
10个基础数据结构学习记录
10 个数据结构:数组、链表、栈、队列、跳表、散列表、二叉树、堆、图、Trie 树。
《数据结构与算法之美》王争 再看一次吧。 加深理解。 第三次看总结下
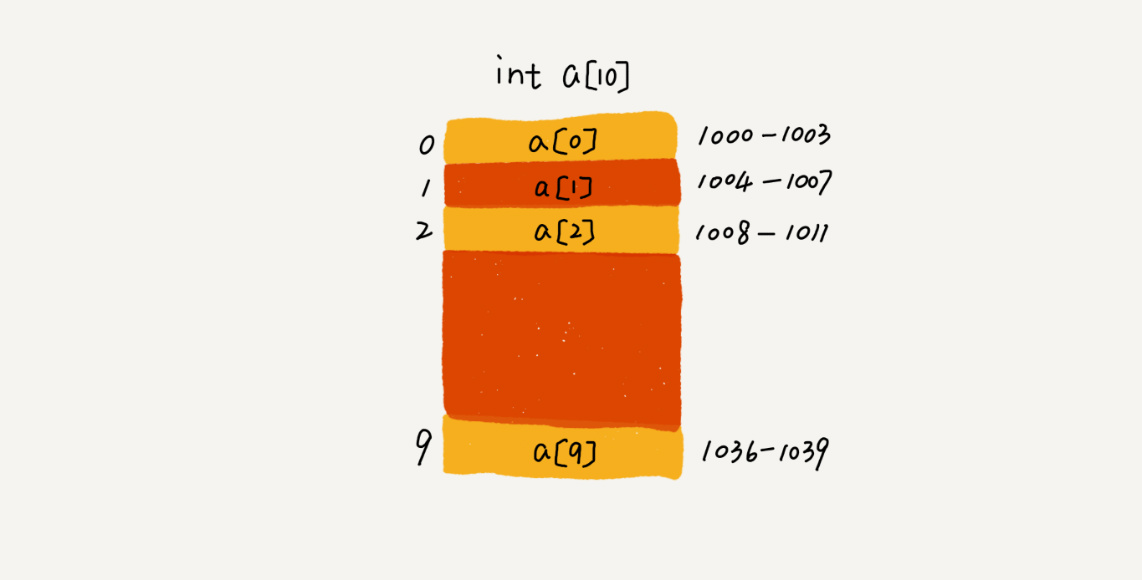
1.数组:
概念:线性表,连续的内存空间和相同类型的数据
优点:查找快,根据下标随机访问的时间复杂度为 O(1)
缺点:插入删除慢,内存大小固定
问题:为什么数组要从 0 开始编号,而不是从 1 开始呢?
(寻址公式:a[i]_address = base_address + i * data_type_size)
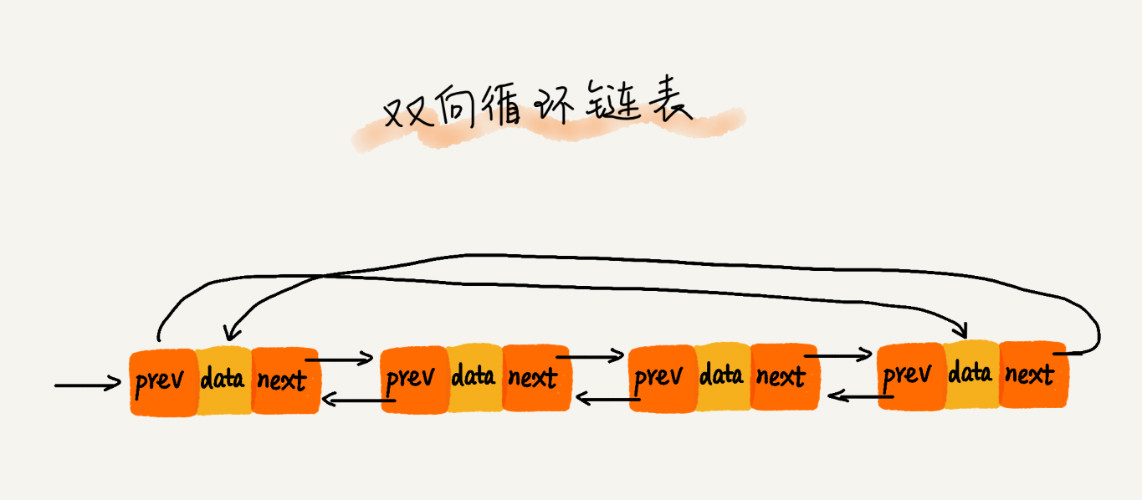
2.链表(单链表,循环链表,双向链表):
概念:不连续内存,通过指针连接零散内存块
优点:插入删除快 时间复杂度为 O(1)
缺点:查询慢 需要遍历 O(n)
问题:如何基于链表实现 LRU 缓存淘汰算法?
(1.已存在,删除并且插入新节点到头部。2.不存在缓存未满,直接插入头部。3.不存在缓存已满,删除尾部节点,插入头部节点)
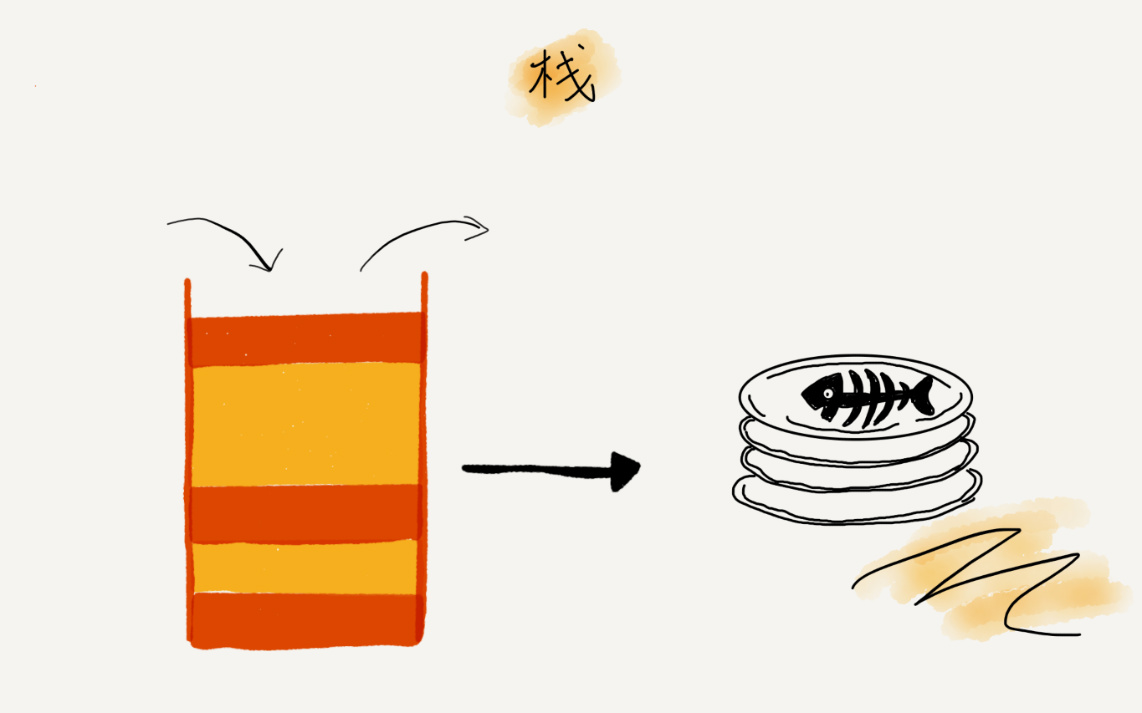
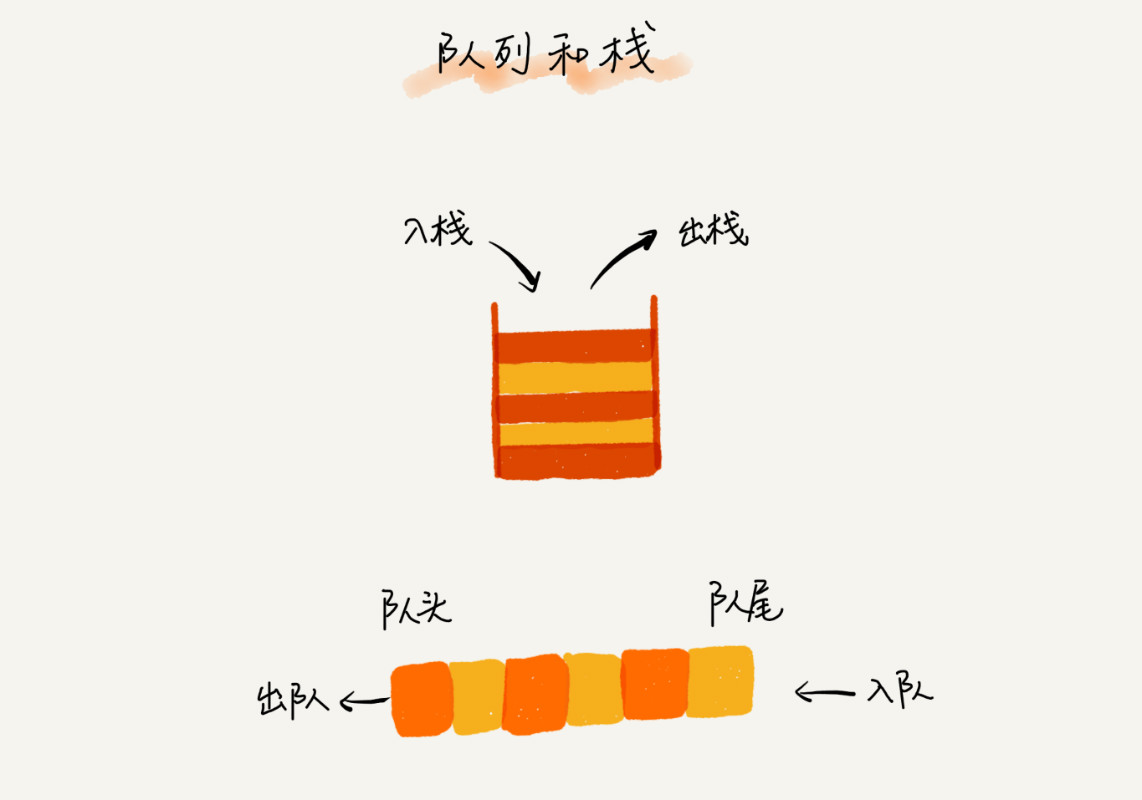
3.栈:
概念:后进者先出,先进者后出,只允许一端插入删除数据
问题:如何实现浏览器前进后退?(两个栈实现)
4.队列:
概念:排队 先进先出
问题:线程池怎么处理线程的分配?
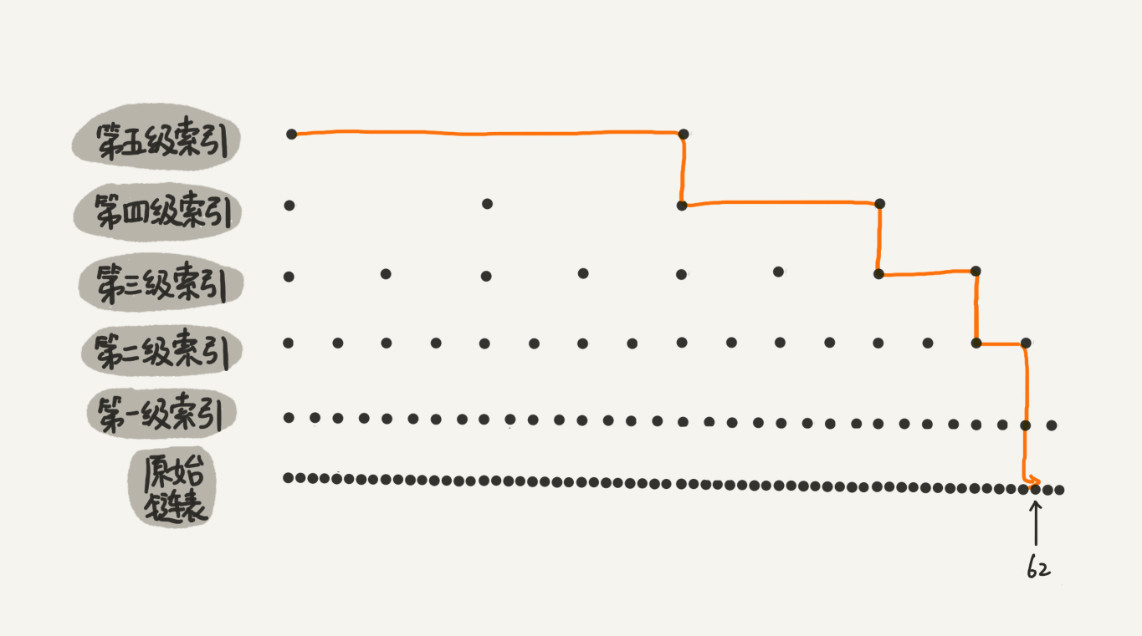
5.跳表skip list:
概念:链表加多级索引的结构,就是跳表
特点:空间换时间,不过不像数据库索引 。 可以忽略这个内存大小
问题:那 Redis sortset为什么会选择用跳表来实现有序集合呢? 为什么不用红黑树呢
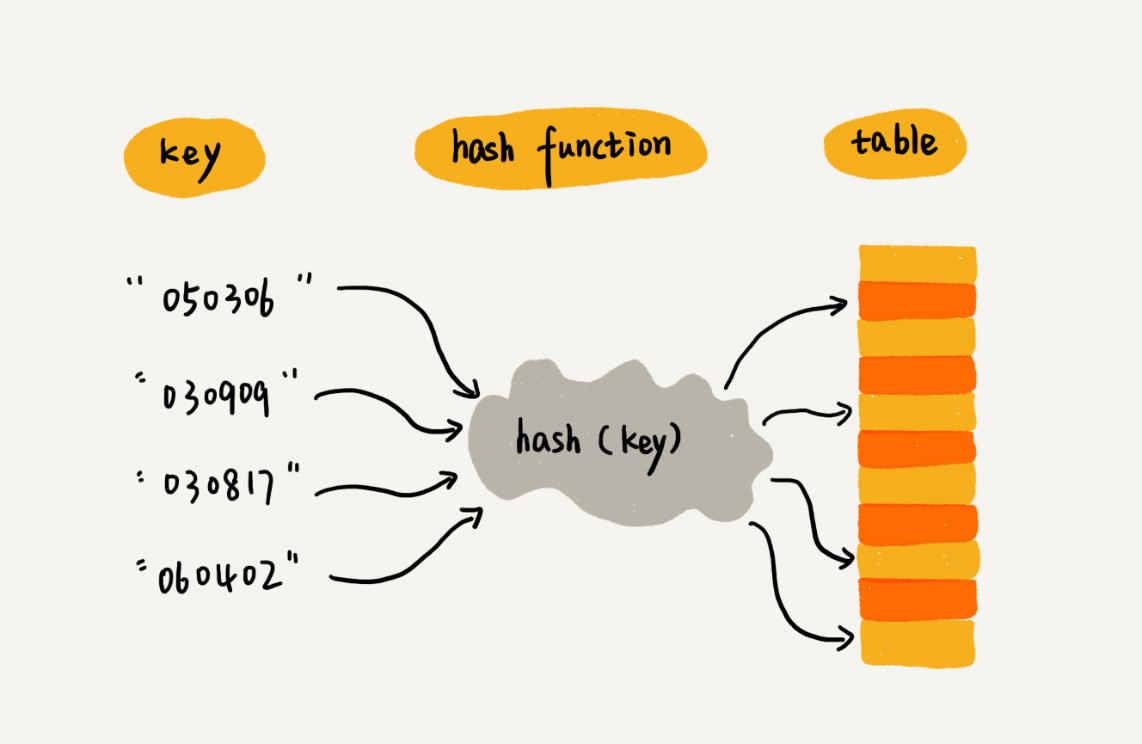
6.散列表
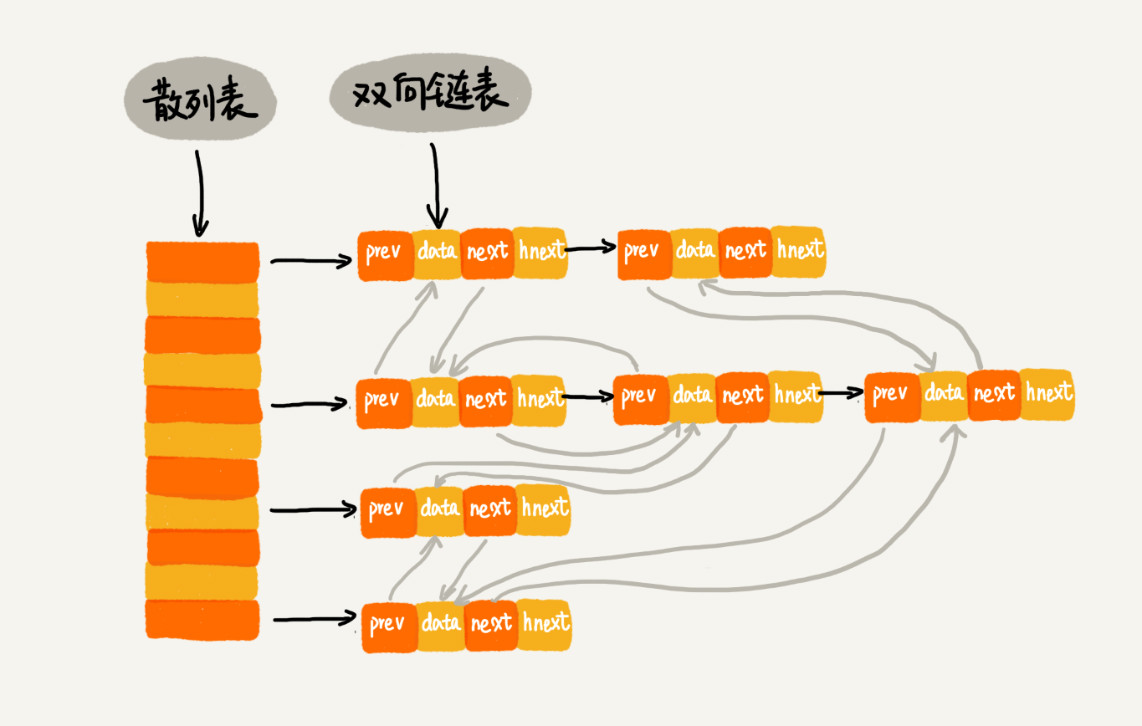
概念:散列表来源于数组,用散列函数获取唯一key作为数组下表,和链表一起使用更佳
缺点:散列冲突
问题:Word文档中单词拼写检查功能是如何实现的?(就是弄一张散列表存了所有英文字母,然后查一下)
7.树:
根节点、叶子节点、父节点、子节点、兄弟节点,还有节点的高度、深度、层数,高度
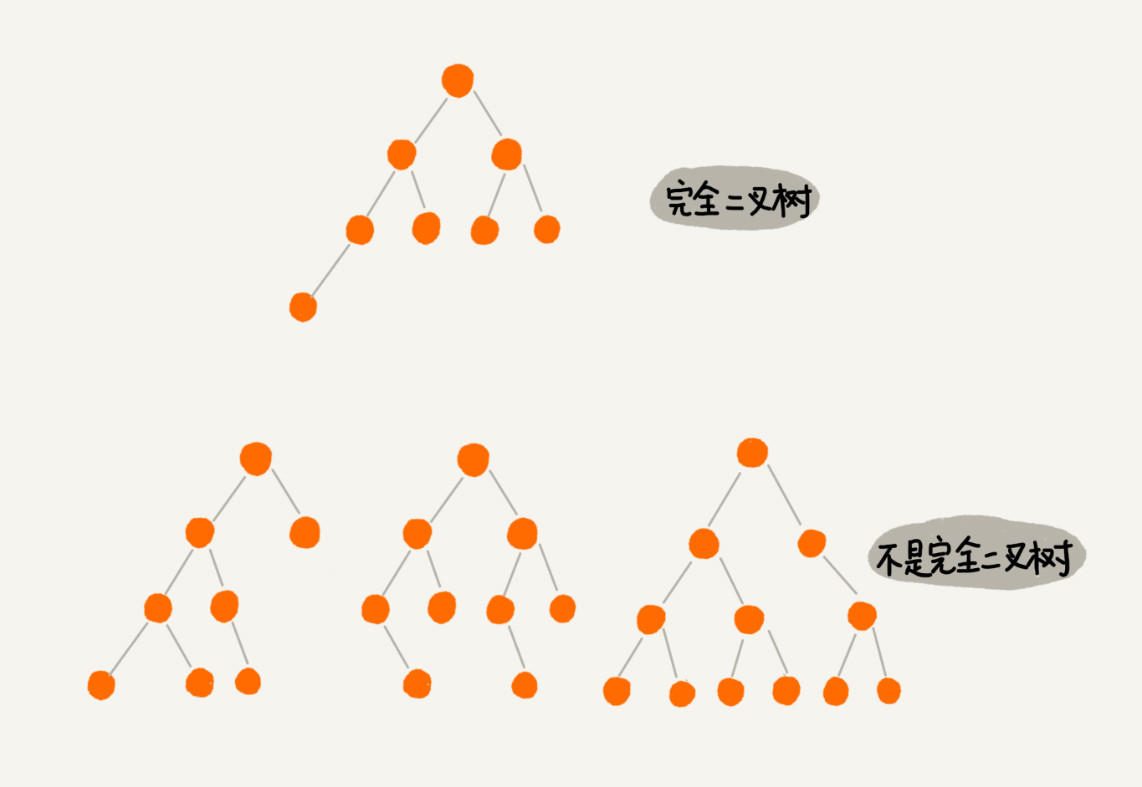
满二叉树:满了,叶子节点全都在最底层,除了叶子节点之外,每个节点都有左右两个子节点,这种二叉树就叫做满二叉树
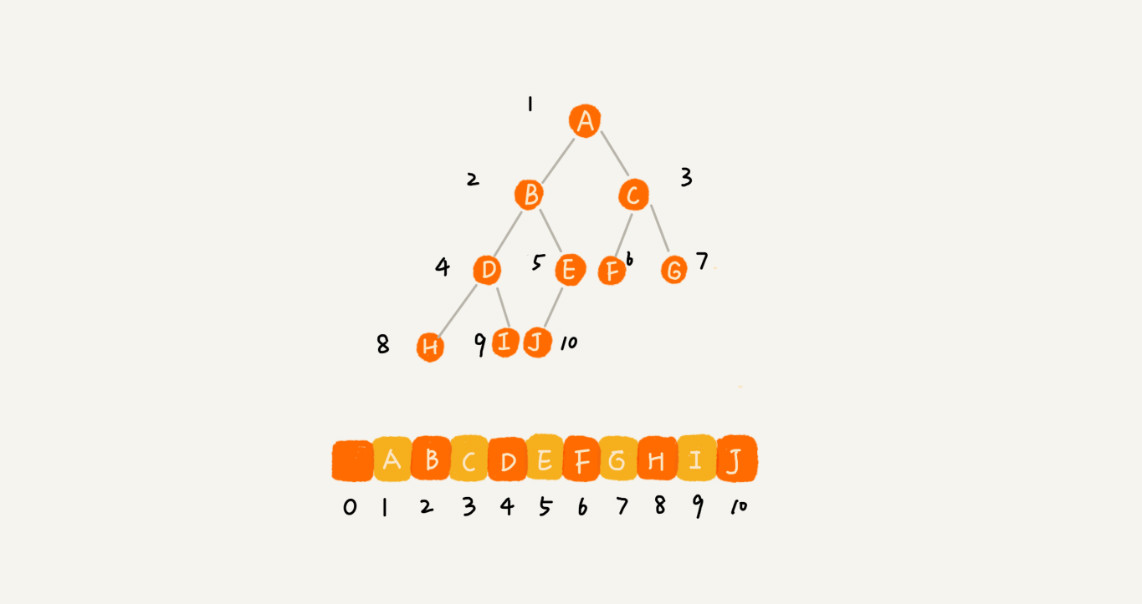
完全二叉树:叶子节点都在最底下两层,最后一层的叶子节点都靠左排列,并且除了最后一层,其他层的节点个数都要达到最大,这种二叉树叫做完全二叉树
链式存储法:
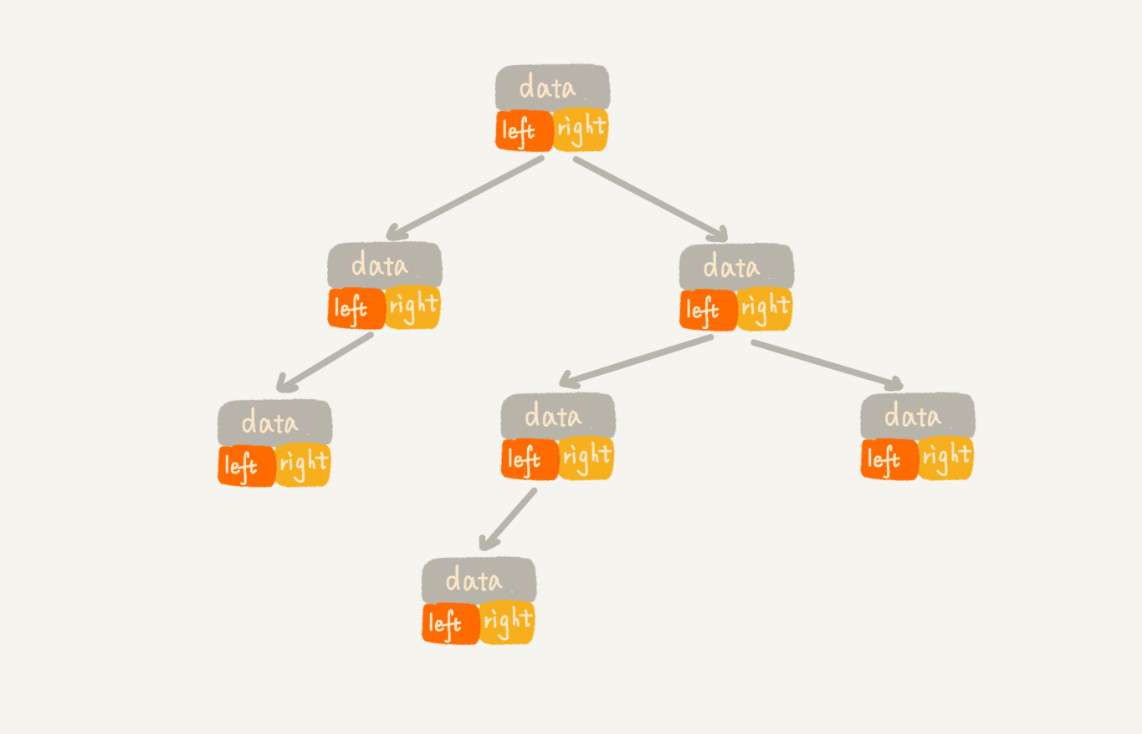
顺序存储法:(为什么偏偏把最后一层的叶子节点靠左排列的叫完全二叉树?如果靠右排列就不能叫完全二叉树了吗?这个定义的由来或者说目的在哪里?就是通过这张图解释)
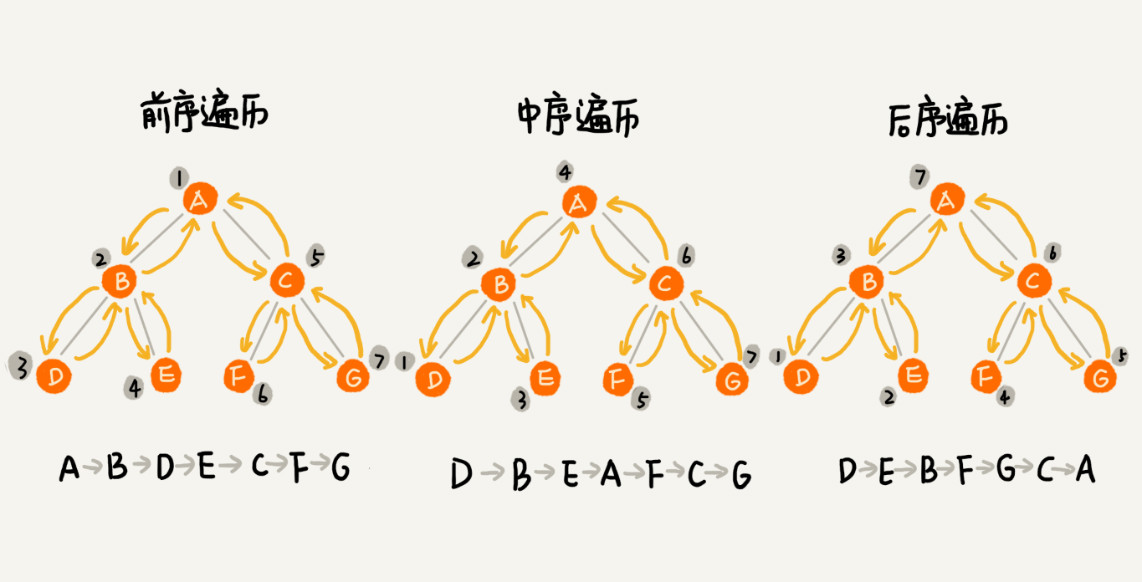
前中后 遍历
二叉查找树:
在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都大于这个节点的值。
缺点:极度不平衡的二叉查找树,退化成链表
散列表的插入、删除、查找操作的时间复杂度可以做到常量级的 O(1),非常高效。而二叉查找树在比较平衡的情况下,插入、删除、查找操作时间复杂度才是 O(logn),相对散列表,好像并没有什么优势,那我们为什么还要用二叉查找树呢?
(1.散列表无序,扩容问题,散列冲突问题)
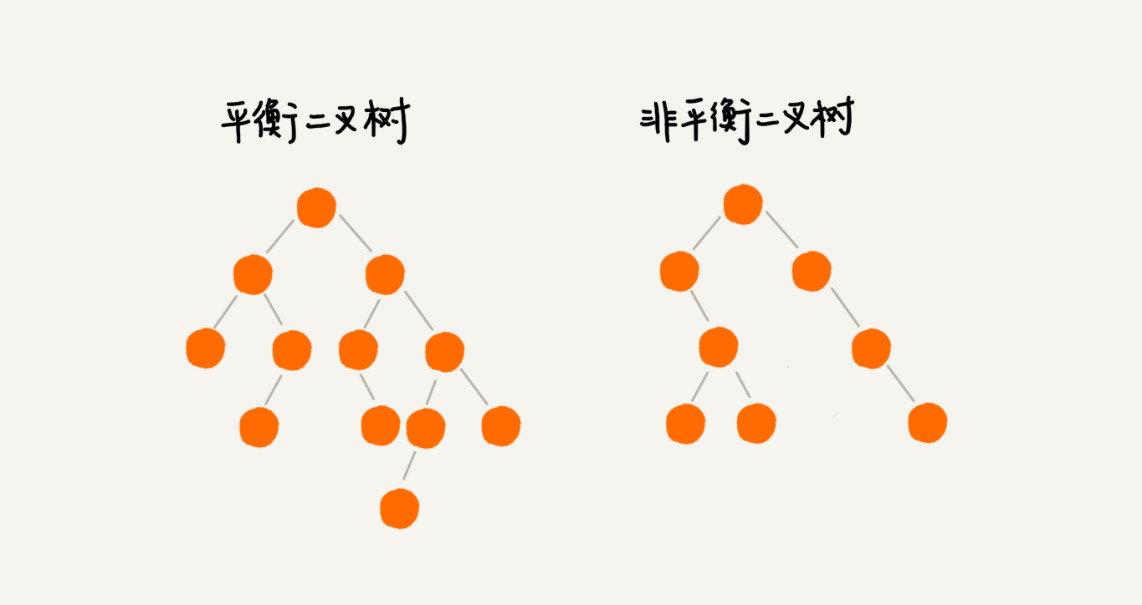
平衡二叉查找树:二叉树中任意一个节点的左右子树的高度相差不能大于1
平衡二叉查找树中“平衡”的意思,其实就是让整棵树左右看起来比较“对称”、比较“平衡”,不要出现左子树很高、右子树很矮的情况。这样就能让整棵树的高度相对来说低一些,相应的插入、删除、查找等操作的效率高一些。
红黑树:
红黑树是一种平衡二叉查找树。它是为了解决普通二叉查找树在数据更新的过程中,复杂度退化的问题而产生的。红黑树的高度近似 log2n,所以它是近似平衡,插入、删除、查找操作的时间复杂度都是 O(logn)。因为红黑树是一种性能非常稳定的二叉查找树,所以,在工程中,但凡是用到动态插入、删除、查找数据的场景,都可以用到它。不过,它实现起来比较复杂,如果自己写代码实现,难度会有些高,这个时候,我们其实更倾向用跳表来替代它。
8.9.10
堆,图,trie树 略
总结:
**基本数据结构**
1.数组:连续的内存空间,支持按下标随机访问O(1),删除和查找设计数据搬移效率是O(n) 试用场景:数据规模较小,不经常变动。
缺点:对于内存连续性要求高。插入删除操作效率低。
2.链表:查询效率不高O(n),插入和删除效率高O(1),并且内存申请可以不连续,适用场景是插入和删除多于查询操作。
缺点:查找效率低,实际上删除之前先要查找,所以实际删除效率也不高。
**动态数据结构**
1.散列表:可以说是利用数组和链表两个基本数据结构设计了一个高效的动态数据结构。利用了数组的随机访问特性,用于满足根据某个属性来随机访问元素。基于key查找效率很高O(1).同时借助链表进行散列冲突解决方案,删除和插入操作效率也可以接近O(1).试用场景:海量数据随机访问、防止重复、缓存等。缺点:需要设计合理的散列函数,并且要考虑散列冲突和动态扩容。
2.跳表:尽管散列表效率很高,但是散列表是无序的,跳表效率和散列表类似,并且支持区间序列的输出(因为基于链表)。使用场景:对有序元素的快速查找、插入和删除。
缺点:比较占用内存。
3.红黑树:红黑树是平衡二叉查找树的一种近似实现。红黑树和跳表类似,但是实现方式有所差异。红黑树存在的价值是,它可以实现比较高效的查找,删除和插入。虽然相比高度平衡的AVL树效率有所下降,但是红黑树不用耗费太多精力维护平衡。相比跳表,红黑树除了内存占用较小,其他性能并不比跳表更优。但由于历史原因,红黑树使用的更广泛。
缺点:实现比较复杂。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号