。凭借免费+对话式的批量生图功能,它生成的图片质量出乎意料地好,尤其在摄影、电商场景和3D风格上表现突出质感优秀,现在超能创意2.0修图、对话修改、批量输出和生成海报等都非常方便,特别适合需要快速生成配图的场景。
豆包生图的“超能创意1.0”功能在中文语境下的表现尤为出色,不仅全面支持中文输入,还能精准理解用户用自然语言表达的模糊或简略提示,极大降低了使用门槛。无论是“阳光洒在老巷的午后”这样富有意境的描述,还是“科技感十足的办公室”这类偏功能性的表达,它都能快速捕捉关键词并生成符合预期的图像,对中文用户来说非常友好。
豆包还支持“以图生图”模式,用户可以上传一张参考图像,再辅以文字描述,系统便会结合图像的风格、色调、构图等视觉特征与文本语义进行融合创作,生成风格一致且富有创意的新图片。这种图文协同的生成方式,特别适合需要保持视觉统一性的内容创作场景,比如系列博客配图、社交媒体视觉内容、品牌宣传素材等。
举个实际例子:当你输入“未来城市的科幻场景”,并上传一张霓虹灯闪烁、雨夜街道、机械建筑林立的赛博朋克风格夜景图作为参考,豆包生图不仅能准确理解“未来城市”这一主题,还能自动提取参考图中的光影氛围、色彩搭配和建筑风格,生成一幅细节清晰、充满科技感与未来感的赛博朋克都市图像。画面中可能包含悬浮的广告牌、飞行器穿梭的空中车道、金属质感的高楼,甚至行人身上发光的义体部件,整体视觉张力强,极具沉浸感。
此外,生成的图像在分辨率和细节处理上也表现不俗,边缘清晰、纹理自然,基本无需额外修饰即可直接用于文章配图或演示文稿。对于不擅长撰写复杂提示词的用户来说,这种“上传+描述”的组合方式大大提升了创作效率,真正实现了“所想即所得”。
总的来说,豆包生图的“超能创意1.0”不仅在中文理解能力上领先同类产品,还通过图文结合的智能生成机制,为普通用户和内容创作者提供了一种高效、直观又富有创意的图像生成路径,是写博客、做设计、搞自媒体时不可多得的实用利器。
优点:
-
中文支持良好,适合中文用户。
-
批量生成提升效率,适合大规模创作。
缺点:
- 生成速度可能受限于服务器性能。
2. 即梦
即梦也是字节跳动旗下的AI创作工具,和豆包同属一个“大家庭”,但两者的定位其实有些微妙的不同。如果说豆包更像是一个全能型的AI助手,主打便捷和通用性,那即梦则更偏向于“专业创作”的方向,尤其适合有一定设计需求的用户,比如做海报、封面、视觉草案,甚至是艺术字设计这类对审美和细节要求更高的场景。不过别担心,虽然它定位偏设计师,但界面友好、操作直观,哪怕你是零基础的小白,也能很快上手,不需要懂复杂的PS技巧或设计理论。
我用下来最惊艳的,是它在艺术字生成和海报设计方面的表现。输入一段文字,比如“夏日音乐节”,它不仅能生成极具风格感的标题字体——可能是霓虹灯效果、手绘涂鸦风,也可能是金属质感或未来科技感——还能自动搭配背景、色彩和排版,一键输出完整视觉方案。这种“文字+视觉”一体化的生成能力,在写公众号、做小红书封面或者策划活动宣传时特别实用,省去了反复调整的麻烦。
另外,即梦在生成人物图像时的质感也相当不错,皮肤细节、光影过渡自然,不会出现那种“塑料脸”或诡异的五官错位问题。无论是想生成模特图、角色设定,还是用于文章插图的虚拟人物,效果都比较接近真实摄影或专业插画的水准。如果你经常需要视觉草案来表达想法,比如产品概念图、场景构想、UI界面示意等,即梦真的能帮你快速把脑海中的画面具象化。
还有一个让我持续使用它的原因:免费政策非常友好。即梦采用积分制,每天登录就有基础积分,而且有个很贴心的机制——你当天用得越多,系统会认为你是活跃用户,第二天返还的免费积分也就越多。这意味着只要你正常使用,基本不会遇到“突然用不了”的尴尬。对于个人创作者、自由职业者或者内容博主来说,这套免费体系完全能满足日常配图需求,性价比非常高。
总的来说,如果你追求的是高质量、有设计感的图像输出,又不想花大价钱买专业设计服务或订阅昂贵的工具,即梦是一个非常值得尝试的选择。它既保留了AI生图的高效便捷,又在美学表达和专业功能上走得更远,可以说是“让普通人也能做出专业级视觉”的典型代表。

优点:
-
多功能集成,满足多种创作需求。
-
中文支持良好,适合中文用户。
-
社区互动功能丰富,促进创作交流。
缺点:
- 部分功能可能需要付费或会员权限。
3. gpt-4o
GPT-4o的大名相信大家都已经如雷贯耳了,毕竟它代表了当前大模型技术的一个高峰。而当OpenAI为ChatGPT-4o正式加入图像生成功能后,整个AI创作生态又迎来了一次不小的震动。和以往需要跳转平台、切换工具才能生成图片不同,GPT-4o的绘图能力是原生集成在对话系统中的——也就是说,你正在聊天,突然想配张图,直接说一句“帮我画一个森林里的小木屋,清晨阳光洒在屋顶上”,下一秒,图就出来了,整个过程自然得就像它本来就应该这样。
这种无缝嵌入对话的图像生成体验,是GPT-4o最让人惊艳的地方。它不只是“能画图”,而是真正实现了“边聊边画”。你可以像和设计师沟通一样,一步步调整细节:“把屋顶换成红色”“加一只趴在门前的橘猫”“让画面更有童话绘本的感觉”——它不仅能听懂,还能在原有图像基础上进行修改,支持多轮交互式的局部调整,省去了反复重来的麻烦。
更厉害的是它的改图能力和风格迁移表现。你上传一张草图或照片,它可以帮你重新渲染成水彩、赛博朋克、极简扁平风等各种艺术风格,同时保持核心内容不变。比如你想设计一个品牌周边小物件,上传一个杯子的简单线稿,再告诉它“用复古插画风格,加上咖啡豆和蒸汽元素”,它就能生成一张极具质感的视觉参考图,细节丰富,构图合理,甚至文字渲染都相当准确——这在很多AI生图工具里都是个痛点,经常出现字母错乱或字体不协调的情况,但GPT-4o在这方面表现非常稳定。
正因为这种原生多模态的集成能力,GPT-4o在AI生图工具中显得有点“超前”。它不只是一款“图像生成器”,更像是一个能听、能看、能画、能改的全能创作伙伴。无论是做海报概念、文章插画、产品原型草图,还是社交媒体配图,它都能快速给出高质量的视觉方案。尤其是在需要快速迭代创意的场景下,比如头脑风暴、内容策划、教学演示,它的响应速度和理解能力能极大提升效率。
当然,目前它的图像生成仍有一定使用门槛,比如需要订阅ChatGPT Plus,且生成次数受速率限制。但从体验来看,这种“对话即设计”的方式,或许正是未来AI创作的主流方向——不再需要复杂的指令或专业软件,只要你会表达,就能把想法变成看得见的画面。对写博客、做内容、搞创意的人来说,GPT-4o不仅是个工具,更像是一位随时在线的视觉搭档。

优点:
-
多模态支持,适应多种输入方式。
-
实时语音交互,提升用户体验。
-
强大的理解和生成能力,适应复杂任务。
缺点:
-
中文支持可能不如英文,需优化提示词。
-
部分功能可能需要付费或会员权限。
4. Midjourney
它的创意激发能力在AI图像生成领域依然是那种“站在山顶”的存在,哪怕如今竞争者越来越多,它依然保持着独特的艺术气质和视觉统治力。作为一个长期使用者,我能明显感受到V7版本在细节质感、光影层次和整体构图上的提升——画面更干净、更“像真的”,尤其是在处理复杂材质、人物皮肤纹理和环境氛围时,那种细腻程度让人惊叹。比如生成一个“穿丝绸长裙站在黄昏海滩上的女子”,V7能清晰呈现出布料随风的褶皱、沙粒的反光、海面的波纹,甚至连发丝边缘的透光都处理得非常自然。
除了真实感人物和写实场景,Midjourney最让我着迷的其实是它在创意插图、幻想世界和超现实题材上的表现。无论是“漂浮在星空中的水晶图书馆”,还是“机械与藤蔓共生的未来城市”,它总能以一种极具美感的方式将天马行空的想象具象化。它的“美感”不是简单的漂亮,而是一种融合了构图、色彩、情绪和叙事的综合审美,很多设计师和艺术家都承认,Midjourney经常能生成出“你没想到但一看就觉得对”的画面。
另外,Midjourney的放大(Upscale)和扩图(Outpainting)功能也一直很稳。放大后细节依然清晰,不会糊成一团;扩图时能自然延续原图的光影和结构,比如你有一幅森林小屋的画面,扩图后延伸出的小径、远处的山峦,甚至天空的云层走向,都像是原本就存在的。这种“画面可生长”的能力,在做海报延展、长图设计或场景构建时特别实用。
总的来说,Midjourney可能不是最快、最易用的工具,但它依然是那个最能“点燃灵感”的AI画笔。它不只帮你画图,更像在和你一起创作,时不时给你一点意外的惊喜。如果你追求的不只是“一张配图”,而是一种视觉上的独特表达,那Midjourney依然是那个绕不开的名字。

优点:
-
生成高质量的艺术图像,适合艺术创作。
-
支持多种风格,满足不同需求。
-
支持自定义提示词,生成符合用户需求的图像。
缺点:
-
付费计划昂贵
-
缺少再次修改的能力
5. Xole AI
最近我发现了一个让人眼前一亮的AI视觉创作平台——Xole AI。它不像一些只专注于“输入文字出图”的基础工具,而更像是一个为创意而生的在线实验室,主打原创性、想象力和极致的易用性。如今,它已经吸引了超过200万用户,每天生成的图像高达数百万张,逐渐成为不少设计师、内容创作者甚至营销团队的秘密武器。
最直观的体验是它的“文字转图像”功能。你只需要输入一段简单的描述,比如“一只发光的狐狸在雪夜森林中奔跑,身后拖着星尘般的尾巴”,Xole AI就能迅速将这种抽象的情绪和画面具象化,生成极具艺术感的图像。它的优势在于对语义的理解非常细腻,不仅能抓住关键词,还能捕捉氛围和情绪,输出的视觉作品往往带有一种独特的“呼吸感”,不机械、不堆砌,更像是真正被“创作”出来的。
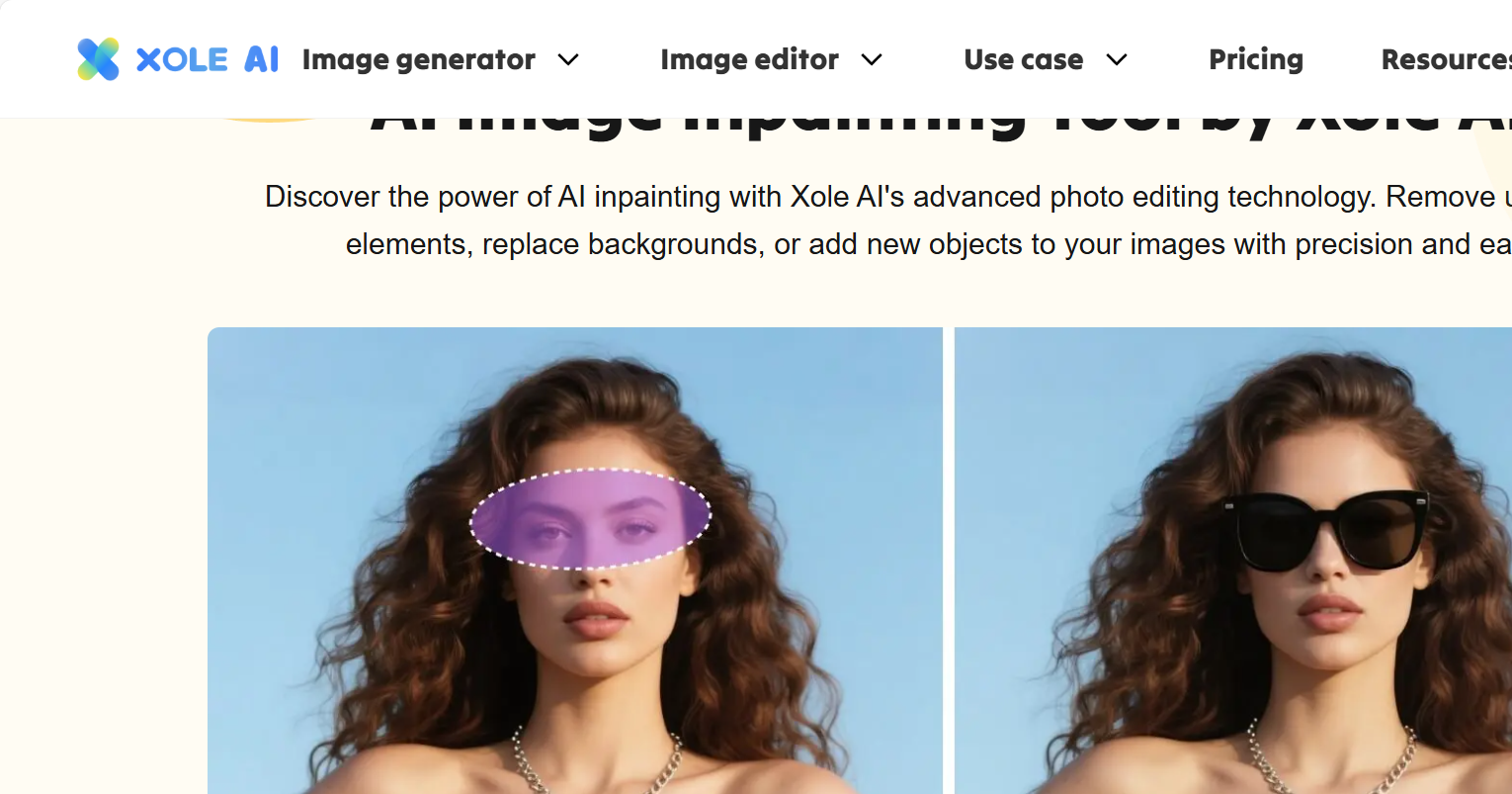
但这还只是开始。Xole AI真正让我觉得“好用到离谱”的,是它集成的一整套AI图像编辑工具,全都无缝嵌入在同一个平台里,完全不需要跳转到PS或其他软件。
比如它的AI修复(Inpaint)功能,你可以圈出图片中想修改的区域,然后告诉它“把这件衣服换成红色风衣”或“把背景里的路人去掉”,系统就会智能重绘那一块,而且融合得自然流畅,几乎看不出痕迹。这种“边看边改”的体验,极大提升了创作效率,特别适合做产品图优化或社交媒体内容调整。
更厉害的是图像扩展功能。有时候你有一张不错的图,但构图不够宽,或者想用作横幅但画面太局促。Xole AI可以智能地向外延展画布,生成与原图风格、光影、内容高度一致的新场景。比如一张城市夜景,扩图后会出现新的建筑、街道和灯光,仿佛原本就属于同一张照片,完全没有割裂感。
还有它的背景更换功能,也非常实用。上传一张人物或产品图,几秒钟就能替换成你想要的任何场景——“站在极光下的雪山营地”“未来感十足的玻璃大厅”“复古咖啡馆的一角”……AI不仅会生成匹配的背景,还会自动调整光影和色调,让主体和新环境融为一体,效果堪比专业合成。
所有这些功能——从生成、编辑到优化——都被整合在一个简洁的界面中,并包含在统一的订阅计划里。这意味着你不需要为不同功能额外付费或切换多个工具,无论是做小红书封面、公众号配图、电商主图,还是数字艺术创作,都能在一个平台上完成全流程操作。
对社交媒体创作者来说,它能帮你快速产出吸睛内容;对独立设计师而言,它是一个灵感激发和效率提升的助手;哪怕只是偶尔需要一张特别的图,Xole AI也能让你轻松实现“所想即所见”。
总的来说,Xole AI不只是又一个AI生图工具,它更像是一个为现代视觉创作而打造的全能引擎。它把复杂的技术藏在背后,把简单、强大和创造力交到用户手中。如果你希望用更少的时间,做出更有质感、更具个性的视觉内容,Xole AI绝对值得加入你的创作工具箱。
优点:
-
支持多种风格转换(如 Ghibli、Disney、皮克斯、卡通、草图等),适用场景广泛
-
操作简便,无需设计基础,一键上传即可生成
-
生成速度较快,一般几十秒完成一张高分辨率图像
缺点:
-
高峰期生成速度可能稍慢,不一定实时
-
风格定制程度有限,适合一键式需求,不适合深度 prompt 调整
-
对专业用户或复杂视觉项目而言可能不够灵活
总结
我在写文章的时候,总是纠结于“文字够不够深刻”“逻辑严不严谨”,却常常忽略了读者打开文章那一刻的第一感受——视觉体验。直到有次朋友调侃我说:“你这文章写得像论文,密密麻麻看着就累。”我才意识到,好的内容,也需要好的呈现。
配图不再是可有可无的装饰,而是提升阅读流畅度和吸引力的重要一环。以前总觉得做图门槛高,找图麻烦还怕侵权,现在有了这些AI工具,真的像是多了几位懂你想法的“视觉搭档”。不管是豆包的中文友好、即梦的设计感,还是GPT-4o的边聊边画、Midjourney的艺术气质,还有Xole AI那种一站式的便捷编辑,都在让“图文并茂”这件事变得越来越简单、自然。
其实技术再厉害,最终服务的还是我们想表达的心意。一张恰到好处的图,能让冷冰冰的技术文字多一分温度,也能让抽象的概念瞬间变得具体可感。希望这篇文章推荐的工具,能帮你少一点配图焦虑,多一点创作乐趣。
毕竟,我们写博客,不只是为了记录,更是为了被看见、被理解。而好的图像,就是让思想更容易被看见的那扇窗。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号