机器学习课设--空气质量预测系统
机器学习课程设计(1):空气质量预测系统
各位朋友,晚上好!这是我的第一篇博客,以后我会边学边写,记录一下自己的学习过程,也希望能和大家一起交流。这学期的机器学习课程设计,我选的题目是《空气质量预测系统》,今天就来和大家聊聊这个项目。
一、准备工作:搭建开发环境
在开始之前,先做好准备工作。先新建一个文件夹,把项目相关的文件都放进去,这样比较整齐,方便管理,别像我以前一样,桌面上乱七八糟一堆文件,找起来都麻烦。
然后是 Python 环境,我用的是 Python3.1x,运行起来挺稳定的。这个项目要用到几个第三方库,分别是:
- requests:用来爬取网上的数据,方便获取空气质量相关的实时数据。
- pandas:处理表格数据很厉害,数据预处理用它很方便,比如筛选、填充缺失值之类的操作都能轻松搞定。
- matplotlib:可以用来画图表,把数据分析的结果可视化,看起来更直观。
- seaborn:辅助 matplotlib 画热力图,能更清楚地看出数据之间的相关性,对后续建模很有帮助。
安装命令如下:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests pandas matplotlib seaborn
刚才做完了准备工作,咱们可要动真格的啦,直接上手实现这个系统。整个过程就像是一场探险,咱们要一步步走过几个重要的关卡:数据采集、数据处理、数据分析、模型训练,还有最后的预测。那咱们现在就出发,看看每个关卡里都有啥好玩的!
一、数据采集:把数据“抓”过来
机器学习就像是在找宝藏,我们要找到输入(X)和输出(Y)之间的秘密通道。在这个项目里,我们的目标是预测空气质量指数(AQI),这就是我们要找的宝藏(Y)。但要找到宝藏,咱们得先知道哪儿有线索,这些线索就是影响AQI的各种因素,也就是输入(X)。可要是没有地图,咱们连第一步都迈不出去,这地图就是咱们的数据。没有数据,机器学习就像是在黑暗里摸索,啥都看不见。
那咱们的数据地图从哪儿来呢?长沙空气质量历史数据网站(http://www.tianqihoubao.com/aqi/changsha-2025xx.html)就像是一个藏宝图,上面有长沙2024年的空气质量数据。咱们要用爬虫这个“小工具”,把每个月的数据都“抓”过来,然后存到本地文件里,这样咱们的数据地图就到手啦!
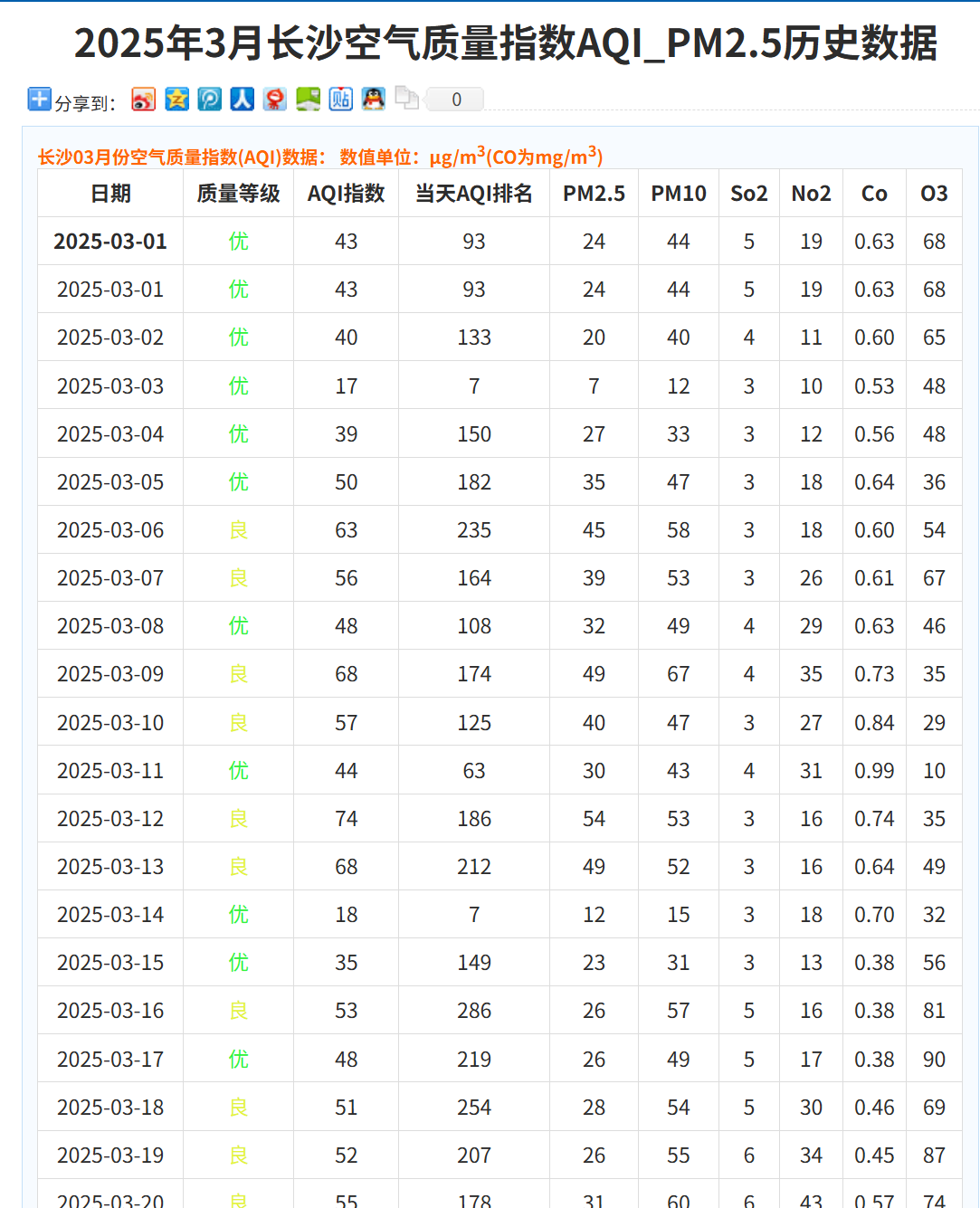
实现代码(1.数据采集.py)
import pandas as pd
import requests
import warnings
warnings.filterwarnings("ignore")
for page in range(1, 13):
if page < 10:
url = f'http://www.tianqihoubao.com/aqi/changsha-20240{page}.html'
res = requests.get(url)
html = res.text
df = pd.read_html(html, encoding='utf-8')[0]
if page == 1:
df.to_csv('空气质量-changsha_day.csv', mode='a+', index=False, header=False)
else:
df.iloc[1:, ::].to_csv('空气质量-changsha_day.csv', mode='a+', index=False, header=False)
print(f"{page}月数据采集完毕")
else:
url = f'http://www.tianqihoubao.com/aqi/changsha-2024{page}.html'
res = requests.get(url)
html = res.text
df = pd.read_html(html, encoding='utf-8')[0]
df.iloc[1:, ::].to_csv('空气质量-changsha_day.csv', mode='a+', index=False, header=False)
print(f"{page}月数据采集完毕")
print("长沙2024空气质量数据采集完毕!\n存储文件:空气质量-changsha_day.csv")
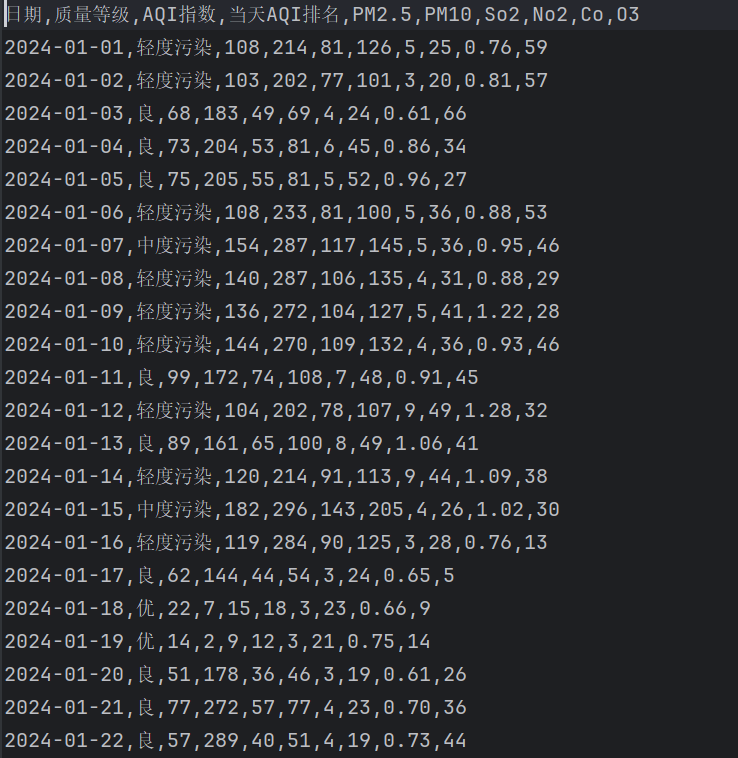
运行这段代码,咱们的数据地图——长沙2024年的空气质量数据,就稳稳地落在咱们手上了!
二、数据处理:把数据“理”整齐
采集到的数据就像是刚从地里挖出来的宝藏,乱七八糟的,还带着不少泥巴。咱们得把它们洗干净、理整齐,才能用。这就到了数据处理的环节,咱们要做的事儿可不少:去除重复的数据,就像把重复的宝藏标记去掉;添加时间特征,给每个宝藏标记上时间戳;计算滞后特征,看看过去的宝藏对现在的宝藏有啥影响。做完这些,咱们的数据就变得干干净净、整整齐齐啦!
实现代码(2.数据处理.py)
import pandas as pd
# 加载数据
file_path = '空气质量-changsha_day.csv'
data = pd.read_csv(file_path)
data['日期'] = pd.to_datetime(data['日期'])
data['年'] = data['日期'].dt.year
data['月'] = data['日期'].dt.month
data['日'] = data['日期'].dt.day
data['星期'] = data['日期'].dt.dayofweek
data.drop_duplicates(inplace=True)
data['AQI_1天前'] = data['AQI指数'].shift(1)
data['AQI_2天前'] = data['AQI指数'].shift(2)
data['PM2.5_1天前'] = data['PM2.5'].shift(1)
data['PM2.5_2天前'] = data['PM2.5'].shift(2)
data['PM10_1天前'] = data['PM10'].shift(1)
data['PM10_2天前'] = data['PM10'].shift(2)
data['So2_1天前'] = data['So2'].shift(1)
data['So2_2天前'] = data['So2'].shift(2)
data['No2_1天前'] = data['No2'].shift(1)
data['No2_2天前'] = data['No2'].shift(2)
data['O3_1天前'] = data['O3'].shift(1)
data['O3_2天前'] = data['O3'].shift(2)
data['Co_1天前'] = data['Co'].shift(1)
data['Co_2天前'] = data['Co'].shift(2)
data = data.dropna()
data.to_csv("dataset.csv", index=False)
print("数据处理完毕,存储位置dataset.csv")
print(data.head(7))
经过处理,咱们的数据变得干净整齐,就像是把宝藏都擦得亮晶晶的,存到了一个漂亮的小盒子里——dataset.csv文件。
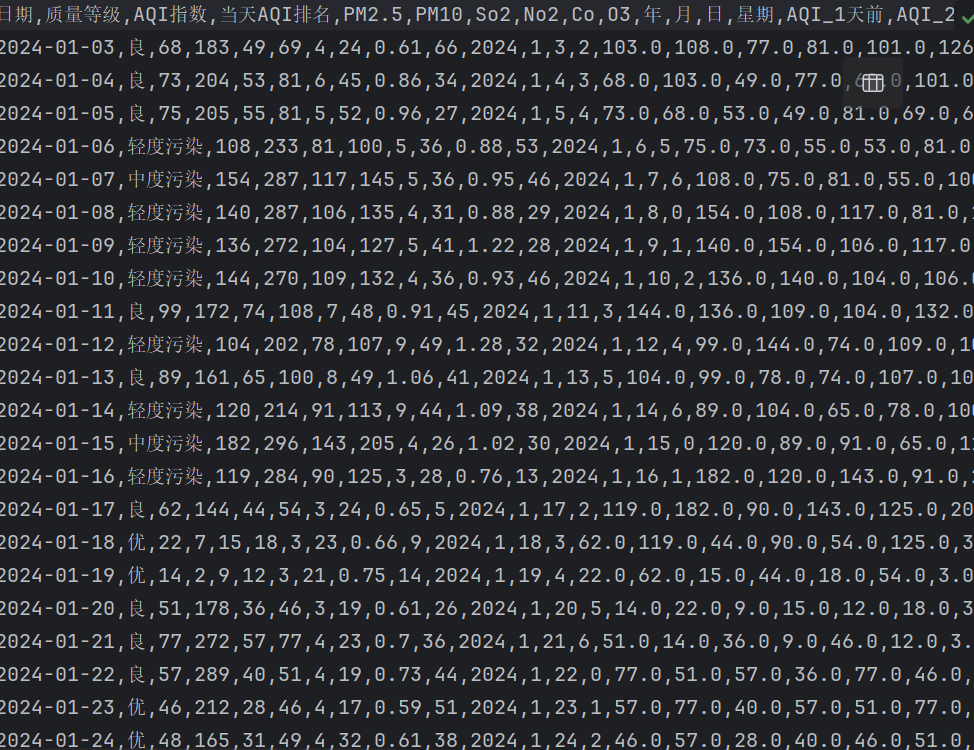
三、数据分析:看看数据有啥“秘密”
数据处理完啦,接下来就是数据分析。这就像是拿着放大镜,仔细看看咱们的宝藏里藏着啥秘密。咱们要看看AQI指数和其他因素(比如PM2.5、PM10等)之间的关系,看看它们是不是好朋友,是不是互相影响。咱们还要看看AQI指数随时间的变![]
化,看看它是不是有规律可循。要是能找到这些秘密,咱们就能更好地预测AQI指数啦!
实现代码(3.数据分析.py)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import seaborn as sns
# 加载数据
file_path = 'dataset.csv'
data = pd.read_csv(file_path)
# 相关性分析
numeric_columns = data.select_dtypes(include=[np.number]).columns
correlation_matrix = data[numeric_columns].corr()
print(correlation_matrix['AQI指数'].sort_values(ascending=False))
# 设置 Matplotlib 的字体为支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定中文字体为 SimHei
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 绘制时间序列图
plt.figure(figsize=(14, 7))
plt.plot(data['日期'], data['AQI指数'], label='AQI指数')
plt.xlabel('日期')
plt.ylabel('AQI指数')
plt.title('AQI指数随时间变化')
plt.legend()
ax = plt.gca()
ax.xaxis.set_major_locator(mdates.MonthLocator(interval=3))
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
plt.tight_layout()
plt.show()
# 箱线图
plt.figure(figsize=(14, 7))
sns.boxplot(x='月', y='AQI指数', data=data)
plt.xlabel('月份')
plt.ylabel('AQI指数')
plt.title('AQI指数的月度分布')
plt.show()
# 热力图
plt.figure(figsize=(14, 7))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
plt.title('特征相关性热力图')
plt.show()
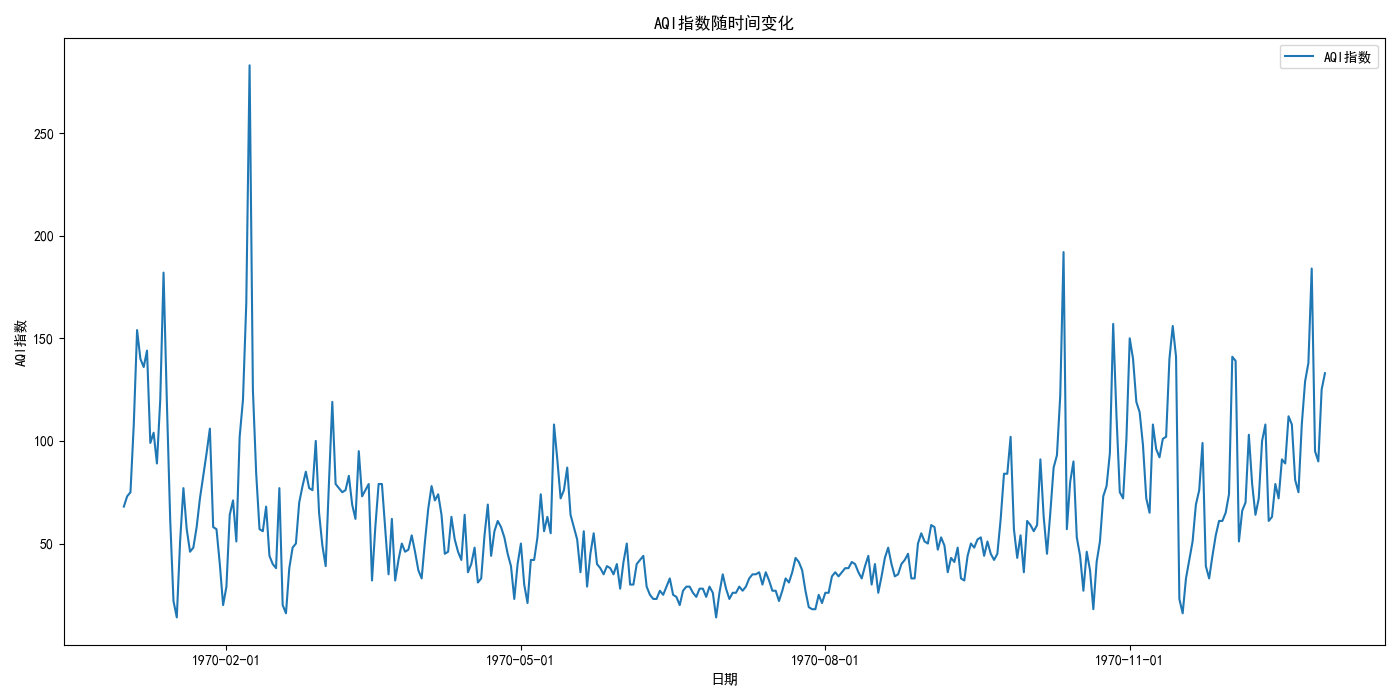
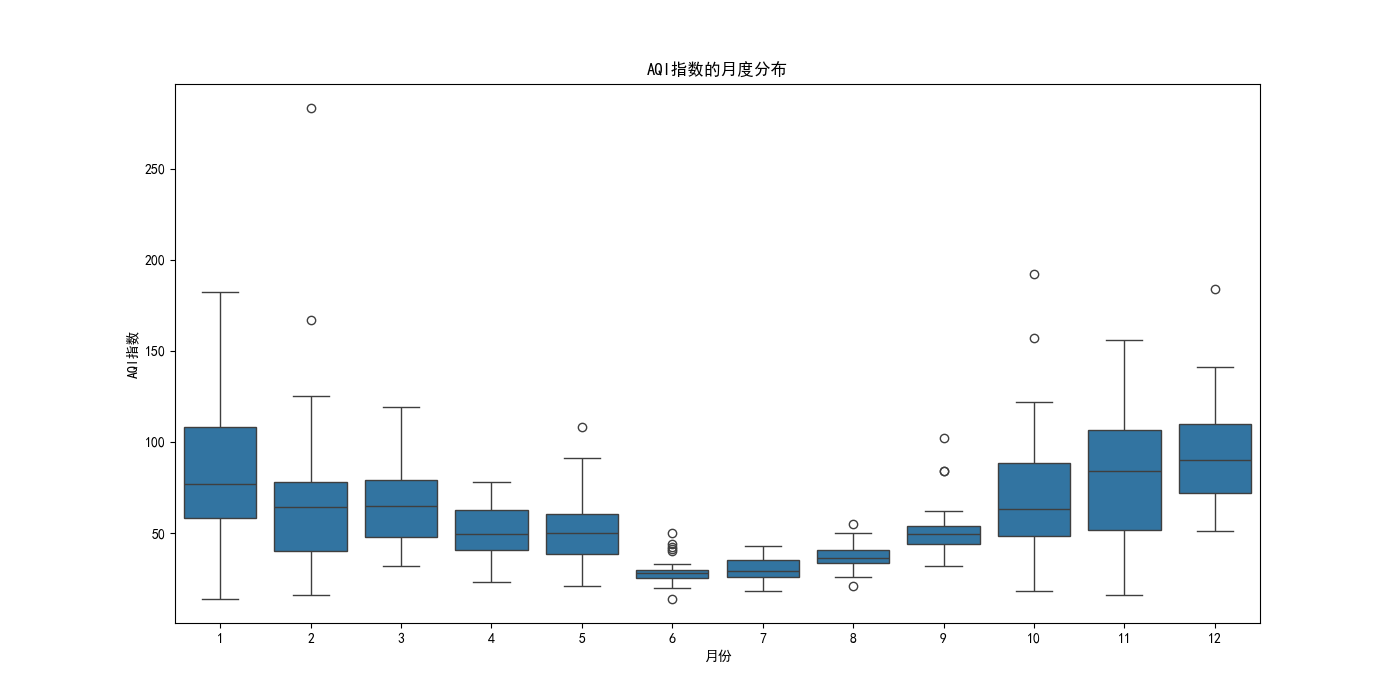

通过相关性分析,咱们发现AQI指数与某些污染物(如PM2.5、PM10等)存在较高的相关性。时间序列图显示了AQI指数随时间的变化趋势,箱线图揭示了不同月份AQI指数的分布情况,热力图则直观地展示了各个特征之间的相关性。这些分析结果为后续的模型选择和特征工程提供了重要依据。
四、模型训练:让机器“学会”预测
经过前面的分析,咱们已经找到了一些线索,知道了哪些因素(X)对空气质量指数(AQI,也就是Y)有影响。现在,咱们要让机器“学会”这些规律,这样它就能根据已知的因素(X)来预测未知的空气质量指数(Y)啦。这就到了模型训练的环节。
咱们选择了一个叫随机森林的模型来训练。随机森林就像是一个由很多小树组成的森林,每棵小树都能做出自己的预测,然后森林把这些预测综合起来,给出一个最终的预测结果。这种模型很厉害,它能处理很多复杂的情况,而且不容易犯错。
实现代码(4.开始训练.py)
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
import joblib
# 加载数据
file_path = 'dataset.csv'
data = pd.read_csv(file_path)
# 特征选择
features = ['AQI_1天前', 'PM2.5_1天前', 'PM10_1天前', 'So2_1天前', 'No2_1天前', 'O3_1天前', 'Co_1天前']
X = data[features]
y = data['AQI指数']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 随机森林模型
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
# 保存模型
joblib.dump(rf_model, 'random_forest_model.pkl')
print("模型已保存到文件:random_forest_model.pkl")
# 使用测试集进行预测
y_pred = rf_model.predict(X_test)
# 计算预测值与真实值的差值
differences = abs(y_pred - y_test)
# 统计差值不超过30的比例
accuracy = (differences <= 30).mean()
print(f"模型在测试集上的准确率(预测值与真实值差值不超过30的比例)为:{accuracy:.4f}")
训练完成后,咱们得到了一个随机森林模型,并把它保存到了文件里。在测试集上,模型的准确率还不错,这意味着咱们的机器已经“学会”了根据已知因素(X)来预测空气质量指数(Y)啦!
五、预测:让机器“预言”未来
现在,咱们的机器已经“学会”了预测空气质量指数,那咱们就来让它“预言”一下未来吧!咱们只需要给它输入一些已知的因素(X),它就能告诉我们未来的空气质量指数(Y)啦。
实现代码(5.预测.py)
import pandas as pd
import joblib
def load_model(model_path):
"""加载指定路径的模型"""
return joblib.load(model_path)
def predict_aqi(model, input_data):
"""使用指定模型进行预测"""
return model.predict(input_data)
def main():
model_path = 'random_forest_model.pkl'
model_name = '随机森林模型'
model = load_model(model_path)
# 提示用户输入预测所需的参数
print("\n请输入预测所需的参数:")
aqi_1_day_before = float(input("AQI_1天前: "))
pm25_1_day_before = float(input("PM2.5_1天前: "))
pm10_1_day_before = float(input("PM10_1天前: "))
so2_1_day_before = float(input("So2_1天前: "))
no2_1_day_before = float(input("No2_1天前: "))
o3_1_day_before = float(input("O3_1天前: "))
co_1_day_before = float(input("Co_1天前: "))
# 创建包含输入参数的DataFrame
input_data = pd.DataFrame({
'AQI_1天前': [aqi_1_day_before],
'PM2.5_1天前': [pm25_1_day_before],
'PM10_1天前': [pm10_1_day_before],
'So2_1天前': [so2_1_day_before],
'No2_1天前': [no2_1_day_before],
'O3_1天前': [o3_1_day_before],
'Co_1天前': [co_1_day_before]
})
# 进行预测
prediction = predict_aqi(model, input_data)
# 输出预测结果
print(f"\n使用{model_name}预测的AQI指数为: {prediction[0]:.2f}")
if __name__ == "__main__":
main()
运行这段代码,咱们就可以输入一些已知的因素(X),然后让机器告诉我们未来的空气质量指数(Y)啦。是不是很神奇?这就像咱们有了一个“预言家”,能告诉咱们未来的空气质量会怎么样。
六、总结
通过这几个步骤,咱们成功地实现了一个空气质量预测系统。从数据采集、数据处理、数据分析,到模型训练和预测,每一步都像是在解开一个谜题。现在,咱们的机器已经能够根据已知的因素来预测未来的空气质量啦。这不仅是一个有趣的项目,还能帮助咱们更好地了解和应对空气污染问题。
希望这个项目能给大家带来一些启发,也欢迎大家在评论区留言,一起交流学习。咱们下回再见啦!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号