【Elasticsearch 7 探索之路】(三)倒排索引
上一篇,我们介绍了 ES 文档的基本 CURE 和批量操作。我们都知道倒排索引是搜索引擎非常重要的一种数据结构,什么是倒排索引,倒排索引的原理是什么。
1 索引过程
在讲解倒排索引前,我们先了解索引创建,下图是 Elasticsearch 中数据索引过程的流程。

从上图可以看到,文档未在 ES 中进行索引,而是 由 Analyzer 组件对其执行一些操作并将其拆分为 token/term。然后将这些术语作为倒排索引存储在磁盘中。假设我们有两个名为 name 和 age 字段,当要将文档索引到 ES 时,Analyzers 组件 以某些定界符(有默认定界符,例如空格,句号等)将它们分割开获取 token,再对每个 token 应用特定的过滤器。经过分析的这些标记称为 term。然后将这些 term 针对该字段)存储在倒排列表中。
2 倒排索引
2.1 正排与倒排索引
一般在我们阅读图书,我们会根据目录快速定位想要阅读的章节,过了一段时间,你想要的回顾之前某一个知识点,你发现从目录难以查找到对应的地方,这时你可能就会从索引页从去查找对应内容索引,从而找到页码。


搜索引擎其实跟我们的使用图书很相似,下面我来对图书和搜索引擎进行一个简单的类比,来看一下搜素引擎中正排和倒排索引。
-
图书
- 正排索引-目录页
- 倒排索引-索引页
-
搜索引擎
- 正排索引-文档 Id 到文档内容和单词的关联
- 倒排索引-单词到文档 Id 的关系
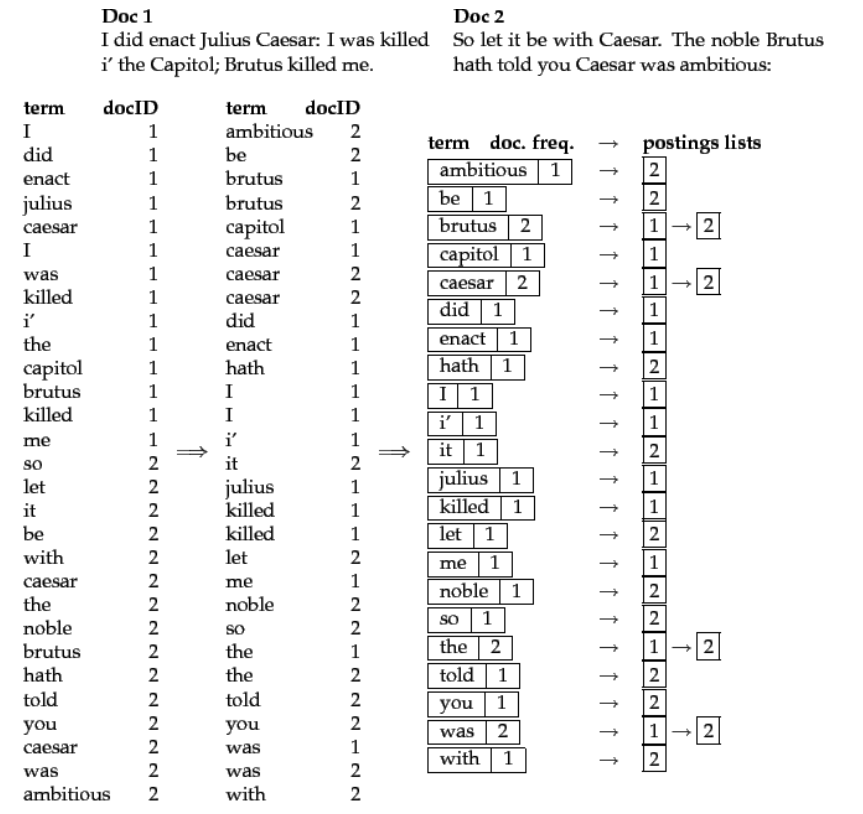
2.2 倒排索引的核心组成
举个例子,假设我们有 3 个文档:
Doc 1:breakthrough drug for schizophrenia
Doc 2:new schizophrenia drug
Doc 3:new approach for treatment of schizophrenia
经过分析,文件中的术语如下
| 文档 | 分词结果 |
|---|---|
| Doc 1 | breakthrough,drug,for,schizophrenia |
| Doc 2 | new,schizophrenia,drug |
| Doc 3 | new,approach,for,treatment,of |
倒排列表的元数据结构:
(DocID;TF;<POS>)
其中:
-
DocID:出现某单词的文档ID
-
TF(词频):单词在该文档中出现的次数
-
POS:单词在文档中的位置
则它们生成的倒排索引
| 单词 | 逆向文档频率 | 倒排列表(DocID;TF; |
|---|---|---|
| breakthrough | 1 | (1;1;<1>) |
| drug | 2 | (1;1;<2>),(2;1;<3>) |
| for | 2 | (1;1;<3>),(3;1;<3>) |
| schizophrenia | 2 | (1;1;<4>),(2;1;<2>) |
| new | 2 | (2;1;<1>),(3;1;<1>) |
| approach | 1 | (3;1;<2>) |
| treatment | 1 | (3;1;<4>) |
| of | 1 | (3;1;<5>) |
-
ES 倒排索引包含两个部分
-
单词词典 (Term Dictionary),索引最小单位,记录所有文档的单词,记录单词到倒排列表的关联关系
- 单词词典一般都会非常多,通过 B+ 树或 Hash 表方式以满足高性能的插入与查询
-
倒排列表(Posting List)-由倒排索引项(Posting)组成
- 文档 ID
- 词频 TF,该单词在文档中出现的次数,用于相关性评分
- 位置(Position),单词在文档中分词的位置。用于语句搜索(phrase query)
- 偏移(Offset),记录单词的开始结束位置,实现高亮显示
-
ES 也可以指定对某些字段不做索引
- 优点:节省存储空间
- 缺点:字段无法被搜索
3 总结
在之前文章说了 ES 的文档是基于 JSON 格式,在我们创建索引的时候,对每一个文档记录对应索引相关的信息。在对倒排索引进行搜索时,查询单词是否在单词字典,获取单词在倒排列表的指针,获取有该单词单词的文档 Id 列表,通过 ES 的倒排索引,我们轻易对全文进行快速搜素。
系列文章
【Elasticsearch 7 搜索之路】(一)什么是 Elasticsearch?
【Elasticsearch 7 探索之路】(二)文档的 CRUD 和批量操作

更多干货,欢迎关注公众号,哈尔的数据城堡,关注免费领取学习资料~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号