8月29日课设个人小结(组名:double-H)
今天的提交:
今天完成的任务:
①上午找到了影视详情的信息的url,放进代码中部署了请求了数据的获取,放在控制台上打印出来,看了一下其中的信息,和组员讨论思考哪些信息可用,该怎么去布局。
下午着手准备将这些数据放入deteil页面中。
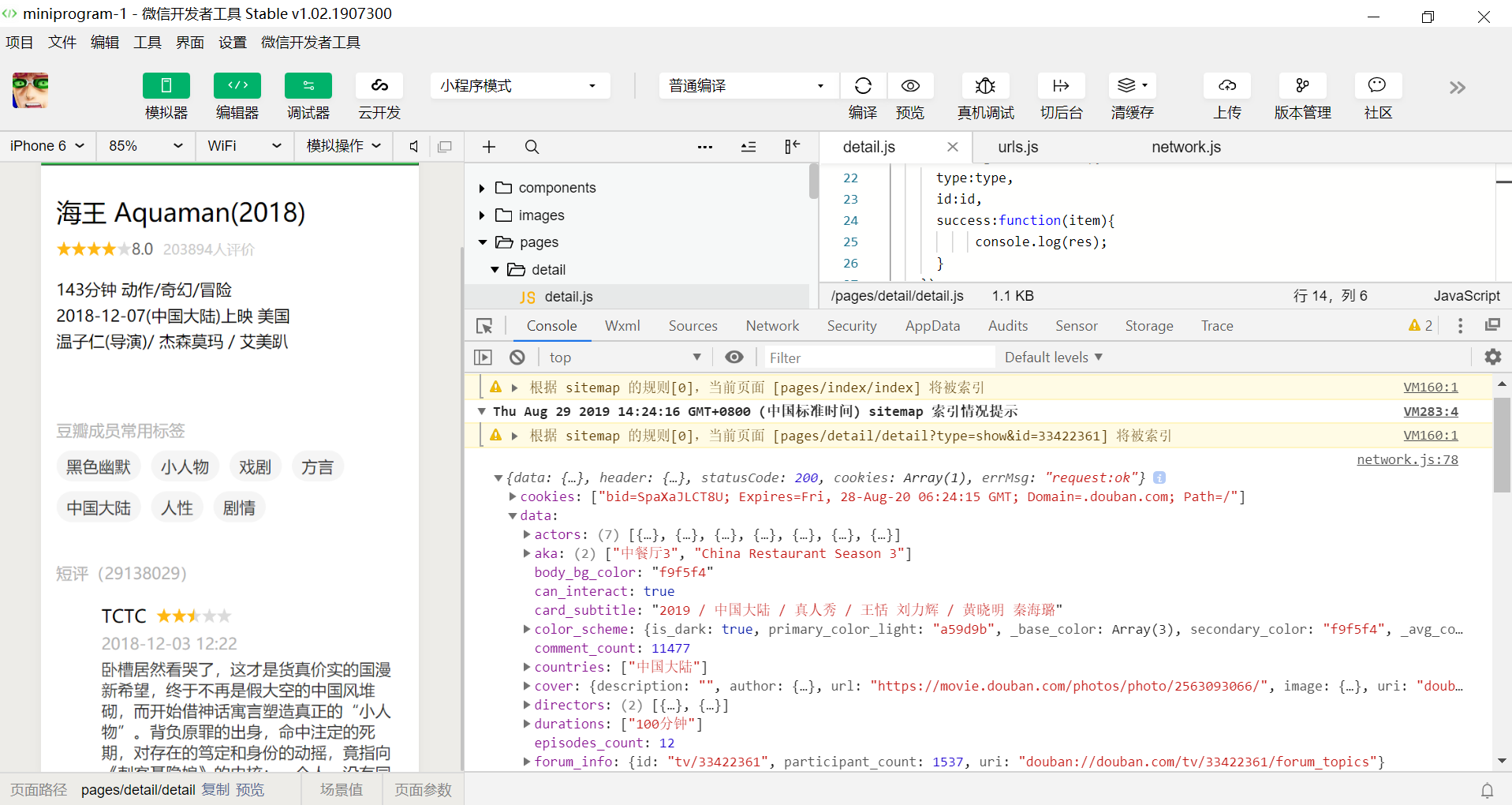
②下午则将这些影视信息的数据布署进detail.wxml页面中(遇到了许许多多大大小小的问题,放在后面的个人小结上面讲)
具体操作就是将自己原先瞎写上去的数据一个一个换成爬下来的数据
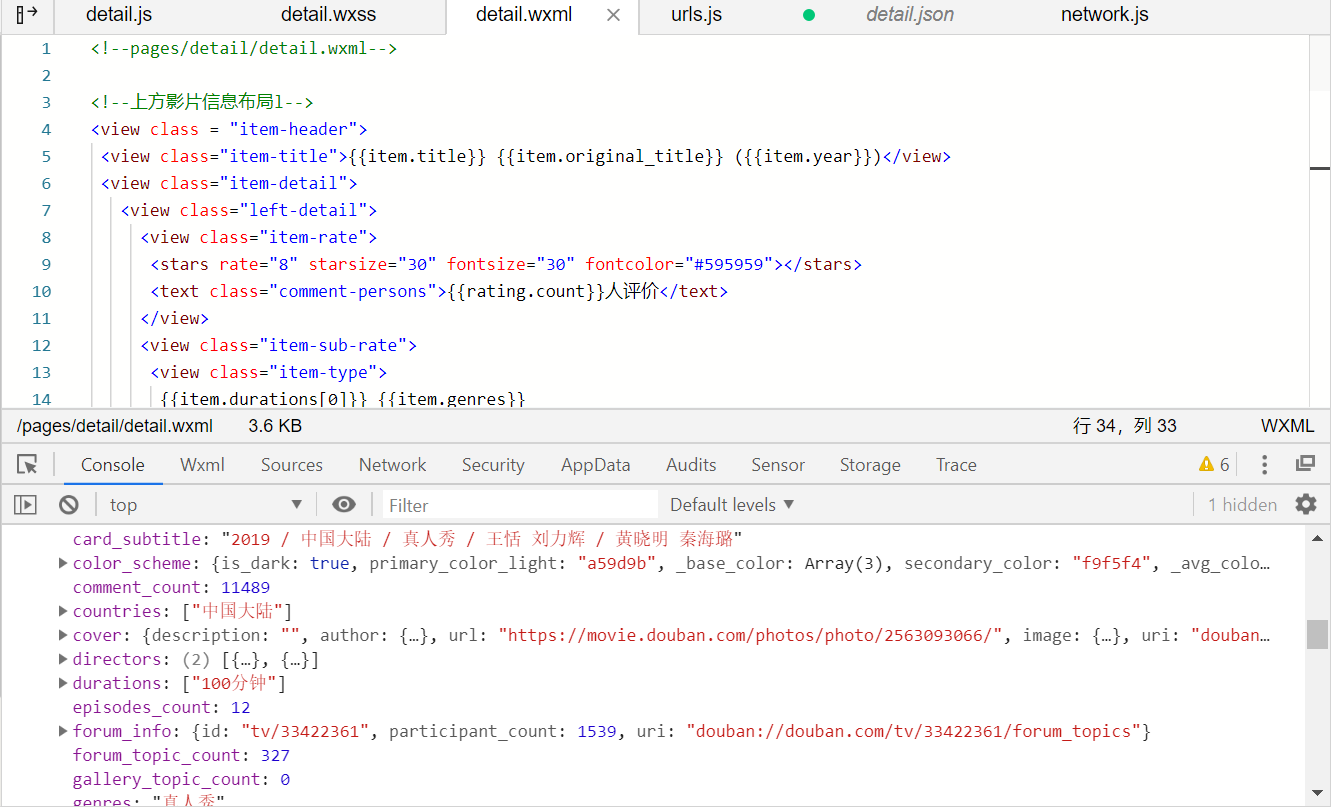
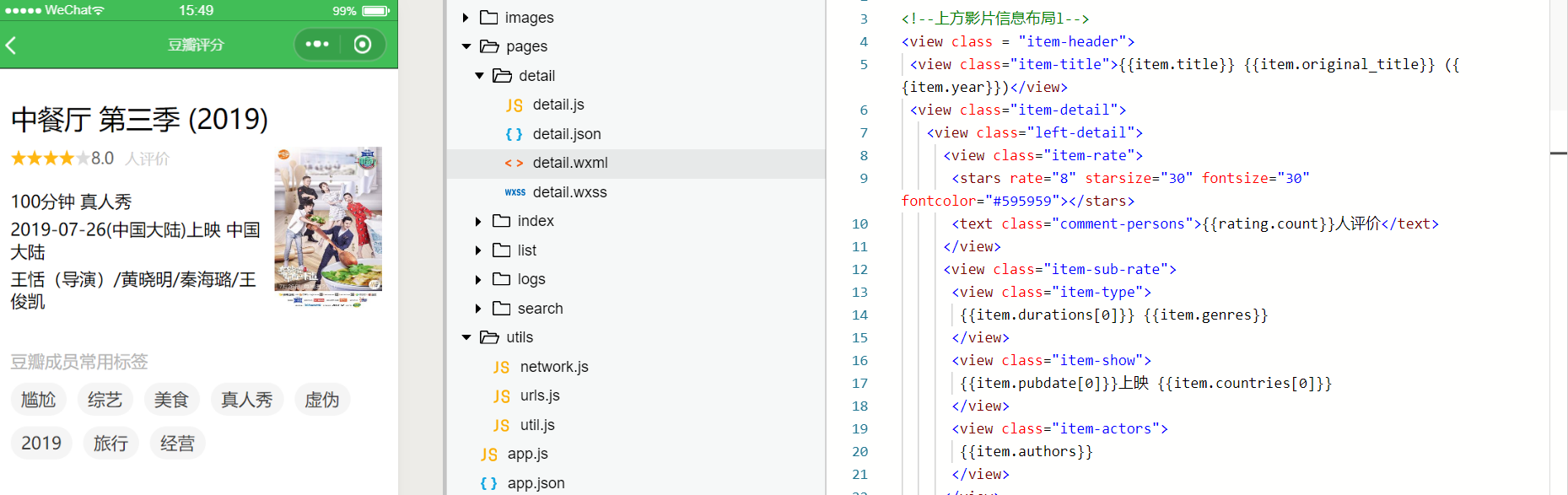
最后完成影片简介和豆瓣标签(点击影片,就会跳转到相应的detail页面当中)
明天的计划:
①上午就回顾一下之前写的东西,为下午的答辩做准备。
②下午就开始每周一次的答辩。
③晚上看把豆瓣评论的url弄一下,部署出来,看一看(其实就是为了强行更新一次代码)。
个人小结:
由于今天晚上要去参加篮球赛,所以晚上就不打算弄了,在下午部署的时候,遇到了许多问题。
①在对着爬下来的数据一个一个对着改时,我们发现有些数据在wxml文件中中不能很好的展示,比如类型genres是一个字符串数组

而我们想要的效果是类似于 ,中间会有斜杠,想了许久发现在wxml中并不能出来我们想要的效果,最后发现可以在js文件中写好,把这个数据先拿到,放进我们定义的一个数组变量当中,再用join函数加上斜杠
,中间会有斜杠,想了许久发现在wxml中并不能出来我们想要的效果,最后发现可以在js文件中写好,把这个数据先拿到,放进我们定义的一个数组变量当中,再用join函数加上斜杠
 ,在wxml中直接输出这个变量即可。
,在wxml中直接输出这个变量即可。
后面在渲染导演和演员数据的时候,也用的是这样的方法(演员他给的数据太多了,于是我们就用了三个,而且演员给的是对象,而我们只需要姓名即可)

②在获取具体影视的标签时,是需要id的,此时就需要id号拼接在url的中间 ,
,
由于以前的url是写死的,但是这个标签的不太好写死,因为有个变量id的存在,这个也卡了我们一段时间,后来也是查资料发现可以写成函数的形式,
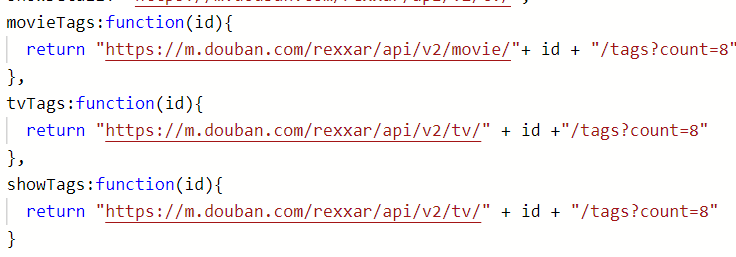
这样也就完美解决了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号