迁移学习
一 概述
Transfer Learning 利用与task没有直接相关的data。那么什么叫没有直接相关呢? 比如:

那么为什么要利用不直接相关的数据呢,如下:
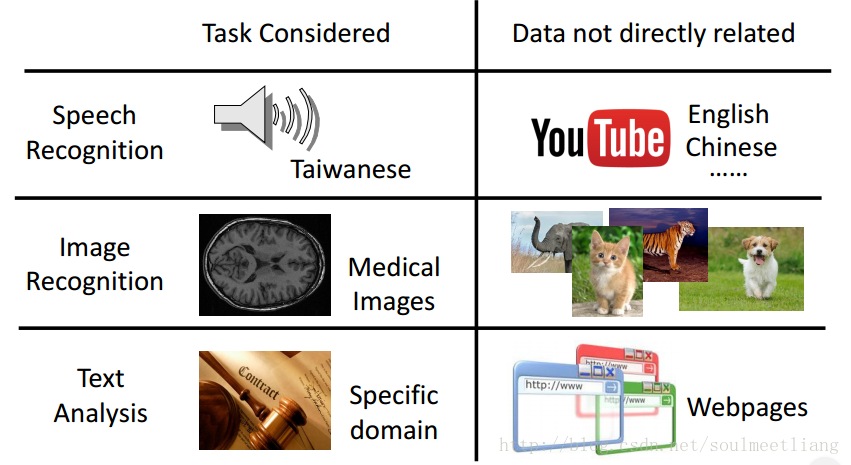
Example in real life
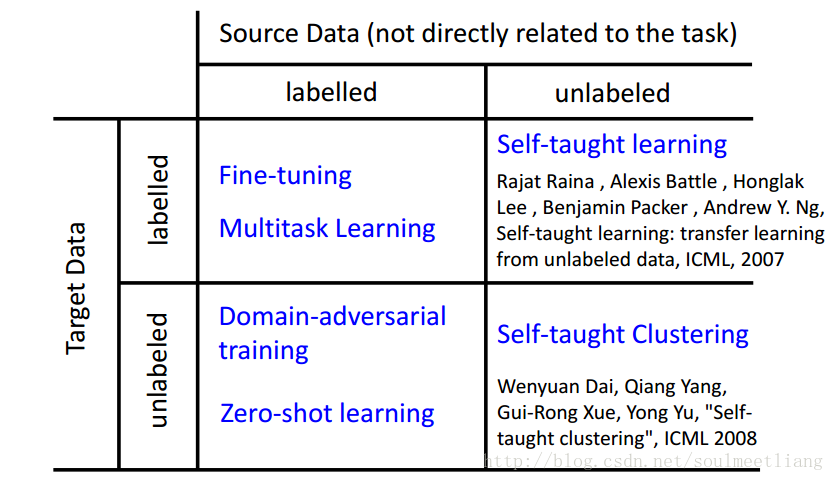
二 各种情况对应的解决方法
- 分成四个象限:下面将以象限作为小标题。
- Target Data:直接相关的数据。
- Source Data:没有直接相关的数据。
2.1 Traget Data labelled Source Data labelled
方法1:Model Fine-tuning

把在source data上train出来的model当作是training的initial value。 由于target data可能很少,极有可能过拟合,所以train的时候要很小心,这里有一下几种技巧。
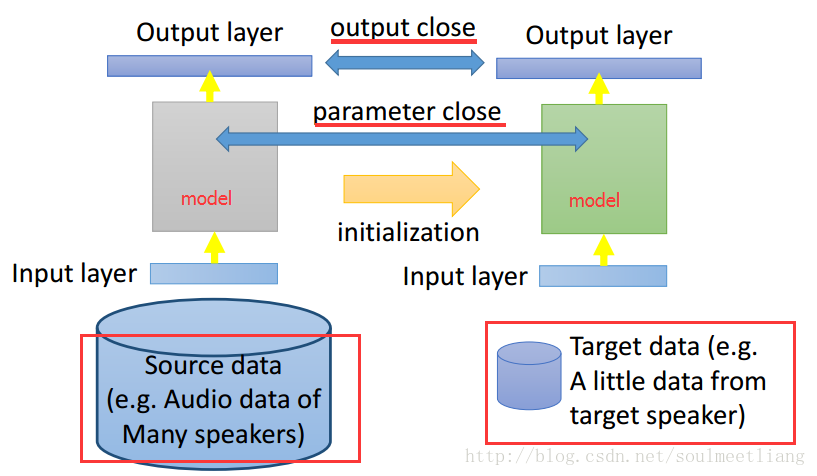
Conservative Training (保守训练)
让左右两个model差距不要太大。
Layer Transfer
将Source data train好的model,复制几个参数到新的model里,然后再利用Target data训练没有被复制来的参数,这样每次训练的参数都较少,避免了过拟合。
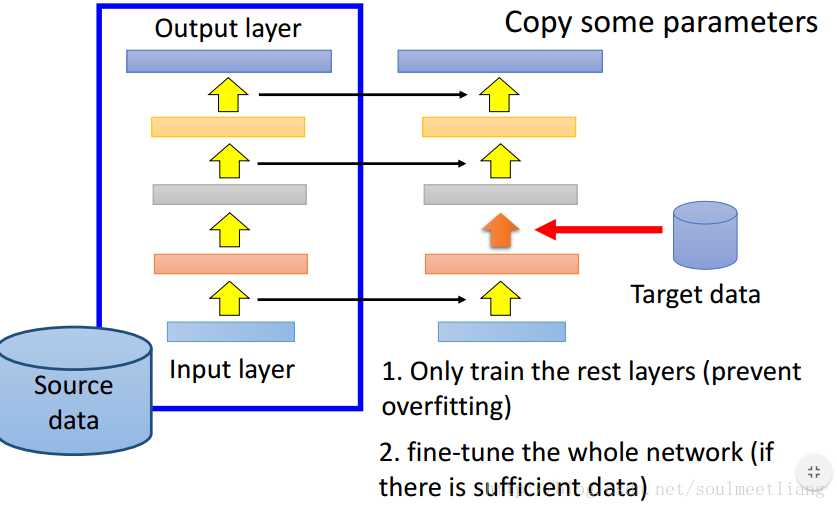
那么那些layer 的参数可以copy呢? 因任务而异,case by case
- Speech: usually copy the last few layers
- Image: usually copy the first few layers
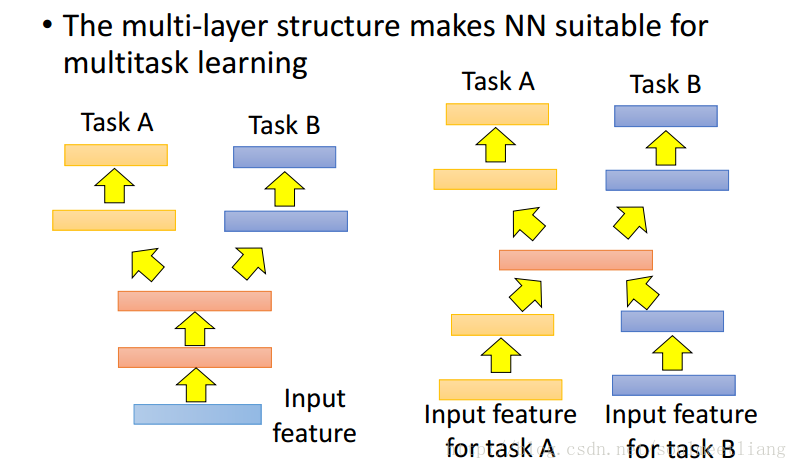
方法2:Multitask Learning
Multilingual Speech Recognition :目前发现,几乎所有的语言都可以互相transfer。
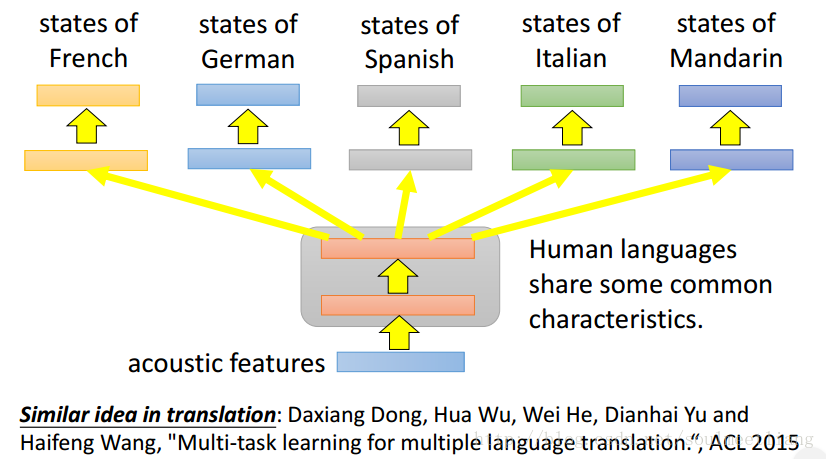
实验表明transfer 果然是很有帮助的

2.2 Traget Data unlabelled Source Data labelled

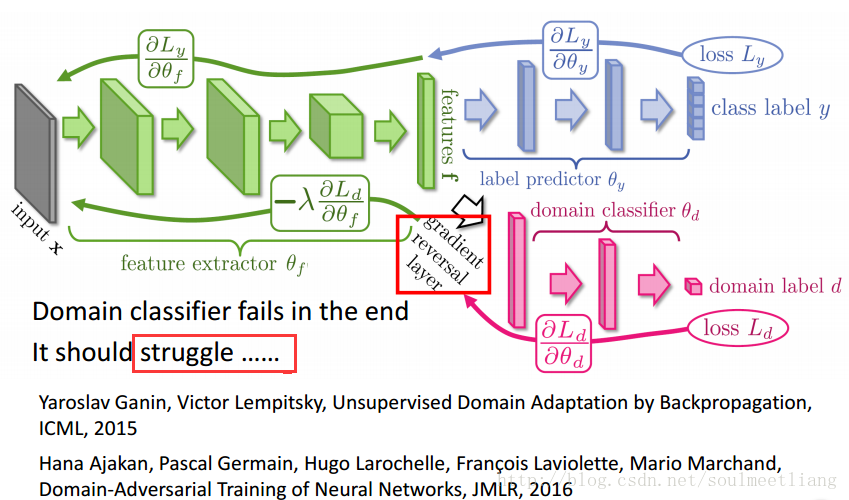
方法1:Domain-adversarial training
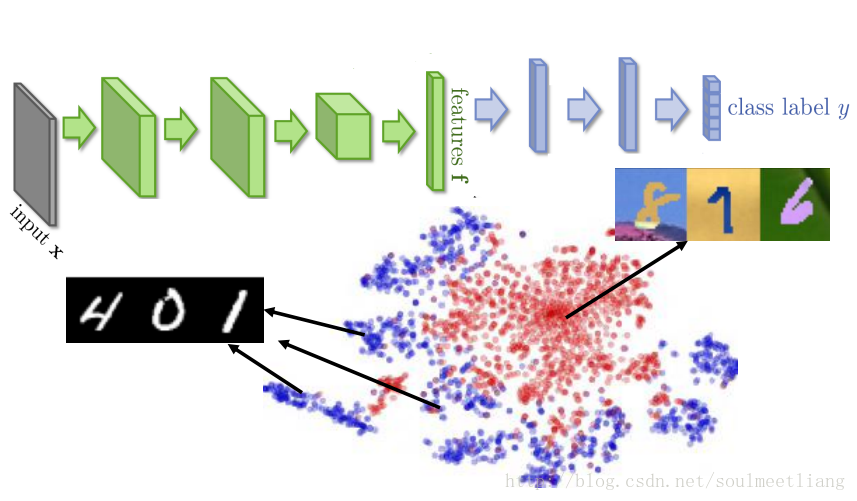
当我们利用neutral network抽取feature和做classification时,可以看到,蓝色部分抽取的feature分成10块,而红色部分并没有被区分开来,所以后面的分类也不可能做好。
运用Domain-adversarial training
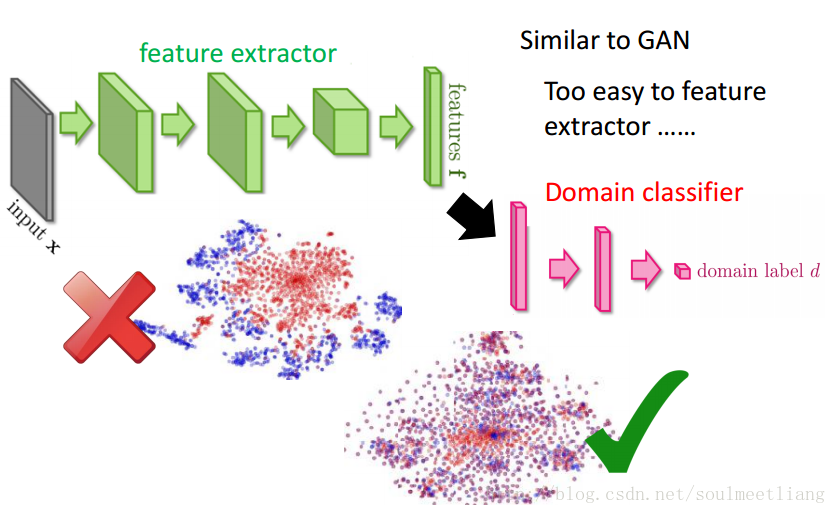
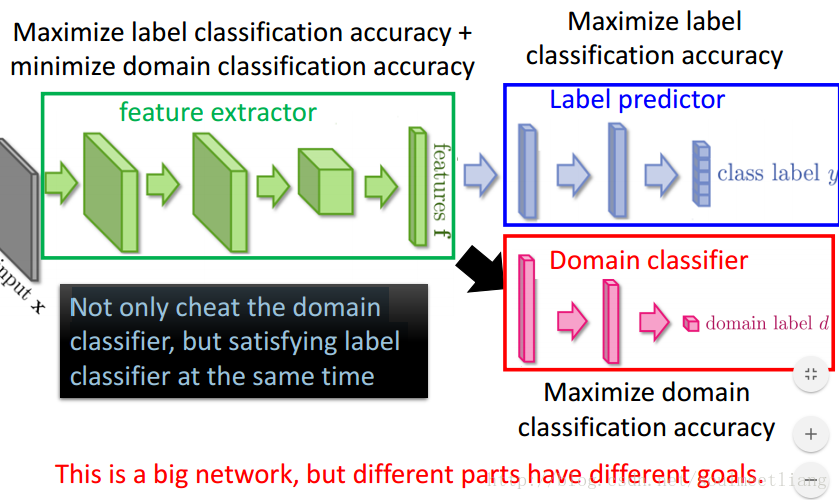
全部分类为零就可以骗过Domain classifier,所以要加一个Label predictor。使之不仅要骗过Domain classifier,还要同时满足label classifier。 这是一个很庞大的网络,不同于以往所有的参数都目标一致,这个网络中的参数可谓各怀鬼胎。 蓝色部分参数想让Domain classifier做得更好。 红色部分参数想要正确预测来者属于哪个domain。 绿色部分参数想同时做两件事,提高蓝色部分的预测正确率,最小化红色部分的分类正确率。 可以看到红色与绿色是在相互对抗的。
效果:

方法2:Zero-shot learning
今天想要辨识羊驼,但是source data中没有一只羊驼!
Representing each class by its attributes
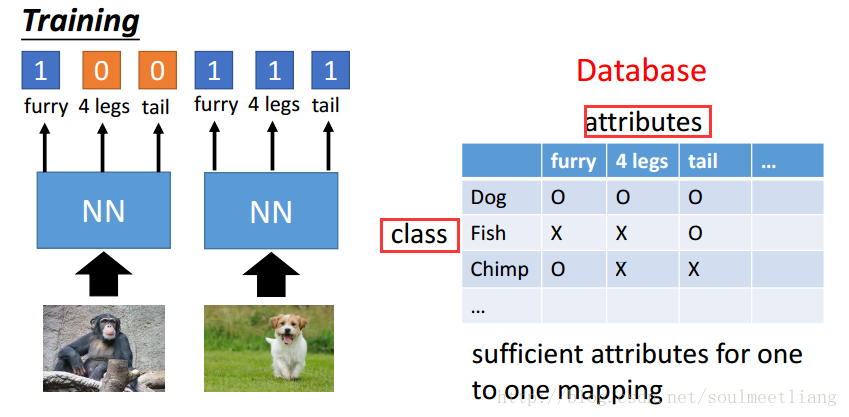
通过特征表来进行分类,当输入一只羊驼时;
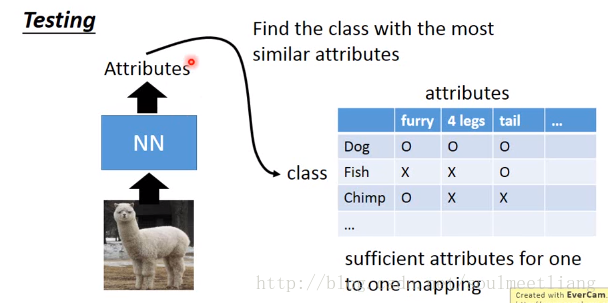
Attribute embedding
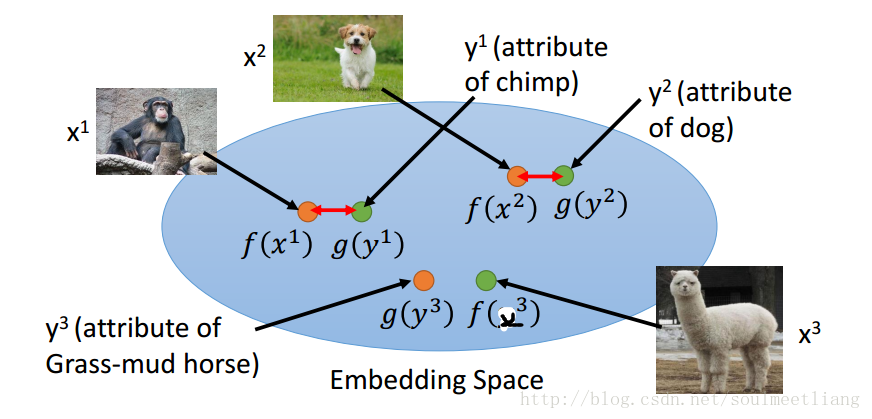
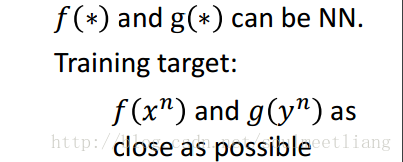
x 是一张图片,通过函数(NN)f(),可以投影到embedding space成为一个向量f(x);y 是特征表里的一行特征向量,通过函数(NN)g((),降维到embedding space成为向量g(y); 然后使f(x123),g(y123)上越接近越好,当我们输入一张不知道的图片比如草泥马,通过比较f(草泥马)与哪个g(y)比较接近,得到它的类别。但是会有一个问题,当我们并不知道特征表时,怎么解决呢,那么就需要用Attribute embedding + word embedding。我们知道word embedding 中的每一维度,其实就代表了一个特征,所以就不需要一个database来告诉每种动物的特征是啥。
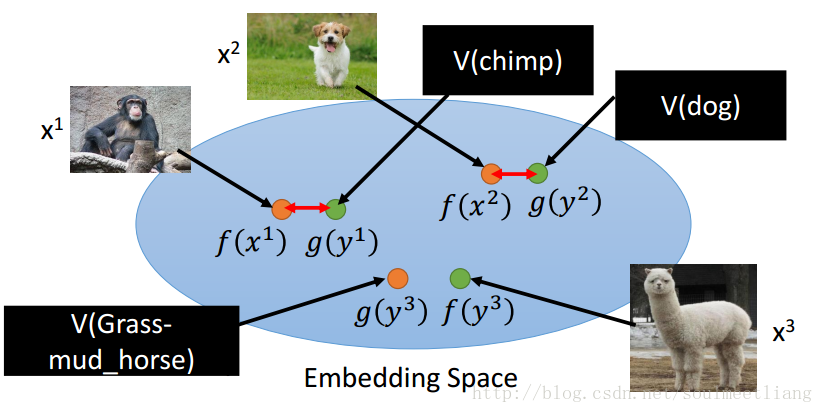
回到刚刚在embedding space 上的距离比较,通过下边这个公式比较可以吗?
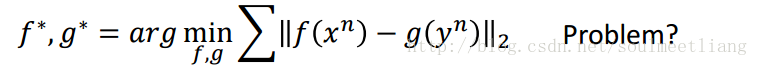
答案是不可以的,很明显,为了使结果更接近,全部投影到一个点上显然可以,但明显不合适。所以loss function这样定义是不行的。 上述公式只考虑了同一组x,y越接近越好,但没有考虑到,不同组的x,y距离要拉大。 所以要改成:

其实还有一个Zero-shot 的方法叫做Convex Combination of Semantic Embedding。 其实就是取NN得出的分类的概率中点,然后word vector 与该中点比较。

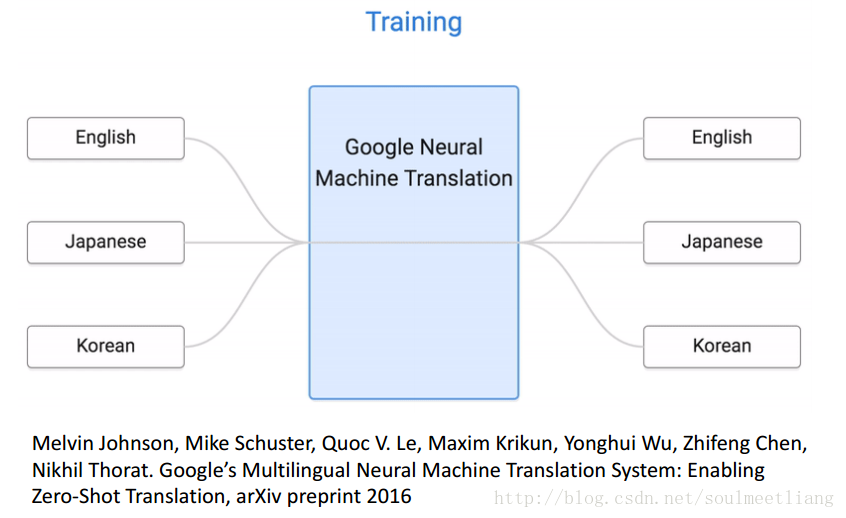
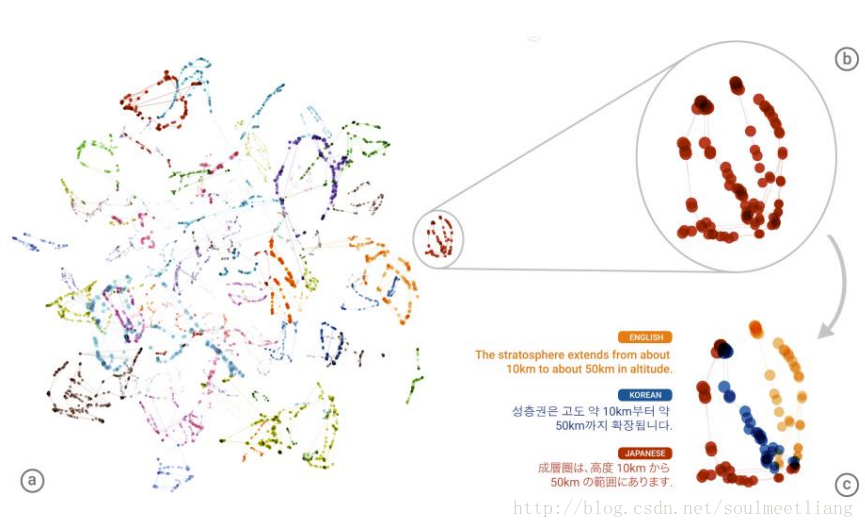
Example of Zero-shot Learning:本来只有中英、日法翻译,通过transfer,学会了中法翻译。
2.3 Target data labelled Source Data unlabelled
方法:Self-taught learning
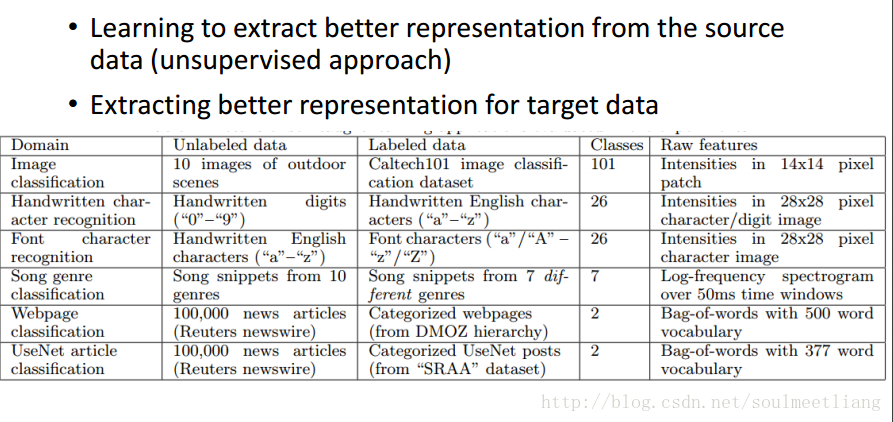
2.4 Target data unlabelled Source Data unlabelled
方法:Self-taught Clustering

参考:
http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Lecture/transfer%20%28v3%29.pdf
https://blog.csdn.net/soulmeetliang/article/details/74621919

 浙公网安备 33010602011771号
浙公网安备 33010602011771号