通过源码学习@functools.lru_cache
一、前言
通常在一些代码中包含了重复运算,而这些重复运算会大大增加代码运行所耗费的时间,比如使用递归实现斐波那契数列。
举个例子,当求 fibonacci(5) 时,需要求得 fibonacci(3) 和 fibonacci(4) 的结果,而求 fibonacci(4) 时,又需要求 fibonacci(2) 和 fibonacci(3) ,但此时 fibonacci(3) 就被重新计算一遍了,继续递归下去,重复计算的内容就更多了。求 fibonacci(5) 的代码和运行结果如下:
1 def fibonacci(n): 2 # 递归实现斐波那契数列 3 print("n is {}".format(n)) 4 if n < 2: 5 return n 6 return fibonacci(n - 2) + fibonacci(n - 1) 7 8 9 if __name__ == '__main__': 10 fibonacci(5) 11 12 # n is 5 13 # n is 3 14 # n is 1 15 # n is 2 16 # n is 0 17 # n is 1 18 # n is 4 19 # n is 2 20 # n is 0 21 # n is 1 22 # n is 3 23 # n is 1 24 # n is 2 25 # n is 0 26 # n is 1
从打印的结果来看,有很多重复计算的部分,传入的 n 越大,重复计算的部分就越多,程序的耗时也大大增加,例如当 n = 40 时,运行耗时已经很长了,代码如下:
1 import time 2 3 4 def fibonacci(n): 5 # 递归实现斐波那契数列 6 if n < 2: 7 return n 8 return fibonacci(n - 2) + fibonacci(n - 1) 9 10 11 if __name__ == '__main__': 12 print("Start: {}".format(time.time())) 13 print("Fibonacci(40) = {}".format(fibonacci(40))) 14 print("End: {}".format(time.time())) 15 16 # Start: 1594197671.6210408 17 # Fibonacci(40) = 102334155 18 # End: 1594197717.8520994
二、@functools.lru_cache
1.使用方法
@functools.lru_cache 是一个装饰器,所谓装饰器,就是在不改变原有代码的基础上,为其增加额外的功能,例如打印日志、计算运行时间等,该装饰器的用法如下:
1 import functools 2 3 4 @functools.lru_cache(100) 5 def fibonacci(n): 6 # 递归实现斐波那契数列 7 print("n is {}".format(n)) 8 if n < 2: 9 return n 10 return fibonacci(n - 2) + fibonacci(n - 1) 11 12 13 if __name__ == '__main__': 14 fibonacci(5) 15 16 # n is 5 17 # n is 3 18 # n is 1 19 # n is 2 20 # n is 0 21 # n is 4
从打印的结果来看,从0到5都只计算了一遍,没有出现重复计算的情况,那当 n = 40 时,程序的耗时情况又是如何呢?代码如下:
1 import time 2 import functools 3 4 5 @functools.lru_cache(100) 6 def fibonacci(n): 7 # 递归实现斐波那契数列 8 if n < 2: 9 return n 10 return fibonacci(n - 2) + fibonacci(n - 1) 11 12 13 if __name__ == '__main__': 14 print("Start: {}".format(time.time())) 15 print("Fibonacci(40) = {}".format(fibonacci(40))) 16 print("End: {}".format(time.time())) 17 18 # Start: 1594197813.2185402 19 # Fibonacci(40) = 102334155 20 # End: 1594197813.2185402
从结果可知,没有了这些重复计算,程序运行所耗费的时间也大大减少了。
2.源码解析
在 Pycharm 中点击 lru_cache 可以查看源码,其源码如下:
def lru_cache(maxsize=128, typed=False): """Least-recently-used cache decorator. If *maxsize* is set to None, the LRU features are disabled and the cache can grow without bound. If *typed* is True, arguments of different types will be cached separately. For example, f(3.0) and f(3) will be treated as distinct calls with distinct results. Arguments to the cached function must be hashable. View the cache statistics named tuple (hits, misses, maxsize, currsize) with f.cache_info(). Clear the cache and statistics with f.cache_clear(). Access the underlying function with f.__wrapped__. See: http://en.wikipedia.org/wiki/Cache_algorithms#Least_Recently_Used """ # Users should only access the lru_cache through its public API: # cache_info, cache_clear, and f.__wrapped__ # The internals of the lru_cache are encapsulated for thread safety and # to allow the implementation to change (including a possible C version). # Early detection of an erroneous call to @lru_cache without any arguments # resulting in the inner function being passed to maxsize instead of an # integer or None. if maxsize is not None and not isinstance(maxsize, int): raise TypeError('Expected maxsize to be an integer or None') def decorating_function(user_function): wrapper = _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo) return update_wrapper(wrapper, user_function) return decorating_function
注释的第一行就指明了这是一个 LRU 缓存装饰器(“Least-recently-used cache decorator”)。如果 maxsize 参数被设置为 None,则禁用了 LRU 特性,且缓存可以无限制地增长;如果 typed 参数被设置为 True,则不同类型的参数会被视为不同的调用,例如 f(3.0) 和 f(3) 就会被视为不同的调用,其结果也就不同了。
再看代码部分,maxsize 只能为 None 或者 int 类型数据,然后就是一个装饰的函数 decorating_function,包含了两个函数 _lru_cache_wrapper 和 update_wrapper,而其中主要功能包含在 _lru_cache_wrapper() 函数中,其源码如下:
1 def _lru_cache_wrapper(user_function, maxsize, typed, _CacheInfo): 2 # Constants shared by all lru cache instances: 3 sentinel = object() # unique object used to signal cache misses 4 make_key = _make_key # build a key from the function arguments 5 PREV, NEXT, KEY, RESULT = 0, 1, 2, 3 # names for the link fields 6 7 cache = {} 8 hits = misses = 0 9 full = False 10 cache_get = cache.get # bound method to lookup a key or return None 11 cache_len = cache.__len__ # get cache size without calling len() 12 lock = RLock() # because linkedlist updates aren't threadsafe 13 root = [] # root of the circular doubly linked list 14 root[:] = [root, root, None, None] # initialize by pointing to self 15 16 if maxsize == 0: 17 18 def wrapper(*args, **kwds): 19 # No caching -- just a statistics update after a successful call 20 nonlocal misses 21 result = user_function(*args, **kwds) 22 misses += 1 23 return result 24 25 elif maxsize is None: 26 27 def wrapper(*args, **kwds): 28 # Simple caching without ordering or size limit 29 nonlocal hits, misses 30 key = make_key(args, kwds, typed) 31 result = cache_get(key, sentinel) 32 if result is not sentinel: 33 hits += 1 34 return result 35 result = user_function(*args, **kwds) 36 cache[key] = result 37 misses += 1 38 return result 39 40 else: 41 42 def wrapper(*args, **kwds): 43 # Size limited caching that tracks accesses by recency 44 nonlocal root, hits, misses, full 45 key = make_key(args, kwds, typed) 46 with lock: 47 link = cache_get(key) 48 if link is not None: 49 # Move the link to the front of the circular queue 50 link_prev, link_next, _key, result = link 51 link_prev[NEXT] = link_next 52 link_next[PREV] = link_prev 53 last = root[PREV] 54 last[NEXT] = root[PREV] = link 55 link[PREV] = last 56 link[NEXT] = root 57 hits += 1 58 return result 59 result = user_function(*args, **kwds) 60 with lock: 61 if key in cache: 62 # Getting here means that this same key was added to the 63 # cache while the lock was released. Since the link 64 # update is already done, we need only return the 65 # computed result and update the count of misses. 66 pass 67 elif full: 68 # Use the old root to store the new key and result. 69 oldroot = root 70 oldroot[KEY] = key 71 oldroot[RESULT] = result 72 # Empty the oldest link and make it the new root. 73 # Keep a reference to the old key and old result to 74 # prevent their ref counts from going to zero during the 75 # update. That will prevent potentially arbitrary object 76 # clean-up code (i.e. __del__) from running while we're 77 # still adjusting the links. 78 root = oldroot[NEXT] 79 oldkey = root[KEY] 80 oldresult = root[RESULT] 81 root[KEY] = root[RESULT] = None 82 # Now update the cache dictionary. 83 del cache[oldkey] 84 # Save the potentially reentrant cache[key] assignment 85 # for last, after the root and links have been put in 86 # a consistent state. 87 cache[key] = oldroot 88 else: 89 # Put result in a new link at the front of the queue. 90 last = root[PREV] 91 link = [last, root, key, result] 92 last[NEXT] = root[PREV] = cache[key] = link 93 # Use the cache_len bound method instead of the len() function 94 # which could potentially be wrapped in an lru_cache itself. 95 full = (cache_len() >= maxsize) 96 misses += 1 97 return result 98 99 def cache_info(): 100 """Report cache statistics""" 101 with lock: 102 return _CacheInfo(hits, misses, maxsize, cache_len()) 103 104 def cache_clear(): 105 """Clear the cache and cache statistics""" 106 nonlocal hits, misses, full 107 with lock: 108 cache.clear() 109 root[:] = [root, root, None, None] 110 hits = misses = 0 111 full = False 112 113 wrapper.cache_info = cache_info 114 wrapper.cache_clear = cache_clear 115 return wrapper
可以看到根据 maxsize 的值会返回不同的 wrapper 函数。当 maxsize 为零时,定义了一个局部变量 misses,并在每次调用时加1;当 maxsize 为 None 时,在函数调用时会先从缓存中获取,若缓存中有就返回结果,若缓存中没有则运行函数并将结果加入到缓存中;当 maxsize 为非零整数时,可以缓存最多 maxsize 个此函数的调用结果,此时使用了一个双向链表 root,其初始化如下:
root = [] # root of the circular doubly linked list
root[:] = [root, root, None, None] # initialize by pointing to self
当调用时也会先从缓存中进行获取,如果有则更新 root 并返回结果,如果没有则调用函数,此时需要判断缓存是否达到最大数量,若已满,则删除 root 中最久未访问的数据并更新 root 和缓存。
三、LRU Cache
1.基本认识
我们知道计算机的缓存容量有限,如果缓存满了就要删除一些内容,给新内容腾位置。但问题是,删除哪些内容呢?
LRU 缓存策略就是一种常用的策略。LRU,全称 least recently used,表示最近最少使用。LRU 缓存策略认为最近使用过的数据应该是是有用的,而很久都没用过的数据应该是无用的,内存满了就优先删那些很久没用过的数据。
2.自定义实现
实现 lru cache 需要两个数据结构:双向链表和哈希表,双向链表用于记录存储数据的顺序,用于淘汰最久未使用的数据,哈希表用于记录元素位置,可在 O(1) 的时间复杂度下获取元素。
然后要实现两个操作,分别是 get 和 put:
1)get 操作:根据传入的 key 从哈希表中获取元素的位置,若没有返回 None,若有则从链表中获取元素并将该元素移到链表尾部;
2)put 操作:首先判断传入的 key 是否在哈希表中存在,若有则进行更新,并将该元素移到链表尾部;若没有,表示是一个新元素,需要添加到哈希表中,再判断数据量是否超过最大容量,若达到最大容量则删除最久未使用的数据,即链表头部元素,再将新元素添加到链表尾部,若未达到最大容量则直接添加到链表尾部。
首先要实现双向链表,代码如下:
1 # Node of the list 2 class Node: 3 def __init__(self, val): 4 self.val = val 5 self.prev = None 6 self.next = None 7 8 def __str__(self): 9 return "The value is " + str(self.val) 10 11 12 # Double Linked List 13 class DoubleList: 14 def __init__(self): 15 self.head = None 16 self.tail = None 17 18 def is_empty(self): 19 """ 20 returns true if the list is empty, false otherwise 21 :return: 22 """ 23 return self.head is None 24 25 def append(self, value): 26 """ 27 append element after the list 28 :param value: the value of node 29 :return: 30 """ 31 node = Node(value) 32 if self.is_empty(): 33 self.head = node 34 self.tail = node 35 return 36 cur = self.head 37 # find the tail of the list 38 while cur.next: 39 cur = cur.next 40 cur.next = node 41 node.prev = cur 42 self.tail = node 43 44 def remove(self, value): 45 """ 46 if value in the list, remove the element 47 :param value: the value of node 48 :return: 49 """ 50 if self.is_empty(): 51 return 52 cur = self.head 53 while cur: 54 if cur.val == value: 55 if len(self) == 1: 56 # when the list has only one node 57 self.head, self.tail = None, None 58 else: 59 if cur == self.head: 60 self.head = cur.next 61 elif cur == self.tail: 62 self.tail = cur.prev 63 else: 64 cur.prev.next = cur.next 65 return 66 else: 67 cur = cur.next 68 69 def traverse(self): 70 """ 71 iterate through the list 72 :return: 73 """ 74 cur = self.head 75 index = 1 76 while cur: 77 print("Index: {}".format(index) + cur) 78 cur = cur.next 79 index += 1 80 81 def __len__(self): 82 count = 0 83 cur = self.head 84 while cur: 85 count += 1 86 cur = cur.next 87 return count 88 89 def __str__(self): 90 cur = self.head 91 ret = "" 92 while cur: 93 ret += str(cur.val) + "->" if cur.next else str(cur.val) 94 cur = cur.next 95 return ret
其中实现了添加节点、删除节点、获取长度等方法,已经足够作为我们需要的双向链表来使用了,最后就是实现 LRU Cache,主要实现 get(获取数据) 和 put(添加数据)方法,下面是自定义实现的 LRU Cache 类的代码:
1 # LRU Cache 2 class LRU: 3 def __init__(self, size): 4 self.size = size 5 self._list = DoubleList() 6 self._cache = dict() 7 8 def _set_recent(self, node): 9 """ 10 set the node to most recently used 11 :param node: node 12 :return: 13 """ 14 # when the node is the tail of the list 15 if node == self._list.tail: 16 return 17 cur = self._list.head 18 while cur: 19 # remove the node from the list 20 if cur == node: 21 if cur == self._list.head: 22 self._list.head = cur.next 23 else: 24 prev = cur.prev 25 prev.next = cur.next 26 if cur.next: 27 cur = cur.next 28 else: 29 break 30 # set node to the tail of the list 31 cur.next = node 32 node.next = None 33 node.prev = cur 34 self._list.tail = node 35 36 def get(self, key): 37 """ 38 get value of the key 39 :param key: key 40 :return: 41 """ 42 node = self._cache.get(key, None) 43 if not node: 44 return 45 self._set_recent(node) 46 return node.val 47 48 def put(self, key, value): 49 """ 50 set value of the key and add to the cache 51 :param key: key 52 :param value: value 53 :return: 54 """ 55 node = self._cache.get(key, None) 56 if not node: 57 if len(self._list) < self.size: 58 self._list.append(value) 59 else: 60 # when the quantity reaches the maximum, delete the head node 61 name = None 62 for k, v in self._cache.items(): 63 if v == self._list.head: 64 name = k 65 if name: 66 del self._cache[name] 67 self._list.head = self._list.head.next 68 self._list.append(value) 69 else: 70 self._set_recent(node) 71 self._list.tail.val = value 72 # add to cache 73 self._cache[key] = self._list.tail 74 75 def show(self): 76 """ 77 show data of the list 78 :return: 79 """ 80 return "The list is: {}".format(self._list)
下面是测试代码:
1 if __name__ == '__main__': 2 lru = LRU(8) 3 for i in range(10): 4 lru.put(str(i), i) 5 print(lru.show()) 6 for i in range(10): 7 if i % 3 == 0: 8 print("Get {}: {}".format(i, lru.get(str(i)))) 9 print(lru.show()) 10 lru.put("2", 22) 11 lru.put("4", 44) 12 lru.put("6", 66) 13 print(lru.show())
最后是运行结果的截图:
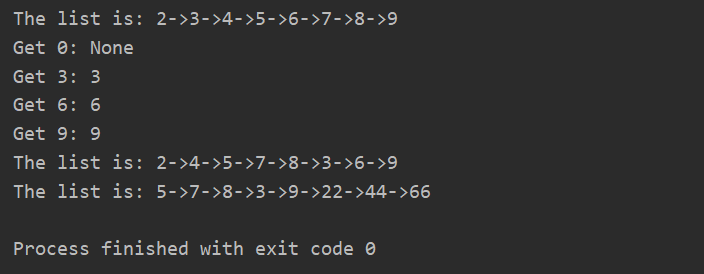
- 当插入数据时,因为最大容量为8,而插入了10个数据,那么最开始添加进去的0和1就会被删掉;
- 当获取数据时,不存在则返回None,存在则返回对应的值,并将该节点移到链表的尾部;
- 当更新数据时,会将对应节点的值进行更新,并将节点移到链表的尾部。
完整代码已上传到 GitHub!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号