PyTorch代码测试以及螺旋数据分类
(写在前面)我将个人的思考总结和截图放在一起写,用来展现一个完整的学习过程
Pytorch代码
首先挂载在谷歌云盘上,然后修改为GPU运行后,开始测试代码(由于与例子大量重复,只写我感觉较为重要的点)

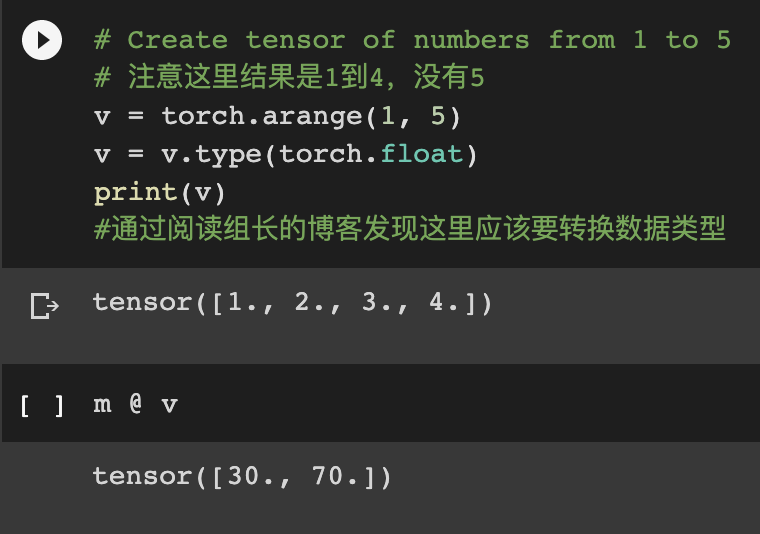
做到这里时,我有点疑惑,@是对tensor进行矩阵相乘,那m是一个2x4的矩阵,v是一个1x4的矩阵,按理不能相乘。在查阅资料以及跟好兄弟讨论之后,发现这里的@类似于dot()运算,是将m的第一行看作一个向量,再与v这个向量来进行点乘,得到结果(如果此处理解有误,还请老师指正)
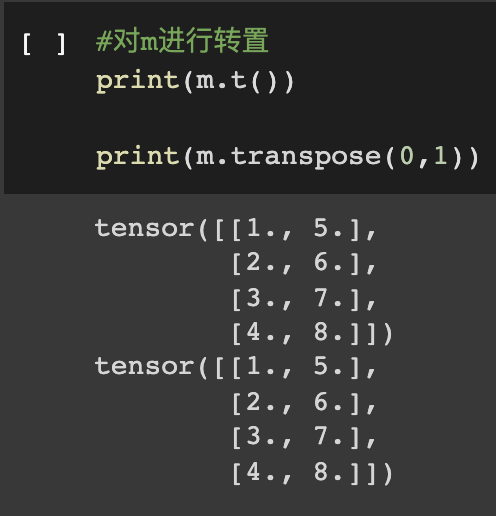
transpose() 是对维度进行的操作,在pytorch中只能操作两个维度
2.螺旋数据分类
初始化样本:

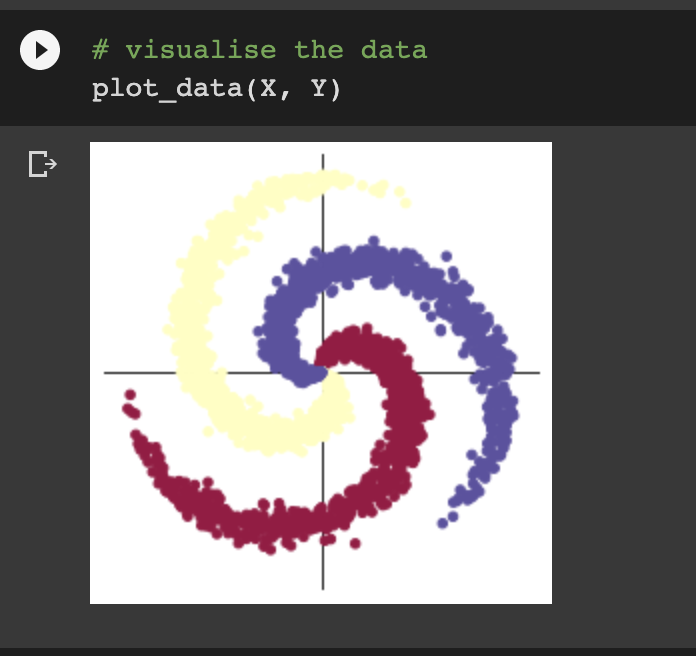
(还蛮好看的)
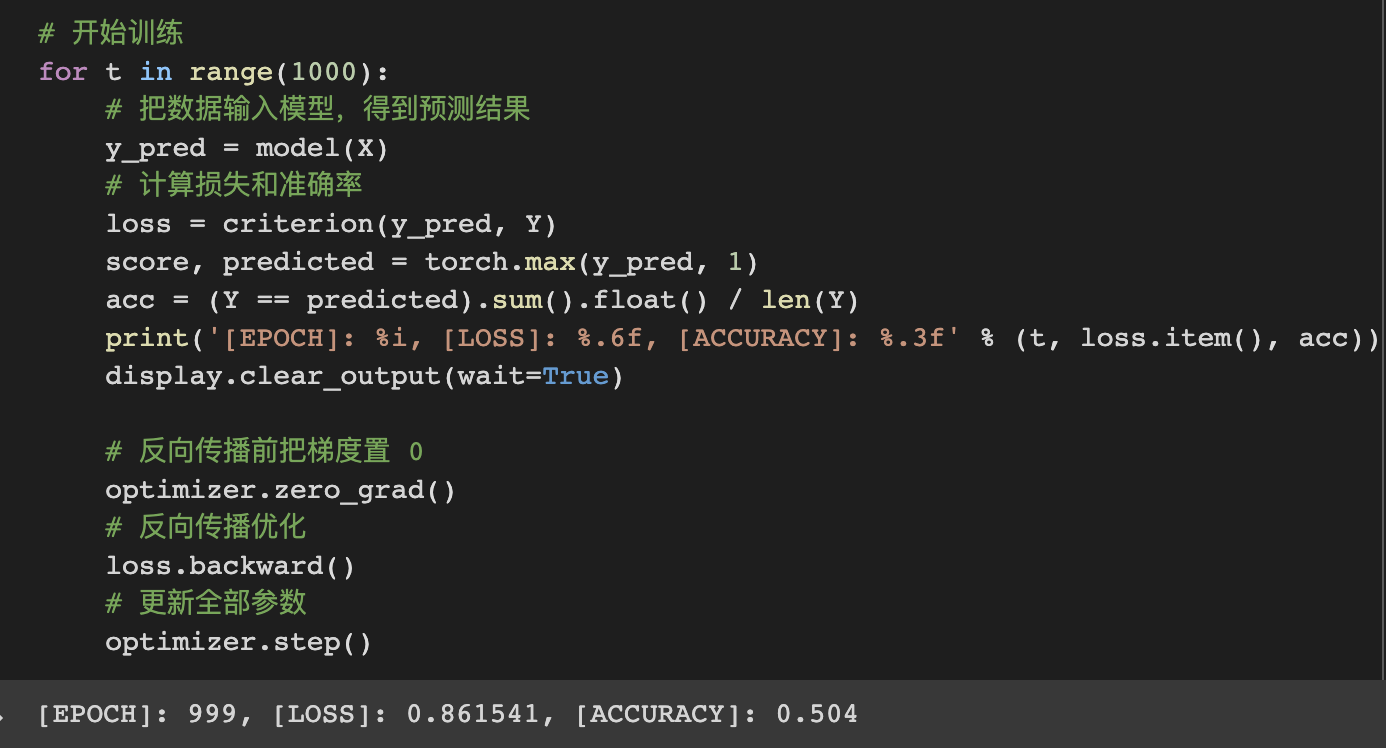
由于nn包创建了线性函数之后,采用的是单层神经网络分类,对于非线形的数据不能较为精确的拟合,模型的准确率只有50.4%,从图像上来看,也是分割的不精确且是用线形的表示来分割的。
关于为什么需要在反向传播前手动将梯度清零,在结合视频以及知乎回答来看,pytorch会有一个梯度的累加机制,若不清零,训练的结果在反向传播过程中,不断累加,就会影响最终结果。但有些时候,这个机制也能用于实现batchsize的变相放大,对内存十分友好。

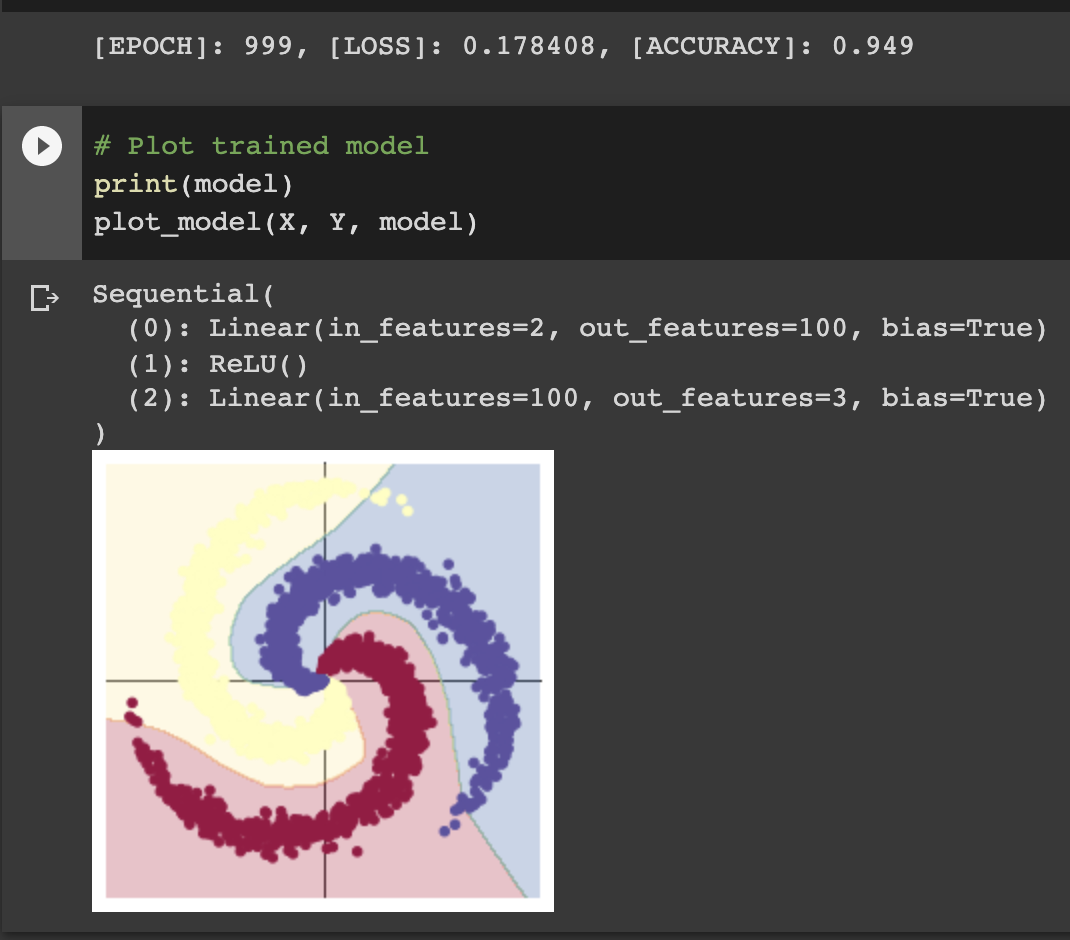
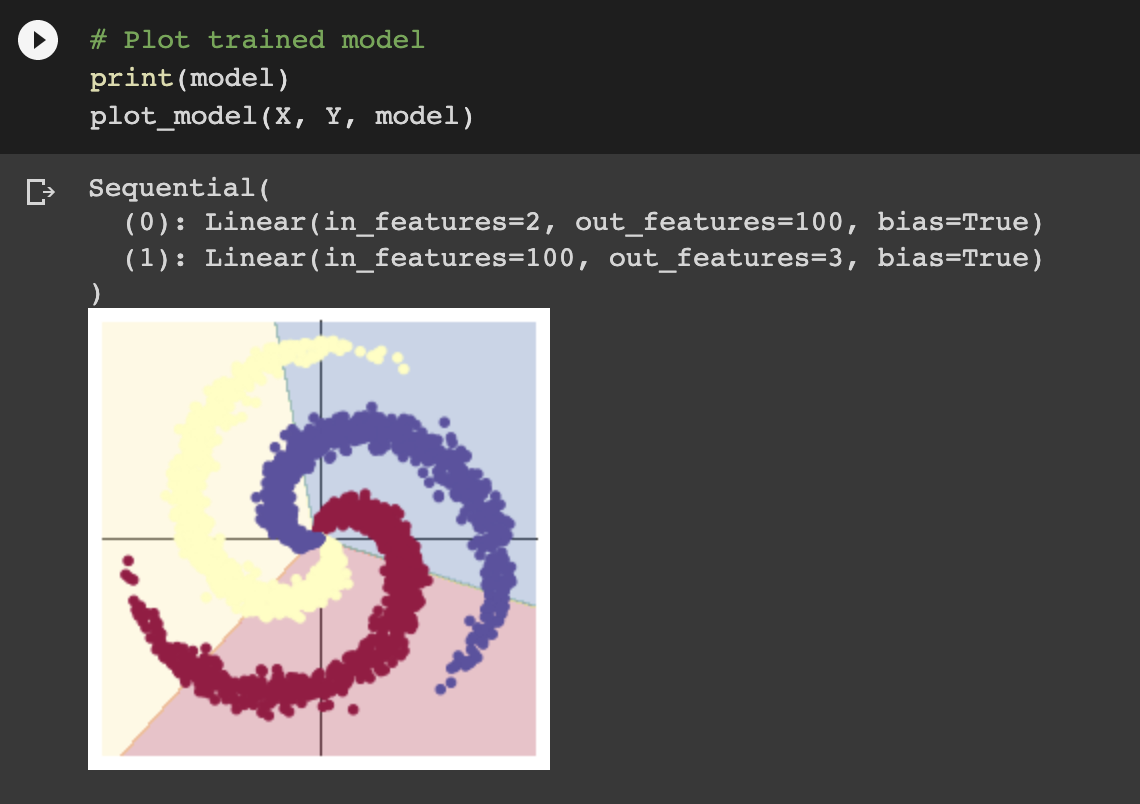
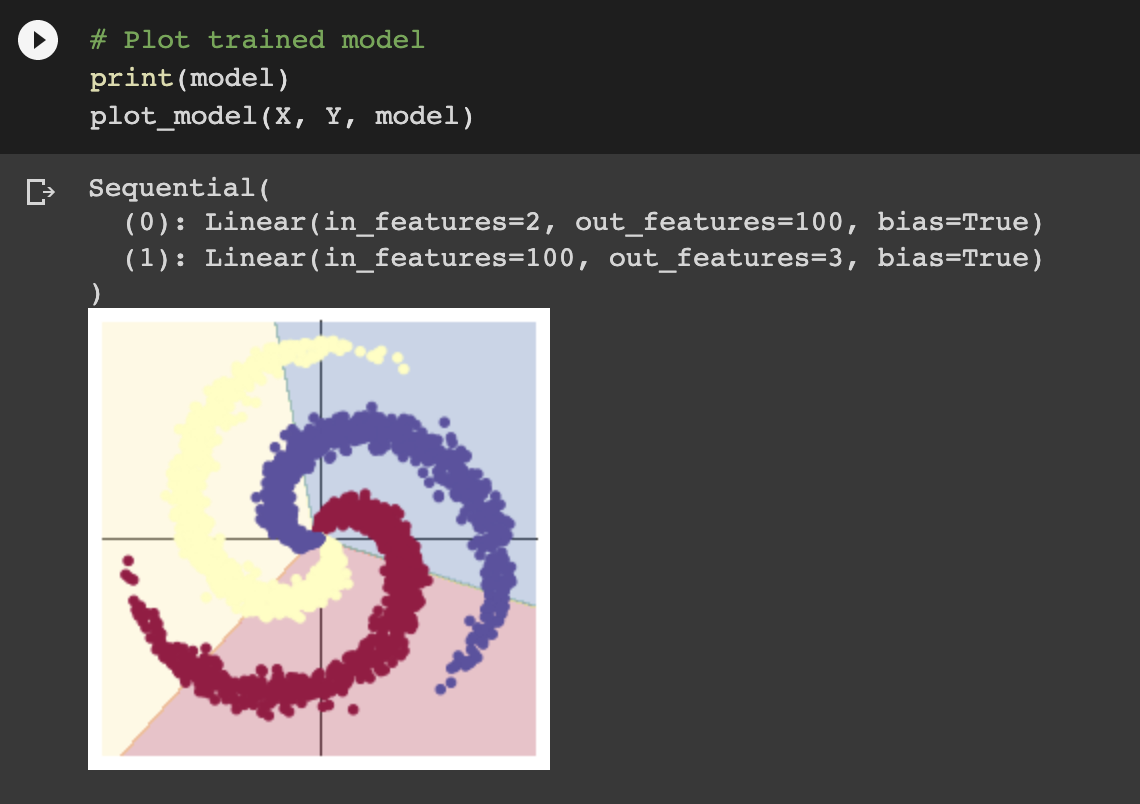
可以明显看到,增加了一个隐层之后,模型的准确率来到了94.9%,双层网络实现了非线形函数的拟合和学习,使得其对于这样一个螺旋分类的样本有了更精确的判断,这点从图片也很明显的看出来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号