

汇编实验3 转移指令跳转原理及其简单应用编程
实验任务1
源代码
点击查看代码
assume cs:code, ds:data
data segment
x db 1, 9, 3
len1 equ $ - x ; 符号常量 , $指下一个数据项的偏移地址,这个示例中,是3
y dw 1, 9, 3
len2 equ $ - y ; 符号常量 , $指下一个数据项的偏移地址,这个示例中,是9
data ends
code segment
start:
mov ax, data
mov ds, ax
mov si, offset x
mov cx, len1
mov ah, 2
s1:mov dl, [si]
or dl, 30h
int 21h
mov dl, ' '
int 21h
inc si
loop s1
mov ah, 2
mov dl, 0ah
int 21h
mov si, offset y
mov cx, len2/2
mov ah, 2
s2:mov dx, [si]
or dl, 30h
int 21h
mov dl, ' '
int 21h
add si, 2
loop s2
mov ah, 4ch
int 21h
code ends
end start
实验结果
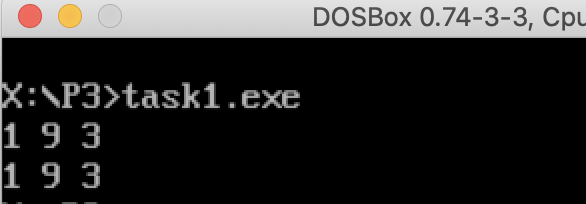
根据 Intel 白皮书,LOOP指令的机器码格式为:E2 cb(cb指一个字节单位)
cb处是一个字节的偏移量,是一个8位有符号整数,范围在-128 ~ 127
根据课堂和课本知识可知:LOOP本质是一个近转移,偏移量存储时采用补码表示
问题①
十六进制(补码):F2
二进制(补码):1111 0010
二进制(原码):1000 1110
十进制(原码):-14
根据LOOP指令定义:当前IP + 有符号偏移量 = 跳转地址
当前IP指向下一条指令开始地址,为001B,十进制表示:27
根据公式:27 + (-14) = 13
13的十六进制表示为:D,跳转地址即000D,可以发现的确是代码中跳转的地址
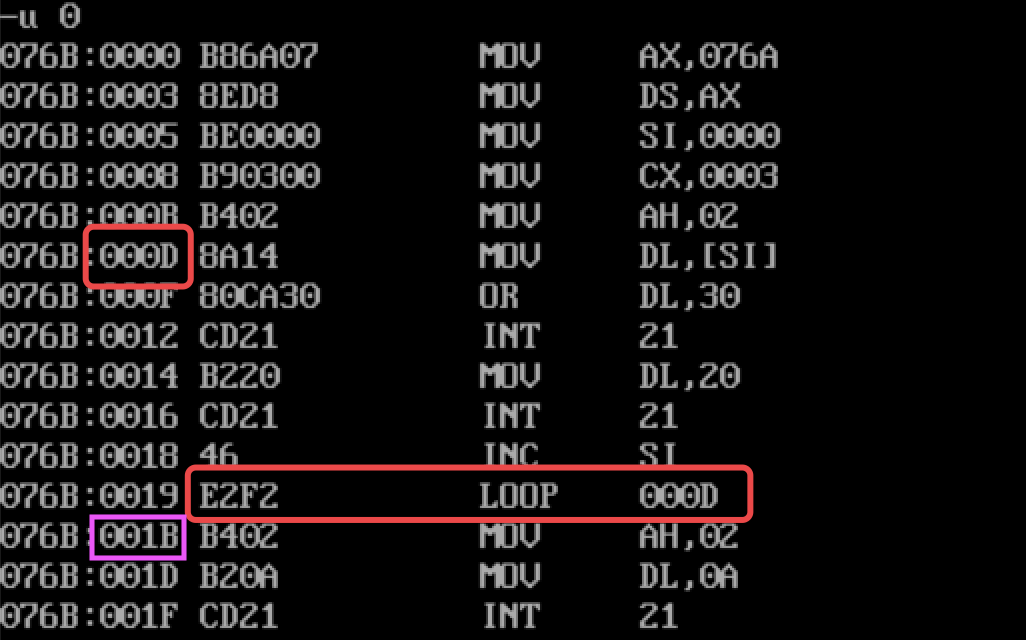
问题②
十六进制(补码):F0
二进制(补码):1111 0000
二进制(原码):1001 0000
十进制(原码):-16
根据LOOP指令定义:当前IP + 有符号偏移量 = 跳转地址
当前IP为0039,十进制表示:57
根据公式:57 + (-16) = 41
41的十六进制表示为:29,跳转地址即0029,可以发现的确是代码中跳转的地址
相关研究
1. 关于汇编中的标号(label)
在 Intel 白皮书中,标号一律被称作label
目前已经学过的汇编中有两种标号方式,一种有冒号(:),一种没有冒号
上面的代码中:
assume cs:code, ds:data
data segment
x db 1, 9, 3
len1 equ $ - x
...
data ends
code segment
start:
...
x和len1没有冒号,而start有冒号。根据博客《汇编语言之 有冒号的标号和没冒号标号的区别》的说法,区别在于x和len既可以当做地址,也可以查看其中的内容,而start只能作为地址使用。
但是这篇博客写的很含糊,不明不白。因此做了以下进一步尝试。
尝试1:如果在data段中给x加上冒号写作这样:
data segment
x: db 1, 9, 3
len1 equ $ - x
...
会提示错误:Missing or unreachable CS

目前还没搞清楚这是为什么,盲猜是因为assume中将data段作为数据段,里面的代码不会被执行所导致的。
但是可以知道,在data段中无法使用带冒号的标号(label)
尝试2:以下代码段masm编译阶段会报错:
a mov ax, 0
mov ax, word ptr a

尝试3:以下两个代码段编译和运行中均不会报错:
a: mov ax, 0
mov ax, word ptr a
a db 1, 9, 3
mov ax, word ptr a
两段代码中:
第一段ax放入的均为a处指令开始的地址
第二段ax放入的为数字1
尝试4:如下代码段编译和运行中也不会报错:
a db 1, 9
len1 = $ - a
mov ax, len1
b: db 1, 9
len2 = $ - b
mov ax, len2
在debug中进行反汇编:

可以看到二者没有什么差别
可以发现:
- 不带冒号的标号后只能跟伪指令,而带冒号后可以跟任何指令
- 带冒号和不带冒号都可以作为指令的地址使用
这里只做了简单实验来研究加冒号和不加冒号两种标号形式的异同点,但是资料过少且没有时间,以后再做深入了解。
2. LOOP指令
在《Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 2 (2A, 2B, 2C & 2D): Instruction Set Reference, A-Z》(Intel白皮书)中,
LOOP指令的机器码结构(Vol.2A 3-597):


关于LOOP指令的描述:
The target instruction is specified with a relative offset (a signed offset relative to the current value of the instruction pointer in the IP/EIP/RIP register). This offset is generally specified as a label in assembly code, but at the machine code level, it is encoded as a signed, 8-bit immediate value, which is added to the instruction pointer. Offsets of –128 to +127 are allowed with this instruction.
目标指令被指定为相对偏移量(相对于IP/EIP/RIP寄存器中指令指针的当前值的有符号偏移)。这个偏移量在汇编代码中通常被指定为一个标号,但在机器码层面,它被编码为一个加在指令指针(IP)上的有符号8位立即数。这条指令允许的偏移量为-128到+127。
实验任务2
源代码
点击查看代码
assume cs:code, ds:data
data segment
dw 200h, 0h, 230h, 0h
data ends
stack segment
db 16 dup(0)
stack ends
code segment
start:
mov ax, data
mov ds, ax
mov word ptr ds:[0], offset s1 ; ds:[0] 存储了s1的地址
mov word ptr ds:[2], offset s2 ; ds:[2] 存储了s2的地址
mov ds:[4], cs ; ds:[4] 存储了当前段的段地址
mov ax, stack
mov ss, ax
mov sp, 16
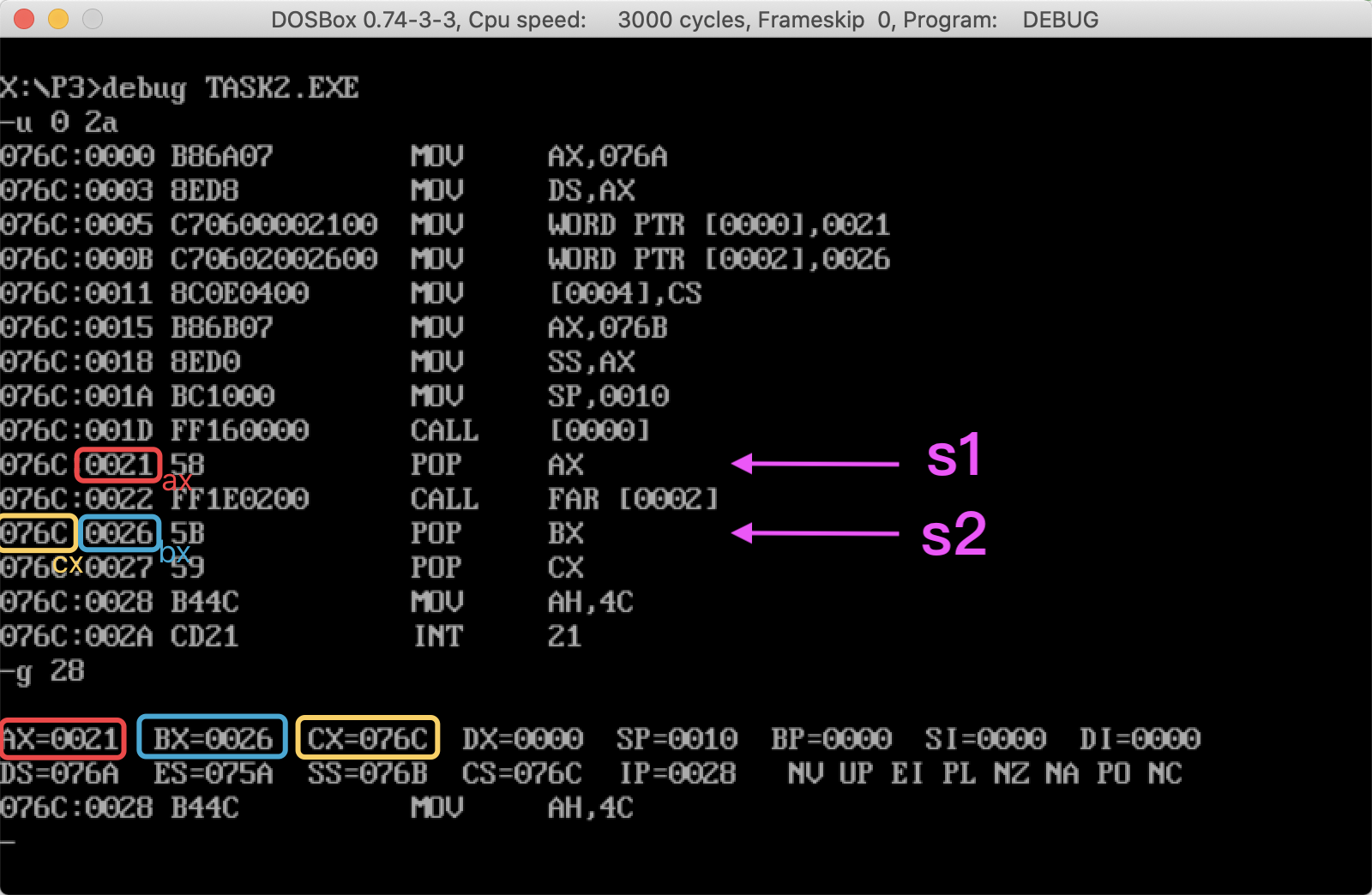
call word ptr ds:[0] ; word为短转移,把 s1 处的 IP 进栈, 然后跳转到 s1 的地址
s1: pop ax ; 把 s1 处的 IP 值送入 ax
call dword ptr ds:[2] ; dword为远转移,把 s2 出的 CS:IP 值进栈, 然后跳转到 s2 处
s2: pop bx ; 把 s2 的 IP 值送入 bx
pop cx ; 把 s2 的 CS 值送入 cx
mov ah, 4ch
int 21h
code ends
end start
问题解答
根据分析:(上面代码中的注释为分析过程)
ax = s1 处的 IP
bx = s2 的 IP
cx = s2 的 CS
实验结果
和分析的结果是一致的。
实验任务3
仅实现任务中要求的源代码
点击查看代码
; 仅能打印byte长度的数字(0-255),可以实现不定位数
assume ds:data, cs:code, ss:stack
data segment
x db 99, 72, 85, 63, 89, 97, 55
len equ $ - x
data ends
stack segment
dw 16 dup(?)
stack ends
code segment
start:
mov ax, data
mov ds, ax
mov ax, stack
mov ss, ax
mov sp, 32
mov cx, len ; 由于数据都是byte型,所以len就是数据个数
; print循环: 依次打印所有数字
print:
mov ah, 0 ; 数据只有一个字节,先把ah置0,子函数中除法是以ax作为被除数的
mov al, byte ptr ds:[di] ; 把数据放入al
inc di ; di指针后移
push cx ; 把cx保存起来, 子程序中会修改cx值
call printNumber ; 打印数字
call printSpace ; 打印空格
pop cx ; 恢复cx
loop print
mov ah, 4ch
int 21h
; 子程序: printNumber
; 功能: 打印数字
; 入口参数:
; 寄存器ax (待输出的数据 --> ax)
; 局部变量说明:
; bx -> 存储数字字符个数
printNumber:
mov bx, 0 ; 获取之前位数为0
; 逐位获取数字
; getEach循环: 获取每一位,然后压入栈中
getEach:
mov dl, 10
div dl ; 数据除10
push ax ; 将数字压入栈中(ah余数在ax里了)
inc bx ; 位数+1
mov ah, 0 ; ah是余数,置0后ax表示除法的结果
mov cx, ax ; 除法结果赋给cx, 如果结果为0则说明所有位数都获取完了
inc cx ; 由于loop时会-1,这里先+1,防止出现负数
loop getEach
; 打印数字
mov cx, bx ; 先把bx存的数字位数赋给cx
; printEach循环: 依次从栈中取出数字,逐位打印
printEach:
pop ax ; 取出一位数
add ah, 30h ; ah是刚才除法的余数,也就是需要得到的位数,+30h是转成对应字符
mov dl, ah ; 放到dl, 用于打印
mov ah, 2 ; 调用int 21h的2号子程序打印
int 21h
loop printEach
ret
; 子程序: printSpace
; 功能: 打印空格
printSpace:
mov ah, 2
mov dl, 20h
int 21h
ret
code ends
end start
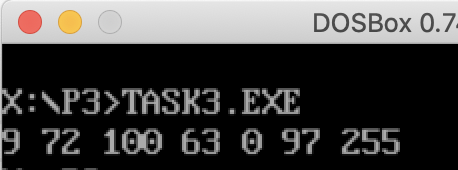
任务要求的实验结果
可以成功打印要求中的2位数。

实际上,该代码还可以打印0 ~ 255之间的任意数字,效果如下:
改进的源代码
点击查看代码
; 对task3.asm的修改, 可以打印0~2559不定位数的数字
assume ds:data, cs:code, ss:stack
data segment
; 改进: db换成dw
x dw 999, 0, 856, 1024, 36, 97, 2559
len equ $ - x
data ends
stack segment
dw 32 dup(?)
stack ends
code segment
start:
mov ax, data
mov ds, ax
mov ax, stack
mov ss, ax
mov sp, 64
; 这里需要改
mov cx, len/2 ; 由于数据都是word型,所以len/2才是数据个数
; print循环: 依次打印所有数字
print:
; 这里需要改, 数据读进ax而不是al
mov ax, word ptr ds:[di] ; 把数据放入al
add di, 2 ; di指针后移2字节
push cx ; 把cx保存起来, 子程序中会修改cx值
call printNumber ; 打印数字
call printSpace ; 打印空格
pop cx ; 恢复cx
loop print
mov ah, 4ch
int 21h
; 子程序: printNumber
; 功能: 打印数字
; 入口参数:
; 寄存器ax (待输出的数据 --> ax)
; 局部变量说明:
; bx -> 存储数字字符个数
printNumber:
mov bx, 0 ; 获取之前位数为0
; 逐位获取数字
; getEach循环: 获取每一位,然后压入栈中
getEach:
mov dl, 10
div dl ; 数据除10
push ax ; 将数字压入栈中(ah余数在ax里了)
inc bx ; 位数+1
mov ah, 0 ; ah是余数,置0后ax表示除法的结果
mov cx, ax ; 除法结果赋给cx, 如果结果为0则说明所有位数都获取完了
inc cx ; 由于loop时会-1,这里先+1,防止出现负数
loop getEach
; 打印数字
mov cx, bx ; 先把bx存的数字位数赋给cx
; printEach循环: 依次从栈中取出数字,逐位打印
printEach:
pop ax ; 取出一位数
add ah, 30h ; ah是刚才除法的余数,也就是需要得到的位数,+30h是转成对应字符
mov dl, ah ; 放到dl, 用于打印
mov ah, 2 ; 调用int 21h的2号子程序打印
int 21h
loop printEach
ret
; 子程序: printSpace
; 功能: 打印空格
printSpace:
mov ah, 2
mov dl, 20h
int 21h
ret
code ends
end start
改进后的实验结果
改进后的程序可以实现打印 0 ~ 2559之间的任意数字。

一些说明
1.关于改进的代码
源代码的数据存储在字节单位,只能取0~255之间的数字。而改进后数据存在字单位,理论上可以打印0 ~ 65535之间的任意数字。
但是上面的实验结果中说最大只能打印到2559,而不是65535,这和除法运算指令div有关。
2. div指令的一些解释
王爽《汇编语言(第2版)》P169关于div指令的说明是:

根据书上的说法,任意一个16位的被除数(十六进制小于FFFF,也就是十进制小于65535的数)都可以放在ax中进行除法运算。
但是在实际操作中(操作是:除数放在一个8位寄存器中(如bl)),被除数放在bx中把65535也就是FFFFh放在ax中,进行十进制除10运算却发生了错误。同样的,对0FFFh进行除10运算也出错了。而00FFh是不会出错的。
这就奇了怪了。
不过按书上的说明,16位被除数放在ax中,除法运算后的商保存在al中,余数保存ah中。而al和ah都是8位的,因此商和余数应该均小于8位。
所以,其实div除法指令更确切的定义应该是:
如果除数为8位,被除数为16位,且进行除法运算后的商和余数均为8位,除数才能放在一个8位寄存器中,被除数放在
AX中,且商和余数才会存在AH和AL中。否则,即使除数是8位,仍应当放在一个16位的寄存器中,被除数则应当放在
DX:AX中,如果是16位被除数,则只放在AX即可,而商存在AX中,余数存在DX中。
根据 Intel 白皮书(《Intel® 64 and IA-32 Architectures Software Developer’s Manual Volume 2 (2A, 2B, 2C & 2D): Instruction Set Reference, A-Z》)中的说明:


手册的意思说,小于255的数,被除数和结果都在AX中,而255 ~ 65535的数结果则当DX:AX中。
实际测试中,如果被除数放在16位寄存器中,除数是放在8位寄存器中,且商和余数都在8位范围内,则可以正常计算且结果保存在AH和AL中。而如果商或余数超过8位,则会出错。
如果8位除数放在16位寄存器中(除了DX以外的寄存器),无论被除数是多少(0000-FFFFh),结果都会商保存在AX中,而余数保存在DX中。
因此上面改进的实验结果中提到的2559,根据上面的解释,商和余数都在8位以内,由于做的是除10运算,也就是十六进制除A运算,FF(商) * 0A + 09(余数) = 09FF,09FF即2559,因此上面的代码最大可以支持到打印2559。
进一步改进的代码
限于篇幅,这里只展示修改后的printNumber子程序
点击查看代码
; 对task32.asm的修改, 可以打印0~65535不定位数的数字
; 子程序: printNumber
; 功能: 打印数字
; 入口参数:
; 寄存器ax (待输出的数据 --> ax)
; 局部变量说明:
; bx -> 存储数字字符个数
printNumber:
mov bx, 0 ; 获取之前位数为0
; 逐位获取数字
; getEach循环: 获取每一位,然后压入栈中
getEach:
; 改进: 除数放在16位寄存器bp中
mov bp, 10 ; 除10运算
mov dx, 0 ; 由于除数是16位寄存器,dx也是被除数一部分,需要置零
div bp ; 数据除10
push dx ; 将数字压入栈中(余数在dx里)
inc bx ; 位数+1
mov cx, ax ; 除法商赋给cx, 如果商为0则说明所有位数都获取完了
inc cx ; 由于loop时会-1,这里先+1,防止出现负数
loop getEach
; 打印数字
mov cx, bx ; 先把bx存的数字位数赋给cx
; printEach循环: 依次从栈中取出数字,逐位打印
printEach:
pop dx ; 取出一位数
add dl, 30h ; dl是刚才除法的余数,也就是需要得到的位数,+30h是转成对应字符
mov ah, 2 ; 调用int 21h的2号子程序打印
int 21h
loop printEach
ret
进一步的结果
至此,代码task33.asm已经可以实现输出0 ~ 65535的任意数字了

实验任务4
源代码
点击查看代码
assume cs:code, ds:data, ss:stack
data segment
string db 'try'
len = $ - string
data ends
stack segment
dw 2 dup(?)
stack ends
code segment
start:
mov ax, data
mov ds, ax
mov ax, stack
mov ss, ax
mov sp, 2
mov cx, len ; cs: 字符串长度
mov ax, 0
mov si, ax ; si: 0
; 打印顶部的绿色字符
mov bl, 0Ah ; bl: 颜色(背景黑+高亮+绿色:0 000 1 010)
mov bh, 0 ; bh: 行号(第1行)
call printStr
; 打印底部红色字符
mov bl, 0Ch ; bl: 颜色(背景黑+高亮+绿色:0 000 1 100)
mov bh, 24 ; bh: 行号(第25行)
call printStr
mov ah, 4ch
int 21h
; 子程序: printStr
; 功能: 在指定行、以指定颜色,在屏幕上显示字符串
; 入口参数:
; 字符串首字符地址 --> ds:si (其中,字符串所在段的段地址—> ds, 字符串起始地址的偏移地址—> si)
; 字符串长度 --> cx
; 字符串颜色 --> bl
; 指定行 --> bh (取值:0 ~ 24)
printStr:
mov al, bh ; 把行号放在 al
mov dl, 0A0h ; 每行160字节,放在 dl 中
mul dl ; 与行号相乘获得行起始地址, al中存的是行起始地址
mov di, ax ; di存行起始地址
mov ax, 0b800h
mov es, ax ; 显存段地址
; 开始打印
; cx已经存了字符串数量, 直接循环就行
push si ; 先保存si, 以便下次再用
push cx ; 保存cx, 以便下次用
; 循环依次打印字符
startToPrint:
mov al, ds:[si]
mov es:[di], al ; 把ds:[si]的字符放进es:[di]
mov es:[di+1], bl ; 放入颜色
inc si
add di, 2
loop startToPrint
pop cx ; 恢复cx
pop si ; 恢复si
ret ; 打印完成, 返回
code ends
end start
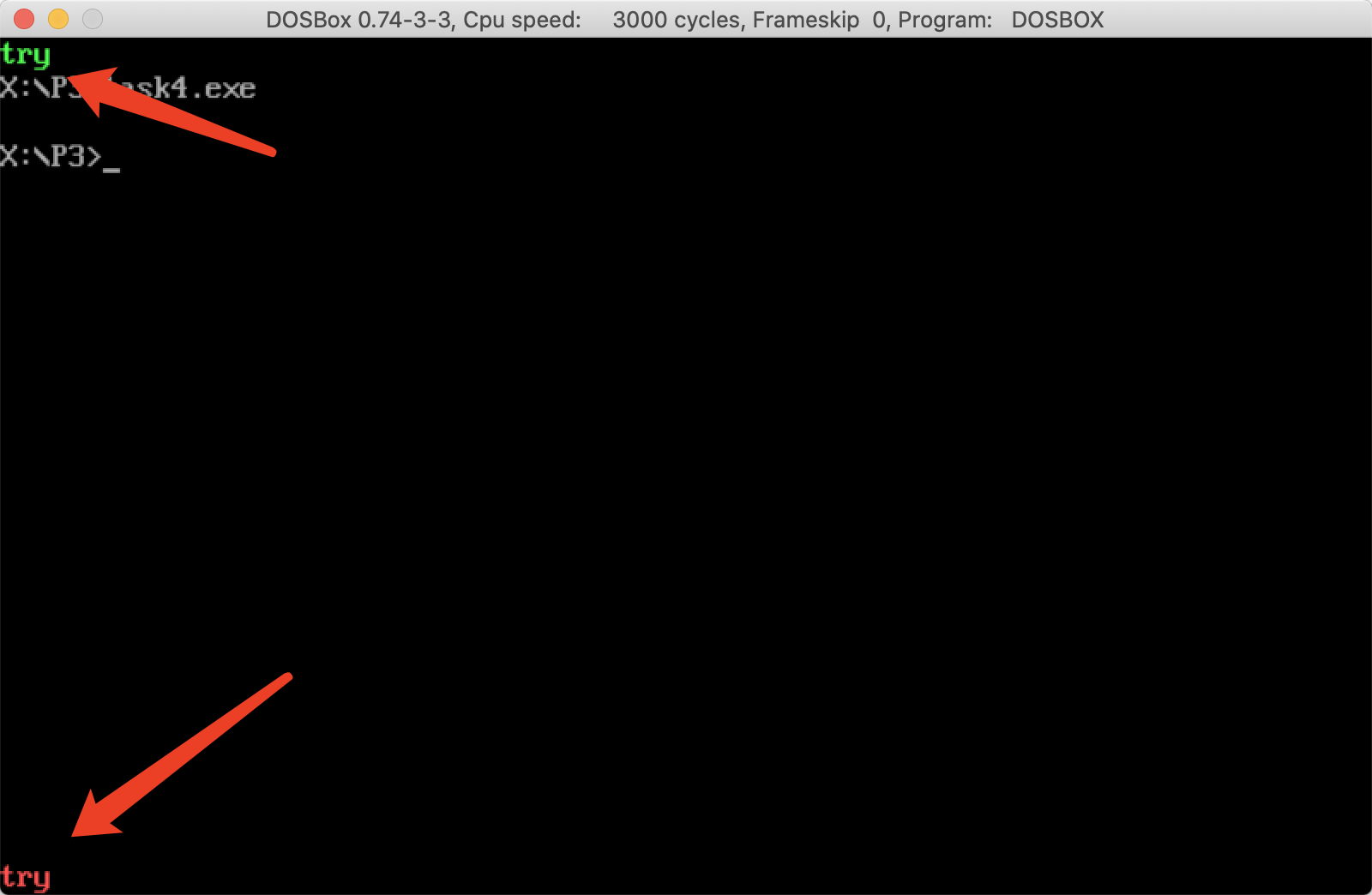
实验结果
可以看到,打印了符合预期的字符
一些记录
-
在
printStr子程序中,进行打印前,可以先将si和cx入栈保存。由于字符串需要打印两次重复利用,而这两个寄存器的值在打印时需要修改(si控制读入字符,cx控制打印字符个数的循环),因此先压入栈中保存,打印结束后再弹出放回寄存器,下次可以继续重复打印这一段字符串,简化程序编写这样做的好处在于:
根据高级语言编写函数的经验,除非需要,否则函数内部最好不要修改外部变量。而
si和cx作为外部变量,在内部需要进行修改,因此先保存起来,修改完成后,在函数退出前再恢复回去,这样相当于把si和cx拷贝为局部变量使用,不会修改外部变量 -
字符属性值(仅作为记录,来自王爽《汇编语言(第2版)》P189)
![]()

实验任务5
源代码
点击查看代码
assume cs:code, ds:data
data segment
stu_no db '201983290048'
len = $ - stu_no
data ends
code segment
start:
mov ax, data
mov ds, ax
mov di, 0
call printStuNum ; 调用打印子程序
mov ah, 4ch
int 21h
; 打印子程序:
; 参数说明:
; 学号字符串存储在 -> ds:[di]
printStuNum:
mov ax, 0b800h
mov es, ax ; 控制显存区域段指针
mov si, 1 ; 显存区域列指针
; 先把屏幕前24行背景打印成蓝色
mov al, 24 ; 前24行
mov dl, 80 ; 每行80个字符需要修改颜色
mul dl ; 24*80, 获得需要填充蓝色的字符数
mov cx, ax
printBlue:
mov al, 17h ; 蓝底+白字:0 001 0 111 -> 17h
mov es:[si], al ; 把颜色填充到位
add si, 2 ; 后移2个
loop printBlue
sub si, 1 ; 指针回退一个, 从最后一行起始位置开始
; 打印最后一行
mov ax, 80
sub ax, len ; 80列 - 学号长度
mov dl, 2
div dl ; (80 - len)/2, 就是学号左右两侧需要填充'-'的长度
mov dx, ax ; 使用dx保存'-'的长度
; 调用打印'-'的子程序, 打印学号左侧的'-'
mov cx, dx
call printSeparator
; 打印学号字符串
mov cx, len
printNumber:
mov al, ds:[di] ; 低位是字符
mov ah, 17h ; 高位是颜色
mov word ptr es:[si], ax ; 按字放入
inc di
add si, 2
loop printNumber
; 再次调用打印'-'的子程序, 打印学号右侧的'-'
mov cx, dx
call printSeparator
ret
; 子程序: 打印分隔符'-'
; 参数: 长度 -> cx
; 位置 -> es:[si]
printSeparator:
mov al, '-'
mov ah, 17h
mov word ptr es:[si], ax
add si, 2
loop printSeparator
ret
code ends
end start
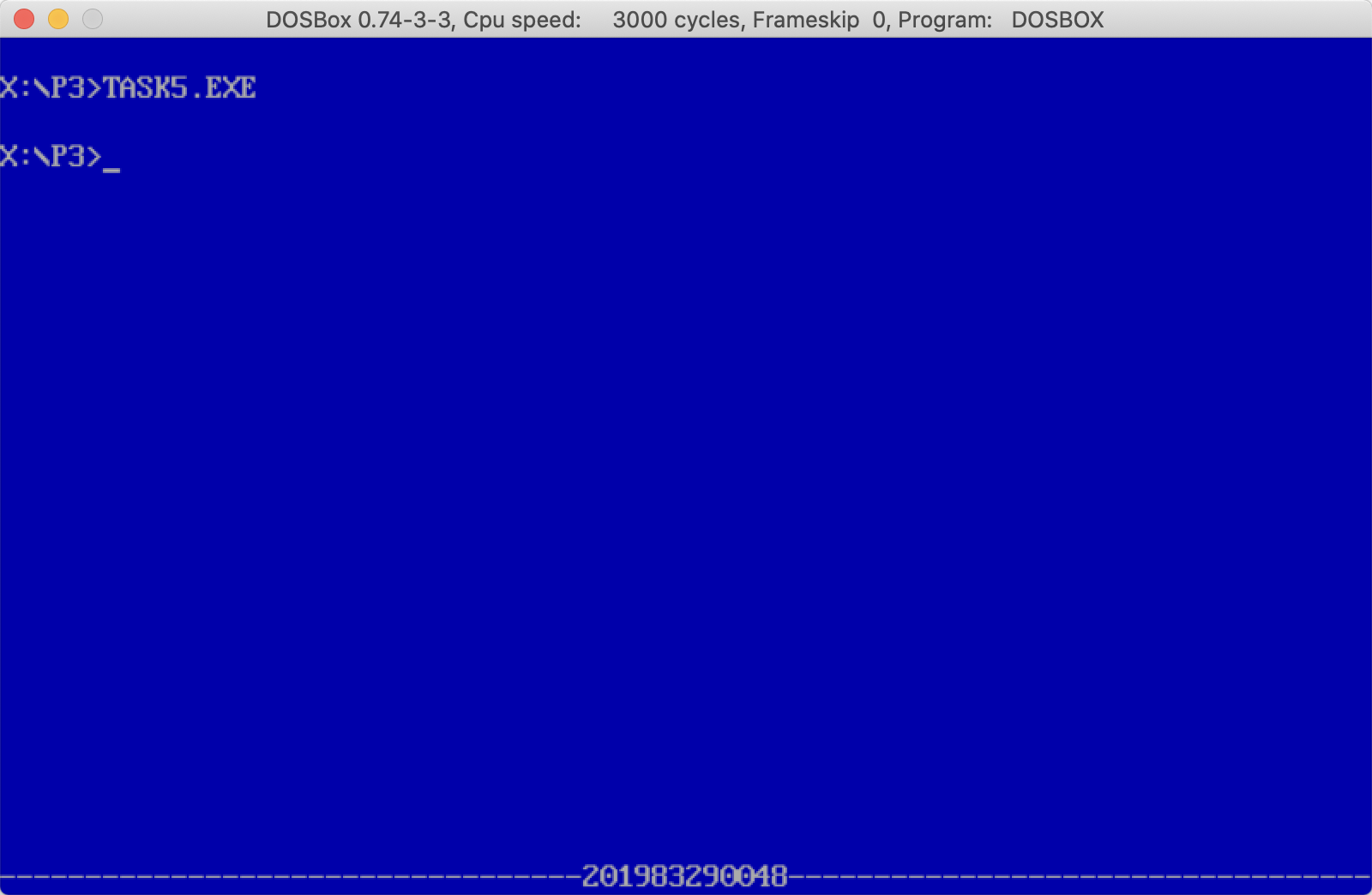
实验结果
代码说明全部写在代码注释中。
可以看到,成功实现了要求实现的效果。
总结与思考

- 课本上的内容说的比较简洁,很多细节没有说的很清楚。这样的好处是比较易懂,缺点是如果想知道更进一步的原理就比较困难。之前偶然知道了 Intel 白皮书(《Intel® 64 and IA-32 Architectures Software Developer’s Manual》),这本手册里可以查到 Intel 汇编指令的所有信息。常用的就是查看汇编指令的具体使用方法和机器码等细节。
- 在研究过程中,关于loop和div两个指令使用时产生了一些问题,由于国内搜索引擎查找汇编相关资料时得到的内容很少,帮助有限。而在查阅 Intel 白皮书后得到了很好的解决。
- 8086的实模式下控制显存在屏幕上打印内容相当方便,只要知道了显存的地址结构就可以随意修改屏幕上的颜色和内容。
- 汇编中编写子程序很像高级语言中的函数,但是比函数更灵活一点。不过由于需要来回跳转,程序的结构性可能不如高级语言来的好。
- 在实验任务1中对于标号进行了一些研究,但是无奈搜不到什么相关资料,只能靠猜测来解释。
- 子程序需要合理分配寄存器,如果需要修改寄存器时最好先把寄存器的内容压栈,操作完后再恢复,这样可以在不同程序段中多次使用一个寄存器。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号