

python程序设计(二):python进阶
python进阶
函数与函数式编程
函数的定义与调用
返回斐波那契数列中小于整数n的所有值
def fib(n):
pass
fib(1000)
python中的函数,用def关键字定义.函数不需要返回值类型,不需要参数类型
函数的参数
函数参数的集中类型:
位置参数(positional arguments):形参和实参数量相同,位置一致.
缺省参数(default arguments):形参有默认值,有缺省参数的形参要在位置参数之后.
关键字参数(keyword arguments):实参顺序可以和形参顺序不一致,避免了用户需要牢记位置参数顺序的麻烦
可变参数(variable-length arguments):*parameter用来接受多个实参并将其放在元组中.**parameter接收多个关键参数并存放到字典中
位置参数:
def func(a,b,c):
print(a,b,c)
func(1,2)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
c:\Users\Tenerome\Desktop\python\lesson.ipynb Cell 45 in <cell line: 3>()
<a href='vscode-notebook-cell:/c%3A/Users/Tenerome/Desktop/python/lesson.ipynb#X63sZmlsZQ%3D%3D?line=0'>1</a> def func(a,b,c):
<a href='vscode-notebook-cell:/c%3A/Users/Tenerome/Desktop/python/lesson.ipynb#X63sZmlsZQ%3D%3D?line=1'>2</a> print(a,b,c)
----> <a href='vscode-notebook-cell:/c%3A/Users/Tenerome/Desktop/python/lesson.ipynb#X63sZmlsZQ%3D%3D?line=2'>3</a> func(1,2)
TypeError: func() missing 1 required positional argument: 'c'
这个就是positional 参数,缺少时报错
缺省参数:
def func1(a,b,c=1):
print(a,b,c)
func1(2,3)
2 3 1
定义函数时就对形参赋值,就是缺省参数,后面传实参会覆盖
关键字参数:
def func2(a,b,c):
print(a,b,c)
func2(c=3,a=1,b=2)
1 2 3
可以看到调用的时候没有按形参顺序来,但是用关键字(形参名)来调用的,就可以忽略顺序
def stu(country='中国',name):
print("%s,%s" %(name,country))
stu('美国','Tom')
Input In [7]
def stu(country='中国',name):
^
SyntaxError: non-default argument follows default argument
有缺省值的参数必须放位置参数后面
def stu(name,country='中国'):
print("%s ,%s" %(name,country))
stu('美国','Tom')
美国 ,Tom
可变参数:
变量的作用域
函数体外部的变量:全局变量
内部:局部变量
函数内可以调用全局变量
x=100
def f():
print(x)
f()
100
在函数内部的变量赋值操作,该变量就是局部变量.
x=100
def f():
print(x)
x=200
print(x)
f()
---------------------------------------------------------------------------
UnboundLocalError Traceback (most recent call last)
c:\Users\Tenerome\Desktop\python\lesson.ipynb Cell 63 in <cell line: 6>()
<a href='vscode-notebook-cell:/c%3A/Users/Tenerome/Desktop/python/lesson.ipynb#Y116sZmlsZQ%3D%3D?line=3'>4</a> x=200
<a href='vscode-notebook-cell:/c%3A/Users/Tenerome/Desktop/python/lesson.ipynb#Y116sZmlsZQ%3D%3D?line=4'>5</a> print(x)
----> <a href='vscode-notebook-cell:/c%3A/Users/Tenerome/Desktop/python/lesson.ipynb#Y116sZmlsZQ%3D%3D?line=5'>6</a> f()
c:\Users\Tenerome\Desktop\python\lesson.ipynb Cell 63 in f()
<a href='vscode-notebook-cell:/c%3A/Users/Tenerome/Desktop/python/lesson.ipynb#Y116sZmlsZQ%3D%3D?line=1'>2</a> def f():
----> <a href='vscode-notebook-cell:/c%3A/Users/Tenerome/Desktop/python/lesson.ipynb#Y116sZmlsZQ%3D%3D?line=2'>3</a> print(x)
<a href='vscode-notebook-cell:/c%3A/Users/Tenerome/Desktop/python/lesson.ipynb#Y116sZmlsZQ%3D%3D?line=3'>4</a> x=200
<a href='vscode-notebook-cell:/c%3A/Users/Tenerome/Desktop/python/lesson.ipynb#Y116sZmlsZQ%3D%3D?line=4'>5</a> print(x)
UnboundLocalError: local variable 'x' referenced before assignment
也就是说,在函数内,一旦引用了全局变量,就不能在函数内对全局变量赋值
但是可以先赋值再引用,这时两个x并不是同一个,相当于两个变量,一个全局,一个局部,但是有相同的变量名
x=100
def f():
x=200
print(id(x))
f()
id(x)
2413391733392
2413391730128
想要在函数内真正调用全局变量,可以用global声明
x=100
def f():
global x
x=200
print(id(x))
f()
id(x)
2413391733392
2413391733392
python支持使用nonlocal关键字定义一宗介于全局和局部之间的变量,成为闭包作用域变量.关键字nonlocal声明的变量会引用距离最近的非全局作用域的变量(闭包变量或局部变量).要求声明的变量已经存在.关键字nonlocal不会创建新变量
lambda表达式
def fsum(x,y):
return x+y
像上面的函数,只是很简单的功能,就定义了函数.lambda表达式就是用来代替简单的函数的
基本结构lambda left : right.其中left是参数,right是返回值.
f=lambda x,y : x+y
f(3,5)
8
lambda表达式就是把简单的函数改成无函数体的形式,只有参数和返回值.返回值用表达式的形式.只要能改成这样的结构的函数,都可以写成lambda表达式的形式
函数式编程
函数式编程就是把函数作用于一个或多个序列,来实现一些功能
① 内置函数map()可以将一个函数作用到一个或多个序列或迭代器对象上,返回可迭代的map对象
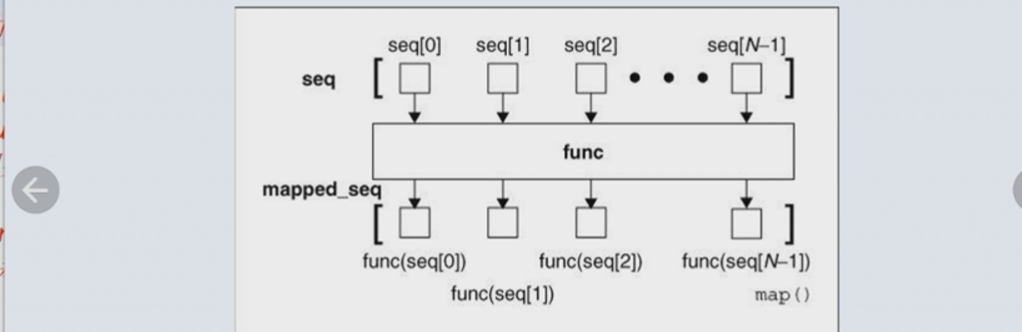
map()会把seq中的元素一个个作用在func()上,并将返回值组成一个新的可迭代对象mapped_seq
结构:map(func, *iterables) --> map object
第一个参数是函数名,也可以是lambda表达式,第二个参数是一个可迭代的对象,返回值为map object
import math
map(lambda x:math.pow(x,2),[1,2,3,4,5,6,7])
<map at 0x231ffcec3a0>
返回结果是map object 是可迭代的
list(map(lambda x:math.pow(x,2),[1,2,3,4,5,6,7]))
[1.0, 4.0, 9.0, 16.0, 25.0, 36.0, 49.0]
②标准库functools中的reduce(function,sequence)函数可以接收一个有两个参数的函数function(),以迭代的方式从左到右依次作用到一个序列sequence上实现类huffman树的聚集操作(求和,求连乘积等)
Huffman树聚集
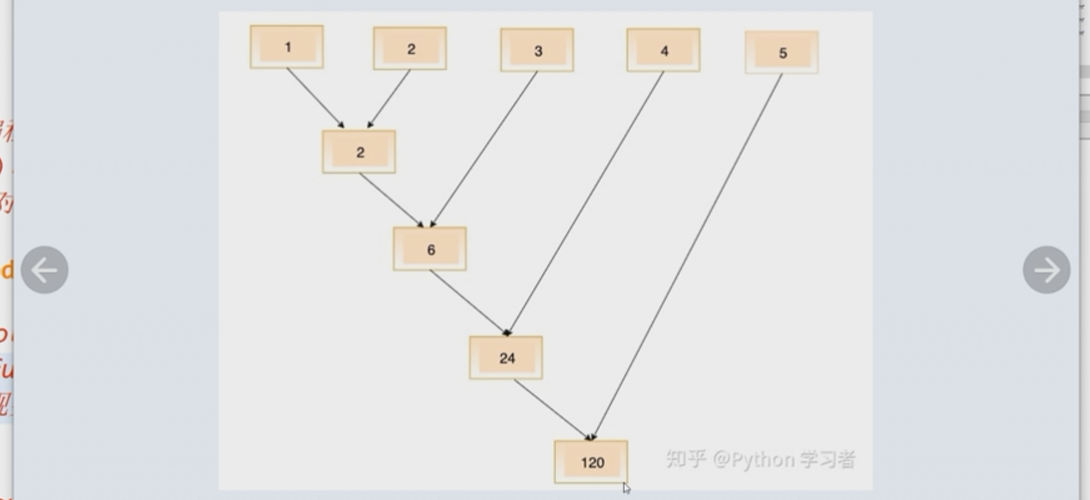
from functools import reduce
reduce(lambda i,j:i+j,range(1,101))
5050
③内置函数filter将一个函数作用到一个序列上,返回该序列中式函数返回值为True的元素组成的filter对象,filter对象也是可迭代的
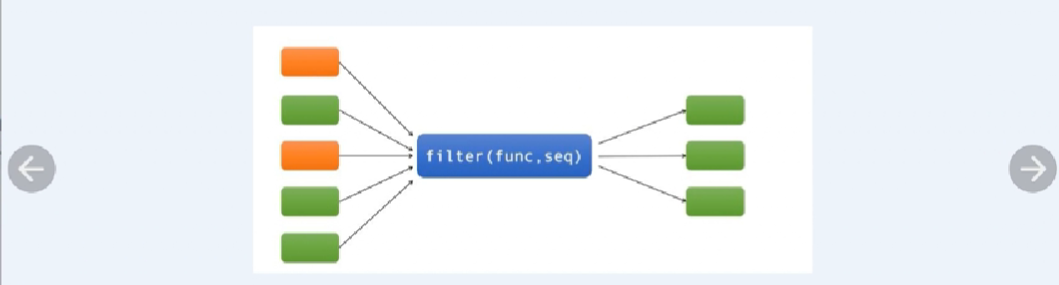
如:输出从1到1000所有的素数
import math
def is_prime(n):
if n<2:
return False
if n==2:
return True
if n%2==0:
return False
sqrt_n=math.floor(math.sqrt(n))
for i in range(3,sqrt_n+1,2):
if n%i==0:
return False
return True
print(list(filter(is_prime,range(1,101))),end=" ")
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97]
④内置函数zip
zip函数像一个拉链,把两个序列连接返回一个zip对象,可迭代.其元素是两个序列元素组成的元组

list(zip(range(10),'abcdefghij'))
[(0, 'a'),
(1, 'b'),
(2, 'c'),
(3, 'd'),
(4, 'e'),
(5, 'f'),
(6, 'g'),
(7, 'h'),
(8, 'i'),
(9, 'j')]
面对对象设计
类的定义和实例化
①结构
class 类名:
类成员
关键字为class,类名首字母要大写,如果是自定义类的派生类,则需要用类名+(object)形式.类中的方法和属性不需要使用Pascal法则命名,即首字母不用大写
例:定义Sheep类,内部定义一个name变量,一个shout方法,实例化一个对象sheep,调用shout方法,喊出它的name
class Sheep:
name='Shown'
def shout(name):
print('My name is:',name)
sheep=Sheep()
sheep.shout()
My name is: <__main__.Sheep object at 0x000002715D415640>
运行提示<main.Sheep object>很明显这不是想传进去的name,而是实例化的sheep对象
print(sheep)
<__main__.Sheep object at 0x000002713C772BE0>
类中的方法,分类方法和实例方法.类方法作用于类,实例方法作用域实例.python中的实例方法必须用self来做第一个参数
调用类中的全局变量时用self.变量名
class Sheep:
name='Shown'
def shout(self):
print('My name is:',self.name)
sheep=Sheep()
sheep.shout()
My name is: Shown
也可以用类名调用
class Sheep:
name='Shown'
def shout(self):
print('My name is:',Sheep.name)#用Sheep.name
def run(self):
self.shout()
print('I am running')
sheep=Sheep()
sheep.run()
My name is: Shown
I am running
同样的,类中的实例方法互相调用时也需要用self.方法名,但是不能用类名
class Sheep:
name='Shown'
def shout(self):
print('My name is:',self.name)
def run(self):
self.shout()
print('I am running')
sheep=Sheep()
sheep.run()
My name is: Shown
I am running
如果想在实例化的时候对对象赋初值,则会用到构造方法.python中的构造方法叫做初始化方法,用__init__表示.python中的类,通过__new__实例化,通过__init__来初始化
print(dir(sheep),end=" ")
['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'name', 'run', 'shout']
类中带双下划线的方法或属性如__new__叫做魔法方法/属性,它是类中的已经定义好的方法,一般有类自己调用,也可以通过编程调用或者重写.后面的name,run,shout才是自已定义的方法/属性
重写__init__,添加参数,用来实例化的时候赋初值
class Sheep:
def __init__(self,name):
self.name=name
def shout(self):
print('my name is:',self.name)
sheep=Sheep('Tom')
sheep.shout()
my name is: Tom
这里的self相当于实例后的独有的空间
self{
name;
shout()
}
self和类class的关系就相当于
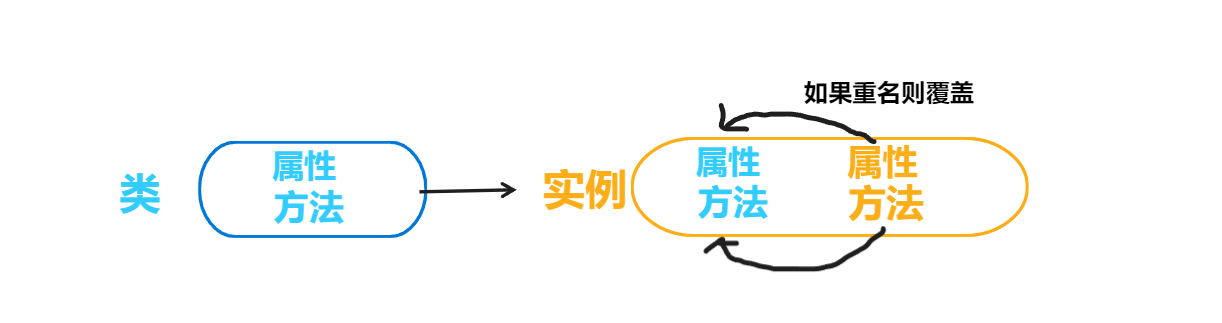
class Panda:
attr1='Pandas'
def func1():
pass
def func2(self):
self.attr2='cats'
def func3(self):
print(self.attr2)
a=3
print(a)
pass
pan=Panda()
print('class:',[i for i in dir(Panda) if i[0]!='_'])
print('self:',[i for i in dir(pan) if i[0]!='_'])
class: ['attr1', 'func1', 'func2', 'func3']
self: ['attr1', 'func1', 'func2', 'func3']
可以看到class和self共有attr1,func1,func2,func3,也就是说,在没有调用实例化方法时,self中的属性并不会创建
pan.func2()
print('class:',[i for i in dir(Panda) if i[0]!='_'])
print('self:',[i for i in dir(pan) if i[0]!='_'])
class: ['attr1', 'func1', 'func2', 'func3']
self: ['attr1', 'attr2', 'func1', 'func2', 'func3']
调用pan.func2()后,self区创建了attr2
pan.func3()
print('class:',[i for i in dir(Panda) if i[0]!='_'])
print('self:',[i for i in dir(pan) if i[0]!='_'])
cats
3
class: ['attr1', 'func1', 'func2', 'func3']
self: ['attr1', 'attr2', 'func1', 'func2', 'func3']
可以看到,虽然attr2是在func2()中创建的,但在func3()中仍能调用.但是func3()中的局部变量3并不在pan中.
但是不同的实例之间并不能共用self区
class Panda:
attr1='Pandas'
def func1():
pass
def func2(self):
self.attr2='cats'
def func3(self):
print(self.attr2)
a=3
print(a)
pass
pan=Panda()
pan1=Panda()
pan.func2()
pan1.func2()
#pan修改attr2不影响pan1
pan.attr2='dogs'
print('pan1.attr2:',pan1.attr2)
pan1.attr2: cats
所以不同实例之间的关系是这样的
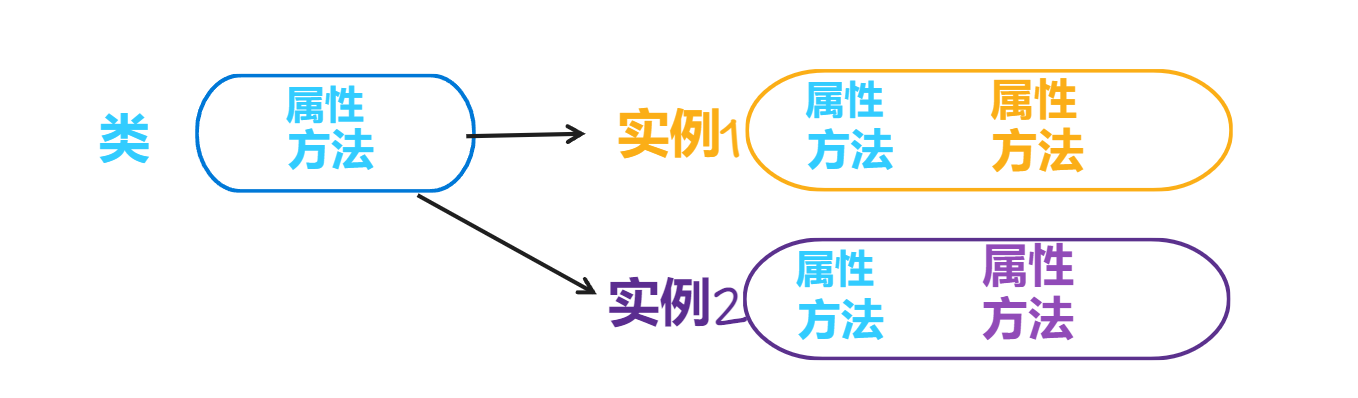
如果形参,self变量,类变量名字相同就这样区分
class Panda:
name='Aa'
def func(self):
self.name='Bb'
name='Cc'
print(Panda.name)
print(self.name)
print(name)
pan=Panda()
pan.func()
print('class:',[i for i in dir(Panda) if i[0]!='_'])
print('self:',[i for i in dir(pan) if i[0]!='_'])
Aa
Bb
Cc
class: ['func', 'name']
self: ['func', 'name']
可以看到三个name值不同.而class和self虽然在内部空间存在相同的属性名name,但他们是两个值
再继续看实例调用类变量的情况
class Panda:
name='Aa'
def func(self):
self.name='Bb'
name='Cc'
pan=Panda()
print(pan.name)
Aa
未调用func(),实例可以访问类变量
pan.func()
print(pan.name)
Bb
调用func()后,self区的name就被覆盖了
但如果是不同的变量名
class Panda:
cname='Aa'
def func(self):
self.name='Bb'
name='Cc'
pan=Panda()
print(pan.cname)
pan.func()
print(pan.cname)
print('self:',[i for i in dir(pan) if i[0]!='_'])
Aa
Aa
self: ['cname', 'func', 'name']
就不会覆盖,self此时既有cname,又有name.所以如果类属性和实例属性名字相同,调用函数后,就不能再通过实例访问类属性
sum up:
类中的变量分类变量(class),实例变量(self)和局部变量
类变量直接定义在类中,可以被类名和实例化的对象调用
实例变量定义在方法中,且由self修饰,只有在调用方法时才创建,能被所有实例调用,不能通过类名访问
如果类变量和实例变量名相同,实例调用函数后,会覆盖
局部变量也定义在函数中,使用后销毁,并不占用实例空间
python中的self就是java中的this,唯一区别就是self必须是实例方法的参数的第一个.其实,self只是规定了第一个参数的位置,命名什么都行,也可以用this
class Sheep:
def __init__(this,name):
this.name=name
def shout(this):
print('my name is:',this.name)
sheep=Sheep('Tom')
sheep.shout()
my name is: Tom
②python类型是动态性的,可以动态为自定义类及对象改变为新的属性和行为,俗称混入(mixin)机制
a=1
print(type(a))
a='hello'
print(type(a))
<class 'int'>
<class 'str'>
但是实际a的引用地址已经发生了改变
a=1
print(id(a))
a='hello'
print(id(a))
2734448994608
2734528578672
利用这个机制,就可以给已经创建好实例,在不修改类,不重新实例化的前提下添加新属性
class Sheep:
name=''
def shout():
pass
shp=Sheep()
print('shp:',[i for i in dir(shp) if i[0]!='_'])
shp.age=12
print('shp:',[i for i in dir(shp) if i[0]!='_'])
shp: ['name', 'shout']
shp: ['age', 'name', 'shout']
而且也可以给类添加新属性
Sheep.type='sheep'
print('Sheep:',[i for i in dir(Sheep) if i[0]!='_'])
Sheep: ['name', 'shout', 'type']
并且,再新的实例也会有type属性
shp1=Sheep()
print('shp2:',[i for i in dir(shp1) if i[0]!='_'])
shp2: ['name', 'shout', 'type']
还有方法也可以添加,但是需要导入type库
import types
def setSpeed(self,s):
self.speed=s
shp1.setSpeed=types.MethodType(setSpeed,shp1)
#绑定后,实例不但有了setSpeed方法,而且有了speed属性
shp1.setSpeed(5)
print(shp1.speed)
5
③私有不私有特点:
*XXX:一个下划线开始,表示受保护的成员,不能用from .. import导入
XXX*:系统定义的特殊成员,如__init_
__xxx:私有成员,只有类对象自己能访问,子对象不能直接访问.但在对象外部可以通过'对象名._类名__xxx'来访问,所以python中的私有并不是真正的私有
方法
python中的方法分为:实例方法,类方法,静态方法
实例方法第一个参数名为self
类方法第一个形参为cls
静态方法没有规定必须的参数
类方法用@classmethod修饰,静态方法用@staticmethod修饰
python中的静态方法不能使用类或实例中的任何属性和方法,相当于一个独立的空间,常作为工具方法使用.python中的类方法更类似于其他语言的静态方法.
共同点:
类方法和静态方法不能直接访问属于对象的成员
类方法和静态方法都可以用对象或类名来调用
class Cat:
@classmethod
def setName(cls,name='Tom'):
cls.name=name
cat=Cat()
cat1=Cat()
cat.setName('Jerry')
print(cat1.name)
print (Cat.name)
Jerry
Jerry
如上,python中的类方法的不同实例是共用空间的
python的静态方法是一个独立的空间,一般用于和类对象以及实例对象无关的代码。
class Game():
@staticmethod
def menu():
print('开始游戏')
print('设置')
print('退出游戏')
def func1():
pass
game=Game()
game.menu()
开始游戏
设置
退出游戏
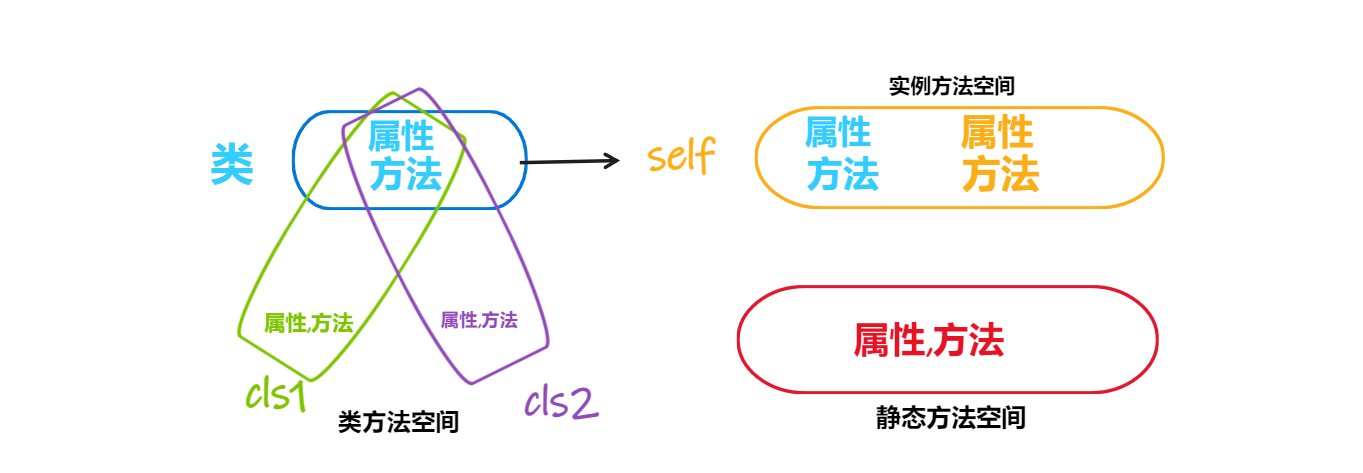
属性
class Sheep:
def __init__(self,name):
self.__name=name
def name(self):
return self.__name
sheep=Sheep('Shown')
print(sheep.name())
print(sheep.__name)
Shown
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
c:\Users\Tenerome\Desktop\python\lesson.ipynb Cell 73 in <cell line: 8>()
<a href='vscode-notebook-cell:/c%3A/Users/Tenerome/Desktop/python/lesson.ipynb#Y134sZmlsZQ%3D%3D?line=5'>6</a> sheep=Sheep('Shown')
<a href='vscode-notebook-cell:/c%3A/Users/Tenerome/Desktop/python/lesson.ipynb#Y134sZmlsZQ%3D%3D?line=6'>7</a> print(sheep.name())
----> <a href='vscode-notebook-cell:/c%3A/Users/Tenerome/Desktop/python/lesson.ipynb#Y134sZmlsZQ%3D%3D?line=7'>8</a> print(sheep.__name)
AttributeError: 'Sheep' object has no attribute '__name'
想得到sefl.__name私有变量,只能通过函数name的返回值(或用类名+私有变量名),python中的@property装饰器,用它装饰的方法可以对类的私有变量进行读写操作,将来可以通过方法名,不需要加()来对属性读写
class Sheep:
def __init__(self,name):
self.__name=name
@property
def name(self):
return self.__name
sheep=Sheep('Shown')
print(sheep.name)
Shown
上面是只读的例子,下面看可读可写的
class Sheep:
def __init__(self,name):
self.__name=name
def __get(self):
return self.__name
def __set(self,value):
self.__name=value
name=property(__get,__set)
sheep=Sheep('Shown')
print(sheep.name)
sheep.name='Tom'
print(sheep.name)
Shown
Tom
上面是第一种形式,除了getter和setter,还有del
'''class C(object):
def getx(self): return self._x
def setx(self, value): self._x = value
def delx(self): del self._x
x = property(getx, setx, delx, "I'm the 'x' property.")'''
如果不定义del的话是不能直接删除的
class Sheep:
def __init__(self,name):
self.__name=name
def __get(self):
return self.__name
def __set(self,value):
self.__name=value
def __del(self):
del self.__name
name=property(__get,__set,__del)
另一种形式:
'''class C(object):
@property def x(self):
"I am the 'x' property." return self._x
@x.setter def x(self, value):
self._x = value
@x.deleter def x(self):
del self._x'''
class Sheep:
@property
def name(self):
return self.__name
@name.setter
def name(self,name):
self.__name=name
@name.deleter
def name(self):
del self.__name
sheep=Sheep()
sheep.name='Shawn'
print(sheep.name)
# del sheep.name
# print(sheep.name)
Shawn
析构方法
实例化出来的对象都是有声明周期的,当声明周期结束时,会自动调用析构函数,默认无动作.可以在析构函数中自定义语句.析构函数用__func__表示
#在jupyter 中会直接结束对象的声明周期,在py文件中运行这段代码
class Dog:
def __eat(self):
print('i am going to eat')
def can_bite(self,condition):
if condition==1:
self.__eat()
else:
return "I can't eat"
def __del__(self):
print('Over')
dog =Dog()
con=int(input('input one number:'))
dog.can_bite(con)
del(dog)
i am going to eat
Over
继承和多态
①继承:派生类继承基类的属性和方法.
python中的派生类用class 派生类名(基类名):来定义
class A:
def hello(self):
print('hello')
class B(A):
pass
b=B()
b.hello()
hello
如果要在派生类中调用基类的方法,可以使用内置函数super().方法名或者通过基类名.方法名()来调用.私有方法在派生类中不能直接访问
class A:
def __init__(self):
__name='shawn'
self.age=12
def hello(self):
print('hello')
class B(A):
def hi(self):
super().hello()
b=B()
b.hi()
print(b.age)
print(b.__name)
hello
12
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
c:\Users\Tenerome\Desktop\python\lesson.ipynb Cell 93 in <cell line: 13>()
<a href='vscode-notebook-cell:/c%3A/Users/Tenerome/Desktop/python/lesson.ipynb#Y160sZmlsZQ%3D%3D?line=10'>11</a> b.hi()
<a href='vscode-notebook-cell:/c%3A/Users/Tenerome/Desktop/python/lesson.ipynb#Y160sZmlsZQ%3D%3D?line=11'>12</a> print(b.age)
---> <a href='vscode-notebook-cell:/c%3A/Users/Tenerome/Desktop/python/lesson.ipynb#Y160sZmlsZQ%3D%3D?line=12'>13</a> print(b.__name)
AttributeError: 'B' object has no attribute '__name'
python也支持多继承(C++也支持,java不支持)
②多态(重载)
多态:指基类的同一个方法在不同派生类对象中具有不同的表现和行为.
class Animal:
def eat(self):
print('吃')
def run(self):
print('跑')
class Dog(Animal):
def run(self): #子类重写父类方法
print('用四个腿跑')#如果想继续调用父类的方法,可以使用super().方法()
dog=Dog()
dog.run()
用四个腿跑
文本
文本文件操作
对文本文件操作,用with open() as f. open是python的内置函数,有三个参数open(filename,mode,encoding),mode是操作模式,有读,写,读写三种.
with open('1.txt','r') as f:
print(f.read())
Hello world
Nice to meet you
'r':读模式,read()函数,读取文件内容,返回一个str
'w':写模式
'r+'或'w+':读写,不能用rw
'a':追加
with open('1.txt','r+') as f:
f.write('哈尔滨商业大学')
print(f.read())
print(f.read())
#不能同时读写?
文件的补充
with open('1.txt','r/w') as f:
这句执行后,r模式会把游标移动到最前面,w模式会清空内容
如果文件不存在,r模式会报错.w模式会自动创建新文件
f.read()会从当前游标位置读取到文档end
f.write()会从当前位置,向后写
①r模式,游标在最前面,先写后读,会覆盖前面的字符,原文档:

r+模式,先写后读
with open('1.txt','r+') as f:
f.write('Hello')
print(f.read())
6789
f.write()从最前面开始覆盖写,游标停止在o后,开始读,所以读到的是6789

r+模式,先读后写
with open('1.txt','r+') as f:
print(f.read())
f.write('nnnn')
Hello6789
r+模式,开始游标在head,读所有的字符,读完游标在最后,写的内容追加到end

w+模式,先把内容清空
with open('1.txt','w+') as f:
pass

先写后读
with open('1.txt','w+') as f:
f.write('MMMM')
print(f.read())

能写进去,但写完之后游标在end,自然就读取不到,想要读内容,需要用f.seek()移动游标
with open('1.txt','w+') as f:
f.write('MMMM')
f.seek(0)
print(f.read())
MMMM
w+模式,先读后写
with open('1.txt','w+') as f:
print(f.read())
f.write('nnnn')

w+模式先清空,所以什么都读不到,然后把内容写进去
a+模式打开时游标默认也在末尾,且文件不存在也新建
二进制文件操作
使用pickle库序列化对象,就是把二进制数据存储在磁盘上
import pickle
i=133000
a=99.23
s='Hello'
lst=[[1,2,3],[4,5,6]]
tu=(2,3,6)
coll={2,4,7}
dic={'a':'apple','b':'banana'}
data=[i,a,s,lst,tu,coll,dic]
想把这些数据存下来
with open('sample.dat','wb') as f:
try:
pickle.dump(len(data),f)
for item in data:
pickle.dump(item,f)
except:
print('写文件异常')
读写二进制文件,就是在w/r/a后面加b,pickle.dump(obj,file_writeable),dump()函数可以把任意对象写入一个可写的文件对象中
使用pickle库反序列化对象
with open('sample.dat','rb') as f:
n=pickle.load(f)
for i in range(n):
x=pickle.load(f)
print(x)
print(type(x))
133000
<class 'int'>
99.23
<class 'float'>
Hello
<class 'str'>
[[1, 2, 3], [4, 5, 6]]
<class 'list'>
(2, 3, 6)
<class 'tuple'>
{2, 4, 7}
<class 'set'>
{'a': 'apple', 'b': 'banana'}
<class 'dict'>
使用pickle.load()读取二进制文件,返回any,根据不同的类型,x的类型动态变化
OS和OS.path模块
open()用来读写单个文件,如果想对目录中的文件读写,需要OS,OS.path库
OS库:
getcwd(): 获取当前目录的path
mkdir(): 创建目录
listdir(path): 返回path目录下的文件和子目录列表
walk(top,topdown=True,onerror=None): 遍历目录树,就是所有目录及其子目录的所有文件
remove(path):删除指定文件,要求用户拥有删除文件的权限,并且文件没有只读或其他特殊属性
rename(src,dst):重命名文件或目录,可以实现文件的移动
startfile(filepath[,operation] ):使用关联的应用程序打开指定文件或启动指定应用程序
OS.path库:
os.path
import os
import os.path
for i in os.listdir():
if os.path.isfile(i) and i.endswith('.py'):
print(i)
test.py
os.path.isfile(path):判断是否为文件,返回bool
S.endswith('suffix'):Return True if S ends with the specified suffix
os.path.exist(path):判断当前路径是否存在指定的目录或文件
os.path.dirname('1.txt'):获取文件的目录部分,是相对路径
os.path.splittext('1.png'):分隔文件名和扩展名,运行结果:('1','png')
os.path.join(path,*path),连接两个或多个path
本文来自博客园,作者:Tenerome,转载请注明原文链接:https://www.cnblogs.com/Tenerome/articles/PythonCourse1.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号