【Python3爬虫】12306爬虫
此次要实现的目标是登录12306网站和查看火车票信息。
具体步骤
一、登录
登录功能是通过使用selenium实现的,用到了超级鹰来识别验证码。没有超级鹰账号的先注册一个账号,充值一点题分,然后把下载这个Python接口文件,再在里面添加一个use_cjy的函数,以后使用的时候传入文件名就可以了(验证码类型和价格可以在价格体系查看):
1 def use_cjy(filename): 2 username = "" # 用户名 3 password = "" # 密码 4 app_id = "" # 软件ID 5 cjy = CJYClient(username, password, app_id) # 用户中心>>软件ID 6 im = open(filename, 'rb').read() # 本地图片文件路径 7 return cjy.PostPic(im, 9004) # 9004->验证码类型
然后进入12306的登录页面,网址为https://kyfw.12306.cn/otn/login/init,可以看到有一个像下面这样的验证码:
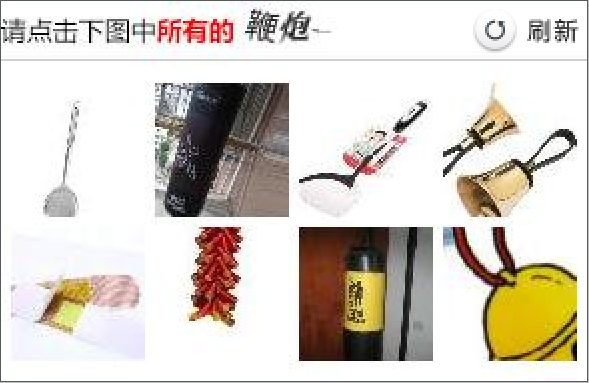
要破解这个验证码,第一个问题是怎么得到这个验证码图片,我们可以很轻松的找到这个验证码图片的链接,但是如果用requests去请求这个链接,然后把图片下载下来,这样得到的图片和网页上的验证码图片是不同的,因为每次请求都会刷新一次验证码。所以需要换个思路,比如先把网页截个图,然后我们可以知道验证码图片在网页中的位置,然后再根据这个位置,把截图相应的位置给截取出来,就相当于把验证码图片从整个截图中给抠出来了,这样得到的验证码图片就和网页上的验证码一样了。相关代码如下:
1 # 定位到验证码图片 2 captcha_img = browser.find_element_by_xpath('//*[@id="loginForm"]/div/ul[2]/li[4]/div/div/div[3]/img') 3 location = captcha_img.location 4 size = captcha_img.size 5 # 写成我们需要截取的位置坐标 6 coordinates = (int(location['x']), int(location['y']), 7 int(location['x'] + size['width']), int(location['y'] + size['height'])) 8 browser.save_screenshot('screen.png') 9 i = Image.open('screen.png') 10 # 使用Image的crop函数,从截图中再次截取我们需要的区域 11 verify_code_image = i.crop(coordinates) 12 verify_code_image.save('captcha.png')
现在已经得到了验证码图片了,下一个问题是怎么识别?点触验证码识别起来有两个难点,一个是文字识别,要把图上的鞭炮文字识别出来,第二点是识别图片中的内容,比如上图就要把有鞭炮的图片识别出来,而这两个难点利用OCR技术都很那实现,因此选择使用打码平台(比如超级鹰)来识别验证码。对于上面这个图,在使用超级鹰识别之后会返回下面这个结果:
{'pic_id': '6048511471893900001', 'err_no': 0, 'err_str': 'OK', 'md5': 'bde1de3b886fe2019a252934874c6669', 'pic_str': '117,140'}
其中pic_str对应的值就是有鞭炮的图片的坐标位置(如果有多个坐标,会用“|”进行分隔),我们对这个结果进行解析,把坐标提取出来,再利用selenium模拟点击就可以了,相关代码如下:
1 # 调用超级鹰识别验证码 2 capture_result = use_cjy('captcha.png') 3 print(capture_result) 4 # 对返回的结果进行解析 5 groups = capture_result.get("pic_str").split('|') 6 points = [[int(number) for number in group.split(',')] for group in groups] 7 for point in points: 8 # 先定位到验证图片 9 element = WebDriverWait(browser, 20).until( 10 EC.presence_of_element_located((By.CLASS_NAME, "touclick-bgimg"))) 11 # 模拟点击验证图片 12 ActionChains(browser).move_to_element_with_offset(element, point[0], point[1]).click().perform() 13 sleep(1)
二、查询
带有车票信息的ajax接口很容易找到,格式也是标准的json格式,解析起来会方便不少

但是爆保存车票的字符串很复杂,我们先把第一条信息打印出来看看,以下是部分信息:
'hH0qeKPBgl0X0aCnrtZFyBgzqydzV45U2M1r%2F32FsaPHeb7Mul00sIb7y9W%2B6df1tUdDGCxqdVs8%0Aw2VodSjdXjUQ2uNdwFprKdVK9iaW60Wj2jKpNKaViR4ndlBCjsYB0SIF
QR0pLksy7HDP0KcaoLe4%0A4RW6zRcscO7SRNJZOsF%2Fxj3Ooq76lzzdku3Uw957yjLFyf7ikixOaC%2FAOrLAwCc7y0krRpKJbSn3%0ApBsY%2F%2Fok%2Bmg2xNhXapoCPIt4w0p9', 这段字符是随机生成的,过几秒就回失效。 '39000D30280G', 列车编号 'D3028', 车次 'HKN', 始发站 'AOH', 终点站 'HKN', 出发站 'AOH', 目的站 '07:31', 出发时间 '13:06', 到达时间 '05:35', 总耗时 'Y', Y表示可以购票,N表示不可以 '20181111', 日期
后面基本都是座位的余票信息了。
对于提到的列车站点代码,可以通过请求这个链接,通过得到JS脚本中的station_names变量获取,对应的站点以@字符分隔,相关代码如下:
1 # 请求保存列车站点代码的链接 2 res1 = requests.get("https://kyfw.12306.cn/otn/resources/js/framework/station_name.js") 3 # 把分割处理后的车站信息保存在station_data中 4 self.station_data = res1.text.lstrip("var station_names ='").rstrip("'").split('@')
1 # 返回车站英文缩写 2 def get_station(self, city): 3 for i in self.station_data: 4 if city in i: 5 return i.split('|')[2] 6 7 # 返回车站中文缩写 8 def get_city(self, station): 9 for i in self.station_data: 10 if station in i: 11 return i.split('|')[1]
由于ajax接口有了一点变化,所以我对之前的代码做了一点修改,在输入数据的部分:
1 # 需要按2018-01-01的格式输入日期,不然会出现错误 2 d = input("请输入日期(如:2018-01-01):") 3 f = self.get_station(input("请输入您的出发站:")) 4 t = self.get_station(input("请输入您的目的站:")) 5 url = "https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date={}&leftTicketDTO.from_station={}" \ 6 "&leftTicketDTO.to_station={}&purpose_codes=ADULT".format(d, f, t)
完整代码已上传到GitHub!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号